
【学术相关】CVPR2021最新接收论文合集!22个方向100+篇论文汇总|持续更新
导读
CVPR2021结果已出,本文为CVPR最新接收论文的资源汇总贴,附有相关文章与代码链接。
https://github.com/extreme-assistant/CVPR2021-Paper-Code-Interpretation/blob/master/CVPR2021.md
官网链接:http://cvpr2021.thecvf.com
时间:2021年6月19日-6月25日
论文接收公布时间:2021年2月28日
1.CVPR2021接受论文/代码分方向整理
分类目录:
检测
图像目标检测(Image Object Detection)
[7] Semantic Relation Reasoning for Shot-Stable Few-Shot Object Detection(小样本目标检测的语义关系推理)
paper:https://arxiv.org/abs/2103.01903
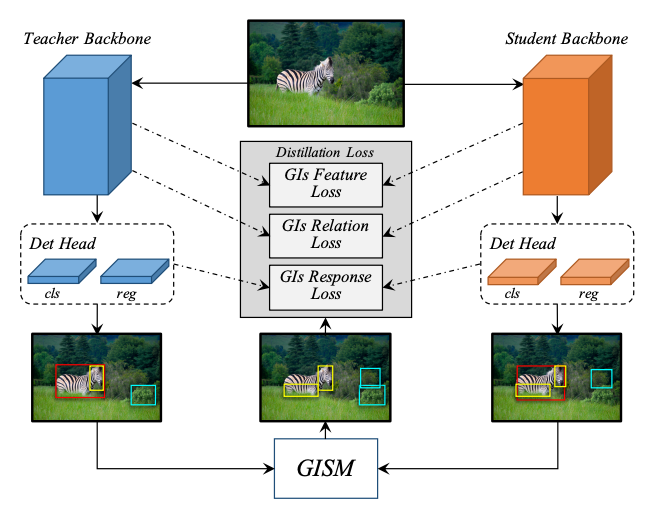
[6] General Instance Distillation for Object Detection(通用实例蒸馏技术在目标检测中的应用)
paper:https://arxiv.org/abs/2103.02340
[5] Instance Localization for Self-supervised Detection Pretraining(自监督检测预训练的实例定位)
paper:https://arxiv.org/pdf/2102.08318.pdf
code:https://github.com/limbo0000/InstanceLoc
[4] Multiple Instance Active Learning for Object Detection(用于对象检测的多实例主动学习)
paper:https://github.com/yuantn/MIAL/raw/master/paper.pdf
code:https://github.com/yuantn/MIAL
[3] Towards Open World Object Detection(开放世界中的目标检测)
paper:Towards Open World Object Detection
code:https://github.com/JosephKJ/OWOD
[2] Positive-Unlabeled Data Purification in the Wild for Object Detection(野外检测对象的阳性无标签数据提纯)
[1] UP-DETR: Unsupervised Pre-training for Object Detection with Transformers
paper:https://arxiv.org/pdf/2011.09094.pdf
解读:
无监督预训练检测器:https://www.zhihu.com/question/432321109/answer/1606004872
视频目标检测(Video Object Detection)
[3] Depth from Camera Motion and Object Detection(相机运动和物体检测的深度)
paper:https://arxiv.org/abs/2103.01468
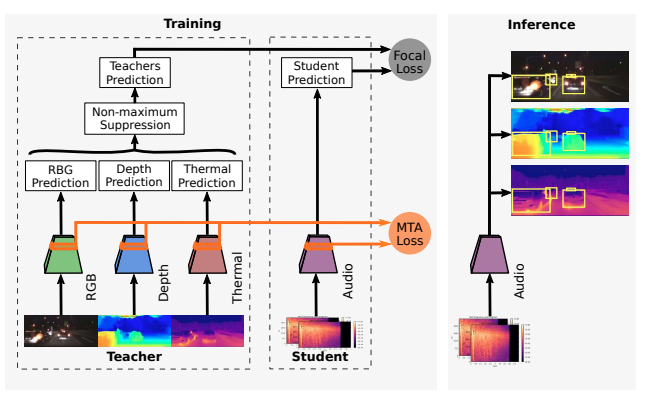
[2] There is More than Meets the Eye: Self-Supervised Multi-Object Detection and Tracking with Sound by Distilling Multimodal Knowledge(多模态知识提取的自监督多目标检测与有声跟踪)
paper:https://arxiv.org/abs/2103.01353
project:http://rl.uni-freiburg.de/research/multimodal-distill
[1] Dogfight: Detecting Drones from Drone Videos(从无人机视频中检测无人机)
三维目标检测(3D object detection)
[2] 3DIoUMatch: Leveraging IoU Prediction for Semi-Supervised 3D Object Detection(利用IoU预测进行半监督3D对象检测)
paper:https://arxiv.org/pdf/2012.04355.pdf
code:https://github.com/THU17cyz/3DIoUMatch
project:https://thu17cyz.github.io/3DIoUMatch/
video:https://youtu.be/nuARjhkQN2U
[1] Categorical Depth Distribution Network for Monocular 3D Object Detection(用于单目三维目标检测的分类深度分布网络)
paper:https://arxiv.org/abs/2103.01100
动作检测(Activity Detection)
[1] Coarse-Fine Networks for Temporal Activity Detection in Videos
paper:https://arxiv.org/abs/2103.01302
异常检测(Anomally Detetion)
[1] Multiresolution Knowledge Distillation for Anomaly Detection(用于异常检测的多分辨率知识蒸馏)
paper:https://arxiv.org/abs/2011.11108
图像分割(Image Segmentation)
[2] Few-Shot Segmentation Without Meta-Learning: A Good Transductive Inference Is All You Need?
