
线上购物被革命!谷歌最新模型AI一键试衣,细节不变姿势随意换

新智元报道
新智元报道
【新智元导读】谷歌的新AI模型,直接解决了AI换装的两大难题——既保留衣服细节,又能随意换姿势。以后再剁手,恐怕要更容易了!
一键换装,被谷歌给实现了!
这个AI试衣模型TryOnDiffusion,你只要给它一张自己的全身照,和服装模特的照片,就能知道自己穿上这件衣服之后是什么样子了。
主打的就是一个真实。所以,是真人版奇迹暖暖吧?

按说,各种换装的AI早就有不少了,谷歌的这个AI模型究竟有何突破呢?

项目地址:https://tryondiffusion.github.io/
关键就在于,他们提出了一种基于扩散的框架,把两个Parallel-Unet统一了起来。

在以前,这种模型的关键挑战就在于,如何既保留衣服细节,又能将衣服变形,同时还能适应不同主体的姿势和形状,让人感觉不违和。
以前的方法无法同时做到这两点,要么只能保留衣服细节,但无法处理姿势和形状的变化,要么就是可以换姿势,但服装细节会缺失。
而TryOnDiffusion因为统一了两个UNet,就能够在单个网络中保留衣服细节,并且对衣服进行重要的姿势和身体变化。
可以看到,衣服在人物上的变形极其自然,并且衣服的细节也还原得非常到位。
话不多说,让我们直接看看,谷歌的这个「AI试穿」到底有多厉害!




