
mmdetection最小复刻版(十一):概率Anchor分配机制PAA深入分析
AI编辑:深度眸
0 摘要
论文题目:
Probabilistic Anchor Assignment with IoU Prediction for Object Detection
论文地址:
https://arxiv.org/abs/2007.08103
本文思想非常简单,通俗易懂:既然正负样本定义这么重要,并且都存在超参难调先验设置问题,那么我就让正负样本定义全自动化,具体是将正负样本定义建模为2个模态的混合高斯概率分布问题(正负类型两个模态),求解该问题就可以每个样本属于正负样本的概率,再采用简单的切分手段就可以定义正负样本了。
看下图就一目了然:
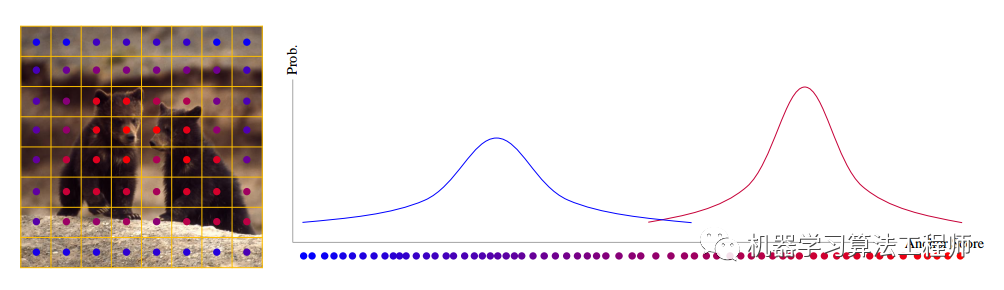
对于特征图上面任意一点,假设我们已经得到了其评估anchor的正样本属性分值,然后采用2个模态的混合高斯分布进行建模,求解该问题就可以得到每个样本相对于正负样本概率了,后面的问题就简单了。
看过我文章的朋友应该都很清楚,在目标检测算法中正负样本定义是一个非常核心问题,特别是在一阶段目标检测中:
(1) faster rcnn和retinanet系列采用通用的iou阈值来区分正负样本,不够鲁棒
(2) dynamic rcnn通过在训练中自适应的提高iou阈值来动态改变正负样本定义,算是一个不错的改进
(3) fcos采用的是回归范围限制和中心扩展系数超参来区分正负样本,超参难以设置
(4) atss提出了基于每层候选anchor,然后计算均值和方差来自适应的计算正负样本,虽然超参就一个但是其实有先验即物体越靠近中心越有可能是正样本,没有做到基于预测值进行自适应功能
