关于大数据的完整讲解
1.什么是大数据
1.1 大数据特征
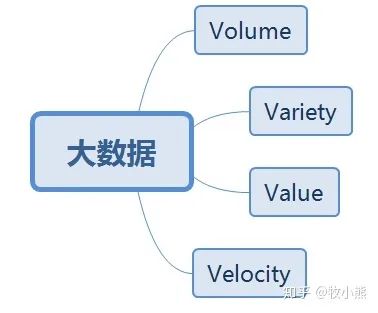
我们引用了大数据的4V特征
Volume 大数据数据量大,数据量单位为T 或者P级 Variety 数据类型多,大数据包含多种数据维度 比如 日志、视频、图片 Value 价值密度低,商业价值高 比如监控视频,其中关键1-2秒可能具有极高的价值 Velocity 要求处理速度块
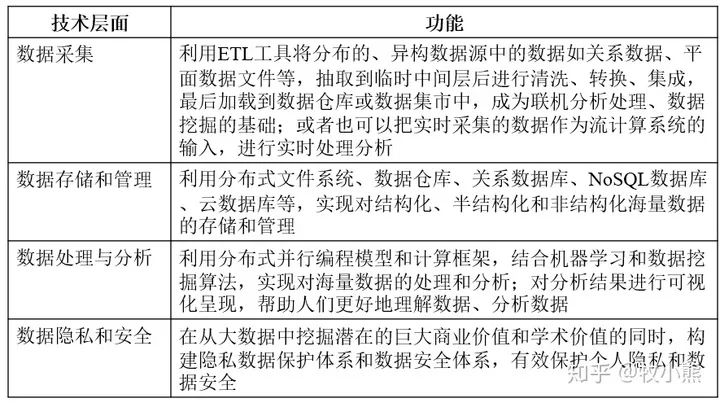
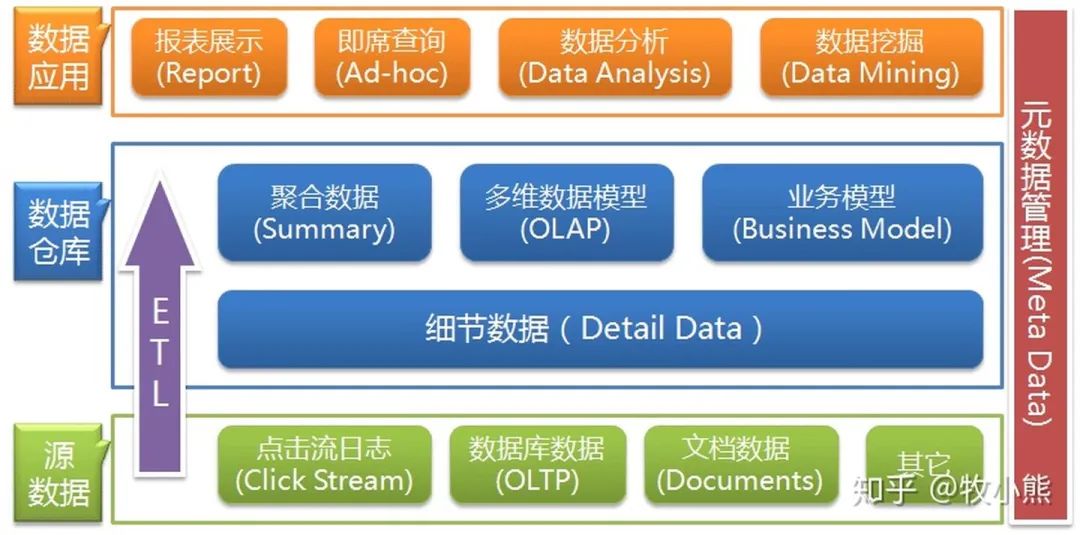
1.2 大数据的4个关键技术
1.3 ETL/ELT的区别
ETL 包含的过程是 Extract、Transform、Load的缩写
包括了数据抽取 => 转换 => 加载三个过程
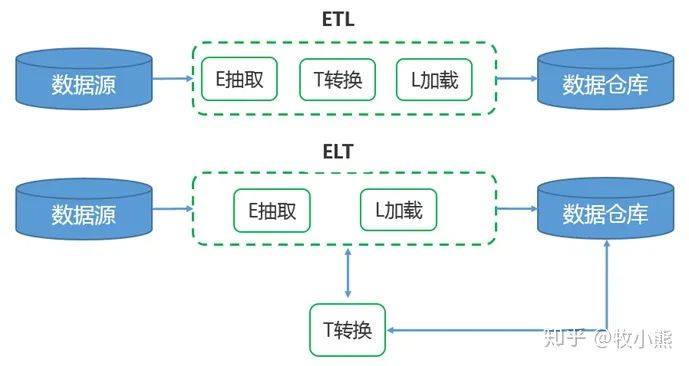
在数据源抽取后首先进行转换,然后将转换的结果写入目的地
ETL 包含的过程是 Extract、Load、Transform的缩写
ELT的过程是,在抽取后将结果先写入目的地,然后利用数据库的聚合分析能力或者外部计算框架,如Spark来完成转换
目前数据主流框架是ETL,重抽取和加载,轻转换,搭建的数据平台属于轻量级
ELT架构,在提取完成之后,数据加载会立即开始,更省时,数据变换这个过程根据后续使用需求在 SQL 中进行,而不是在加载阶段
ELT框架的优点就是保留了原始数据,能够将原始数据展现给数据分析人员
ETL相关软件:
商业软件:Informatica PowerCenter、IBM InfoSphere DataStage、Oracle Data Integrator、Microsoft SQL Server Integration Services等 开源软件:Kettle、DataX、Sqoop
1.4 大数据与数据库管理系统
DataBase Management System,数据库管理系统,可以管理多个数据库
目前关系型数据库在DBMS中占据主流地位,常用的关系型数据库有Oracle、MySQL和SQL Server
其中SQL就是关系型数据库的查询语言
SQL是与数据直接打交道的语言,是与前端、后端语言进行交互的“中台”语言
SQL语言特点:
价值大,技术、产品、运营人员都要掌握SQL,使用无处不在 很少变化,SQL语言从诞生到现在,语法很少变化 入门并不难,很多人都会写SQL语句,但是效率差别很大
除了关系型数据库还有文档型数据库MongoDB、键值型数据库Redis、列存储数据库Cassandra等
提到大数据就不得不说Hive
Hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。
Hive与关联型数据库RDBMS相比
不足:
不能像 RDBMS 一般实时响应,Hive 查询延时大 不能像 RDBMS 做事务型查询,Hive 没有事务机制 不能像 RDBMS 做行级别的变更操作(包括插入、更新、删除)
优点:
Hive 没有定长的 varchar 这种类型,字符串都是 string Hive 是读时模式,保存表数据时不会对数据进行校验,而在读数据时将校验不符合格式的数据设置为NULL
1.5 OLTP/OLAP
在数据仓库架构中有非常相关的2个概念,一个是OLTP,一个是OLAP
OLTP( On-Line Transaction Processing )
联机事务处理,主要是对数据的增删改
记录业务发生,比如购买行为,发生后,要记录是谁在什么时候做了什么事,数据会以增删改的方式在数据库中进行数据的更新处理操作
实时性高、稳定性强,ATM,ERP,CRM,OA等都属于OLTP
OLAP( On-Line Analytical Processing )
联机分析处理,主要是对数据的分析查询
当数据积累到一定的程度,需要做总结分析,BI报表=> OLAP
OLTP产生的数据通常在不同的业务系统中
OLAP需要将不同的数据源 => 数据集成 => 数据清洗 => 数据仓库,然后由数据仓库统一提供OLAP分析
2.大数据计算
2.1 大数据计算模式
| 大数据计算模式 | 解决问题 | 代表产品 |
|---|---|---|
| 批处理计算 | 针对大规模数据的批量处理 | MapReduce、Spark等 |
| 流计算 | 针对流数据的实时计算 | Storm、S4、Flume、Streams、Puma、DStream、Super Mario、银河流数据处理平台 |
| 图计算 | 针对大规模图结构数据的处理 | Pregel、GraphX、Giraph、PowerGraph、Hama、GoldenOrb等 |
| 查询分析计算 | 大规模数据的存储管理和查询分析 | Dremel、Hive、Cassandra、Impala等 |
2.2 Lambda大数据框架

Lambda架构:
Batch Layer(批处理层),对离线的历史数据进行预计算,能让下游进行快速查询。因为基于完整的数据集,准确性能得到保证。可以用Hadoop、Spark 和 Flink 等计算框架
Speed Layer(加速处理层),处理实时的增量数据,加速层的数据不如批处理层完整和准确,但重点在于低延迟。可以用 Spark streaming、Storm 和 Flink 等计框架算
Serving Layer(合并层),将历史数据计算与实时数据计算合并,输出到数据库,供下游分析
2.3 大数据典型技术
Hadoop
一个文件系统,外加一个离线处理框架MapReduce,由于提供的上层api不太友好,加上MapReduce 处理框架比较慢,基本上都用作文件系统
Spark
本身是一个执行引擎,不保存数据,所以需要外部的文件系统(通常会基于hadoop)提出了内存计算的概念,即尽可能把数据放到内存中,还提供了良好的上层使用接口,包括spl语句(spark sql)处理数据十分方便。相比 Hadoop MapReduce 获得了百倍的性能提升,基本上用它来做离线数据处理
Flink
分布式实时计算框架,具有超高的性能,支持Flink流式计算与Storm性能差不多,支持毫秒级计算
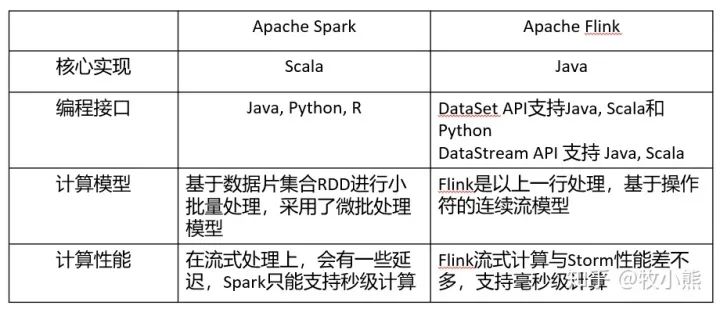
Spark 和 Flink的区别