paper:https://arxiv.org/abs/2012.06166
code:https://github.com/mboudiaf/RePRI-for-Few-Shot-Segmentation

[1] PointFlow: Flowing Semantics Through Points for Aerial Image Segmentation(语义流经点以进行航空图像分割)
全景分割(Panoptic Segmentation)
[2] Cross-View Regularization for Domain Adaptive Panoptic Segmentation(用于域自适应全景分割的跨视图正则化)
paper:https://arxiv.org/abs/2103.02584
[1] 4D Panoptic LiDAR Segmentation(4D全景LiDAR分割)
paper:https://arxiv.org/abs/2102.12472
语义分割(Semantic Segmentation)
[2] Towards Semantic Segmentation of Urban-Scale 3D Point Clouds: A Dataset, Benchmarks and Challenges(走向城市规模3D点云的语义分割:数据集,基准和挑战)
paper:https://arxiv.org/abs/2009.03137
code:https://github.com/QingyongHu/SensatUrban
[1] PLOP: Learning without Forgetting for Continual Semantic Segmentation(PLOP:学习而不会忘记连续的语义分割)
paper:https://arxiv.org/abs/2011.11390
实例分割(Instance Segmentation)
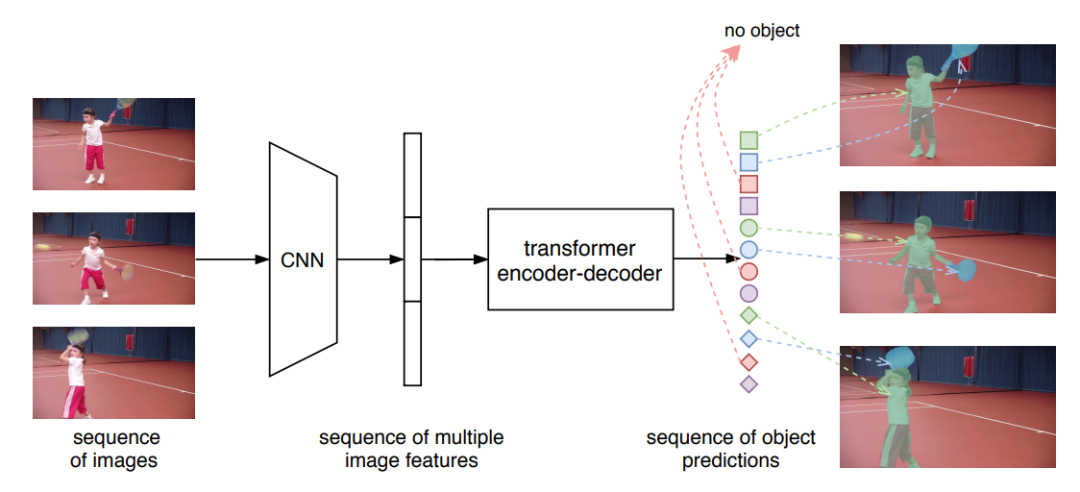
[1] End-to-End Video Instance Segmentation with Transformers(使用Transformer的端到端视频实例分割)
paper:https://arxiv.org/abs/2011.14503
抠图(Matting)
[1] Real-Time High Resolution Background Matting
paper:https://arxiv.org/abs/2012.07810
code:https://github.com/PeterL1n/BackgroundMattingV2
project:https://grail.cs.washington.edu/projects/background-matting-v2/
video:https://youtu.be/oMfPTeYDF9g
9. 估计(Estimation)
人体姿态估计(Human Pose Estimation)
[2] CanonPose: Self-supervised Monocular 3D Human Pose Estimation in the Wild(野外自监督的单眼3D人类姿态估计)
[1] PCLs: Geometry-aware Neural Reconstruction of 3D Pose with Perspective Crop Layers(具有透视作物层的3D姿势的几何感知神经重建)
paper:https://arxiv.org/abs/2011.13607
光流/位姿/运动估计(Flow/Pose/Motion Estimation)
[3] GDR-Net: Geometry-Guided Direct Regression Network for Monocular 6D Object Pose Estimation(用于单眼6D对象姿态估计的几何引导直接回归网络)
paper:http://arxiv.org/abs/2102.12145
code:https://github.com/THU-DA-6D-Pose-Group/GDR-Net
[2] Robust Neural Routing Through Space Partitions for Camera Relocalization in Dynamic Indoor Environments(在动态室内环境中,通过空间划分的鲁棒神经路由可实现摄像机的重新定位)
paper:https://arxiv.org/abs/2012.04746
project:https://ai.stanford.edu/~hewang/
[1] MultiBodySync: Multi-Body Segmentation and Motion Estimation via 3D Scan Synchronization(通过3D扫描同步进行多主体分割和运动估计)
paper:https://arxiv.org/pdf/2101.06605.pdf
code:https://github.com/huangjh-pub/multibody-sync
深度估计(Depth Estimation)
图像处理(Image Processing)
图像复原(Image Restoration)/超分辨率(Super Resolution)
[3] Multi-Stage Progressive Image Restoration(多阶段渐进式图像复原)
paper:https://arxiv.org/abs/2102.02808
code:https://github.com/swz30/MPRNet
[2] Data-Free Knowledge Distillation For Image Super-Resolution(DAFL算法的SR版本)
[1] AdderSR: Towards Energy Efficient Image Super-Resolution(将加法网路应用到图像超分辨率中)

paper:https://arxiv.org/pdf/2009.08891.pdf
code:https://github.com/huawei-noah/AdderNet
解读:华为开源加法神经网络
图像阴影去除(Image Shadow Removal)
[1] Auto-Exposure Fusion for Single-Image Shadow Removal(用于单幅图像阴影去除的自动曝光融合)
paper:https://arxiv.org/abs/2103.01255
code:https://github.com/tsingqguo/exposure-fusion-shadow-removal