(5) yolov3和v4系列采用了iou和网格约束先验来区分正负样本,而v5创新性的采用了宽高比例和邻近网格约束进行区分
上述主流算法,虽然都注意到了正负样本定义问题,并且提出了自己相应的解决办法,但是没有做到真正的基于数据集自适应。本文则从概率分布方面出发,做到了基于预测情况来自适应确定正负样本,即使不管效果,本文思想也是一个进步。
github地址:
https://github.com/hhaAndroid/mmdetection-mini
欢迎star
1 算法实现
1.1 网络结构
首先整体算法采用的是retinanet,不过为了更好评估bbox预测质量,参考前面的相关论文,加入了iou预测分支,都是常规操作。
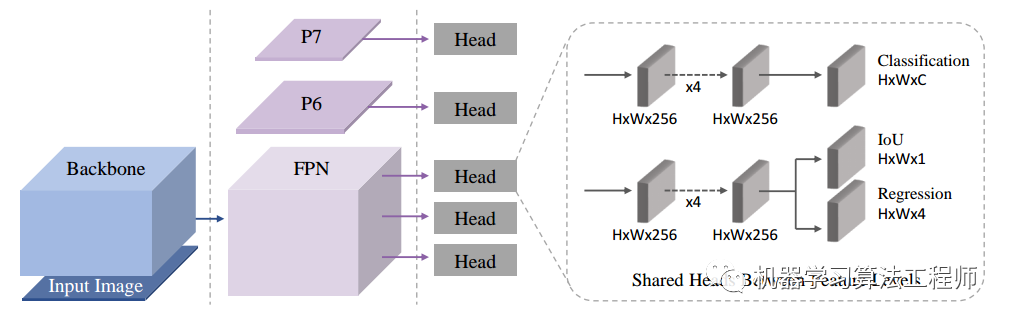
分类分支采用focal loss,bbox回归分支采用giou loss,iou质量评估分支采用bce loss,其label是预测bbox和gt bbox的iou。并且考虑了自适应策略,就不需要那么多anchor了,故和atss论文一样anchor设置为1个。
1.2 定义正负属性分值函数
要构造高斯分布,首先需要找出能够反映每个样本的正负属性分值。假设要我们自己设计,我觉得应该从以下几个方面考虑:
(1) 该分值必须要能够反映出其适合作为正样本的适应度,适应度越高则表示其越适合作为正样本
(2) 该分值最好能够联合3条分支,因为训练时候是三条分支独立训练,但是测试时候是联合测试,采用3条分支进行联合计算,有助于测试阶段,可以最大程度保证一致性
作者做法是:
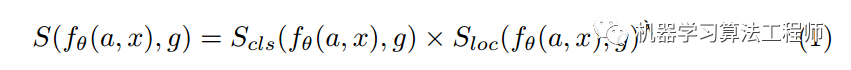