用AI生成试穿图像

虚拟服装试穿中,有许多微妙但对于来说至关重要的细节,比如衣服的垂坠、折叠、紧贴、伸展和起皱的效果。
此前已有的技术,比如geometric warping(几何变形),可以对服装图像进行剪切和粘贴,然后对其进行变形以适配身体的轮廓。
但这些功能,很难让衣服妥帖地适应身体,并且会存在一些视觉缺陷,比如错位的褶皱,会让衣服看起来畸形和不自然。
因此,谷歌的研究者致力于从头开始生成服装的每个像素,以生成高质量、逼真的图像。
他们采用的技术是一种全新的基于Diffusion的AI模型,TryOnDiffusion。
扩散是逐渐向图像添加额外像素(或「噪声」),直到它变得无法识别,然后完全消除噪声,直到原始图像以完美的质量重建。
像Imagen这样的文本到图像模型,就是使用的来自大语言模型LLM的扩散加文本,可以仅根据输入的文本,就能生成逼真的图像。
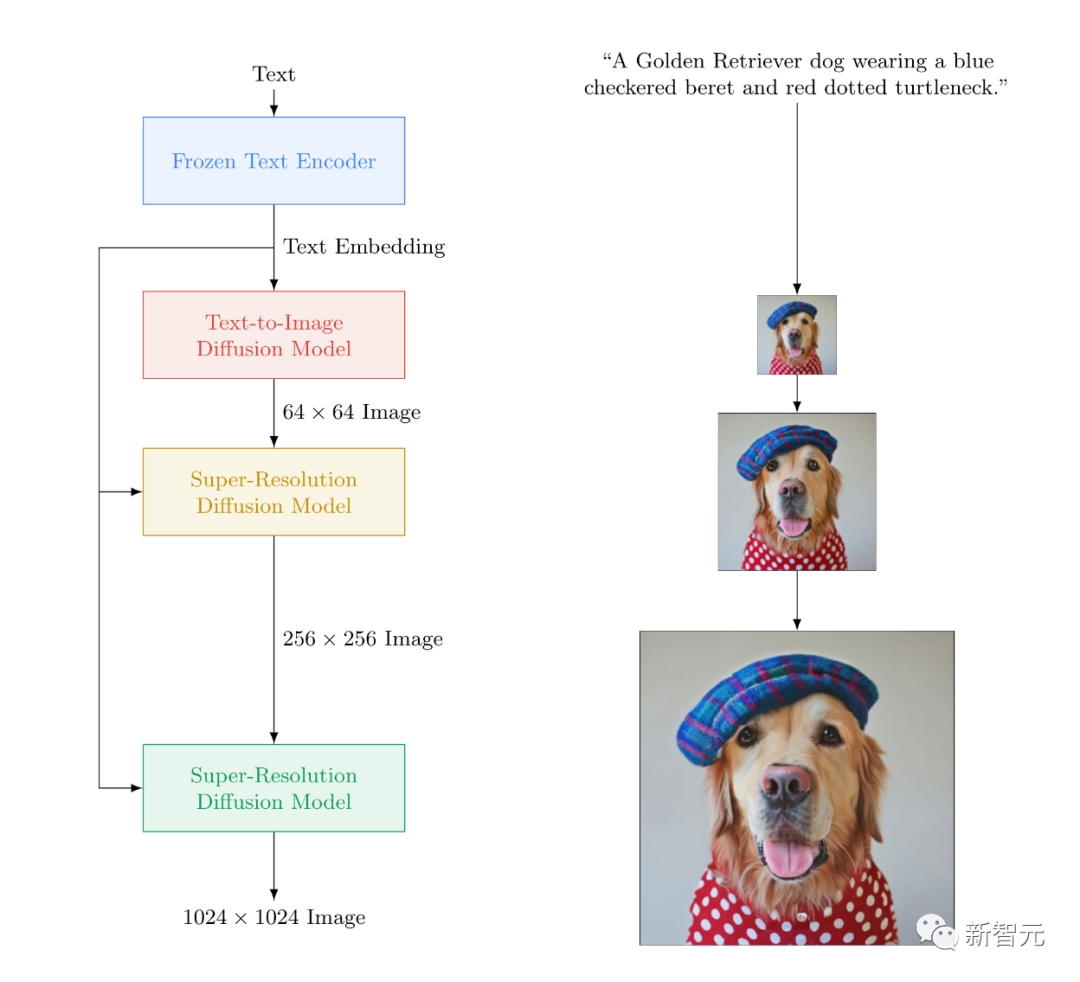
Diffusion是逐渐向图像添加额外像素(或「噪声」),直到它变得无法识别,然后再完全消除噪声,直到原始图像以完美的质量重建。
在TryOnDiffusion中,不需要使用文字,而是使用一组成对的图片:一张图片是衣服(或者穿着衣服的模特),一张图片是模特。
