
离线计算平台在汽车之家的演进之路
本次的分享内容分成四个部分:
1.汽车之家离线计算平台现状
2.平台构建过程中遇到的问题
3.基于构建过程中问题的解决方案
4.离线计算平台未来规划
▌汽车之家离线计算平台现状
1. 汽车之家离线计算平台发展历程
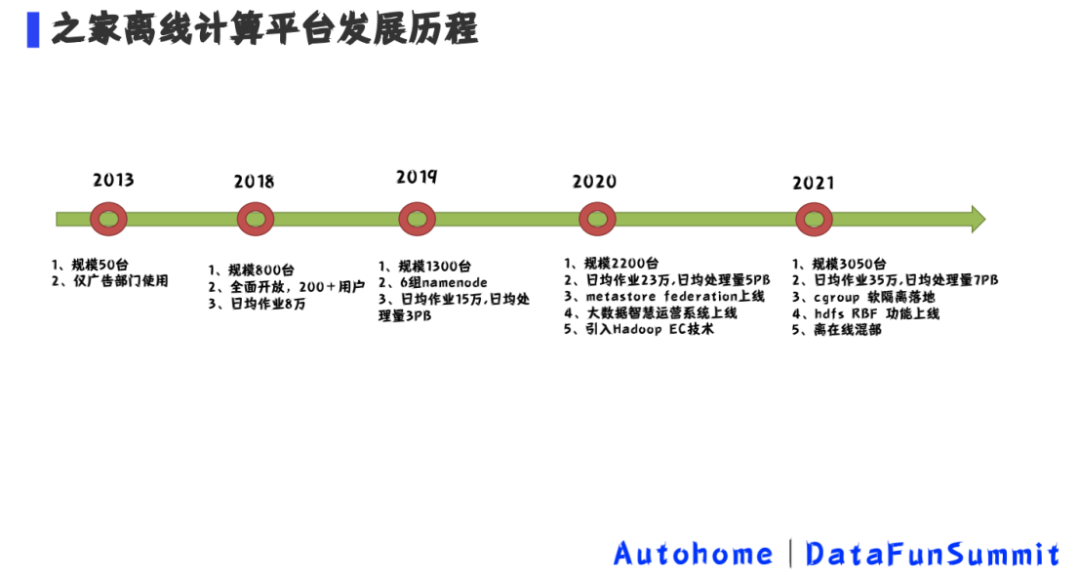
2013年的时候汽车之家集群的规模大概50台左右,主要是广告部门用于离线数据分析使用。
2018年底集群规模大概有800台,面向之家所有的业务团队全面开放,用户大概有200个,日均处理作业8万左右。
2019年底集群规模1300台;由于集群规模越来越大,用户越来越多以及不规范的使用,单一namenode无法承受压力,namenode扩展为6组namenode,日均作业15万,日均处理数据量3PB。
2020年底规模2200台,日均作业23万,日均处理数据量5PB;metastore federation正式上线,解决由于分区数多导致的查询性能问题;大数据智慧运营系统上线,主要是用大数据的理念来治理大数据平台;引入hadoop EC技术解决冷数据存储问题,提升存储利用效率。
2021年集群规模3050台,日均作业35万,日均处理量7PB,Cgroup软隔离落地进一步提升集群的性能,由hdfs viewfs切换到hdfs RBF ,hdfs RBF上线,离在线混部提高集群的利用率,经过这几年的发展,集群性能越来越强大,服务越来越稳定。
2. 集群当前运行状态