g是gt bbox,f是神经网络,theta是可学习参数,a是anchor,x是图片输入,可以看出anchor分值S应该等于分类分值乘以bbox质量评估分值的gamma次方。分类分值很好算,肯定来自分类分支,而bbox评估分值来自iou分支
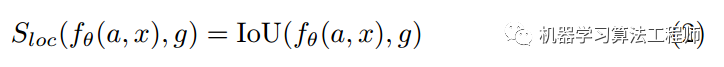
S函数肯定是概率分布格式,因为其范围是0-1,故可以构造最大似然,取负对数形式:
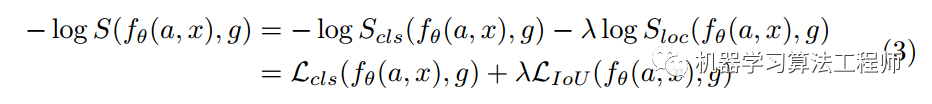
由于分类分支采用bce loss,所以等式后面第一项其实就是分类loss函数,而后一项可以等效为IOU loss(理论上第一行和第二行不是完全相等的,除非iou分支的loss也是bce loss,但是是正相关的)。最终其分值函数S(公式3)可以等效定义为分类Loss加上iou loss(bbox回归还原值和gt bbox计算出的iou loss)乘上系数。
可以发现该公式是满足上面准则:s越小表示越可能是正样本(需要结合后面的高斯建模过程才能理解);利用了三条分支(bbox预测分支已经和iou分支联合训练了)的输出预测情况来联合计算。
在代码层面,为了减少计算量(因为我虽然不知道哪些是正样本,但是对于少数负样本我是很容易确定的),作者首先采用了retinanet里面的MaxIoUAssigner策略先进行初步的正负样本划分,其参数为:
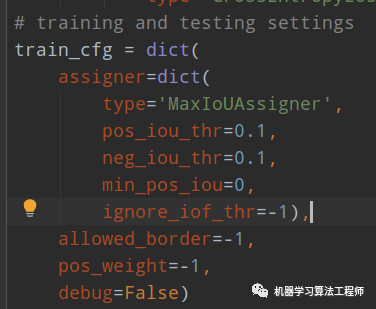
之所以设定阈值如此低就是为了保证负样本一定是背景,没有任何争议。这个操作非常重要,本质上高斯建模面对的样本属于模糊样本或者正样本,而不含纯粹的负样本,否则iou这个地方loss可能一直是0,那么就有问题了。
