
一文全览 | 模仿学习最新进展
点击下方卡片,关注「集智书童」公众号
来源丨专知编辑丨小书童

模仿学习是强化学习与监督学习的结合,目标是通过观察专家演示,学习专家策略,从而加速强化学习。通过引入 任务相关的额外信息,模仿学习相较于强化学习,可以更快地实现策略优化,为缓解低样本效率问题提供了解决方案。近年 来,模仿学习已成为解决强化学习问题的一种流行框架,涌现出多种提高学习性能的算法和技术。通过与图形图像学的最新 研究成果相结合,模仿学习已经在游戏 AI (artificial intelligence)、机器人控制、自动驾驶等领域发挥了重要作用。本综述围 绕模仿学习的年度发展,从行为克隆、逆强化学习、对抗式模仿学习、基于观察量的模仿学习和跨领域模仿学习等多个角度 进行了深入探讨。综述介绍了模仿学习在实际应用上的最新情况,比较了国内外研究现状,并展望了该领域未来的发展方向。报告旨在为研究人员和从业人员提供模仿学习的最新进展,从而为开展工作提供参考与便利。
http://www.cjig.cn/jig/ch/reader/view_abstract.aspx?flag=2&file_no=202301140000005&journal_id=jig
1. 引言
深度强化学习(deep reinforcement learning,DRL) 有着样本效率低的问题,通常情况下,智能体为了 解决一个并不复杂的任务,需要远远超越人类进行 学习所需的样本数。人类和动物天生就有着模仿其 它同类个体的能力,研究表明人类婴儿在观察父母 完成一项任务之后,可以更快地学会该项任务 (Meltzoff 等,1999)。基于神经元的研究也表明,一 类被称为镜像神经元的神经元,在动物执行某一特 定任务和观察另一个体执行该任务的时候都会被激 活(Ferrari 等,2005)。这些现象都启发了研究者希望 智能体能通过模仿其它个体的行为来学习策略,因 此模仿学(imitation learning,IL)的概念被提出。模仿 学习通过引入额外的信息,使用带有倾向性的专家 示范,更快地实现策略优化,为缓解样本低效问题 提供了一种可行的解决途径。
由于模仿学习较高的实用性,其从诞生以来一 直都是强化学习重要的研究方向。传统模仿学习方 法主要包括行为克隆(Bain 和 Sammut,1995)、逆强 化学习(Ng 等,2000)、对抗式模仿学习(Ho 和 Ermon, 2016)等,这类方法技术路线相对简单,框架相对单 一,通常在一些简单任务上能取得较好效果 (Attia and Dayan,2018;Levine,2018)。随着近年来计算 能力的大幅提高以及上游图形图像任务(如物体识 别、场景理解等)的快速发展,融合了多种技术的模 仿学习方法也不断涌现,被广泛应用到了复杂任务, 相关领域的新进展主要包括基于观察量的模仿学习 (Kidambi 等,2021)、跨领域模仿学习(Raychaudhuri 等,2021;Fickinger 等,2021)等。
基于观察量的模仿学习(imitation learning from observation,ILfO)放松了对专家示范数据的要求, 仅从可被观察到的专家示范信息(如汽车行驶的视 频信息)进行模仿学习,而不需要获得专家的具体 动作数据(如人开车的方向盘、油门控制数据) (Torabi 等,2019)。这一设定使模仿学习更贴近现实 情况,使相关算法更具备实际运用价值。根据是否 需要建模任务的环境状态转移动力学(又称为“模 型”),ILfO 类算法可以被分为有模型和无模型两类。