
最高花费1700万美元,这是租卡训练谷歌5400亿参数PaLM的成本
视学算法报道
机器之心编辑部
假设我们普通人想用云计算来训练一个 PaLM,我们需要准备多少钱?一位网友算出的结果是:900~1700 万美元。
从去年开始,谷歌人工智能主管 JeffDean 就开始了「谷歌下一代人工智能架构」——Pathways 的预告。与之前为数千个任务训练数千个模型的方法不同,新架构的愿景是训练一个模型做成千上万件事情。
一年之后,Pathways 系统论文终于亮相,Jeff Dean 所在的团队还公布了用它训练的一个大型语言模型——PaLM。实验表明,PaLM 在多语言任务和代码生成方面具有强大的能力,可以出色地完成笑话解读、bug 修复、从表情符号中猜电影等语言、代码任务。
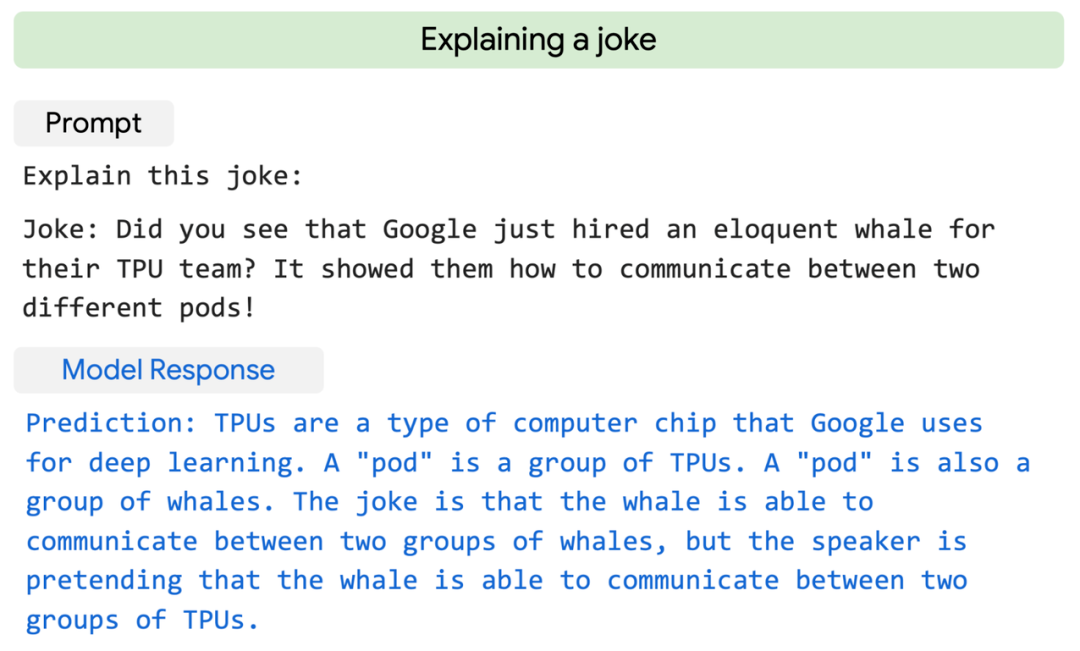
PaLM 解读笑话示例。
PaLM 是一个只有解码器的密集 Transformer 模型,参数量达到了 5400 亿。为了训练这个模型,谷歌动用了 6144 块 TPU,让 Pathways 在两个 Cloud TPU v4 Pods 上训练 PaLM。这是名副其实的「钞能力」。
惊叹之余,有人可能想问:假设我们普通人(不像谷歌那样拥有大量 TPU)想用云计算来训练一个 PaLM,我们需要准备多少钱?一位网友算出的结果是:900~1700 万美元。
我们一起来看一下他是怎么算的。
论文里的可用信息
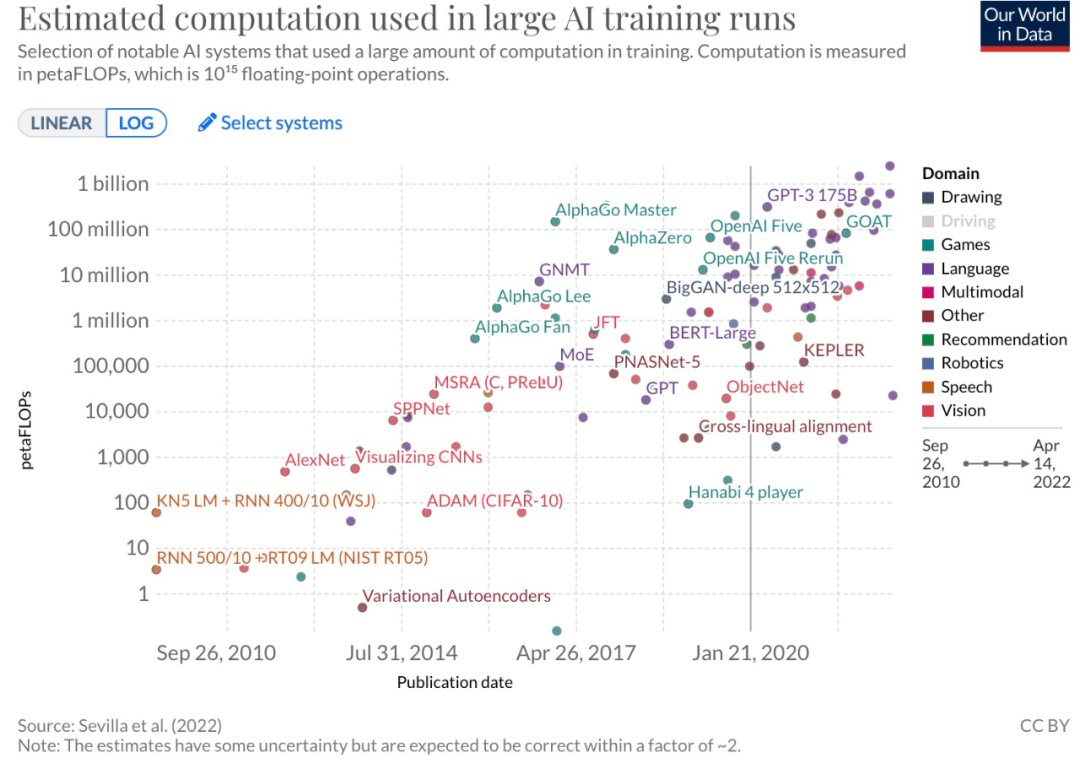
随着参数的增加,ML 模型的计算成本也在飙升。谷歌曾总结过,自 2010 年以来,ML 模型的训练计算量惊人地增长了 100 亿,平均每 6 个月就翻一番。如今,PaLM 站上了 C 位。