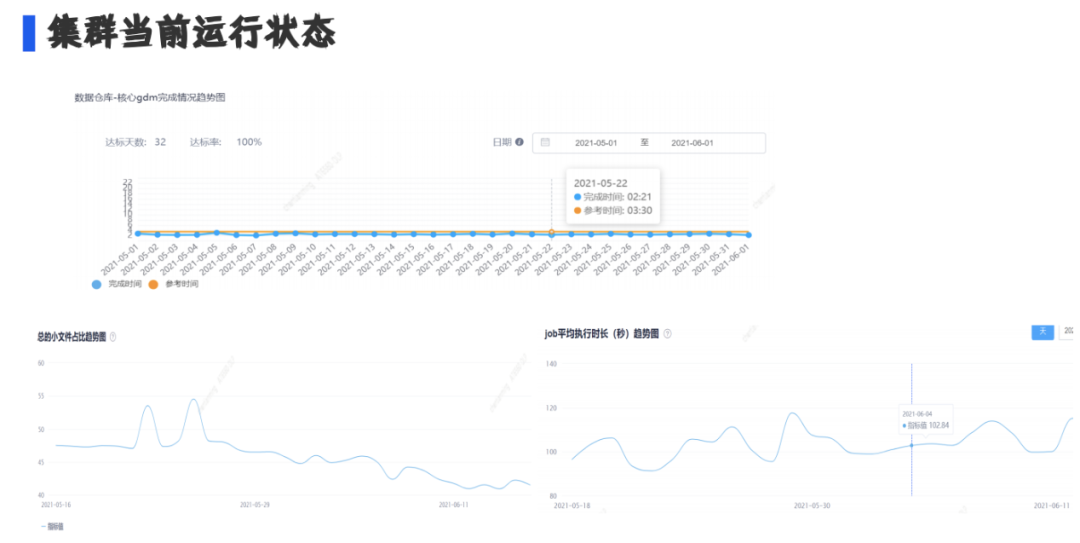
从这个图中可以看出目前数据仓库的核心任务基本上提前一个小时完成;集群小文件占比逐步降低,目前百分之四十多;集群所有MR任务,平均作业运行时长在100秒上下浮动,整个集群的状态非常平稳。
▌平台构建过程中遇到的问题

1. 分区过多,hive性能慢
随着平台的发展数据量越来越多,分区数也越来越多,去年初整个分区数在5000万左右每天还在2万左右的增加,如果有业务上线批量刷数会造成hive查询非常慢。
2. 大量小文件,用户使用不规范
平台在开放的过程中会有很多问题,最典型的例子我们单个namenode文件和块数大概有4亿左右,这样会造成很多问题,比如namenode响应时间非常长,namenode rpc 队列经常被打满,主节点重启用时较长(超过30分钟);另外用户使用不规范的问题,比如队列资源之类的滥用比较多,MR任务申请的内存过大问题
3. 业务急剧增长导致计算资源不足
汽车之家业务的急剧增长导致计算资源不足,任务有延迟,核心任务SLA无法保证等问题;这个需要我们进行优化提高资源的利用率。
4. 离线计算资源总体利用率低
通过分析发现离线计算资源具有潮汐性:夜间利用率比较高,白天利用率比较低。怎么样提升资源使用率,是我们当下需要解决的问题。
▌基于构建过程中问题的解决方案
1.解决metastore的问题
 2020年初集群大概有5000万左右分区,每天2万+的速度在增长导致平台的压力比较大,有新业务上线的时候需要批量更新数据,hive查询比较慢。
