
Mybatis的缓存——一级缓存和源码分析
点击上方蓝色字体,选择“标星公众号”
优质文章,第一时间送达
作者 | isdxh
来源 | urlify.cn/Ynq6ry
什么是缓存?
缓存就是存在内存中的数据,而内存读取都是非常快的 ,通常我们会把更新变动不太频繁且查询频繁的数据,在第一次从数据库查询出后,存放在缓存中,这样就可以避免之后多次的与数据库进行交互,从而提升响应速度。
mybatis 也提供了对缓存的支持,分为:
一级缓存
二级缓存
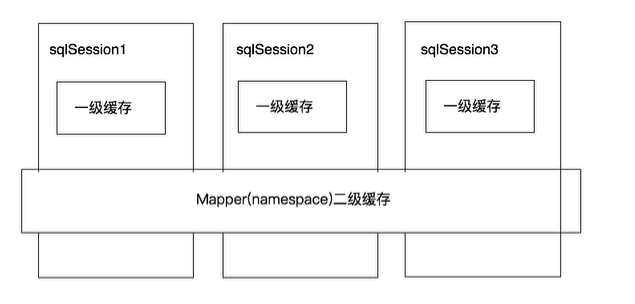
一级缓存:
每个sqlSeesion对象都有一个一级缓存,我们在操作数据库时需要构造sqlSeesion对象,在对象中有一个HashMap用于存储缓存数据。不同的sqlSession之间的缓存数据区域(HashMap)是互不影响的。二级缓存:
二级缓存是mapper级别(或称为namespace级别)的缓存,多个sqlSession去操作同一个Mapper的sql语句,多个SqlSession可以共用二级缓存,二级缓存是跨sqlSession的。
一级缓存
首先我们来开一级缓存,一级缓存是默认开启的,所以我们可以很方便来体验一下一级缓存。
测试一、
准备一张表,有两个字段id和username
在测试类中:
public class TestCache {
private SqlSession sqlSession;
private UserMapper mapper;
@Before
public void before() throws IOException {
InputStream resourceAsStream = Resources.getResourceAsStream("sqlMapConfig.xml");
SqlSessionFactory build = new SqlSessionFactoryBuilder().build(resourceAsStream);
sqlSession = build.openSession();
mapper = sqlSession.getMapper(UserMapper.class);
}
@Test
public void testFirst(){
//第一次查询————首先去一级缓存中查询
User user1 = mapper.findById(1);
System.out.println("======"+user1);
//第二次查询
User user2 = mapper.findById(1);
System.out.println("======"+user2);
System.out.println(user1==user2);
}
}
我们用同一个sqlSession分别根据id来查询用户,id都为1,之后再比较它们的地址值。来看一下结果:
23:16:25,818 DEBUG findById:159 - ==> Preparing: select * from user where id=?
23:16:25,862 DEBUG findById:159 - ==> Parameters: 1(Integer)
23:16:25,894 DEBUG findById:159 - <== Total: 1
======User{id=1, username='lucy'}
======User{id=1, username='lucy'}
true
我们发现只打印了一条SQL,同时它们的地址值一致。
说明第一次查询,缓存中没有,然后从数据库中查询——执行SQL,然后存入缓存,第二次查询时发现缓存中有了,所以直接从缓存中取出,不再执行SQL了。
我们刚才提到,一级缓存的数据结构是一个hashmap,也就是说有key有value。
value就是我们查询出的结果,key是由多个值组成的:
statementid :namespace.id组成
params:查询时传入的参数
boundsql:mybatis底层的对象,它封装着我们要执行的sql