论文显示,PaLM 的最终训练运行消耗的算力是 2.56e24 FLOPs。
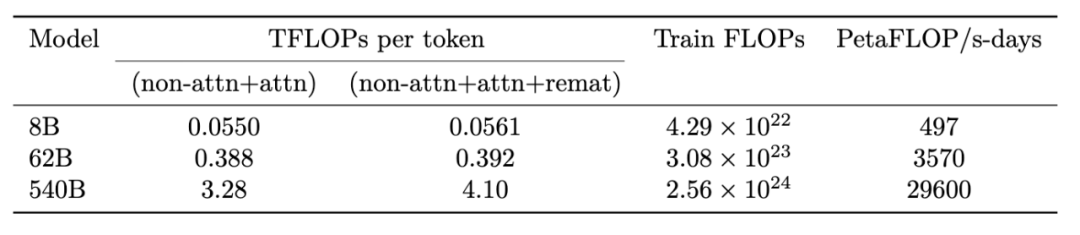
论文还提到,PaLM-540B 在 6144 块 TPU v4 芯片上训练了 1200 小时,在 3072 块 TPU v4 芯片上训练了 336 小时,包括一些停机时间(downtime)和重复步骤。
因此,PaLM-540B 的训练总共花费:
2.56e24 FLOPs;
8404992 个 TPUv4 chip-hour(每个芯片包含 2 个核,约合 16809984 个 TPUv4core-hour);
大约 64 天。
此外,在 TPU 利用率方面,PaLM-540B 的训练使用了 rematerialization,因为带有 rematerialization 的可行批大小可实现更高的训练吞吐量。不考虑 rematerialization 成本,最终模型在没有自注意力机制的情况下 FLOP 利用率为 45.7%,有自注意力为 46.2%。PaLM 的分析计算硬件 FLOPs 利用率(包括 rematerialization FLOPs)为 57.8%。
估算结果
现在有两种方法可以估计 PaLM-540B 的成本:
1、最后训练运行使用 2.56×10²⁴ FLOPs
可以通过租用 TPU 实例来估计每个 flops 的成本(假设利用率为 57.8%)。
从其他云提供商(例如使用 NVIDIA A100 的云提供商)获取每个 FLOP 的成本,然后估计总成本。
2、使用 8404992 个 TPUv4 chip-hour 这一数据
方法 2 似乎更加准确,但遗憾的是,作者没有拿到有关 TPUv4 的租用价格数据(需要咨询销售代表)。

所以,他选择了第一种方法,并按三种方式分别计算了一下。
通过 Google Cloud 租用 TPUv3