图像去噪/去模糊/去雨去雾(Image Denoising)
[1] DeFMO: Deblurring and Shape Recovery of Fast Moving Objects(快速移动物体的去模糊和形状恢复)
paper:https://arxiv.org/abs/2012.00595
code:https://github.com/rozumden/DeFMO
video:https://www.youtube.com/watch?v=pmAynZvaaQ4
图像编辑(Image Edit)
[1] Exploiting Spatial Dimensions of Latent in GAN for Real-time Image Editing(利用GAN中潜在的空间维度进行实时图像编辑)
图像翻译(Image Translation)
[2] Image-to-image Translation via Hierarchical Style Disentanglement
paper:https://arxiv.org/abs/2103.01456
code:https://github.com/imlixinyang/HiSD
[1] Encoding in Style: a StyleGAN Encoder for Image-to-Image Translation(样式编码:用于图像到图像翻译的StyleGAN编码器)
paper:https://arxiv.org/abs/2008.00951
code:https://github.com/eladrich/pixel2style2pixel
project:https://eladrich.github.io/pixel2style2pixel/
人脸(Face)
[5] Cross Modal Focal Loss for RGBD Face Anti-Spoofing(Cross Modal Focal Loss for RGBD Face Anti-Spoofing)
paper:https://arxiv.org/abs/2103.00948
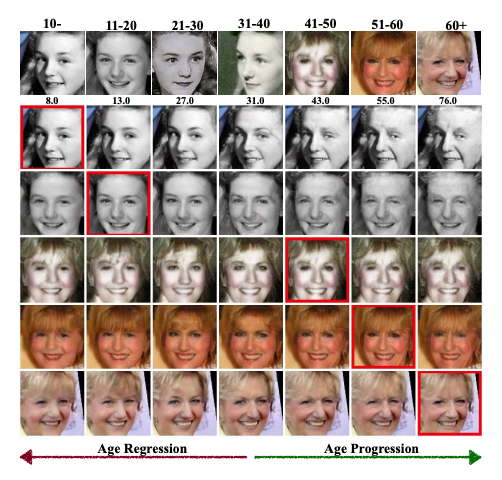
[4] When Age-Invariant Face Recognition Meets Face Age Synthesis: A Multi-Task Learning Framework(当年龄不变的人脸识别遇到人脸年龄合成时:一个多任务学习框架)
paper:https://arxiv.org/abs/2103.01520
code:https://github.com/Hzzone/MTLFace
[3] Multi-attentional Deepfake Detection(多注意的深伪检测)
paper:https://arxiv.org/abs/2103.02406
[2] Image-to-image Translation via Hierarchical Style Disentanglement
paper:https://arxiv.org/abs/2103.01456
code:https://github.com/imlixinyang/HiSD
[1] A 3D GAN for Improved Large-pose Facial Recognition(用于改善大姿势面部识别的3D GAN)
paper:https://arxiv.org/pdf/2012.10545.pdf
目标跟踪(Object Tracking)
[4] HPS: localizing and tracking people in large 3D scenes from wearable sensors(通过可穿戴式传感器对大型3D场景中的人进行定位和跟踪)
[3] Track to Detect and Segment: An Online Multi-Object Tracker(跟踪检测和分段:在线多对象跟踪器)
project:https://jialianwu.com/projects/TraDeS.html
video:https://www.youtube.com/watch?v=oGNtSFHRZJA
[2] Probabilistic Tracklet Scoring and Inpainting for Multiple Object Tracking(多目标跟踪的概率小波计分和修复)
paper:https://arxiv.org/abs/2012.02337
[1] Rotation Equivariant Siamese Networks for Tracking(旋转等距连体网络进行跟踪)
paper:https://arxiv.org/abs/2012.13078
重识别
[1] Meta Batch-Instance Normalization for Generalizable Person Re-Identification(通用批处理人员重新标识的元批实例规范化)
paper:https://arxiv.org/abs/2011.14670
医学影像(Medical Imaging)
[4] Multi-institutional Collaborations for Improving Deep Learning-based Magnetic Resonance Image Reconstruction Using Federated Learning(多机构协作改进基于深度学习的联合学习磁共振图像重建)
paper:https://arxiv.org/abs/2103.02148
code:https://github.com/guopengf/FLMRCM
[3] 3D Graph Anatomy Geometry-Integrated Network for Pancreatic Mass Segmentation, Diagnosis, and Quantitative Patient Management(用于胰腺肿块分割,诊断和定量患者管理的3D图形解剖学几何集成网络)
[2] Deep Lesion Tracker: Monitoring Lesions in 4D Longitudinal Imaging Studies(深部病变追踪器:在4D纵向成像研究中监控病变)
paper:https://arxiv.org/abs/2012.04872
[1] Automatic Vertebra Localization and Identification in CT by Spine Rectification and Anatomically-constrained Optimization(通过脊柱矫正和解剖学约束优化在CT中自动进行椎骨定位和识别)