rowbounds:分页对象
...还有一些会在源码分析中道明
测试二、
我们现在修改一下,我们在查询第一次结果后,修改一下数据库的值,然后再进行第二次查询,我们来看一下查询结果。id=1 的username为lucy
@Test
public void testFirst(){
//第一次查询
User user1 = mapper.findById(1);
System.out.println("======"+user1);
//修改id为1的username
User updateUser = new User();
updateUser.setId(1);
updateUser.setUsername("李思");
mapper.updateUser(updateUser);
//手动提交事务
sqlSession.commit();
//第二次查询
User user2 = mapper.findById(1);
System.out.println("======"+user2);
System.out.println(user1==user2);
}
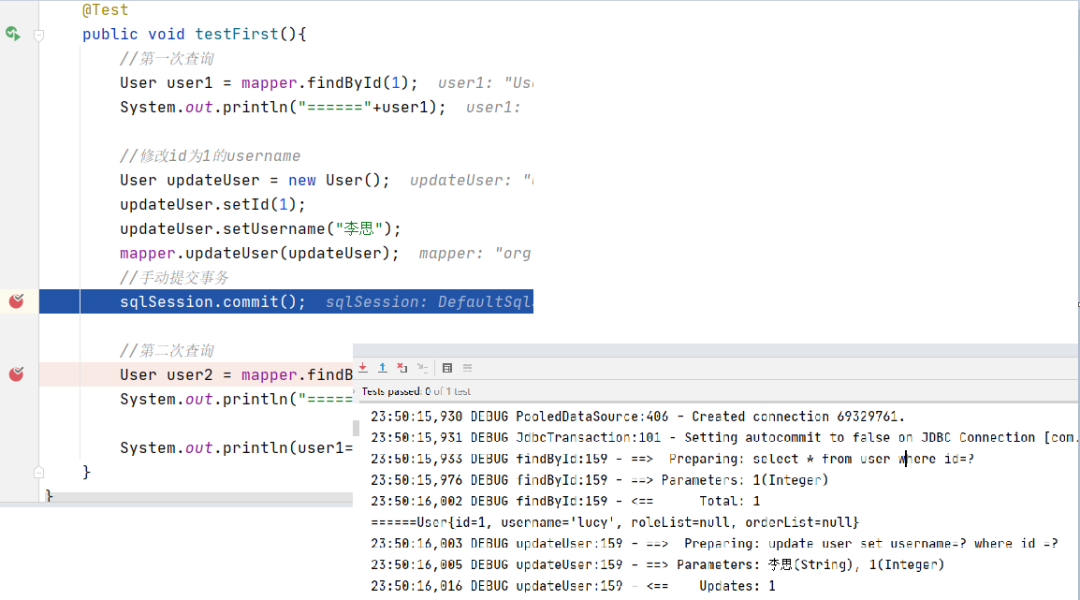
在提交事务的地方打一个断点,可以看到执行了两条sql,一个是查询id为1,一个是修改id为1的username
最终结果:
23:50:15,933 DEBUG findById:159 - ==> Preparing: select * from user where id=?
23:50:15,976 DEBUG findById:159 - ==> Parameters: 1(Integer)
23:50:16,002 DEBUG findById:159 - <== Total: 1
======User{id=1, username='lucy', roleList=null, orderList=null}
23:50:16,003 DEBUG updateUser:159 - ==> Preparing: update user set username=? where id =?
23:50:16,005 DEBUG updateUser:159 - ==> Parameters: 李思(String), 1(Integer)
23:50:16,016 DEBUG updateUser:159 - <== Updates: 1
23:53:18,316 DEBUG JdbcTransaction:70 - Committing JDBC Connection [com.mysql.jdbc.JDBC4Connection@421e361]
23:53:22,306 DEBUG findById:159 - ==> Preparing: select * from user where id=?
23:53:22,306 DEBUG findById:159 - ==> Parameters: 1(Integer)
23:53:22,307 DEBUG findById:159 - <== Total: 1
======User{id=1, username='李思', roleList=null, orderList=null}
我们看到,最终打印了3条sql,再进行修改后的第二次查询也打印了。
说明在第二次查询时在缓存中找不到所对应的key了。在进行修改操作时,会刷新缓存
我们也可以通过sqlSession.clearCache();手动刷新一级缓存
总结:
一级缓存的数据结构时HashMap
不同的SqlSession的一级缓存互不影响
一级缓存的key是由多个值组成的,value就是其查询结果
增删改操作会刷新一级缓存
通过
sqlSession.clearCache()手动刷新一级缓存
一级缓存源码分析:
我们在分析一级缓存之前带着一些疑问来读代码
一级缓存是什么?真的是上面说的HashMap吗?
一级缓存什么时候被创建?
一级缓存的工作流程是怎么样的?
1. 一级缓存到底是什么?