其中,有模型方法依照对智能体与环境交互过程中 构建模型的方式,可以进一步被分为正向动态模型 (forward dynamics models)(Edwards 等 , 2019 ;Kidambi 等,2021)与逆向动态模型(inverse dynamics models)(Nair 等,2017;Torabi 等,2018;Guo 等,2019;Radosavovic 等,2021);无模型的方法主要包 括对抗式方法(Merel 等,2017;Stadie 等,2017;Henderson 等,2018) 与奖励函数工程法(Gupta 等, 2017;Aytar 等,2018;Schmeckpeper 等,2021)。
跨领域模仿学习(cross domain imitation learning, CDIL)主要聚焦于研究智能体与专家处于不同领域 (例如不同的马尔可夫决策过程)的模仿学习方法。当前的 CDIL 研究主要聚焦于以下三个方面的领域 差异性(Kim 等,2020):1)状态转移差异(Liu 等, 2019),即环境的状态转移不同;2)形态学差异(Gupta 等,2017),即专家与智能体的状态、动作空间不同;3)视角差异(Stadie 等,2017;Sharma 等,2019;Zweig 和 Bruna,2020),即专家与智能体的观察量不同。根据算法依赖的主要技术路径,其解决方案主要可 以分为:1)直接法(Taylor 等,2007),该类方法关注 形态学差异来进行跨领域模仿,通常使用简单关系 函数(如线性函数)建立状态到状态之间的直接对 应关系;2)映射法(Gupta 等,2017;Sermanet 等, 2018;Liu 等,2018),该类方法寻求不同领域间的 深层相似性,利用复杂的非线性函数(如深度神经 网络)完成不同任务空间中的信息转移,实现跨领 域模仿;3)对抗式方法(Sharma 等,2019;Kim 等, 2020),该类方法通常包含专家行为判别器与跨领域 生成器,通过交替求解最小-最大化问题来训练判别 器和生成器,实现领域信息传递;4)最优传输法 (Papagiannis 和 Li,2020;Dadashi 等,2021;Nguyen 等,2021;Fickinger 等,2021),该类方法聚焦专家 领域专家策略占用测度(occupancy measure)与目标 领域智能体策略占用测度间的跨领域信息转移,通 过最优传输度量来构建策略迁移模型。
当前,模仿学习的应用主要集中在游戏 AI、机 器人控制、自动驾驶等智能体控制领域。图形图像 学方向的最新研究成果,如目标检测(Feng 等,2021;Li 等,2022)、视频理解(Lin 等,2019;Bertasius 等, 2021) 、视频分类 (Tran 等 , 2019) 、视频识别 (Feichtenhofer,2020)等,都极大地提升了智能体的 识别、感知能力,是模仿学习取得新进展与新应用 的重要基石。此外,近年来也有研究者开始探索直 接使用 IL 提高图形/图像任务的性能,如 3D/2D 模 型与图像配准(Toth 等,2018)、医学影像衰减校正 (Kläser 等,2021)、图像显著性预测(Xu 等,2021)等。总体来说,模仿学习与图像处理的有机结合,极大 地拓展了相关领域的科研范围,为许多困难问题的 解决提供了全新的可能性。
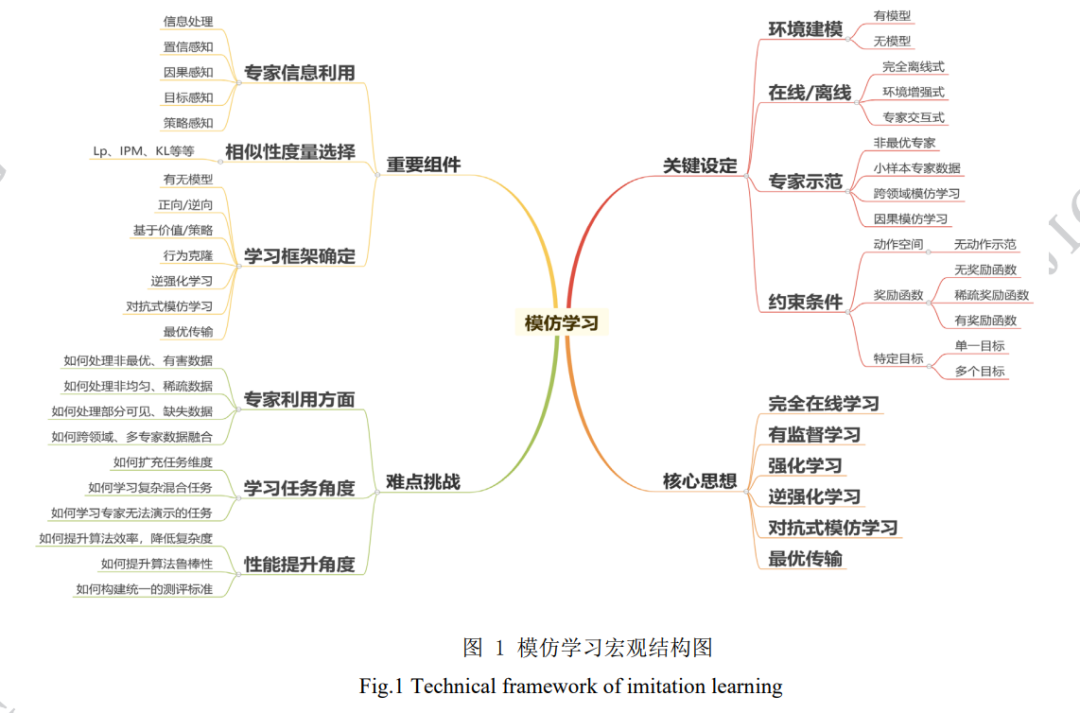
