
结束与开始:为什么 NLP 中间层一定会消亡?
大数据文摘授权转载自安迪的写作间
本篇内容主要源于 Simons Institute 最近 LLM Workshop 中 Dan Klein 的演讲 Are LLMs the Beginning or End of NLP ?
一定程度解答了在上篇文章《选择你的道路》中提到的 “中间层消亡史” ,宏观角度解释后,豁然开朗。
开篇先思考一个问题:LLM 时代,到底是 NLP 的终结,还是 NLP 的开始?
很久很久以前
很久很久以前,也就七八十年前吧,AI 这个概念孕育。在著名的达特茅斯会议之前,已经有些可归类为 AI 的文章或程序了。当然最有影响的还是图灵,50 年发表的 Computing Machinery and Intelligence,当时就已提到了机器学习、强化学习、还有如今越来越过气的图灵测试。
AI 这个词正式诞生,还得五年后,有人(约翰麦卡锡)觉得相关东西多起来了,是时候给大佬们集结起来讨论出点什么,也就是达特茅斯会议,正式启用 Artificial Intelligence 这个词。

早期大量研究还是符号学派,构建程序用数理逻辑来推导证明,当时的 AI 也涉及到大量去用程序证明数学定理。
而给符号学派推到高峰的当然就是专家系统,根据从某个特定领域专业知识中推演出的逻辑规则来回答和解决该领域问题。获得了一定应用,而且因为应用的成功,也掀起了一波热潮,最知名就是日本的第五代计算机计划,希望基于专家系统来造出能与人对话,翻译语言,解释图像,并且像人类一样推理的机器。
结果现在看当然谈不上成功。不成功在于,大家发现这样搞,对于各个方向简单的问题还好,一旦复杂性上去后就根本解决不了,如果强行去解,会发现越往后所制定的各种规则会出现越多自相矛盾的地方,更别提用一套方案解决整个 AI 问题。
大家也就放弃了用一个统一方案解决 AI 问题,而是为了解决各个子方向的问题,分裂成几个子领域。
关于专家系统失败可能图灵早有预料,他说:
it would be easier to create human-level AI by developing learning algorithms and then teaching the machine rather than by programming its intelligence by hand
要创造人类级别的 AI,比起对智能进行手工编程,可能先开发一个学习算法再教机器知识会更简单些。
在各自领域内深入探索后,慢慢随着要解决问题的不同,用到的方法也就不同,于是用到的专业语言也就不同了,各个子领域越发难以沟通,NLP 人讲 Context-free Grammar 讲 Coreference,CV 人讲边缘检测、物体识别等等。
此时,各个领域就变成了,怎么找到该领域下最好的表征(Representation)来解决复杂的实际问题。
NLP 遇上 CL
对 NLP 领域,有一个现成的表征能直接拿来用,那就是语言学,更具体些 Computational Linguistic(计算语言学,CL)。
这两个很易混淆,虽然很多交叉,但追究的终极目的是不一样的。CL 就像很多带 C (Computational)学科,计算社会学、计算生物学,本质上还是语言学,只是用计算的方式来研究,终极目的还是回答关于语言学的问题;而 NLP 更多是个工程学科,目的是怎么通过分析理解(NLU)和生成语言(NLG)来解决工程问题,如机器翻译啊。
不妨就给他俩一开始当作两个学科,而当符号那条路走不通时,NLP 要找到新的表征来解决问题。一看刚好有个 CL,一堆现成东西拿过来就能用。于是 NLP 和 CL 就开始有了大量交叉,很大部分底层都是类似的,不同的是上层要解决的问题。
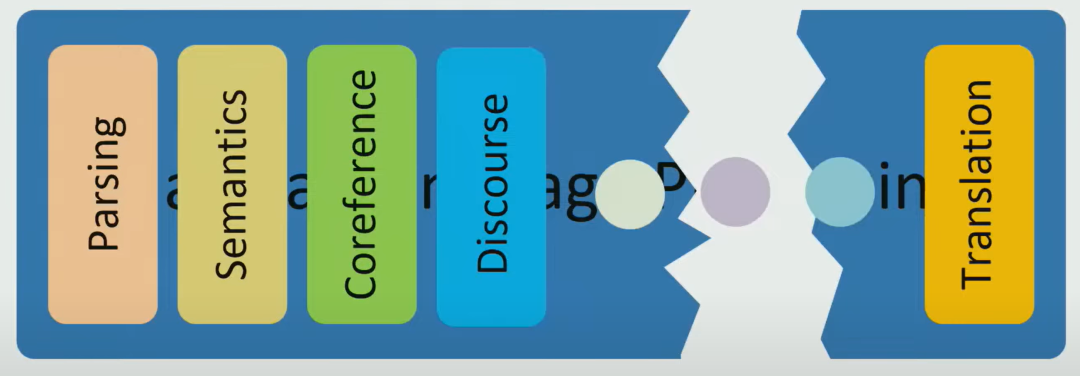
NLP 也随着 CL 的引入,开始出现了和 CL 子领域相关的任务,看十年前的 ACL track 会发现,Syntax、Parsing、Semantic、Discourse、Coreference 分得清清楚楚。究其原因还是 NLP 太难了,你要做语言分析理解和语言生成,那么第一步得先做这些中间任务,获得表征后,再去解决问题。
于是随着 AI 分裂成 NLP、CV 等子领域后,NLP 又因为 CL 的引入,进行了进一步分裂。
Portable General Knowledge(迁移学习)
NLP 或说 AI 领域一个长期目标是,在一个数据源上学到较通用知识,然后用它来泛化解决其他特定问题。
早期 NLP 领域会做 word clustering,有些 Word2Vec 的意思,在一个语料上将类似词聚类,之后特定任务使用。但早期这些方法效果都不是很好,也就不是好的 Portable General Knowledge(PGK)。
直到 Word2Vec 的出现,如上面所说 word2vec 思想很早就有,mikolov 主要解决还是在大量数据上训练的问题。之所以说这个是好的 PGK 的开始,是因为清晰记得,当时做 NLP 就是将之前所有任务,用神经网络方法换上训好的 Word2Vec 向量初始化 Embedding 层,就有提升。
同样模式又出现在 BERT 时代,和 Word2Vec 最大的不同是加入了上下文因素,从 ELMO 双向 LSTM 拼接向量,到 BERT 在 Transformer 上引入 MLM 损失深度双向。于是大家又给所有任务底层替换成 BERT 重做了一遍,这也是很好的 PGK,在通用数据上预训练,然后 finetune 一下就能解决特定任务。那段时间榜单更新非常快,史称“芝麻街的支配”。