之前说不同的SqlSession的一级缓存互不影响,所以我从SqlSession这个类入手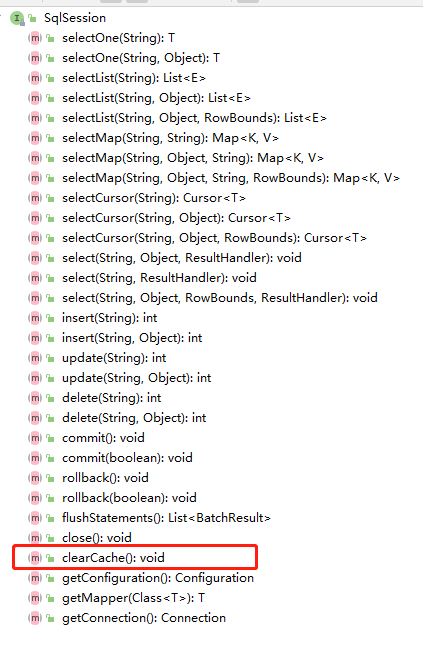
可以看到,org.apache.ibatis.session.SqlSession中有一个和缓存有关的方法——clearCache()刷新缓存的方法,点进去,找到它的实现类DefaultSqlSession
@Override
public void clearCache() {
executor.clearLocalCache();
}
再次点进去executor.clearLocalCache(),再次点进去并找到其实现类BaseExecutor,
@Override
public void clearLocalCache() {
if (!closed) {
localCache.clear();
localOutputParameterCache.clear();
}
}
进入localCache.clear()方法。进入到了org.apache.ibatis.cache.impl.PerpetualCache类中
package org.apache.ibatis.cache.impl;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.locks.ReadWriteLock;
import org.apache.ibatis.cache.Cache;
import org.apache.ibatis.cache.CacheException;
/**
* @author Clinton Begin
*/
public class PerpetualCache implements Cache {
private final String id;
private Map cache = new HashMap();
public PerpetualCache(String id) {
this.id = id;
}
//省略部分...
@Override
public void clear() {
cache.clear();
}
//省略部分...
}
我们看到了PerpetualCache类中有一个属性private Map,很明显它是一个HashMap,我们所调用的.clear()方法,实际上就是调用的Map的clear方法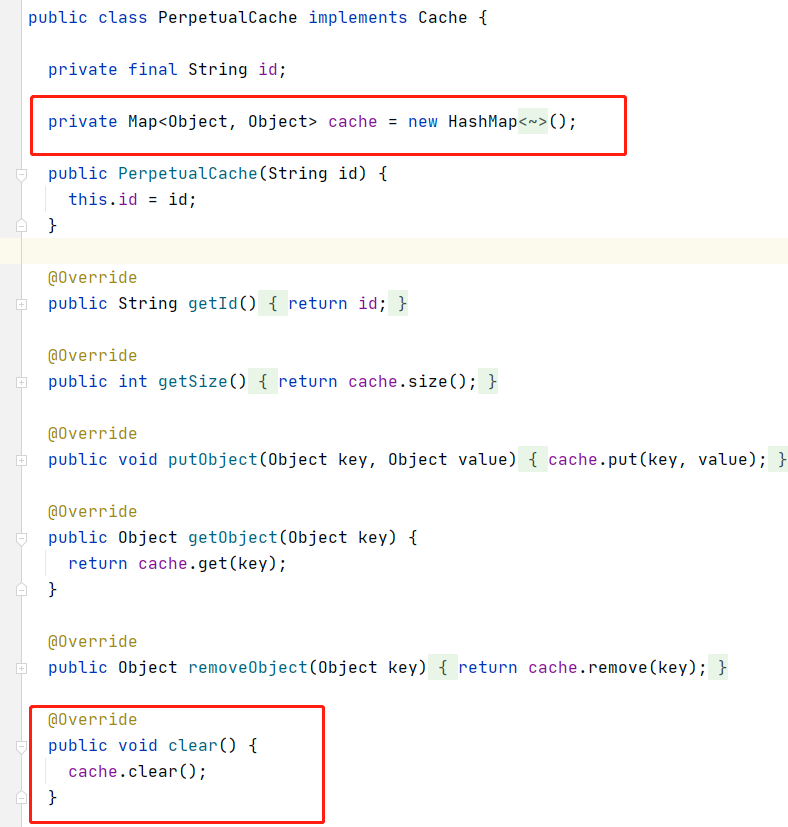
得出结论:
一级缓存的数据结构确实是HashMap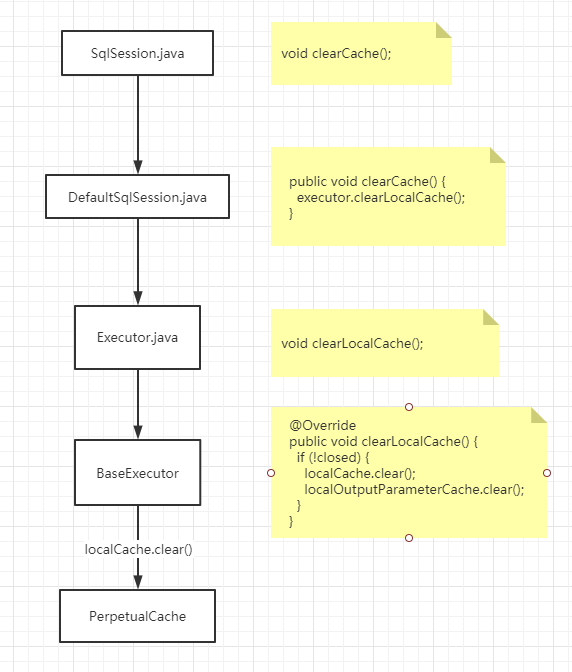