paper:https://arxiv.org/abs/2012.07947
神经网络架构搜索(NAS)
[3] AttentiveNAS: Improving Neural Architecture Search via Attentive(通过注意力改善神经架构搜索)
paper:https://arxiv.org/pdf/2011.09011.pdf
[2] ReNAS: Relativistic Evaluation of Neural Architecture Search(NAS predictor当中ranking loss的重要性)
paper:https://arxiv.org/pdf/1910.01523.pdf
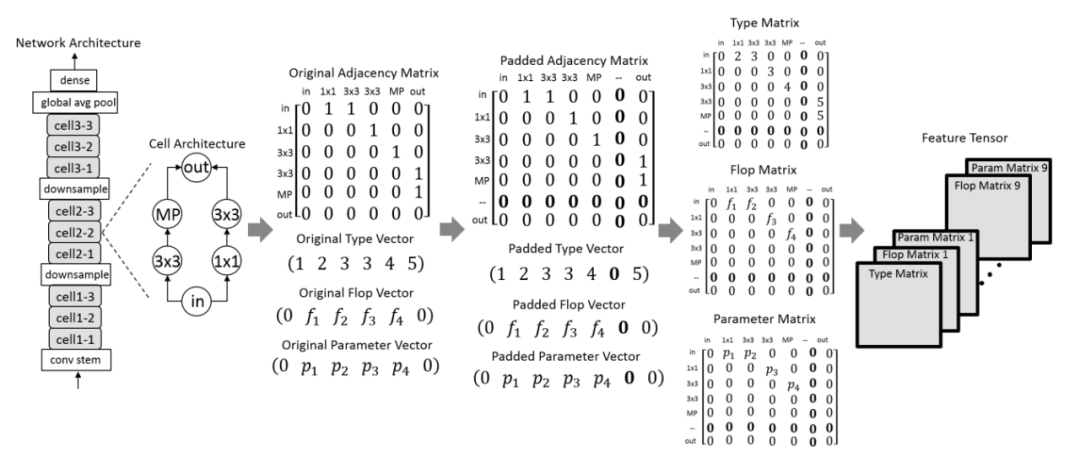
[1] HourNAS: Extremely Fast Neural Architecture Search Through an Hourglass Lens(降低NAS的成本)
paper:https://arxiv.org/pdf/2005.14446.pdf
GAN/生成式/对抗式(GAN/Generative/Adversarial)
[5] Efficient Conditional GAN Transfer with Knowledge Propagation across Classes(高效的有条件GAN转移以及跨课程的知识传播)
paper:https://arxiv.org/abs/2102.06696
code:http://github.com/mshahbazi72/cGANTransfer
[4] Exploiting Spatial Dimensions of Latent in GAN for Real-time Image Editing(利用GAN中潜在的空间维度进行实时图像编辑)
[3] Hijack-GAN: Unintended-Use of Pretrained, Black-Box GANs(Hijack-GAN:意外使用经过预训练的黑匣子GAN)
paper:https://arxiv.org/pdf/2011.14107.pdf
[2] Encoding in Style: a StyleGAN Encoder for Image-to-Image Translation(样式编码:用于图像到图像翻译的StyleGAN编码器)

paper:https://arxiv.org/abs/2008.00951
code:https://github.com/eladrich/pixel2style2pixel
project:https://eladrich.github.io/pixel2style2pixel/
[1] A 3D GAN for Improved Large-pose Facial Recognition(用于改善大姿势面部识别的3D GAN)
paper:https://arxiv.org/pdf/2012.10545.pdf
三维视觉(3D Vision)
[2] A Deep Emulator for Secondary Motion of 3D Characters(三维角色二次运动的深度仿真器)
paper:https://arxiv.org/abs/2103.01261
[1] 3D CNNs with Adaptive Temporal Feature Resolutions(具有自适应时间特征分辨率的3D CNN)
paper:https://arxiv.org/abs/2011.08652
三维点云(3D Point Cloud)
[6] Towards Semantic Segmentation of Urban-Scale 3D Point Clouds: A Dataset, Benchmarks and Challenges(走向城市规模3D点云的语义分割:数据集,基准和挑战)
paper:https://arxiv.org/abs/2009.03137
code:https://github.com/QingyongHu/SensatUrban
[5] SpinNet: Learning a General Surface Descriptor for 3D Point Cloud Registration(SpinNet:学习用于3D点云注册的通用表面描述符)
paper:https://t.co/xIAWVGQeB2?amp=1
code:https://github.com/QingyongHu/SpinNet
[4] MultiBodySync: Multi-Body Segmentation and Motion Estimation via 3D Scan Synchronization(通过3D扫描同步进行多主体分割和运动估计)
paper:https://arxiv.org/pdf/2101.06605.pdf
code:https://github.com/huangjh-pub/multibody-sync
[3] Diffusion Probabilistic Models for 3D Point Cloud Generation(三维点云生成的扩散概率模型)
paper:https://arxiv.org/abs/2103.01458
code:https://github.com/luost26/diffusion-point-cloud
[2] Style-based Point Generator with Adversarial Rendering for Point Cloud Completion(用于点云补全的对抗性渲染基于样式的点生成器)
paper:https://arxiv.org/abs/2103.02535
[1] PREDATOR: Registration of 3D Point Clouds with Low Overlap(预测器:低重叠的3D点云的注册)
paper:https://arxiv.org/pdf/2011.13005.pdf
code:https://github.com/ShengyuH/OverlapPredator
project:https://overlappredator.github.io/
三维重建(3D Reconstruction)
[1] PCLs: Geometry-aware Neural Reconstruction of 3D Pose with Perspective Crop Layers(具有透视作物层的3D姿势的几何感知神经重建)