2020年初集群大概有5000万左右分区,每天2万+的速度在增长导致平台的压力比较大,有新业务上线的时候需要批量更新数据,hive查询比较慢。
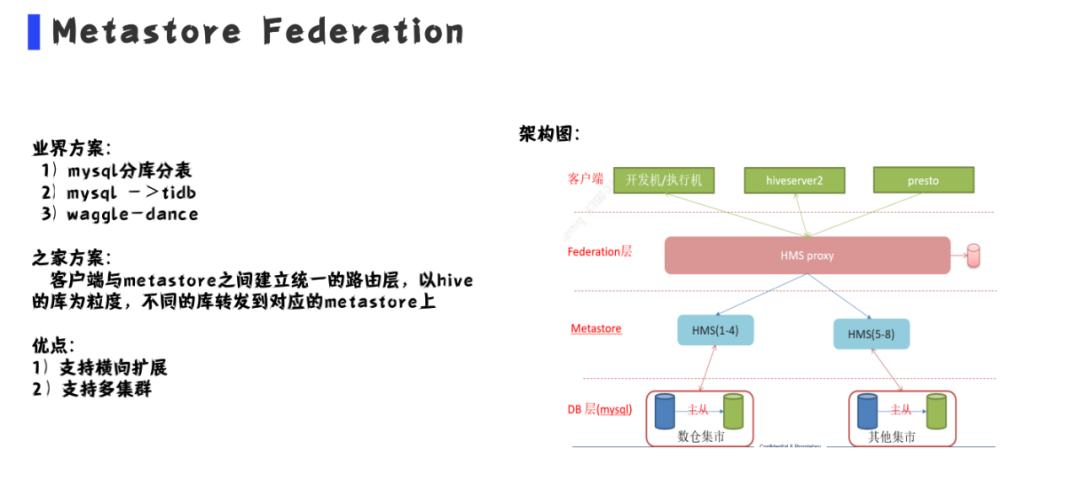
业界解决方案主要有以下几种:
(1) mysql分库分表:无论是垂直分表还是水平分表我们通过metastore 查询mysql都需要修改大量的逻辑,如果使用这种方案改动较大,成本比较高。
(2)mysq切换成tidb:其他大厂也有实现过,但是通过测试发现需要关闭metastore事务等问题,对于tidb没有足够的信息,我们认为这个应该从架构层来解决,即使以后出现问题,所有的设计我们都清楚,能够快速解决问题。
(3)waggle-dance:这个方案滴滴有使用,汽车之家的hadoop平台是基于kerberos做的认证,这个组件没有kerberos认证所以这个也不太适合。
汽车之家解决方案:
在客户端与metastore之间建立统一的路由层,以hive的DB为粒度,不同的库转发到对应的metastore上,通过这种方式解决hive分区量过大的问题。
这种方式有两个优点:1、支持横向扩展,出现性能瓶颈时,只需要把大库拆分下来即可,并且对业务几乎无感知;2、支持多集群,因为我们要建立海外站,我们可以将海外站和国内的metastore关联起来进行查询
上图是我们的架构图,我们的开发机客户端和hiveserver2通过代理来连接到metastore,通过metastore来查询底层的分区信息。这种方案需要注意一个问题,由于集群里有认证,一个客户端可能会访问不同的metastore,后来调研社区方案发现在metastore层面是可以共享托管的,将所有的metastore通过zookeper托管来解决客户端认证的问题。