每张图片都会被发送到自己的神经网络(U-net),并通过被称为「交叉注意力」的过程来相互共享信息,输出新的穿着这件衣服的模特的逼真图像。
这种基于图像的Diffusion和交叉注意力的结合技术,构成了这个AI模型的核心。
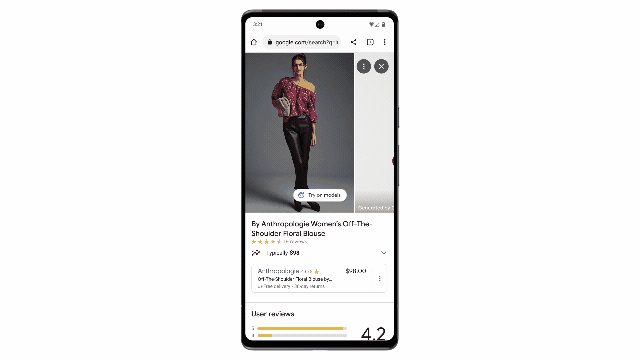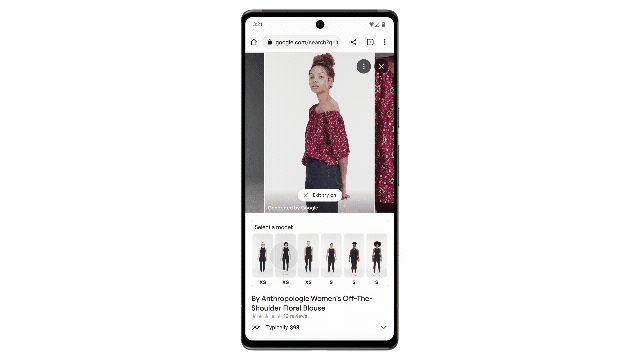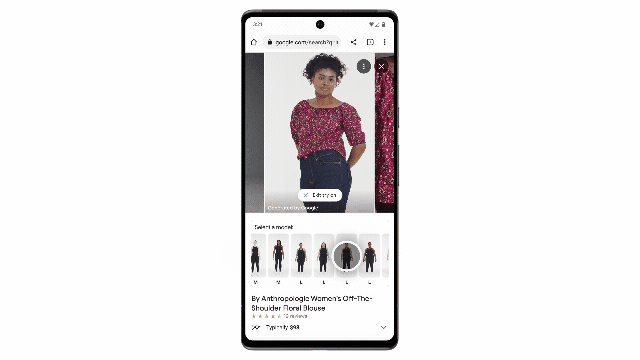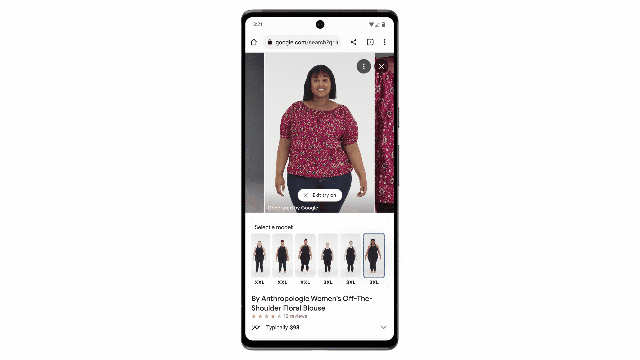
VOT功能让用户可以在符合自己身材的模特身上渲染展示上衣效果。
海量高质量数据训练
这个数据集拥有全世界最全面,同时也是最新的产品、卖家、品牌、评论和库存数据。
谷歌使用了多对图像训练模型,每对图像由两种不同姿势的穿着衣服的模特图组成。
比如,一个穿着衬衫的人侧身站立的图像和另一个向前站立的图像。
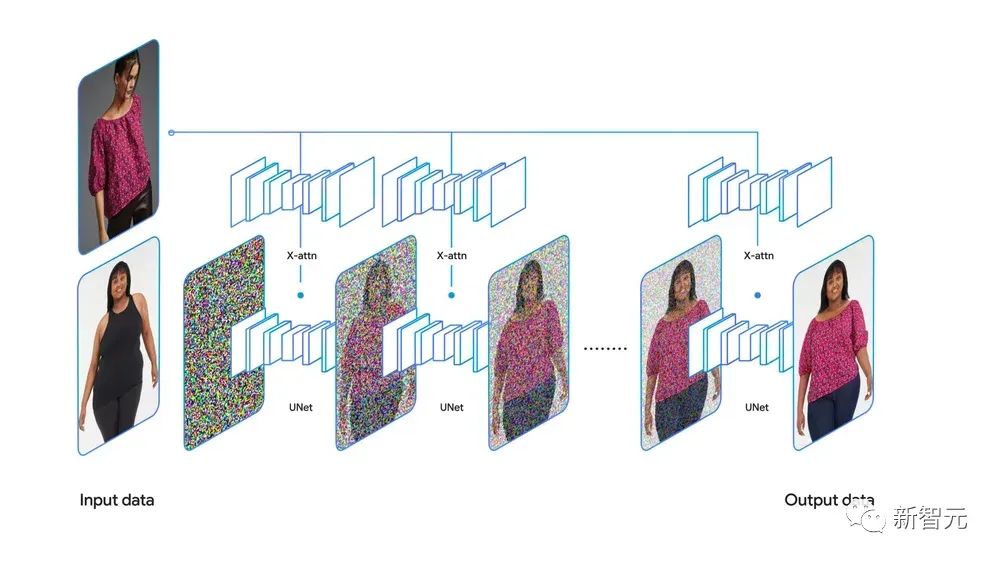
谷歌专门的扩散模型将图像输入到他们自己的神经网络(U-net)来生成输出:穿着这件衣服的模特的逼真图像。
在这对训练图像中,模型学习将侧身姿势的衬衫形状与面朝前姿势的图相匹配。
反过来也一样,直到它可以从各个角度生成该人穿着衬衫的逼真图像。
为了追求更好的效果,谷歌使用数百万不同服装和人物的随机图像对多次重复了这个过程。