paper:https://arxiv.org/abs/2011.13607
模型压缩(Model Compression)
[2] Manifold Regularized Dynamic Network Pruning(动态剪枝的过程中考虑样本复杂度与网络复杂度的约束)
[1] Learning Student Networks in the Wild(一种不需要原始训练数据的模型压缩和加速技术)
paper:https://arxiv.org/pdf/1904.01186.pdf
code:https://github.com/huawei-noah/DAFL
解读:
华为诺亚方舟实验室提出无需数据网络压缩技术:https://zhuanlan.zhihu.com/p/81277796
知识蒸馏(Knowledge Distillation)
[3] General Instance Distillation for Object Detection(通用实例蒸馏技术在目标检测中的应用)
paper:https://arxiv.org/abs/2103.02340
[2] Multiresolution Knowledge Distillation for Anomaly Detection(用于异常检测的多分辨率知识蒸馏)
paper:https://arxiv.org/abs/2011.11108
[1] Distilling Object Detectors via Decoupled Features(前景背景分离的蒸馏技术)
神经网络架构(Neural Network Structure)
[3] Rethinking Channel Dimensions for Efficient Model Design(重新考虑通道尺寸以进行有效的模型设计)
paper:https://arxiv.org/abs/2007.00992
code:https://github.com/clovaai/rexnet
[2] Inverting the Inherence of Convolution for Visual Recognition(颠倒卷积的固有性以进行视觉识别)
[1] RepVGG: Making VGG-style ConvNets Great Again
paper:https://arxiv.org/abs/2101.03697
code:https://github.com/megvii-model/RepVGG
解读:
RepVGG:极简架构,SOTA性能,让VGG式模型再次伟大:https://zhuanlan.zhihu.com/p/344324470
Transformer
[3] Transformer Interpretability Beyond Attention Visualization(注意力可视化之外的Transformer可解释性)
paper:https://arxiv.org/pdf/2012.09838.pdf
code:https://github.com/hila-chefer/Transformer-Explainability
[2] UP-DETR: Unsupervised Pre-training for Object Detection with Transformers
paper:https://arxiv.org/pdf/2011.09094.pdf
解读:无监督预训练检测器:https://www.zhihu.com/question/432321109/answer/1606004872
[1] Pre-Trained Image Processing Transformer(底层视觉预训练模型)
paper:https://arxiv.org/pdf/2012.00364.pdf
图神经网络(GNN)
[2] Quantifying Explainers of Graph Neural Networks in Computational Pathology(计算病理学中图神经网络的量化解释器)
paper:https://arxiv.org/pdf/2011.12646.pdf
[1] Sequential Graph Convolutional Network for Active Learning(主动学习的顺序图卷积网络)
paper:https://arxiv.org/pdf/2006.10219.pdf
数据处理(Data Processing)
数据增广(Data Augmentation)
[1] KeepAugment: A Simple Information-Preserving Data Augmentation(一种简单的保存信息的数据扩充)
paper:https://arxiv.org/pdf/2011.11778.pdf
归一化/正则化(Batch Normalization)
[3] Adaptive Consistency Regularization for Semi-Supervised Transfer Learning(半监督转移学习的自适应一致性正则化)
paper:https://arxiv.org/abs/2103.02193
code:https://github.com/SHI-Labs/Semi-Supervised-Transfer-Learning
[2] Meta Batch-Instance Normalization for Generalizable Person Re-Identification(通用批处理人员重新标识的元批实例规范化)
paper:https://arxiv.org/abs/2011.14670
[1] Representative Batch Normalization with Feature Calibration(具有特征校准功能的代表性批量归一化)
图像聚类(Image Clustering)
[2] Improving Unsupervised Image Clustering With Robust Learning(通过鲁棒学习改善无监督图像聚类)
paper:https://arxiv.org/abs/2012.11150
code:https://github.com/deu30303/RUC
[1] Reconsidering Representation Alignment for Multi-view Clustering(重新考虑多视图聚类的表示对齐方式)
模型评估(Model Evaluation)
[1] Are Labels Necessary for Classifier Accuracy Evaluation?(测试集没有标签,我们可以拿来测试模型吗?)