本文的主要内容如下:首先简要介绍模仿学习 概念,同时回顾必要的基础知识;然后选取模仿学 习在国际上的主要成果,介绍传统模仿学习与模仿 学习最新进展,同时也将展现国外最新的研究现状;接着选取国内高校与机构的研究成果,介绍模仿学 习的具体应用,同时也会比较国内外研究的现状;最后将总结本文,并展望模仿学习的未来发展方向 与趋势,为研究者提供潜在的研究思路。本文是第 一个对模仿学习最新进展(即基于观察量的模仿学 习与跨领域模仿学习)进行详细调研的综述,除本 文以外,(Ghavamzadeh 等,2015;Osa,2018;Attia 和 Dayan,2018;Levine,2018;Arora 和 Doshi, 2021)等文章也对模仿学习的其它细分领域进行了 调研。
2 模仿学习新进展
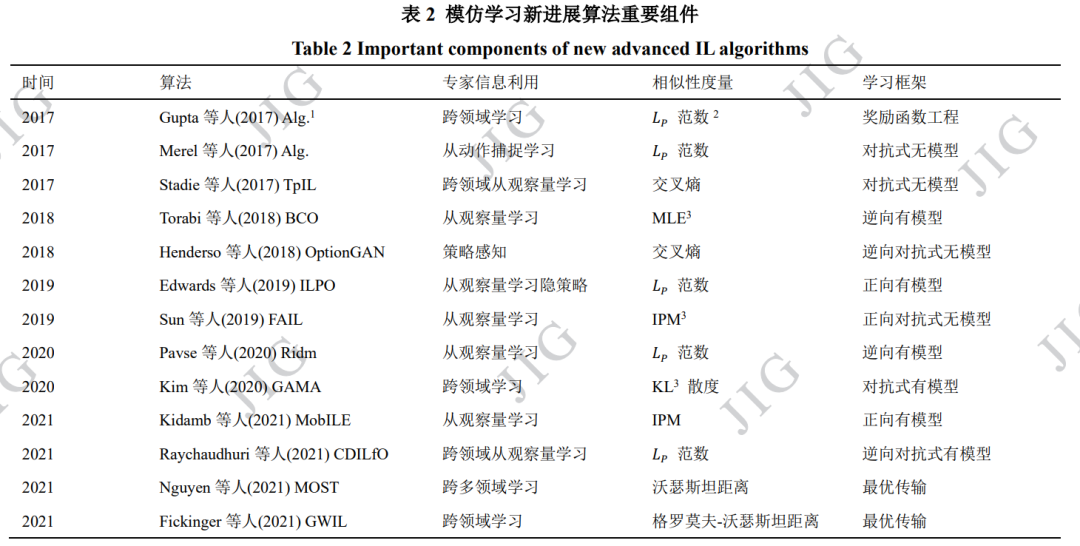
随着强化学习与模仿学习领域研究的不断深入, 近些年模仿学习领域的研究取得了一些瞩目的新进 展,相关的研究不再局限于理论分析与模拟环境, 而是转向更贴近实际的方向,例如:基于观察量的 模仿学习(2.1 节),跨领域模仿学习(2.2 节)。在 这些领域的许多工作,考虑了使用实际数据集进行 模仿学习训练;同时其目标也并非局限于完成 Gym 等模拟环境上提供的标准任务,而是进一步转向模 仿学习算法在机器人控制、自动驾驶等领域的实际 应用,为“模拟到现实”做出了坚实的推进。
2.1 基于观察量的模仿学习
当智能体试图仅通过“观察”来模仿专家的策略 时,就会出现基于观察量的模仿学习(Imitation Learning from Observation,ILfO)这一任务(Torabi 等, 2019)。所谓的“观察”,指的是仅包含状态信息而不 包含动作信息的专家示范,它可以是仅包含状态信 息的轨迹𝝉𝝉𝒆𝒆 = {𝑠𝑠𝑖𝑖}𝑖𝑖=1 𝑀𝑀 ,也可以是单纯的图片或视频。相较于传统模仿学习中既可以获得专家所处的状态, 又可以获得专家在当前状态下的策略(动作)的设 定,ILfO 放松了对专家示范数据的要求,从而成为 了一种更贴近现实情况、更具备实际运用价值的设 定。值得注意的是,ILfO 可以直接使用专家行为的 图片数据作为输入(Liu 等,2018;Torabi 等,2019;Karnan 等,2022),这在引入海量数据集的同时,也 将模仿学习与图像图形学、计算机视觉等领域有机 地结合起来,从而极大地拓展了相关领域的潜在研 究方向,为相关领域的进一步发展开辟了新的土壤。
IL 的目标类似,ILfO 的目标是让智能体通 过模仿仅包含状态信息的专家示范数据,输出一个具有相同行为的策略。既然 ILfO 是一种更贴近现实 的设定,如何从现实的专家行为中获得示范数据是 首先要解决的问题。一些早期的工作通过直接在专 家身上设置传感器的方式记录专家的行为数据 (Ijspeert 等,2001;Calinon 和 Billard,2007)。上述 方法的升级版本是采用动作捕捉技术,专家需要佩 戴专业的动作捕捉设备,这样做的好处是计算机系 统可以直接对专家的行为进行 3 维建模,从而转换 成模拟系统易于识别的输入(Field 等,2009;Merel 等,2017)。随着前些年卷积神经网络在处理图像数 据上大放异彩,现在较为常见的是直接使用摄像头 拍摄专家行为,进而直接使用图像、视频数据作为 输入(Liu 等,2018;Sharma 等,2019;orabi 等,2019;Karnan 等,2022)。由于 ILfO 无法获得专家动作,因此将专家动作 视为状态标签的方法将不再适用,这也使得 ILfO 变 成了更具挑战的任务。一般来说,基于 ILfO 设定的 算法可以被分为有模型和无模型两类。所谓的“模 型”,一般指的是环境的状态转移,通过对智能体与 环境交互过程中学习模型的方式作区分,可以进一 步将有模型的方法分为:正向动态模型(forward dynamics models)与逆向动态模型(inverse dynamics models);无模型的方法主要包括:对抗式方法与奖 励函数工程法。