2.viewfs升级到RBF服务
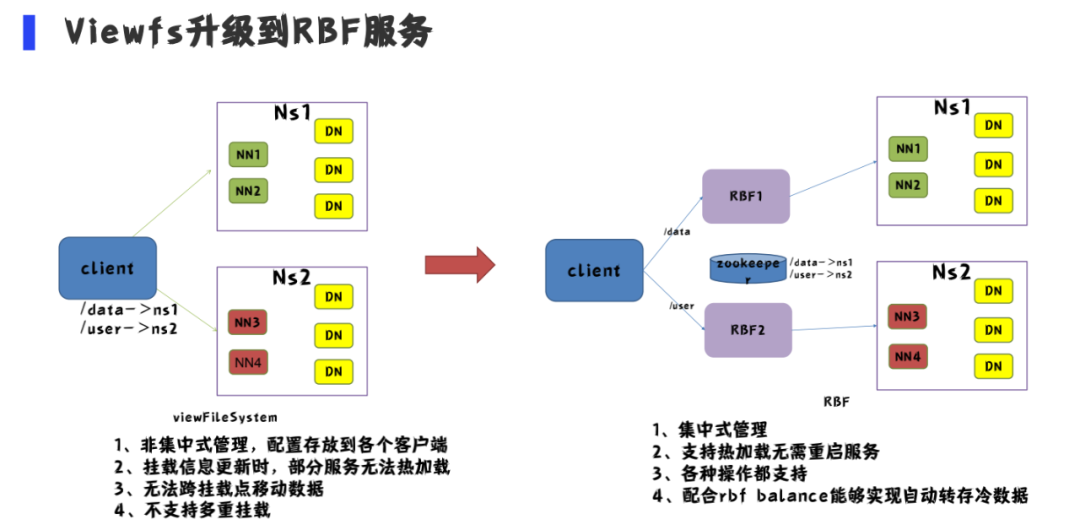
我们之前用的是viewfs,在使用viewfs遇到很多问题,我们总结主要有以下4个问题:
1、非集中式管理,配置都存放到客户端以及部分系统中,造成管理不便
2、挂载表信息更新时部分服务无法热加载,需要手动重新启动服务;比如metastore
3、无法跨挂载点移动数据
4、不支持多重挂载,比如我们的集群所有的application日志保存到hdfs上,存放到一个单独的namespace上,但是应用程序日志比较多时对应的hdfs rpc队列经常被打满,如果支持多重挂载,我们就可以均衡这种数据
RBF优点:
1、集中式管理,不需要将所有的配置都下发到客户端
2、支持热加载无需重启服务
3、支持跨集群的mv,rename操作等(在社区基础上自研功能)
4、配合不同的策略可以使用多重挂载
但是在从viewfs升级到RBF的过程中我们遇到了很多问题,修复了80+bug,也增加了很多功能:
跨挂载点删除数据需要走distcp,我们改造成直接把数据删除到对应的namespace上这样可以避免走distcp缩短删除数据时间
跨挂载点移动数据的时候对于超过10G大文件或者文件比较多的话走dsctcp拷贝任务,对于单个文件或者1G以下的文件直接走客户端拷贝