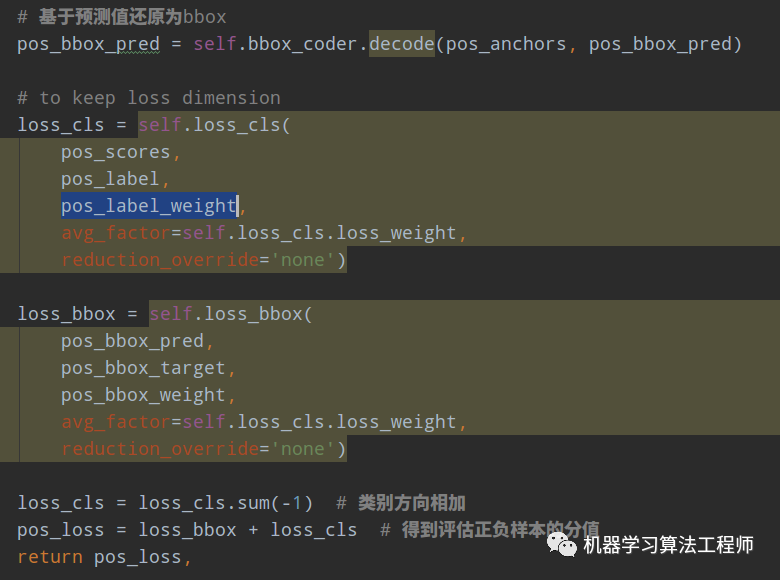
代码比较简单,就是对上述正样本提前算一轮分类和bbox回归的loss,相加即可,Loss越小越可能是正样本。
1.3 建立混合高斯模型
对每个样本都可以得到一个分值S,下面就比较简单了,对所有分值计算混合高斯分布GMM,由于GMM是非常成熟的算法了,所以作者直接调用的sklearn.mixture包进行求解。
但是在具体操作上有些地方要说明下:
(1) 是否是正负样本是基于当前gt bbox而言的,也就是说gmm操作需要在每个gt bbox所对应的样本上单独进行
(2) 由于大小输出size差别很大,样本数也差距较大,为了公平起见和加快速度,按照atss策略,先在每个输出层上利用topk策略选择出loss较小的前k个样本,topk后面的样本直接就是负样本(比较暴力,不那么优雅),不需要算了
整个自适应策略的整体流程图如下(不用看也行):

代码层面上流程是:
(1) 首先前面返回的正样本分值是全部图片和全部输出层flatten的,为了后面topk计算需要先记录每层对应的mask
# 记录每个输出层样本mask,方便后面切割每层样本for i in range(num_level):# pos_inds里面存储的是所有输出层flatten后的值,所以需要先把各输出层的数据提取出来mask = (pos_inds >= inds_level_interval[i]) & (pos_inds < inds_level_interval[i + 1])pos_level_mask.append(mask)
(2) 遍历每个gt bbox,然后遍历每个特征图,采用topk选择出前topk个小loss的样本,进行后续聚类