2.2 跨领域模仿学习
跨领域模仿学习(cross domain imitation learning, CDIL)相关领域的研究最早可以追溯到机器人控制 领域通过观察来让机器人学习策略(Kuniyoshi 等, 1994;Argall 等,2009)。后来随着对 ILfO(章节 2.1) 研究的深入,CDIL 的相关研究也越来越受重视。与 传统设定下的 IL 相比,跨领域模仿学习与现实世界 中的学习过程兼容性更好(Raychaudhuri 等,2021)。传统的 IL 假设智能体和专家在完全相同的环境中 决策,而这一要求几乎只可能在模拟系统(包括游戏) 中得到满足。这一缺点严重地限制了传统 IL 在现实 生活中可能的应用场景,并且将研究者的工作的重心转移到对场景的准确建模,而并非算法本身的性 能上。CDIL 的产生打破了这一枷锁,因为智能体可 以使用不同于自身领域的专家示范来学习策略。当 前 CDIL 所研究的领域差异主要集中在以下三个方 面(Kim 等,2020):1)状态转移差异(Liu 等,2019);2)形态学差异(Gupta 等,2017);3)视角差异(Stadie 等,2017;Sharma 等,2019;Zweig 和 Bruna,2020)。这些差异也对应第 2.1 章中提及的 ILfO 所面临的挑 战。
在模仿学习变得为人熟知之前,这一研究领域 更广泛地被称为迁移学习(Taylor 等,2008)。例如, Konidaris 等人(2006)通过在任务之间共享的状态表 示子集上学习价值函数,来为目标任务提供塑性后 奖励。Taylor 等人(2007)人工设计了一个可以将某一 MDP 对应的动作价值函数转移到另一 MDP 中的映 射来实现知识迁移。直观地说,为了克服智能体环 境和专家环境之间的差异,需要在它们之间建立一 个转移或映射。Taylor 等人 (2008)介绍了一种“直接 映射”的方法,来直接学习状态到状态之间的映射关 系。然而,在不同领域中建立状态之间的直接映射 只能提供有限的转移,因为两个形态学上不同的智 能体之间通常没有完整的对应关系,但这种方法却 不得不学习从一个状态空间到另一个状态空间的映 射(Gupta 等,2017),从而导致该映射关系是病态的。早期的这些方法,大多都需要特定领域的知识,或 是人工构建不同空间之间的映射,这通常会使研究 变得繁琐且泛化性较差,因此必须借助更为先进的 算法来提升性能。随着深度神经网络的发展,更具表达性的神经 网络被广泛运用,CDIL 也迎来了较快的发展。(Gupta 等,2017;Sermanet 等,2018;Liu 等,2018) 等文章研究机器人从视频观察中学习策略,为了解 决专家示范与智能体所处领域不同的问题,他们的 方法借助不同领域间成对的、时间对齐的示范来获 得状态之间对应关系,并且这些方法通常涉及与环 境进行交互的 RL 步骤。相较于“直接映射”的方法, 这些方法学习的映射并不是简单的状态对之间的关 系,而更多利用了神经网络强大的表达性能,从而 取得更好的实验效果。但不幸的是,成对且时间对 齐的数据集很难获得,从而降低了该种方法的可实现性(Kim 等,2020)。