增加了rbf balance失败的时候一键重置的功能
3. 利用大数据治理大数据平台
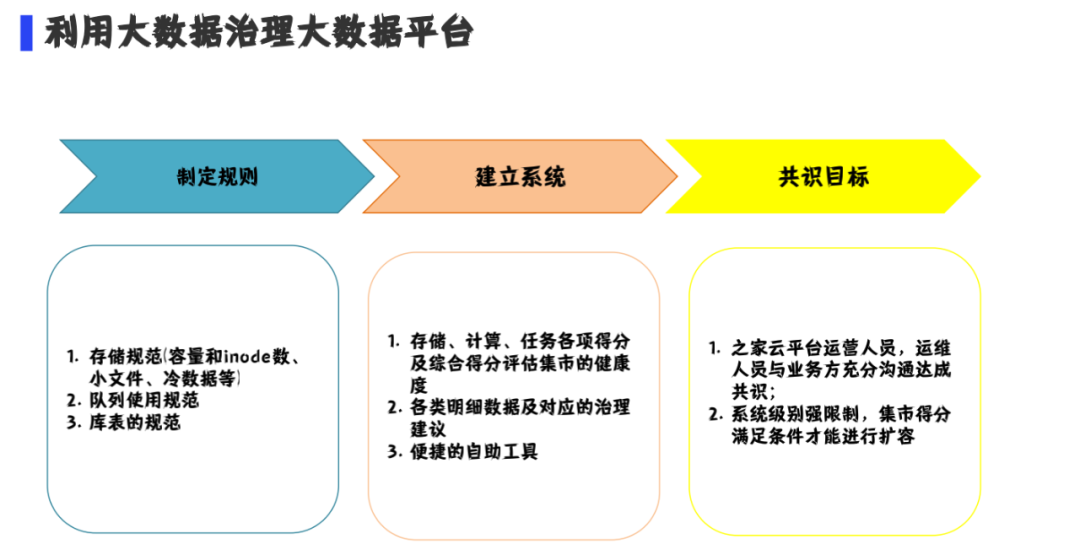
用户在使用过程中会有很多不规范的行为,最初是由平台来兜底进行解决问题。刚开始工作量不大,平台还能承受。发展到后期我们筋疲力尽。最终经过讨论我们通过制定规范来规范用户的行为,建立系统来监管用户行为以纠正不规范的行为,通过各个规范的评分来评估客户使用是否合理,通过大数据的方式来治理大数据平台。
(1) 制定规范
(2)建立系统
(3) 共识目标
制定规范:
1.存储规范:包括团队的容量,inode配额,小文件的定义以及冷数据的界定等
2.队列使用规范:核心队列,base队列,开发队列,测试队列
3.库表规范:包括库的命名,表的命名,路径信息及建库表的权限等
建立系统:
1.对于存储、计算、任务按照一定的规则计算一个团队的分值,通过综合得分评估集市的健康度;进一步根据集市健康度评估团队使用平台是否合理
2.提供各类明细数据以及治理建议
3.提供便捷的自助工具帮助业务治理每一个团队的各种问题:比如治理小文件工具,自动压缩数据的工具等
共识目标:
1.之家的平台运营人员,运维人员与业务方充分沟通达成共识
2.系统级别进行强限制,比如集市得分满足条件才能进行资源扩容

如图这是我们自己建立的系统,上面有各项得分以及综合评分,最近30天集市健康评分,存储计算,集市健康度分析,我们提供了冷数据占比,小文件占比,未压缩数据占比以及建议等,我们还提供了基于库表的分析,包括基于这些库表查询的分区数文件数等,用户可以基于这些进行快速治理。