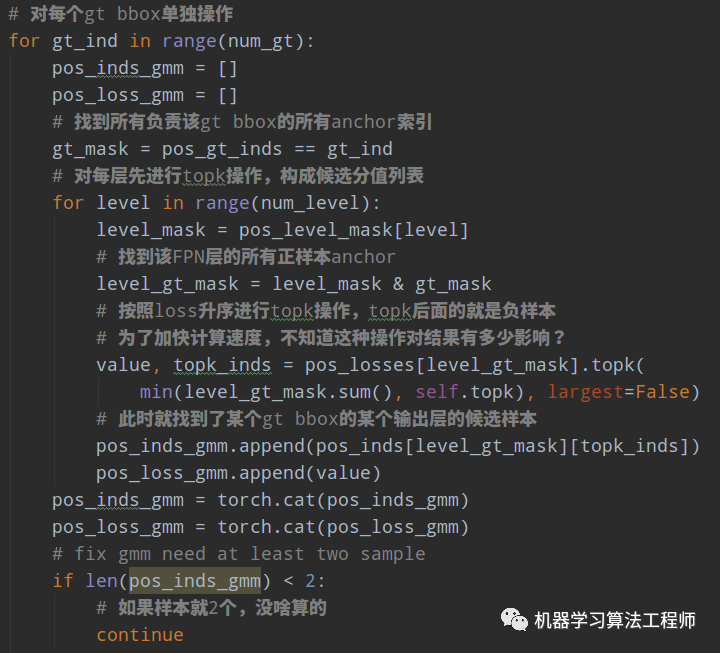
(3) 对每个gt bbox所选择的候选列表进行gmm建模,权重初始化为1:1,得到分配结果和分值
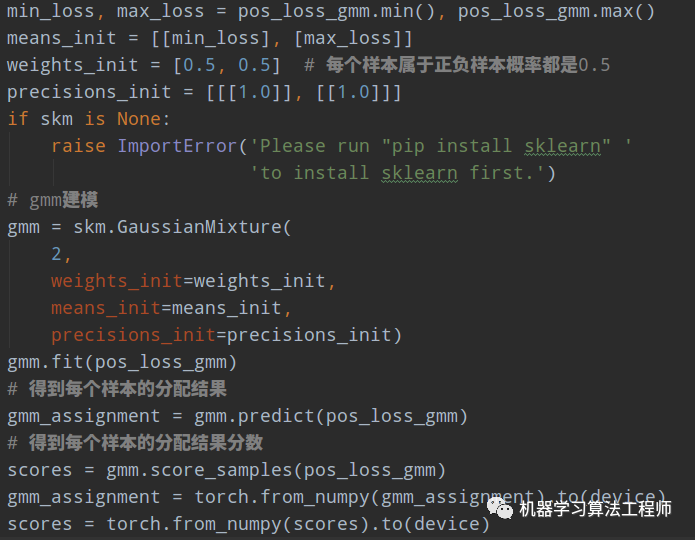
1.4 确定正负样本
在建模得到分布后,进行正负样本分离做法有非常多种,如下所示:
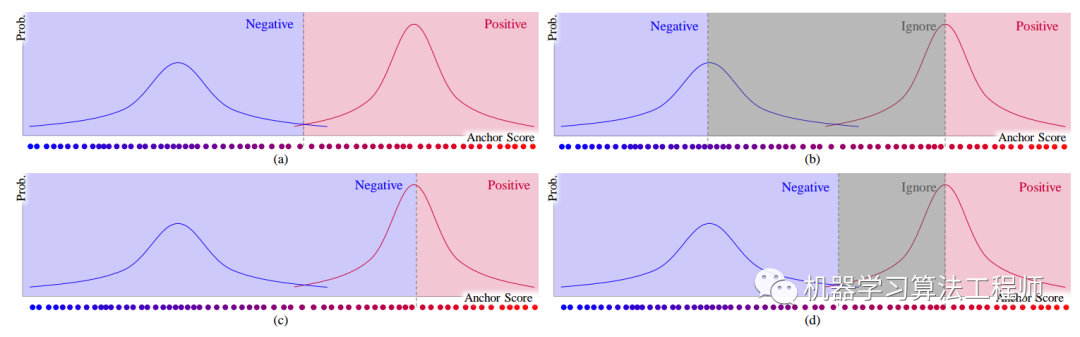
作者后面有对比实验,发现(c)比较好,所以代码实现的是(c)类型。注意上述图绘制的意思是分值越大越可能是正样本,但是实际上我们用的是loss,其是相反的。
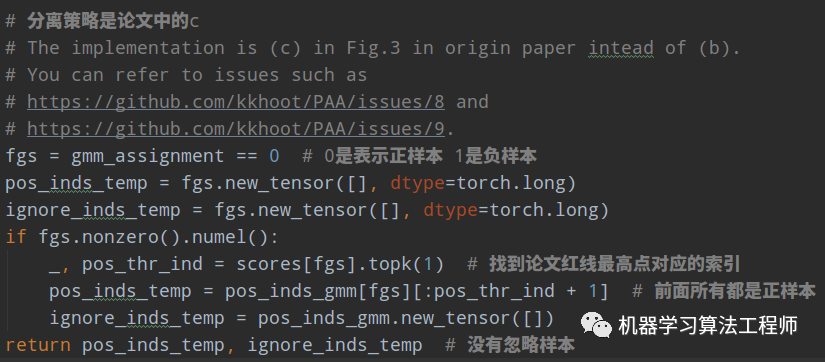
找出了正样本索引,那么其余都是负样本了,没有忽略样本。后面就是正常的loss计算就行。
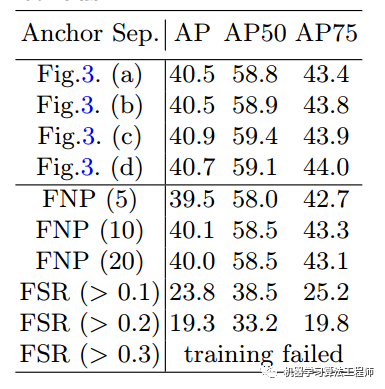
通过实验发现,(c)策略效果好一点。并且在采用固定正样本数这种操作情况下效果都没有本文自适应好。
1.5 可视化分析
代码已经集成进框架中了,只需要把configs/paa/paa_r50_fpn_1x_coco.py中train_cfg设置为True即可,由于其内部调用了Anchor_head的分配策略,故可视化效果是先可视化第一次正负样本分配情况,然后在可视化第二次PAA正负样本分配情况,如下所示:
第一次分配:
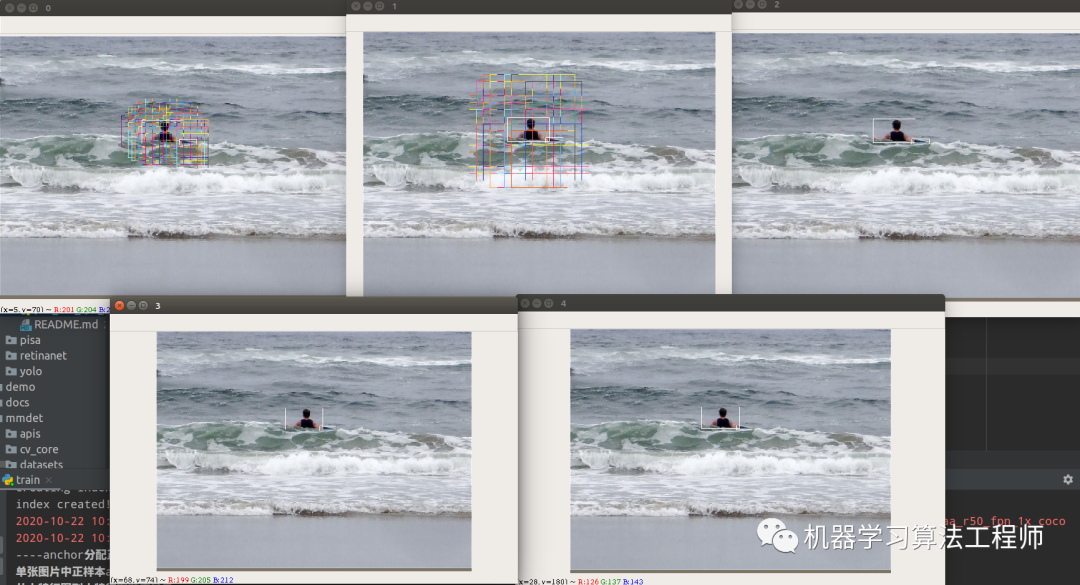
第二次分配:
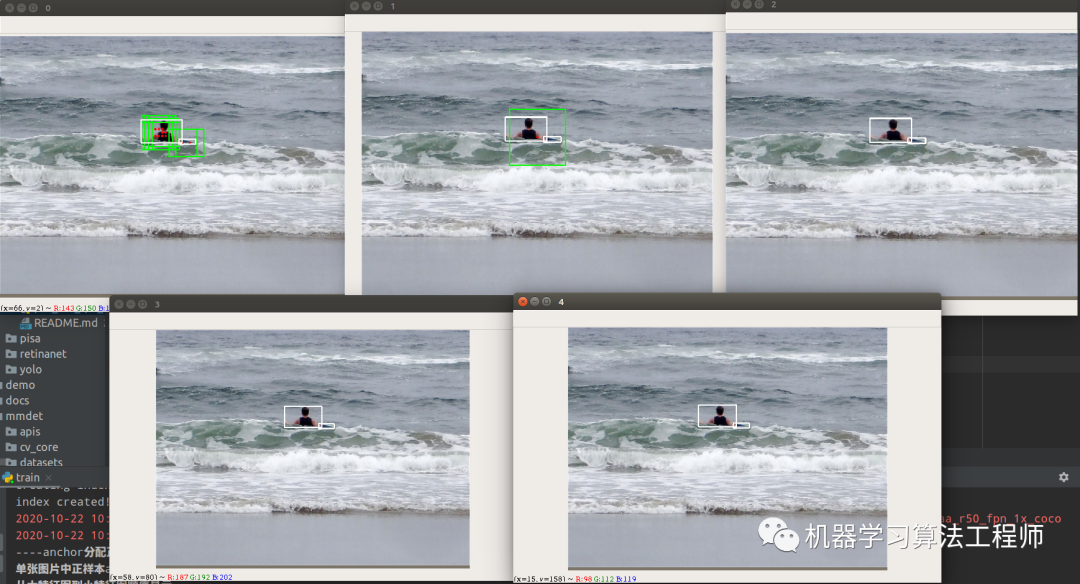
第一次分配:

第二次分配:

看起来这个分配策略比目前最好的ATSS还要好。这是是真正的自适应了(基于预测情况而改变),ATSS可以认为是伪自适应(不管预测输出咋样,其正负样本定义不变)。
1.6 推理流程
在推理过程中,作者还希望用到前面的分值s来进一步提高性能,既然有这个信息那肯定要用上。作者采用了常规的bbox voting策略来加权投票,和常规bbox voting区别在于权重计算方式:
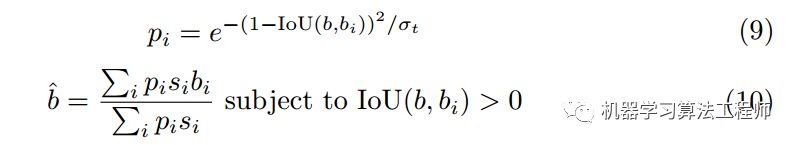
s_i是iou预测值和分类分值的乘积,分值越大越好,bbox voting应用于nms后,其核心思想是利用被nms抑制后的bbox来加权nms后保留的bbox,进行bbox调整。思路非常好理解,假设nms后留下了某个bbox,但nms一共抑制了5个bbox,那么很明显我可以利用这5个bbox采用加权方式来refine当前保留的bbox,其核心就是如何算权重。
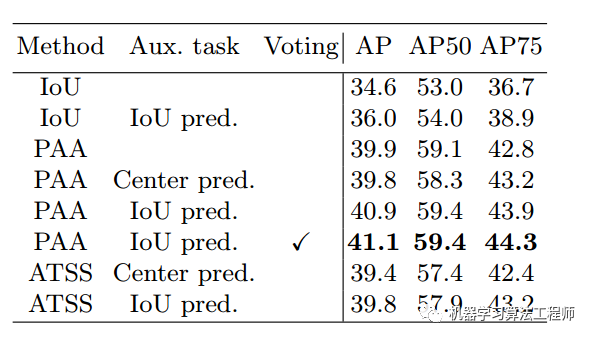
可以看出采用bbox voting后可以提高大概0.2mAP。
2 总结
本文通过将正负样本定义问题转化为2模态的混合高斯建模问题,可以达到超参少、真正自适应的目的。思想还是很可取的,就是实现上过于简单,过于暴力,在不同数据集上不知道会不会有其他问题,期待后续有更优雅的实现办法。
github地址:
https://github.com/hhaAndroid/mmdetection-mini
欢迎star
推荐阅读
mmdetection最小复刻版(六):FCOS深入可视化分析
mmdetection最小复刻版(二):RetinaNet和YoloV3分析
机器学习算法工程师
一个用心的公众号