结果就是我们在文章开头的图片呈现出来的效果。
总之,TryOnDiffusion既保留了衣服的细节效果,也适配了新模特的身材和姿势,谷歌的技术做到了二者兼得,效果相当逼真。





技术细节
先前的方法要么着重于保留服装细节,但无法有效处理姿势和形状的变化。
要么允许根据期望的体型和姿势呈现出了试穿效果,但缺乏服装的细节。
谷歌提出了一种基于Diffusion的架构,将两个UNet(称为Parallel-UNet)合二为一,谷歌能够在单个网络中保留服装细节并对服装的试穿效果进行明显的姿势和身体变化。
Parallel-UNet的关键思想包括:
1)通过交叉注意机制隐式地为服装制作褶皱;
2)服装的褶皱和人物的融合作为一个统一的过程,而不是两个独立任务的序列。
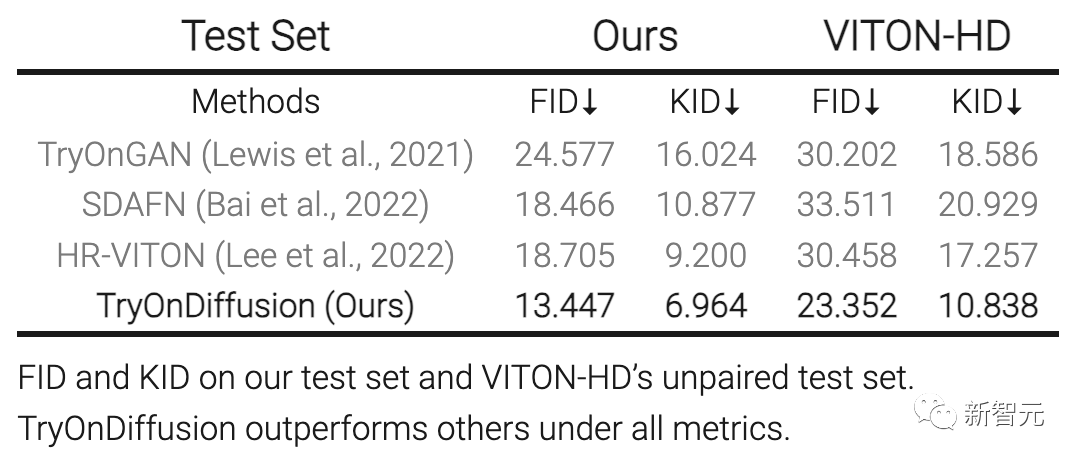
实验结果表明,TryOnDiffusion在定性和定量上均达到了最先进的性能水平。
具体的实现方式如下图所示。
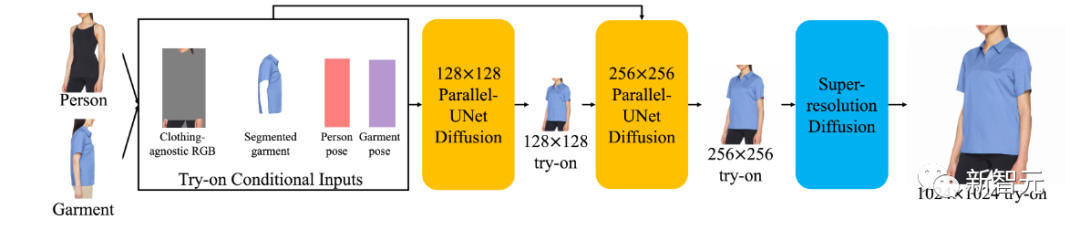
在预处理步骤中,目标人物从人物图像中被分割出来,创建「无服装 RGB」图像,目标服装从服装图像中分割出来,并为人物和服装图像计算姿势。
这些信息输入被带入128×128 Parallel-UNet(关键步骤)以创建128x128的试穿图像,该图像与试穿条件的输入一起作为输入进一步发送到256×256 Parallel-UNet中。
再把256×256 Parallel-UNet的输出内容被发送到标准超分辨率扩散(super resolution diffusion)来创建1024×1024的图像。