我们可以以每小时 32 美元的价格租用一个 32 核的 TPUv3 pod。约合 1 美元一个 TPUcore-hour。
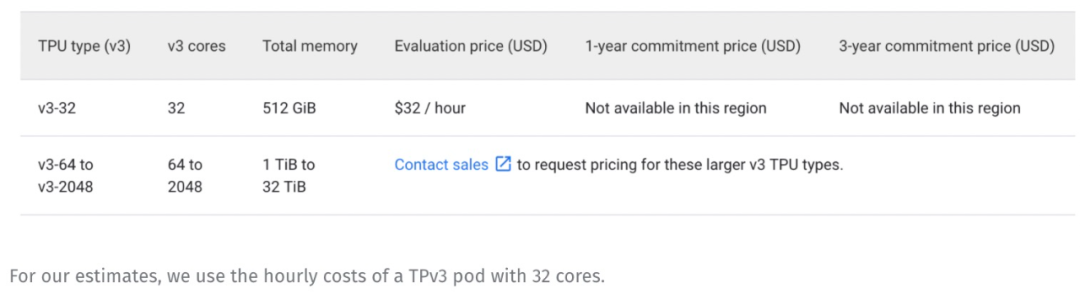
考虑上述 16809984 个 TPUv4core-hour,如果用 TPUv3 替换 TPUv4,则花费约 1700 万美元。
不过这里的估算存在两个问题:
一方面,TPUv3 的性能不如 TPUv4,所以我们需要更多的时间或更多的 TPU。按这个思路计算,实际花费应该高于这个数字;
另一方面,我们经常看到,虽然平台提供的硬件更好了,但价格可能不怎么变化。因此,如果 Google Cloud 给出的 TPUv4 与 TPUv3 的价格大致相同,那么这种估计就是公平的。但如果二者价格相差较大,那么实际成本也会有较大差异。
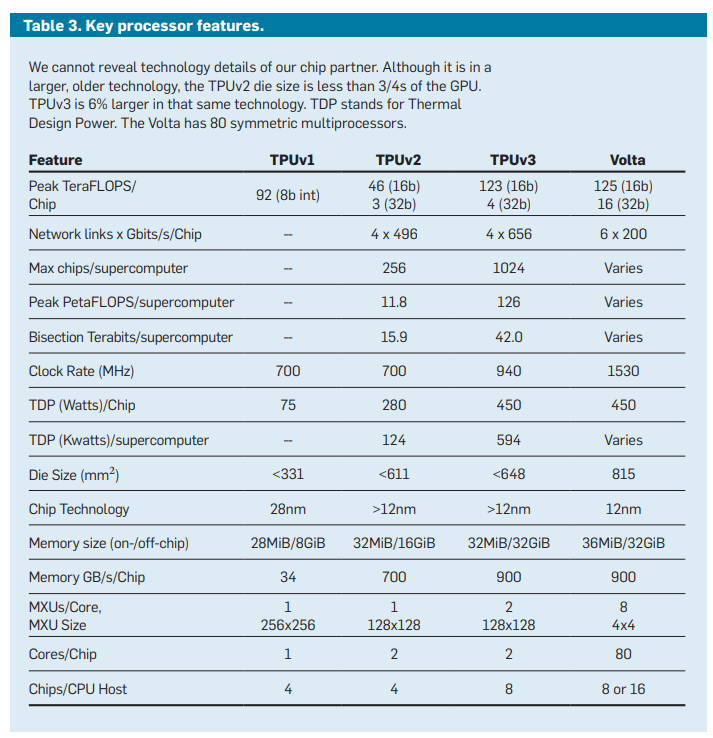
按每 FLOP 的花销算
我们知道,TPUv3 芯片为 bfloat16 提供大约每秒 123 TFLOP(TFLOPS)的算力。当然,这只是表格里显示的峰值性能。
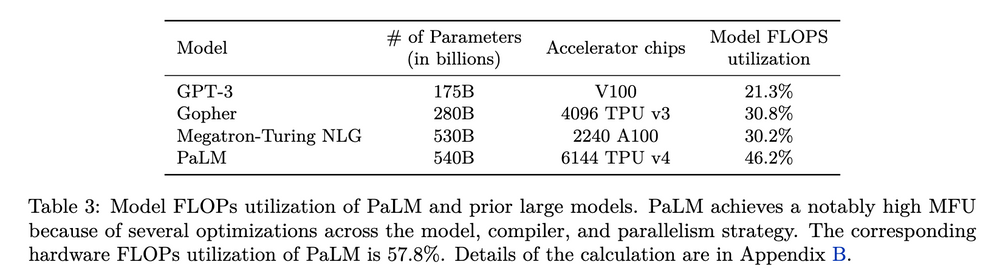
由于不同情况下,硬件的利用率存在差异,所以实际的 TFLOPS 数据往往低于峰值数据。前面说过,PaLM 的 FLOPs 利用率达到了惊人的 57.8%。与之前的诸多模型相比(如下图),这是一项新的记录。

因此,作者假设 PaLM 在 TPU v3 上训练时硬件利用率达到 50%:

按照这个算法,我们每一美元可以买到 221 PFLOPs。考虑到最后一次训练要用 2.56×10^24FLOPs 的算力,我们的最终花费大约是 1160 万美元:
按租用 NVIDIA 显卡算