3 模仿学习应用
随着基于观察量的模仿学习与跨领域模仿学习 的不断发展,基于 IL 的算法也越来越符合现实场景 的应用要求,此外,图形图像学上的诸多最新研究 成果,也为 IL 的现实应用进一步赋能。模仿学习的 主要应用领域包括但不限于:1)游戏 AI;2)机器人 控制;3)自动驾驶;4)图像图形学等。本章节将列举 有代表性的模仿学习应用类工作,同时由于现阶段 国内关于模仿学习的研究主要集中在应用领域,因 此本章节将着重选取国内高校、机构的工作成果, 进而为国内该领域的研究者提供一些参考。Gym(Brockman 等,2016)与 Mujoco(Todorov 等, 2012)是强化学习领域被最广泛使用的训练环境,其 为强化学习领域的研究提供了标准环境与基准任务, 使得不同的算法能在相同的设定下比较性能的优劣。模仿学习作为强化学习最为热门的分支领域,也广 泛使用 Gym 与 Mujoco 作为训练/测试环境。Gym 包 含多个基础游戏环境以及雅达利游戏环境,Mujoco 包含多个智能体控制环境同时支持自建任务。值得 注意的是,Gym 与 Mujoco 都包含大量的图像环境, 即以图像的形式承载环境的全部信息,这就使得图 像图形学的众多最新成果,直接推动了模仿学习的 应用。考虑到 Gym 与 Mujoco 的虚拟仿真特性,可 将其归类为游戏环境。这些使用 Gym 与 Mujoco 进 行训练或验证的模仿学习算法,都能在一定程度上 推广到其他游戏领域的应用。国内的诸多高校都在 该方面做出了自己的贡献,包括 清华大学的 Yang 等人(2019)探究了基于逆向动态模型的 IL 算法性能, Jing 等人(2021)验证了分层模仿学习的性能;上海交 通大学的 M.Liu 等人(2020)探究基于能量的模仿学 习算法性能,Liu 等人(2021)探究离线模仿学习算法 COIL(curriculum offline imitation learning)的性能, Liu等人(2022)探究通过解耦策略优化进行模仿学习。南京大学的 Zhang 等人(2022)探究生成式对抗模仿 学习的性能,Xu 等人(2020) 探究模仿策略的误差界 限,Jiang 等人(2020) 探究带误差的模拟器中的离线 模仿学习。
Gym 与 Mujoco 环境之外,模仿学习也被广 泛用于训练棋类与即时战略类游戏 AI。这类游戏任 务的难度显著增加,且通常包含较大信息量的图像数据,因此也会更依赖于先进的图像处理方法(例如 目标检测)。对于这些复杂游戏环境,状态动作空间 过于庞大,奖励信息过于稀疏,智能体通常无法直 接通过强化学习获得策略。进而,智能体首先通过 模仿人类选手的对局示范来学习较为基础的策略, 然后使用强化学习与自我博弈等方式进一步提升策 略。其中最为代表的就是 Google 公司开发的围棋游 戏 AI AlphaGo(Silver 等,2016)以及星际争霸AI Alphastar(Vinyals 等,2019)。与国外的情况相似国内工业界也十分重视该类游戏 AI 的开发,包括 腾 讯公司开发的王者荣耀(复杂的多智能体对抗环境) 游戏 AI(Ye 等,2020);华为公司基于多模式对抗模 仿学习开发的即时战略游戏 AI(Fei 等,2020),如图 3 所示。考虑到该类游戏的超高复杂性,人工智能在 如此复杂的任务中完胜人类对手,可以预见人工智 能在游戏领域完全超越人类已经只是时间问题。