但 NLP 仍然是分裂的,大家仍做着各自的任务,刷着各自的榜单。但你如果真问实际解决 NLP 高级任务的人,你想做 parsing 吗,想做 semantic 吗,如果不用做这些就能解决问题你愿意吗,答案必然是愿意。没人真愿意做中间任务。
于是梦想照进现实:LLM 的出现。
LLM 统一 NLP
LLM 消灭的中间层,从前面分裂的角度看,相当于给 NLP 因为 CL 分裂出的各类任务给统一起来了,NLP 又变成了一体,没有了这些中间任务,这里的 PGK 就是 LLM 在预训练中学到的各种知识,而对齐后,连 finetune 都不用做了。
这种一个模型解决所有任务的思想之前没出现过吗?
至少在我印象中,在 cs224n 扩展课中,Richard Socher 就推过 The Natural Language Decathlon,一个模型用统一接口同时解决多个任务,但他当时投还被拒过,前阵子还发 twitter 吐槽。


感觉就是想法太超前了,加上当时不管是硬件,还是模型参数各种 Scaling 都还没起来,所以一起做的各项性能并不高,无法说服大家。如果我是审稿人我可能也会拒绝,反而会觉得是不是想蹭多任务学习热度,给各种任务堆在一起就想发篇论文。
所以重要的是 Timing,顺便一提,Socher 现在是 You.com 的 CEO。
因此当硬件和 Scaling Law 跟上后,也就是 LLM 的出现,这类思想才真正发挥自己的潜力。
随着 Scaling, 还有预训练和下游技巧的积累,各项任务上的指标不断提升,LLM 对老 NLP 范式的冲击也不断增强,直到 ChatGPT 和 GPT4 送出最后的一击,彻底打破横隔在 NLP 子领域之间的墙,完成了对过去分裂 NLP 领域的统一。
这便是 NLP 中间层消亡的必然因素。
NLP 的未来
回到开头那个问题,NLP 终结了吗?
全文看过来的读者,应该会和我齐声说出:No。
终结只是中间任务的终结,NLP 的终极目的还是解决语言理解和生成问题相关的工程问题,这块仍有一大堆要解决的问题。
我们只不过是终于一步迈过了之前的台阶,丢弃掉之前的临时方案。而之后要做的则是在基于 LLM 统一的 NLP 基础上,继续向上向下搭建不同的层级,来更进一步地解决问题。甚至能横向地去统一仍然分裂的 AI 其他子领域。
后 LLM 的 NLP 将是,以 LLM 层为核心,往上会有几层,往下也会有几层,就如计算机网络体系结构一般。

而这些层最终具体会是什么,我也不知道,我之前出于直觉列了些,比如向下 Pretrain、Deployment、Infrastructure,向上 Alignment、Agents、Application、Evaluation. 这些有些可能会对上,但也可能和我想的完全不一样。
毕竟去年这个时候我也绝对不会想到,从去年年底到今年此时,会有如此波澜壮阔的一章。
那么,欢迎来到 NLP 的新时代。

租!GPU云资源
新上线一批A100/A800
运营商机房,服务有保障

扫码了解详情☝
点「在看」的人都变好看了哦!