4. 提升离线资源提高资源利用率
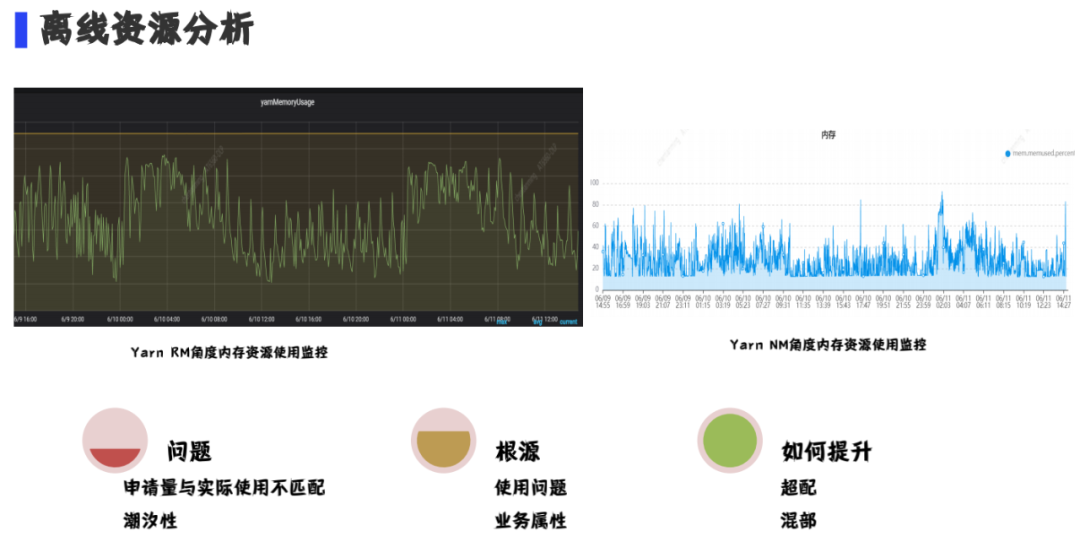
通过长时间的观察,我们发现离线计算有两个特点:
(1) Yarn的资源申请和实际物理机使用不匹配
(2) 潮汐性
(1) 超配 (2)离在线混部
超配+Cgroup优化
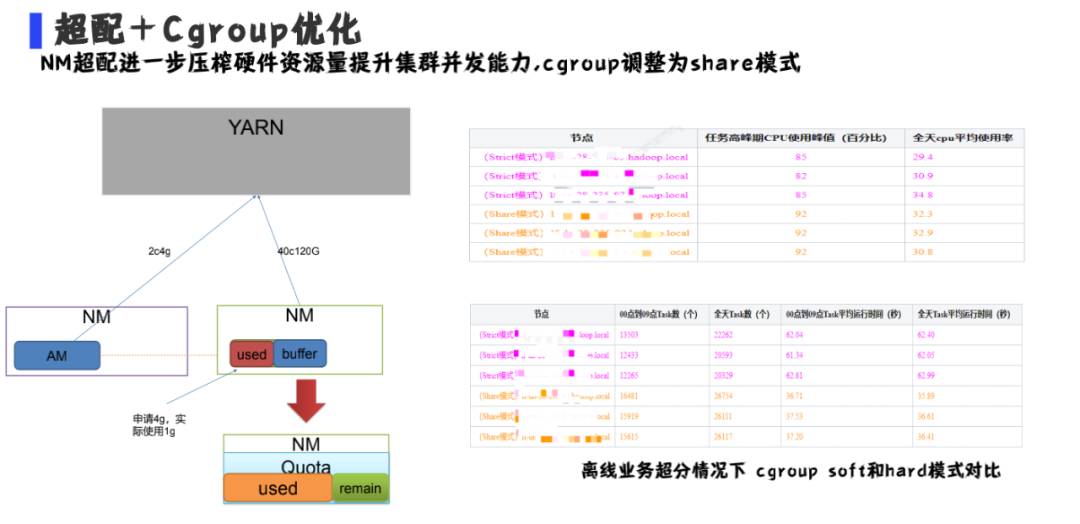
hadoop可以设置虚拟资源和实际物理机资源的一个比例,通过超配可以增加集群的资源量,提高container的并行度。但是我们当时使用的是Cgroup严格资源模式,如果超配达到30%的话,集群的每个continer算力会下降。通过将Cgroup改成share模式,整个集群的cpu使用峰值由原来的82%提高到92%,container计算量也会增加很多,全天的task数据也增加很多,平均运行时间也提高了很多。
离在线混部
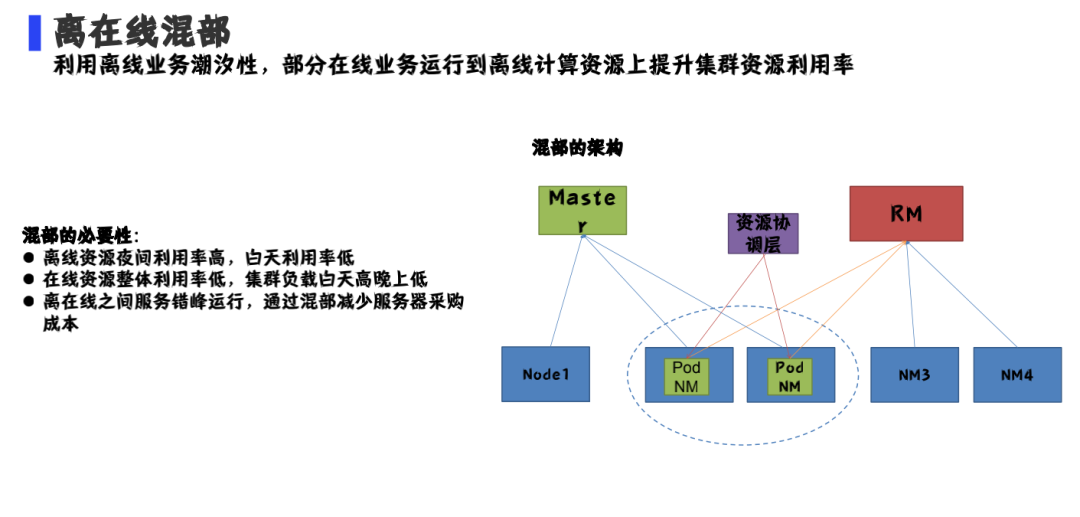 离线计算具有潮汐性,通过部分在线业务迁移到离线计算来提高资源利用率,用离线资源来提供算力。
离线计算具有潮汐性,通过部分在线业务迁移到离线计算来提高资源利用率,用离线资源来提供算力。
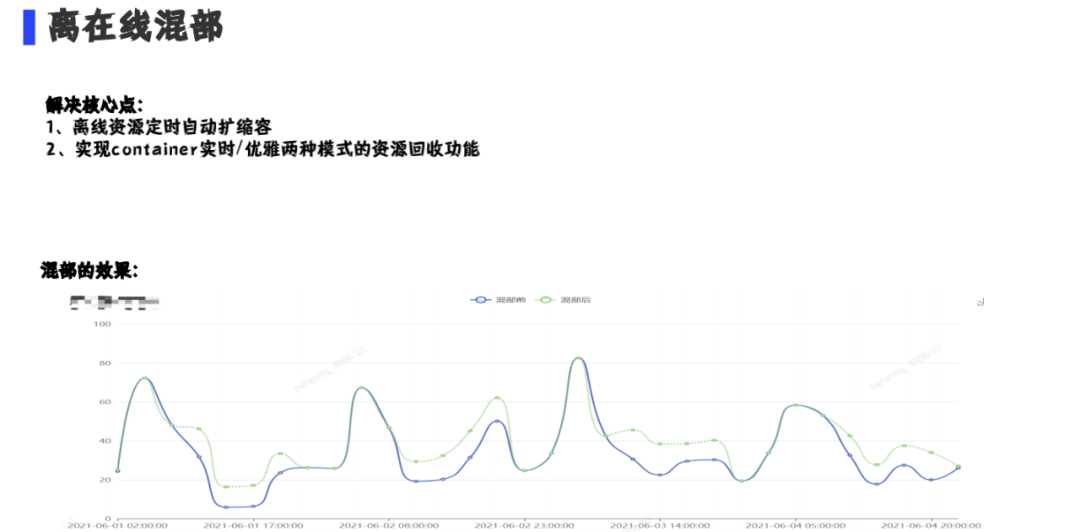
目前解决了两个核心问题:
通过图中可以看到混部之后的效果;当然我们还在开发其他更高级的功能。
▌未来规划