2. 一级缓存什么时候被创建?
我们进入到org.apache.ibatis.executor.Executor中
看到一个方法CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql) ,见名思意是一个创建CacheKey的方法
找到它的实现类和方法org.apache.ibatis.executor.BaseExecuto.createCacheKey
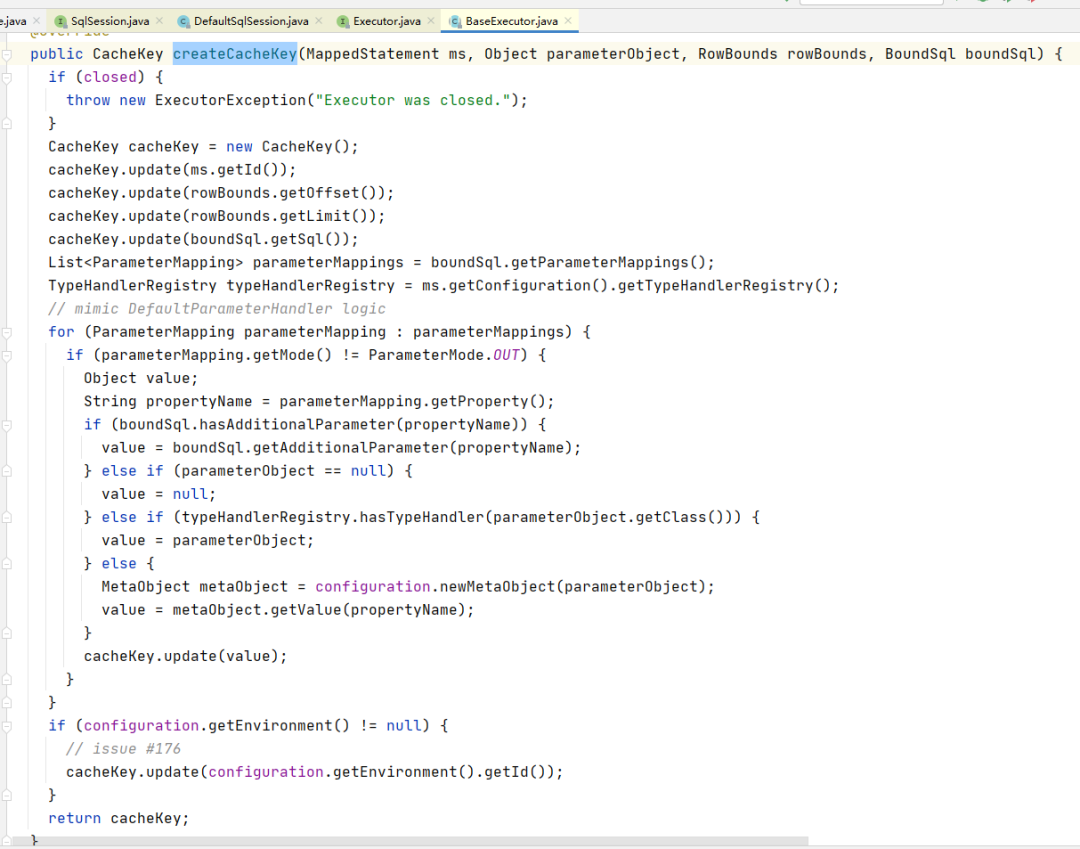
我们分析一下创建CacheKey的这块代码:
public CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql) {
if (closed) {
throw new ExecutorException("Executor was closed.");
}
//初始化CacheKey
CacheKey cacheKey = new CacheKey();
//存入statementId
cacheKey.update(ms.getId());
//分别存入分页需要的Offset和Limit
cacheKey.update(rowBounds.getOffset());
cacheKey.update(rowBounds.getLimit());
//把从BoundSql中封装的sql取出并存入到cacheKey对象中
cacheKey.update(boundSql.getSql());
//下面这一块就是封装参数
List parameterMappings = boundSql.getParameterMappings();
TypeHandlerRegistry typeHandlerRegistry = ms.getConfiguration().getTypeHandlerRegistry();
for (ParameterMapping parameterMapping : parameterMappings) {
if (parameterMapping.getMode() != ParameterMode.OUT) {
Object value;
String propertyName = parameterMapping.getProperty();
if (boundSql.hasAdditionalParameter(propertyName)) {
value = boundSql.getAdditionalParameter(propertyName);
} else if (parameterObject == null) {