paper:https://arxiv.org/abs/2007.02915
解读:https://zhuanlan.zhihu.com/p/328686799
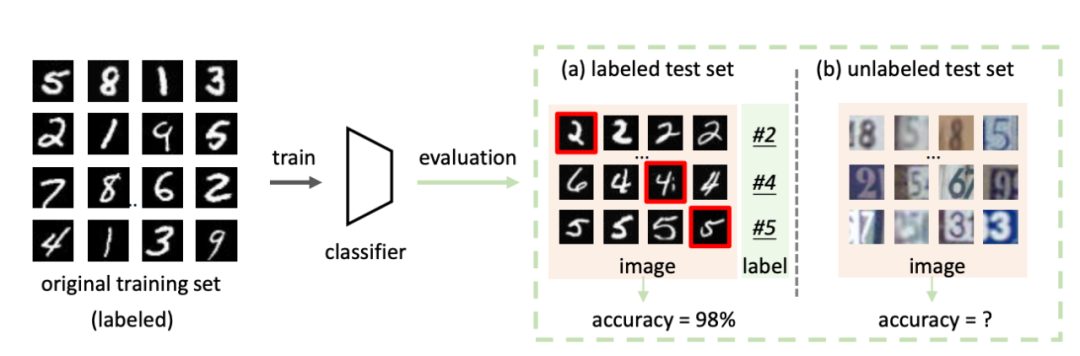
数据集(Database)
[2] Towards Semantic Segmentation of Urban-Scale 3D Point Clouds: A Dataset, Benchmarks and Challenges(走向城市规模3D点云的语义分割:数据集,基准和挑战)
paper:https://arxiv.org/abs/2009.03137
code:https://github.com/QingyongHu/SensatUrban
[1] Re-labeling ImageNet: from Single to Multi-Labels, from Global to Localized Labels(重新标记ImageNet:从单标签到多标签,从全局标签到本地标签)
paper:https://arxiv.org/abs/2101.05022
code:https://github.com/naver-ai/relabel_imagenet
主动学习(Active Learning)
[3] Vab-AL: Incorporating Class Imbalance and Difficulty with Variational Bayes for Active Learning
paper:https://github.com/yuantn/MIAL/raw/master/paper.pdf
code:https://github.com/yuantn/MIAL
[2] Multiple Instance Active Learning for Object Detection(用于对象检测的多实例主动学习)
paper:https://github.com/yuantn/MIAL/raw/master/paper.pdf
code:https://github.com/yuantn/MIAL
[1] Sequential Graph Convolutional Network for Active Learning(主动学习的顺序图卷积网络)
paper:https://arxiv.org/pdf/2006.10219.pdf
小样本学习(Few-shot Learning)/零样本
[5] Few-Shot Segmentation Without Meta-Learning: A Good Transductive Inference Is All You Need?
paper:https://arxiv.org/abs/2012.06166
code:https://github.com/mboudiaf/RePRI-for-Few-Shot-Segmentation

[4] Counterfactual Zero-Shot and Open-Set Visual Recognition(反事实零射和开集视觉识别)
paper:https://arxiv.org/abs/2103.00887
code:https://github.com/yue-zhongqi/gcm-cf
[3] Semantic Relation Reasoning for Shot-Stable Few-Shot Object Detection(小样本目标检测的语义关系推理)
paper:https://arxiv.org/abs/2103.01903
[2] Few-shot Open-set Recognition by Transformation Consistency(转换一致性很少的开放集识别)
[1] Exploring Complementary Strengths of Invariant and Equivariant Representations for Few-Shot Learning(探索少量学习的不变表示形式和等变表示形式的互补强度)
paper:https://arxiv.org/abs/2103.01315
持续学习(Continual Learning/Life-long Learning)
[2] Rainbow Memory: Continual Learning with a Memory of Diverse Samples(不断学习与多样本的记忆)
[1] Learning the Superpixel in a Non-iterative and Lifelong Manner(以非迭代和终身的方式学习超像素)
视觉推理(Visual Reasoning)
[1] Transformation Driven Visual Reasoning(转型驱动的视觉推理)
paper:https://arxiv.org/pdf/2011.13160.pdf
code:https://github.com/hughplay/TVR
project:https://hongxin2019.github.io/TVR/
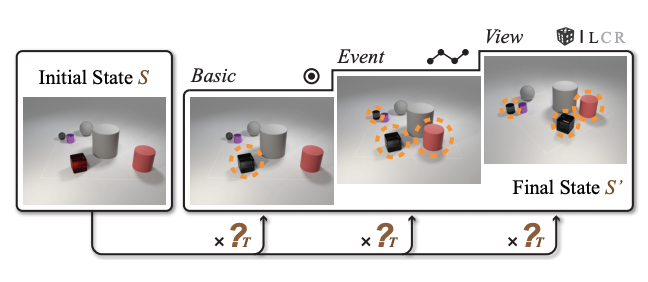
迁移学习/domain/自适应](#domain)
[4] Continual Adaptation of Visual Representations via Domain Randomization and Meta-learning(通过域随机化和元学习对视觉表示进行连续调整)