目前集群有两个版本2.7.2和3.2.1接下来我们会将集群全部升级到3.2.1
Namenode读写分离
离在线混部高级功能,比如离在线资源隔离。
Ai on Hadoop:主要想将ai的部分训练迁移到离线集群
▌问答环节
1、Hiveserver2经常OOM的问题,这个问题怎么解决的。Hiveserver2是水平业务部署的吗,如果是怎么使用高可用。
目前我们的业务很少使用hiveserver2,基本上没有使用所以没有遇到过这种问题。
2、Cgroup对于业务使用上有什么影响,是否显示指定资源,这个对于用户是不是有改造成本。
这个对于用户是无感知的,不需要用户单独设置配置信息。我们线上用的Cgroup模式根据业务情况有所不同,离线节点采用超配的方式,为了提高效率采用share模式;实时业务采用严格隔离模式。
3、Ai on hadoop方案和其他方案的对比
人工智能的训练任务主要有两种:cpu训练和gpu训练,有些业务用的cpu比较多gpu比较少,我们做Ai on hadoop主要是先替换这种类型的训练任务提升资源的利用率
4、Hadoop集群是可以不停机升级,你们是滚动升级的吗
我们目前还没有进行升级,其实我们可以在线升级,但是这样还是有风险的;我们rbf功能上线了之后我们会逐步迁移数据来升级,这样比较稳定,对业务没有影响,风险比较低。
嘉宾介绍:
陈天明 汽车之家离线计算平台负责人。2015年加入汽车之家,主导之家离线计算平台的建设;目前专注离线计算相关技术栈研究,对大规模集群的建设和管理有丰富的技术和实战经验。
编辑整理:徐焱森 中经惠众