在机器人控制领域,由于机器人的价格昂贵, 部件易损且可能具备一定危险性,因此需要一种稳 定的方式获得策略,模仿学习让机器人直接模仿专 家的行为,可以快速、稳定地使其掌握技能,而不依 赖于过多的探索。斯坦福大学的 Abbeel 等人(2006), 早在 2006 年就将逆强化学习方法用在直升机控制 任务上(如图 4 所示)。加州大学伯克利分校的 Nair 等人(2017),结合自监督学习与模仿学习的方法,让 机器人通过模仿专家行为的视频数据,学习完成简 单的任务(如图 5 所示)。国内高校也在该领域做出 了一定的贡献,包括 清华大学的 Fang 等人(2019)调 研了模仿学习在机器人操控方面的研究。中国科学 院大学的 Jiayi Li 等人(2021)通过视频数据进行元模 仿学习以控制机器(如图 6 所示)。中科院自动化所 的 Y. Li 等人(2021)通过视频数据进行模仿学习以精 确操控机器手臂的位置。
自动驾驶是当前人工智能最重要的应用领域 (Grigorescu 等,2020;Kiran 等,2021),模仿学习凭 借其优秀的性能也在该领域占据一席之地,特别是 基于观察量的模仿学习与跨领域模仿学习兼容自动 驾驶的绝大部分现实需求,从而使得 IL 在该领域大 放异彩(Codevilla 等,2018;Bhattacharyya 等,2018Liang 等,2018;Chen 等,2019;Kebria 等,2019;Pan 等,2020)。国内的高校与企业也十分重视模仿 学习在自动驾驶领域的研究,包括 清华大学的 Wu 等人(2018)结合模仿学习进行水下无人设备训练。浙 江大学的 Li 等人(2020)探究了用于视觉导航的基于 无监督强化学习的可转移元技能;Wang 等人(2021) 探究从分层的驾驶模型中进行模仿学习(如图 7 所 示);百度公司的 Zhou 等人(2021)使用模仿学习实现 自动驾驶。北京大学的 Zhu 等人(2021)关于深度强 化学习与模仿学习在自动驾驶领域的应用作了综述。事实上,近年来模仿学习也被直接用于图像处 理上,在图形图像领域发挥出独特的价值。Toth 等 人(2018)探究模仿学习在心脏手术的 3D/2D 模型与 图像配准上的应用。Kläser 等人(2021)研究模仿学习 在改进3D PET/MR(positron emission tomography and magnetic resonance)衰减校正上的应用。北京航天航 空大学的Xu等人(2021)探究了生成对抗模仿学习在 全景图像显著性预测上的应用。在其它领域,模仿学习也有着广泛的应用,包 括电子有限集模型预测控制系统 (Novak 和 Dragicevic,2021)、云机器人系统(B. Liu 等,2020)、 异构移动平台的动态资源管理(Mandal 等,2019)、 多智能体合作环境中的应用(Hao 等,2019)、信息检 索(Dai 等,2021)、移动通信信息时效性(Wang 等, 2022)、黎曼流形(Zeestraten 等,2017)、运筹学 (Ingimundardottir 和 Runarsson,2018)、缓存替换(Liu 等,2020)等。


扫码加入👉「集智书童」交流群
(备注:方向+学校/公司+昵称)




前沿AI视觉感知全栈知识👉「分类、检测、分割、关键点、车道线检测、3D视觉(分割、检测)、多模态、目标跟踪、NerF」
欢迎扫描上方二维码,加入「集智书童-知识星球」,日常分享论文、学习笔记、问题解决方案、部署方案以及全栈式答疑,期待交流!