value = null;
} else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {
value = parameterObject;
} else {
MetaObject metaObject = configuration.newMetaObject(parameterObject);
value = metaObject.getValue(propertyName);
}
cacheKey.update(value);
}
}
//从configuration对象中(也就是载入配置文件后存放的对象)把EnvironmentId存入
/**
* "development">
* "development"> //就是这个id
*
* type="JDBC">
*
* type="POOLED">
* "driver" value="${jdbc.driver}"/>
* "url" value="${jdbc.url}"/>
* "username" value="${jdbc.username}"/>
* "password" value="${jdbc.password}"/>
*
*
*
*/
if (configuration.getEnvironment() != null) {
// issue #176
cacheKey.update(configuration.getEnvironment().getId());
}
//返回
return cacheKey;
}
我们再点进去cacheKey.update()方法看一看
/**
* @author Clinton Begin
*/
public class CacheKey implements Cloneable, Serializable {
private static final long serialVersionUID = 1146682552656046210L;
public static final CacheKey NULL_CACHE_KEY = new NullCacheKey();
private static final int DEFAULT_MULTIPLYER = 37;
private static final int DEFAULT_HASHCODE = 17;
private final int multiplier;
private int hashcode;
private long checksum;
private int count;
//值存入的地方
private transient List我们知道了那些数据是在CacheKey对象中如何存储的了。下面我们返回createCacheKey()方法。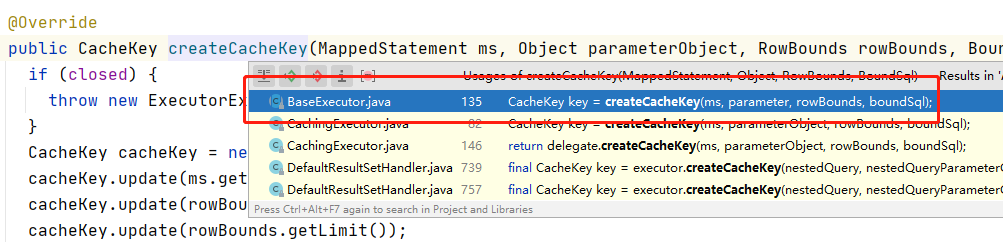
Ctrl+鼠标左键 点击方法名,查询有哪些地方调用了此方法
我们进入BaseExecutor,可以看到一个query()方法:
这里我们很清楚的看到,在执行query()方法前,CacheKey方法被创建了
3. 一级缓存的执行流程
我们可以看到,创建CacheKey后调用了query()方法,我们再次点进去:
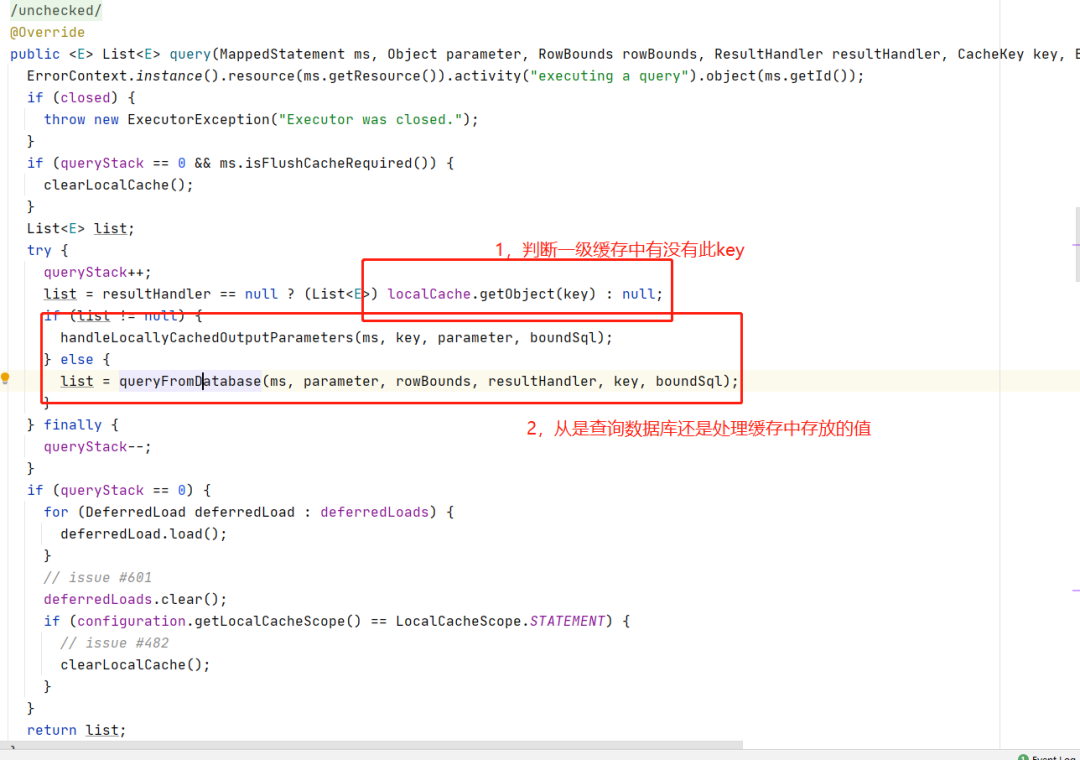
在执行SQL前如何在一级缓存中找不到Key,那么将会执行sql,我们来看一下执行sql前后会做些什么,进入
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);

分析一下:
private List queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List list;
//1. 把key存入缓存,value放一个占位符
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
//2. 与数据库交互
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
//3. 如果第2步出了什么异常,把第1步存入的key删除
localCache.removeObject(key);
}
//4. 把结果存入缓存
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
至此,我们思路就非常的清晰了。
结论:
在执行sql前,会首先根据CacheKey查询缓存中有没有,如果有,就处理缓存中的参数,如果没有,就执行sql,执行sql后把结果存入缓存。
一级缓存源码分析结论:
一级缓存的数据结构是一个
HashMap,它的value就是查询结果,它的key是CacheKey,CacheKey中有一个list属性,statementId,params,rowbounds,sql等参数都存入到了这个list中一级缓存在调用
query()方法前被创建。并传入到query()方法中会首先根据
CacheKey查询缓存中有没有,如果有,就处理缓存中的参数,如果没有,就执行sql,执行sql后把结果存入缓存。
粉丝福利:实战springboot+CAS单点登录系统视频教程免费领取
???
?长按上方微信二维码 2 秒 即可获取资料
感谢点赞支持下哈 