两年前,有人给 GPT-3 算过一笔账,发现如果使用当时市场上价格最低的 GPU 云(使用 Lambda GPU 实例)来训练 GPT-3,花费最低为 460 万美元。
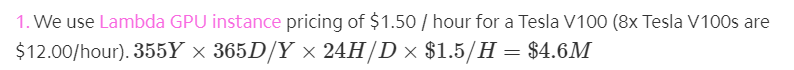
图源:https://lambdalabs.com/blog/demystifying-gpt-3/
如果只考虑 PaLM 的训练计算量是 GPT-3 的 10 倍这一事实,PaLM 的最终训练成本应为 4600 万美元左右。
但是,文章里的数据毕竟是两年前的,而且用的是 Tesla V100。现在的 NVIDIA A100 性能(Tensor 性能)已经提升了一个数量级。
因此,如果按硬件性能提高到原来的 10 倍,利用率是 50% 来计算,PaLM 的训练成本大概是 920 万美元左右。
结论
作者用三种方法估计了 PaLM 的最终训练成本,结果分别为 1700 万美元、1160 万美元和 920 万美元左右。
但需要注意的是:
1、谷歌并不需要花那么多钱,他们拥有硬件。这里是假设终端消费者因租用 TPUv3 pod 训练 PaLM 而向 Google Cloud 支付的钱;
2、如果租用时间比较长,你可以拿到折扣(1 年 37% 的折扣);
3、作者没有 TPUv4 的价格数据,所以使用了 TPUv3 的。
4、这里假设你知道如何高效利用 TPUv3 pod,将利用率提到 50%,这一利用率非常惊人;
5、这里只讨论最后一次训练的成本,不包括其他困难且费钱的工作,如工程、研究、测试等。
参考链接:https://blog.heim.xyz/palm-training-cost/
© THE END
转载请联系原公众号获得授权
投稿或寻求报道:content@jiqizhixin.com

点个在看 paper不断!