paper:https://arxiv.org/abs/2012.04324
[3] Domain Generalization via Inference-time Label-Preserving Target Projections(基于推理时间保标目标投影的区域泛化)
paper:https://arxiv.org/abs/2103.01134
[2] MetaSCI: Scalable and Adaptive Reconstruction for Video Compressive Sensing(可伸缩的自适应视频压缩传感重建)
paper:https://arxiv.org/abs/2103.01786
code:https://github.com/xyvirtualgroup/MetaSCI-CVPR2021
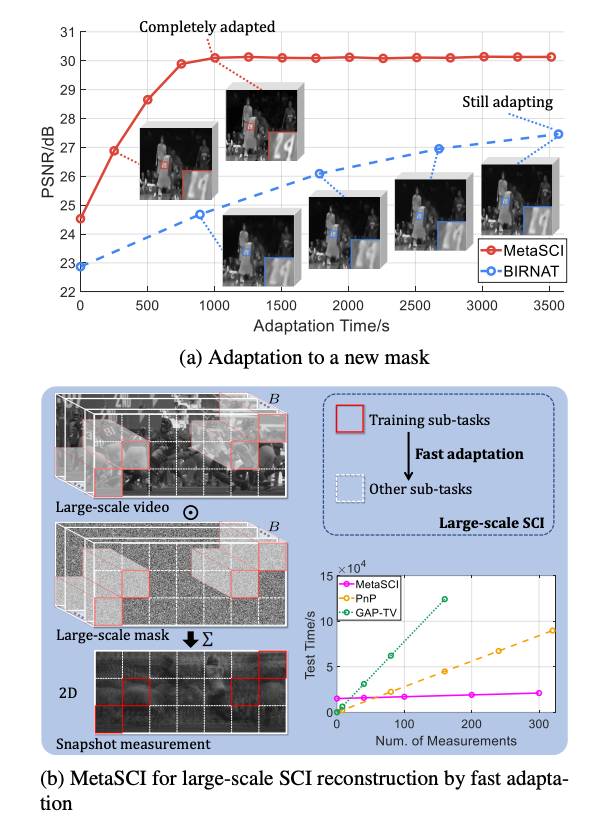
[1] FSDR: Frequency Space Domain Randomization for Domain Generalization(用于域推广的频域随机化)
paper:https://arxiv.org/abs/2103.02370
对比学习(Contrastive Learning)
[1] Fine-grained Angular Contrastive Learning with Coarse Labels(粗标签的细粒度角度对比学习)
paper:https://arxiv.org/abs/2012.03515
暂无分类
Quantifying Explainers of Graph Neural Networks in Computational Pathology(计算病理学中图神经网络的量化解释器)
paper:https://arxiv.org/pdf/2011.12646.pdf
Exploring Data-Efficient 3D Scene Understanding with Contrastive Scene Contexts(探索具有对比场景上下文的数据高效3D场景理解)
paper:http://arxiv.org/abs/2012.09165
project:http://sekunde.github.io/project_efficient
video:http://youtu.be/E70xToZLgs4
Data-Free Model Extraction(无数据模型提取)
paper:https://arxiv.org/abs/2011.14779
Patch-NetVLAD: Multi-Scale Fusion of Locally-Global Descriptors for Place Recognition(用于【位置识别】的局部全局描述符的【多尺度融合】)
paper:https://arxiv.org/pdf/2103.01486.pdf
code:https://github.com/QVPR/Patch-NetVLAD
Right for the Right Concept: Revising Neuro-Symbolic Concepts by Interacting with their Explanations(适用于正确概念的权利:通过可解释性来修正神经符号概念)
paper:https://arxiv.org/abs/2011.12854
Multi-Objective Interpolation Training for Robustness to Label Noise(多目标插值训练的鲁棒性)
paper:https://arxiv.org/abs/2012.04462
code:https://git.io/JI40X
VX2TEXT: End-to-End Learning of Video-Based Text Generation From Multimodal Inputs(【文本生成】VX2TEXT:基于视频的文本生成的端到端学习来自多模式输入)
paper:https://arxiv.org/pdf/2101.12059.pdf
Scan2Cap: Context-aware Dense Captioning in RGB-D Scans(【图像字幕】Scan2Cap:RGB-D扫描中的上下文感知密集字幕)
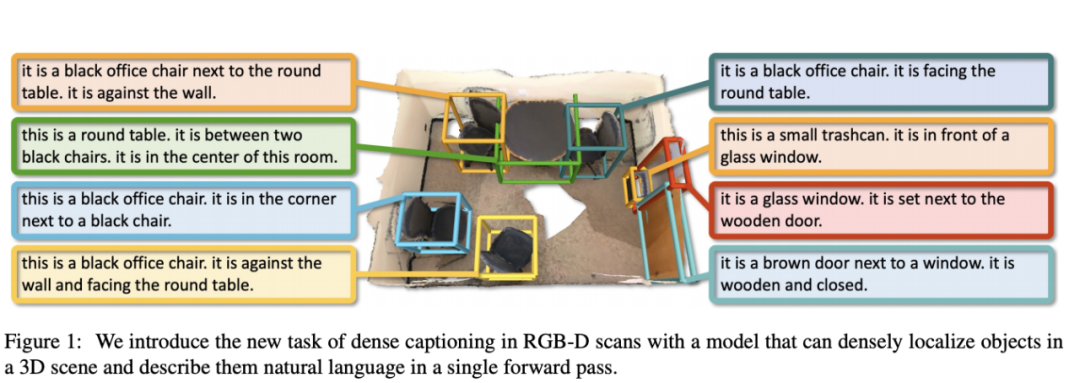
paper:https://arxiv.org/abs/2012.02206
code:https://github.com/daveredrum/Scan2Cap
project:https://daveredrum.github.io/Scan2Cap/
video:https://youtu.be/AgmIpDbwTCY
Hierarchical and Partially Observable Goal-driven Policy Learning with Goals Relational Graph(基于目标关系图的分层部分可观测目标驱动策略学习)
paper:https://arxiv.org/abs/2103.01350
ID-Unet: Iterative Soft and Hard Deformation for View Synthesis(视图合成的迭代软硬变形)
paper:https://arxiv.org/abs/2103.02264
PML: Progressive Margin Loss for Long-tailed Age Classification(【长尾分布】【图像分类】长尾年龄分类的累进边际损失)