而在上面整个流程中最为重要的128×128 Parallel-UNet的构架和处理过程,如下图所示。
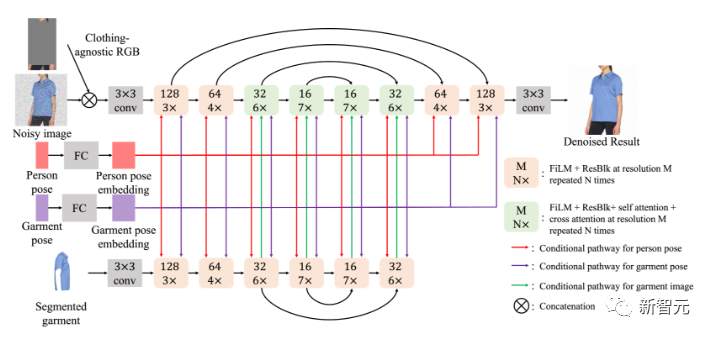
将与服装无关的RGB和噪声图像输入顶部的person-UNet中。
由于两个输入内容都是按像素对齐的,在 UNet 处理开始时直接沿着通道维度(channel demension)将两个图像连接起来。
由于两个输入都是按像素对齐的,我们在 UNet 处理开始时直接沿着通道维度将它们连接起来。
将分割后的服装图像输入位于底部的garment-UNet。
服装的特征通过交叉注意(cross attention)融合到目标图像之中。
为了保存模型参数,谷歌研究人员在32×32上采样(Upsampling)之后提前停止了garment-UNet,此时person-UNet中的最终交叉注意力模块(final cross attention module)已经完成。
人和衣服的姿势首先被送入线性层以分别计算姿势嵌入。
然后通过注意力机制将姿势嵌入融合到person-UNet中。
此外,它们被用在使用FiLM在所有规模上调制两个UNet的特征。
与主流技术的对比
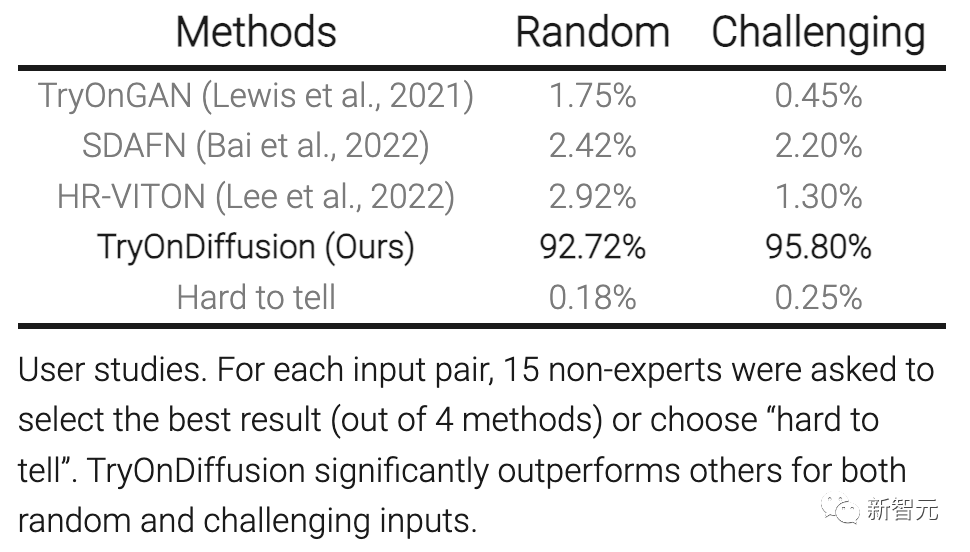
用户调查研究:对于每组输入的图片,15个普通用户选从4个备选技术中选择一个他们认为最好的,或者选择「无法区分」。TryOnDiffusion的表现明显超过了其他技术。
下图从左到右依次是「输入,TryOnGAN,SDAFN,HR-VITON,谷歌的方法」。


局限性
不过TryOnDiffusion存在一些局限性。
首先,在预处理过程中,如果分割图和姿势估计存在错误,谷歌的方法可能会出现服装泄漏的瑕疵。

