用Transformer定义所有ML模型,特斯拉AI总监Karpathy发推感叹AI融合趋势

来源:机器之心 本文约1700字,建议阅读5分钟
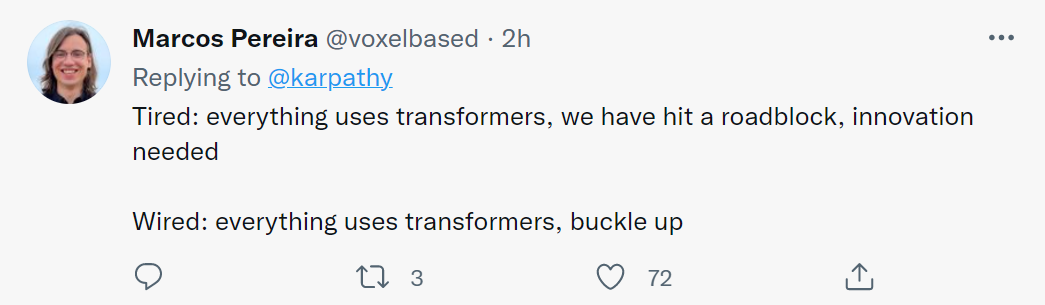
特斯拉 AI 总监 Andrej Karpathy 连发多条推文表示,AI 不同领域(视觉、语音、自然语言等)正在打通,融合速度令人惊叹。
近日,特斯拉 AI 总监、Autopilot Vision 团队领导人 Andrej Karpathy 在推特上发文,对 AI 领域正在进行中的融合(consolidation)表示惊叹。
他表示,10 年前,视觉、语音、自然语言、强化学习等都是完全分离的,甚至没有跨领域的论文。方法也完全不同,通常不是基于机器学习。
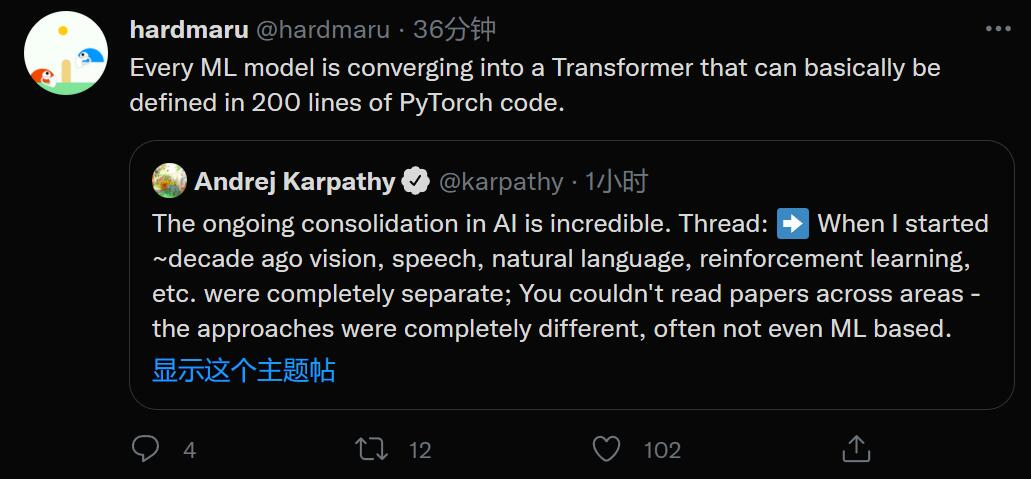
从 2010 年开始,视觉、语言、自然语言、强化学习等领域的壁垒逐渐打破,它们开始转向同一个技术方向,即机器学习,特别是神经网络。它们使用的网络架构具有多样性,但至少论文开始读起来更加相似,基本上都用到了大型数据集和网络优化。
随着 AI 技术的发展,近两年,不同领域模型架构似乎也变得相同起来。很多研究者开始专注于 Transformer 架构,在此基础上做较小的改动以进行研究。
例如 2018 诞生的 GPT,1.17 亿参数;2019 年 GPT-2,15 亿参数;2020 年更是将其扩展到 1750 亿参数 GPT-3。Karpathy 基于 PyTorch,仅用 300 行左右的代码就写出了一个小型 GPT 训练库,并将其命名为 minGPT,这个 minGPT 能够进行加法运算和字符级的语言建模,而且准确率还不错。核心的 minGPT 库包含两个文档:mingpt/model.py 和 mingpt/trainer.py。前者包含实际的 Transformer 模型定义,大约 200 行代码,后者是一个与 GPT 无关的 PyTorch 样板文件,可用于训练该模型。

部分代码截图
随着模型架构的融合,现在,我们可以向模型输入词序列、图像 patch 序列、语音序列、强化学习序列(状态、行为、奖励)。我们可以在条件设置中添加任意 token,这种模式是极其简单、灵活的建模框架。
即使是在某个领域(如视觉)内部,过去在分类、分割、检测和生成任务上存在一些差异。但是,所有这些也正在转换为相同的框架,例如 patch 的检测 take 序列和边界框的输出序列。
现在,区别性特征主要包括以下几个方面:
数据
将自身问题映射到向量序列以及从向量序列映射出自身问题的输入 / 输出规范
位置编码器的类型以及注意力 mask 中针对特定问题的结构化稀疏模式
所以,从技术上来说,AI 领域的方方面面,包括前景、论文、人才和想法突然之间变得极其相关。每个人基本上都在使用相同的模型,大多数改进和想法可以快速地在所有 AI 领域「复制粘贴」(copy paste)。
正如其他很多人注意到并指出的那样,新大脑皮质(neocortex)在其所有的输入模态中也有一个高度统一的架构。也许自然界偶然发现了一个非常相似的强大架构,并以类似的方式复制了它,并只在一些细节上做了改变。
这种架构上的融合将使我们专注于软硬件和基础设施建设,进一步加速 AI 领域的进展。「无论如何,这是激动人心的时刻。」
对于 Andrej Karpathy 描述的 AI 融合趋势,网友也纷纷发表意见。
推特网友 @Neural Net Nail 表示,「这是一个有价值的见解。融合将加速 AI 领域的创新步伐,在边缘端使用 AI 的尖端产品变得更加可行。我想,变化(variation)才是质量的最大敌人。」
网友 @sisil mehta 也认为,「ML 基础设施迎来了激动人心的时刻。随着模型架构的融合,建模框架和基础设施也将融合。我当然希望 PyTorch Lightning 也会这样。」
网友 @Marcos Pereira 表示,「一方面,处处都在用 transformers,我们已经遇到了障碍,需要创新;另一方面,处处都在用 transformers,所以跟上来吧。」