paper:https://arxiv.org/abs/2103.02140
Diversifying Sample Generation for Data-Free Quantization(【图像生成】多样化的样本生成,实现无数据量化)
paper:https://arxiv.org/abs/2103.01049
Domain Generalization via Inference-time Label-Preserving Target Projections(通过保留推理时间的目标投影进行域泛化)
paper:https://arxiv.org/pdf/2103.01134.pdf
DeRF: Decomposed Radiance Fields(分解的辐射场)
project:https://ubc-vision.github.io/derf/
Densely connected multidilated convolutional networks for dense prediction tasks(【密集预测】密集连接的多重卷积网络,用于密集的预测任务)
paper:https://arxiv.org/abs/2011.11844
VirTex: Learning Visual Representations from Textual Annotations(【表示学习】从文本注释中学习视觉表示)
paper:https://arxiv.org/abs/2006.06666
code:https://github.com/kdexd/virtex
Weakly-supervised Grounded Visual Question Answering using Capsules(使用胶囊进行弱监督的地面视觉问答)
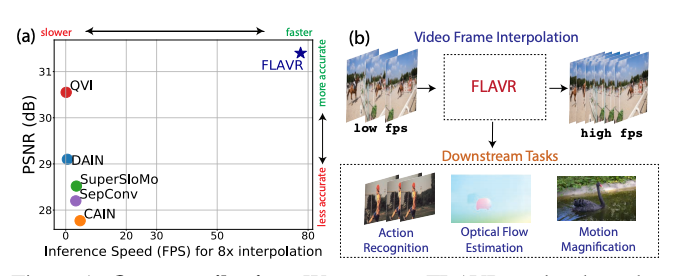
FLAVR: Flow-Agnostic Video Representations for Fast Frame Interpolation(【视频插帧】FLAVR:用于快速帧插值的与流无关的视频表示)
paper:https://arxiv.org/pdf/2012.08512.pdf
code:https://tarun005.github.io/FLAVR/Code
project:https://tarun005.github.io/FLAVR/
Probabilistic Embeddings for Cross-Modal Retrieval(跨模态检索的概率嵌入)
paper:https://arxiv.org/abs/2101.05068
Self-supervised Simultaneous Multi-Step Prediction of Road Dynamics and Cost Map(道路动力学和成本图的自监督式多步同时预测)
IIRC: Incremental Implicitly-Refined Classification(增量式隐式定义的分类)
paper:https://arxiv.org/abs/2012.12477
project:https://chandar-lab.github.io/IIRC/
Fair Attribute Classification through Latent Space De-biasing(通过潜在空间去偏的公平属性分类)
paper:https://arxiv.org/abs/2012.01469
code:https://github.com/princetonvisualai/gan-debiasing
project:https://princetonvisualai.github.io/gan-debiasing/
Information-Theoretic Segmentation by Inpainting Error Maximization(修复误差最大化的信息理论分割)
paper:https://arxiv.org/abs/2012.07287
UC2: Universal Cross-lingual Cross-modal Vision-and-Language Pretraining(【视频语言学习】UC2:通用跨语言跨模态视觉和语言预培训)
Less is More: CLIPBERT for Video-and-Language Learning via Sparse Sampling(通过稀疏采样进行视频和语言学习)
paper:https://arxiv.org/pdf/2102.06183.pdf
code:https://github.com/jayleicn/ClipBERT
D-NeRF: Neural Radiance Fields for Dynamic Scenes(D-NeRF:动态场景的神经辐射场)
paper:https://arxiv.org/abs/2011.13961
project:https://www.albertpumarola.com/research/D-NeRF/index.html
Weakly Supervised Learning of Rigid 3D Scene Flow(刚性3D场景流的弱监督学习)
paper:https://arxiv.org/pdf/2102.08945.pdf
code:https://arxiv.org/pdf/2102.08945.pdf
project:https://3dsceneflow.github.io/
往期精彩回顾
本站qq群704220115,加入微信群请扫码: