
触类旁通Elasticsearch之吊打同行系列:原理篇
点击上方蓝色字体,选择“设为星标”
回复”资源“获取更多资源



目录
一、逻辑设计
文档
类型
索引
二、物理设计
节点
主分片与副本分片
分布式索引和搜索
三、索引数据
四、搜索数据
在哪里搜索
回复的内容
如何搜索
通过ID获取文档
ES被设计为处理海量数据的高性能搜索场景。海量数据具体说至少应该是数亿文档,而高性能具体说就是从数亿文档中任意搜索需要的信息,应该在秒级返回结果。既然ES的一切都是为了性能而设计,从逻辑设计和物理设计两个角度考察ES的数据组织,对于理解ES的工作原理会有帮助。
逻辑设计:用于索引和搜索的基本单位是文档,可以将其认为是关系数据库里的一行记录。文档以类型分组,类型包含若干文档,类似表中包含若干行。最终,一个或多个类型存储于同一索引中,索引是更大的容器,类似于SQL世界中的数据库。ES6中类型的概念已经过时,并且将在7中彻底弃用。因此在我的环境中,ES索引和文档就对应数据库的表和记录。
物理设计:物理设计的配置方式决定了集群的性能、可扩展性和可用性。ES将每个索引划分为片,缺省为5片,每份分片可以在集群中不同的服务器间迁移。通常,应用程序无须关心这些,因为无论ES是单台还是多台服务器,应用和ES的交互基本保持不变。
图1展示了这两个方面:
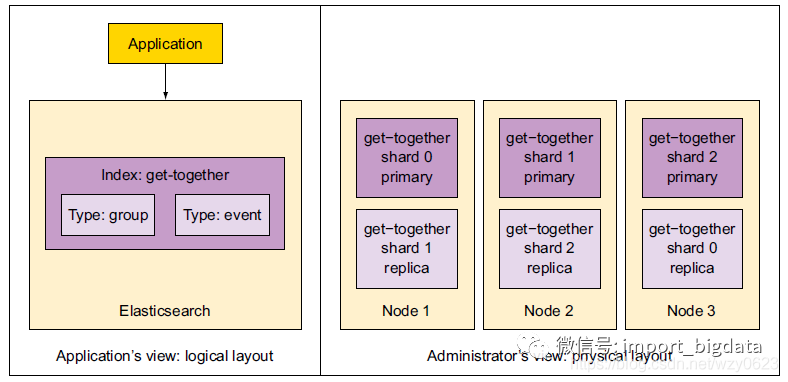 图1 ES逻辑设计与物理设计
图1 ES逻辑设计与物理设计
一、逻辑设计
图2所示为一个ES索引的逻辑结构:
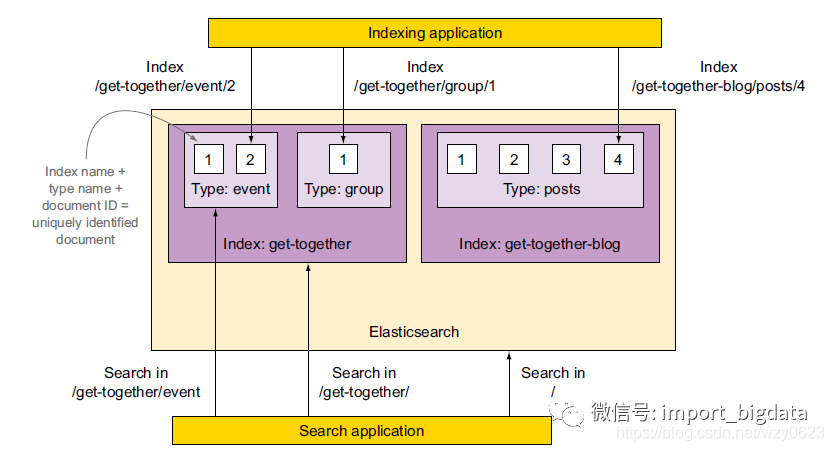 图2 ES数据的逻辑设计
图2 ES数据的逻辑设计
在ES6中,一个索引中只能有一个类型,缺省名为_doc。索引-类型-文档ID 的组合唯一确定了一篇文档,文档ID可以是任意字符串。
当进行搜索的时候,可以查找特定的索引中的文档,也可以跨多个索引进行搜索,类似于单表或多表查询。但和关系数据库不同的是,ES并不支持关系数据库中表之间的join,或者嵌套子查询。
1. 文档
ES是面向文档的,索引和搜索的最小单位是文档。ES中文档有几个重要的属性。
它是自包含的。一篇文档中同时包含字段和字段的取值。关系库的表结构是元数据,与真正数据的存储和管理方式是不同的。但ES中文档数据本身就包含了字段名和字段值。
它可以是层次的。文档中可以包含其它文档。一个字段可以是简单的,如一个字符串,也可以包含其它字段和取值。
它是无模式的。文档不依赖于预先定义的模式,不同文档的字段可以不同。
一篇文档通常是数据的JSON表示。和ES沟通最为广泛的方式是HTTP协议上的JSON。下面是个简单文档的例子:
{
"name": "Elasticsearch Denver",
"organizer": "Lee",
"location": "Denver, Colorado, USA"
}
下面是一个层次型文档的例子:
{
"name": "Elasticsearch Denver",
"organizer": "Lee",
"location": {
"name": "Denver, Colorado, USA",
"geolocation": "39.7392, -104.9847"
}
}
一个简单的文档也可以包含一组数值,例如:
{
"name": "Elasticsearch Denver",
"organizer": "Lee",
"members": ["Lee", "Mike"]
}
ES中的文档是无模式的,也就是说并非所有的文档都需要拥有相同的字段,它们不是受限于同一个模式。尽管可以随意添加和忽略字段,但是每个字段的类型很重要。ES保存字段和类型之间的映射以及其它设置,类似于表结构。
2. 类型
ES6中类型的概念已经过时。在ES6之前的版本中,类型是文档的容器,类似于表格是行的容器。每个类型中字段的定义称为映射(mapping),每种字段通过不同的方式进行处理。
既然ES是无模式的,为什么每个文档属于一种类型,而且每个类型包含一个看上去很像模式的映射呢?我们说“无模式”是因为文档不受模式的限制。它们并不需要拥有映射中所定义的所有字段,也能提出新的字段。这是如何运作的?首先,映射包含某个类型中当前索引的所有文档的所有字段。但不是所有的文档必须要有所有的字段。同样,如果一篇新索引的文档拥有一个映射中尚不存在的字段,ES会自动地将新字段加入映射。为了添加这个字段,ES需要确定它是什么类型,于是ES会根据字段值进行猜测。例如,如果值是7,ES会假设字段是长整型。
这种对新字段的自动检测也有缺点,因为ES可能猜得不对。例如,在索引了值7之后,可能想再索引hello world,这时由于它是text而不是long,索引就会失败,对于线上环境,最安全的方式是在索引数据之前,就定义好所需的映射。从这个角度看很像数据库,在加入数据前先建表。所以在实际应用中,常见的使用方式还是先仔细定义好映射,再装载数据。
映射只是将文档进行逻辑划分。从物理角度看,文档写入磁盘时不考虑它们所属的类型。
3. 索引
索引是文档的容器,一个ES索引非常像关系数据库中的表,是独立的大量文档的集合。每个索引存储在磁盘上的同组文件中;索引存储了所有字段的映射和数据,还有一些设置。例如,每个索引有一个称为refresh_interval的设置,定义了新文档对于搜索可见的时间间隔。从性能的角度看,刷新操作的代价是非常昂贵的。ES的索引数据是写入到磁盘上的。但这个过程是分阶段实现的,因为IO的操作比较费时。
先写到内存中,此时不可搜索。
默认经过 1s 之后会被写入 lucene 的底层文件 segment 中 ,此时可以搜索到。
refresh 之后才会写入磁盘。
ES被称为准实时的,指的就是这种刷新过程。
二、物理设计
默认情况下,每个索引由5个分片组成,而每个分片又有一个副本,一共10个分片。如图3所示。
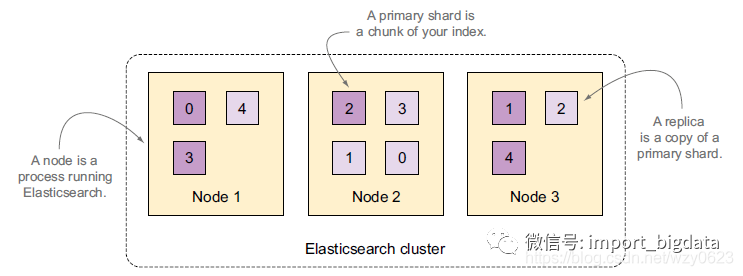 图3 一个有3个节点的集群,索引被划分为5个主分片,每个主分片有一个副本分片
图3 一个有3个节点的集群,索引被划分为5个主分片,每个主分片有一个副本分片
技术上而言,一个分片是一个的文件,Lucene用这些文件存储索引数据。分片也是ES将数据从一个节点迁移到另一个节点的最小单位。
1. 节点
一个节点是一个ES实例,多个节点可以加入同一集群。在多节点的集群上,同样的数据可以在多台服务器上传播。如果每分片至少有一个副本,那么任何一个节点都可以宕机,而ES依然可以进行服务,返回所有数据。对于应用程序,集群中有1个还是多个节点是透明的。默认情况下,可以连接集群中的任一节点并访问完整的数据集。
默认情况下,当索引一篇文档时,系统首先根据文档ID的散列值选择一个主分片,并将文档发送到该主分片。这个主分片可能位于另一个节点,如图4中节点2上的主分片,不过对于应用程序这一点是透明的。
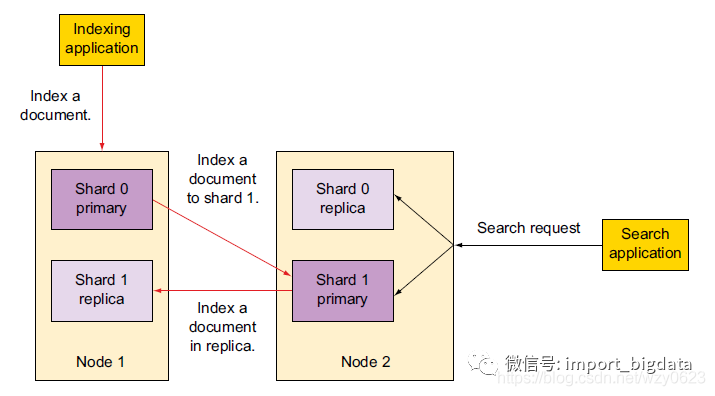 图4 文档被索引到随机的主分片和它们的副本分片。
图4 文档被索引到随机的主分片和它们的副本分片。
搜索在完整的分片集合上运行,无论它们的状态是主分片还是副本分片。
然后文档被发送到该主分片的所有副本分片进行索引(如图4的左边)。这使得副本分片和主分片之间保持数据的同步。数据同步使得副本分片可以服务于搜索请求,并在原主分片无法访问时自动升级为主分片。
当搜索一个索引时,ES需要在该索引的完整集合中进行查找(见图4的右边)。这些分片可以是分片,也可以是副本分片。ES在索引的主分片和副本分片中进行搜索请求的负载均衡,使得副本分片对于搜索性能和容错都有所帮助。
2. 主分片与副本分片
分片是ES最小的处理单元,一个分片是一个Lucene的索引:一个包含倒排索引的文件目录。如图5所示,get-together索引的首个主分片可能包含何种信息。该分片称为get-together0,它是一个Lucene索引、一个倒排索引。它默认存储原始文档的内容,再加上一些额外的信息,如词条字典和词频。
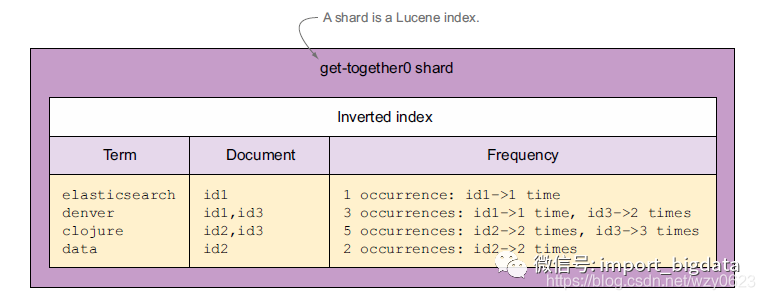 图5 Lucene索引中的词条字典和词频
图5 Lucene索引中的词条字典和词频
词条字典将每个词条和包含该词条的文档映射起来。搜索的时候,ES没必要为了某个词条扫描所有文档,而是根据这个字典快速识别匹配的文档。
词频使得ES可以快速地获取谋篇文档中某个词条出现的次数。这对于计算结果的相关性得分非常重要。更高得分的文档出现在结果列表的更前面。默认的排序算法是TF-IDF。
可以在任何时候改变每个分片的副本分片的数量,因为副本分片总是可以被创建和移除。但主分片的数量必须在创建索引之前确定,索引创建后主分片的数量不能修改。过少的分片将限制可扩展性,但过多的分片影响性能。默认设置的5份是个不错的开始。
3. 分布式索引和搜索
索引的过程如图6所示。接受索引请求的ES节点首先选择文档索引到哪个分片。默认的,文档在分片中均匀分布:对于每篇文档,分片是通过其ID字符串的散列决定的。每个分片拥有相同的散列范围,接收新文档的机会均等。一旦目标分片确定,接受请求的节点将文档转发到该分片所在节点。随后,索引操作在所有目标分片的副本分片中进行。在所有可用副本分片完成文档的索引后,索引命令就会返回成功。
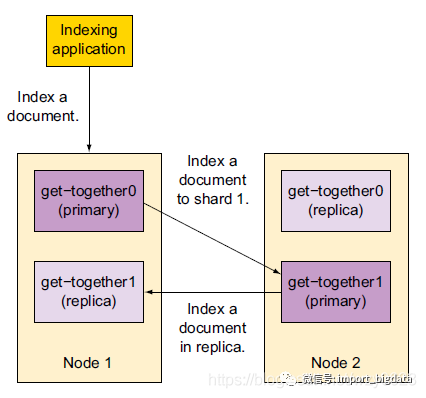 图6 索引操作被转发到相应的分片,然后转发到它的副本分片
图6 索引操作被转发到相应的分片,然后转发到它的副本分片
在搜索的时候,接受请求的节点将请求转发到一组包含所有数据的分片。ES使用round-robin的轮询机制选择可用的分片(主分片或副本分片),并将搜索请求转发过去,其假设集群中的所有节点是同样快的。如图7所示,ES然后从这些分片收集结果,将其聚集到单一的结果返回给应用程序。
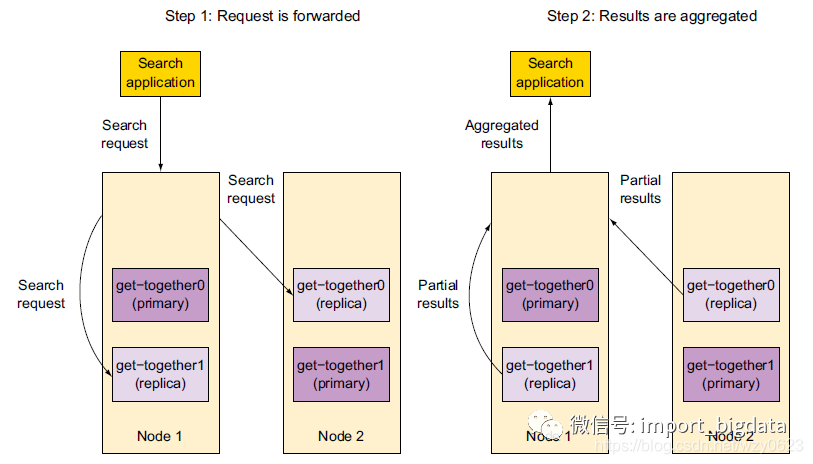 图7 转发搜索请求到包含完整数据集合的主分片/副本分片,然后聚集结果并将其发送回客户端
图7 转发搜索请求到包含完整数据集合的主分片/副本分片,然后聚集结果并将其发送回客户端
三、索引数据
可以使用curl的PUT方法索引一个文档,如:
curl -XPUT '172.16.1.127:9200/get-together/_doc/1?pretty' -H 'Content-Type: application/json' -d '
{
"name": "Elasticsearch Denver",
"organizer": "Lee"
}'
这句DSL语句的功能是向索引get-together中新增一个ID为1的文档,类似于SQL的insert命令:
insert into get-together (id, name, organizer) values (1, 'Elasticsearch Denver', 'Lee');
输出如下:
{
"_index" : "get-together",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
回复中包含索引、类型和文档ID。如果索引和类型不存在,则会自动创建。文档ID也可以由ES自动生成。这里还获得了文档的版本,它从1开始并随着每次的更新而增加。ES使用这个版本号实现并发更新时的乐观锁功能,防止类似关系数据库中的第二类更新丢失问题。
这个curl命令之所以可以奏效,是因为ES自动创建了get-together和_doc类型,并为_doc类型创建了一个新的映射。映射包含字符串字段的定义。默认情况下ES处理所有这些,无需任何事先配置,就可以开始索引。
使用下面的命令查询索引的映射:
curl '172.16.1.127:9200/get-together/_mapping?pretty'
返回如下。可以看到,ES自动将name和organizer字段识别为text类型:
{
"get-together" : {
"mappings" : {
"_doc" : {
"properties" : {
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"organizer" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
}
}
映射类型包含与文档相关的字段或属性列表。ES缺省将字符串数据映射为text和keyword。因此,可以对name和organizer字段执行全文搜索,同时使用name.keyword或organizer.keyword执行原文匹配和聚合。
可以手动创建索引:
curl -XPUT '172.16.1.127:9200/new-index?pretty'
类似于创建一个名为new-index的表,但这里只指定了索引名称,返回如下:
如果只想建立字符串类型的倒排索引搜索字段,而不映射keyword字段,只需要在创建索引时显式指定mapping:
curl -XPUT '172.16.1.127:9200/myindex?pretty' -H 'Content-Type: application/json' -d '
{
"mappings": {
"_doc": {
"properties": {
"name": {
"type": "text"
},
"organizer": {
"type": "text"
}
}
}
}
}'
curl '172.16.1.127:9200/myindex/_mapping?pretty'
{
"myindex" : {
"mappings" : {
"_doc" : {
"properties" : {
"name" : {
"type" : "text"
},
"organizer" : {
"type" : "text"
}
}
}
}
}
}
四、搜索数据
下面的命令搜索get-together索引中包含“elasticsearch”关键词的文档,但只获取最相关文档的name和location_event.name字段。功能类似于SQL语句:
select name, location_event from get-together
where column1 like '%elasticsearch%'
or column2 like '%elasticsearch%'
...
or columnn like '%elasticsearch%'
order by _score
limit 1;
下面两种写法是等价的,但后者的可读性更好。这个例子中的搜索条件没有指定任何字段,意为在所有字段中搜索。
curl "172.16.1.127:9200/get-together/_search?\
q=elasticsearch\
&_source=name,location_event.name\
&size=1\
&pretty"
curl "172.16.1.127:9200/get-together/_search?pretty" -H 'Content-Type: application/json' -d'
{
"_source": [
"name",
"location_event.name"
],
"query": {
"query_string": {
"query": "elasticsearch"
}
},
"size": 1
}'
结果返回:
{
"took" : 6,
"timed_out" : false,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 10,
"max_score" : 1.4880564,
"hits" : [
{
"_index" : "get-together",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.4880564,
"_source" : {
"name" : "Elasticsearch Denver"
}
}
]
}
}
1. 在哪里搜索
可以指定ES在特定索引中进行查询,但也可以在同一个索引的多个字段中搜索、在多个索引或在所有索引中搜索。
# 在多个索引中搜索
curl "172.16.1.127:9200/get-together,myindex/_search?q=elasticsearch&pretty"
# ignore_unavailable=true会忽略不存在的索引,而不是返回错误
curl "172.16.1.127:9200/get-together,myindex/_search?q=name:elasticsearch&pretty&ignore_unavailable=true"
# 为了在所有索引中搜索,省略索引名称
curl "172.16.1.127:9200/_search?q=name:elasticsearch&pretty"
这种关于“在哪里搜索”的灵活性,允许在多个索引中组织数据。例如,日志事件经常以基于时间的索引组织,如“logs-20190101”、“logs-20190102”等。可以只搜索最新的索引,也可以在多个索引或全量数据里搜索。
2. 回复的内容
(1)时间
除了和搜索条件匹配的文档,搜索回复还包含其它有价值的信息,用于检验搜索的性能或结果的相关性。ES的JSON应答包含了时间、分片、命中统计数据、文档等。
took字段表示ES处理请求所花的时间,单位是毫秒。timed_out字段表示搜索请求是否超时,默认情况下,搜索永远不会超时,但是可以通过timeout参数设定超时时间。例如下面的搜索在3秒后超时:
curl "172.16.1.127:9200/get-together/_search?q=elasticsearch&pretty&timeout=3s"
如果搜索超时,timed_out的值就是true,而且只能获得超时前所获得的结果。
(2)分片
回复的下一部分是搜索相关的分片信息:
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
}
get-together索引有两个分片,所有分片都有返回,所以成功(successful)的值是2,而失败(failed)的值是0。图8展示了一个拥有3个节点的集群,每个节点只有一份分片且没有副本分片。如果某个节点宕机了,就会丢失某些数据。在这种情况下,ES提供正常分片中的结果,并在failed字段中报告不可搜索的分片数量。
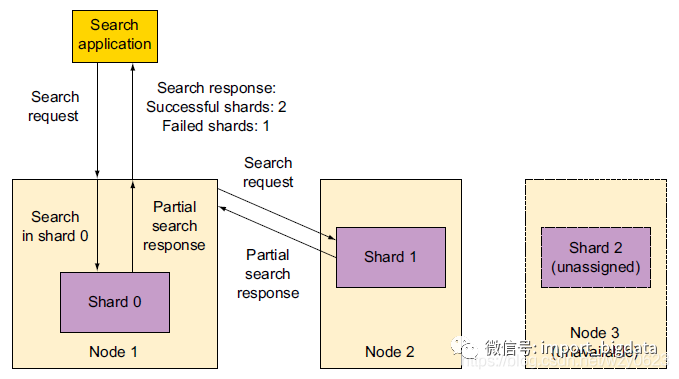 图8 仍然可用的分片将返回部分结果
图8 仍然可用的分片将返回部分结果
(3)命中统计数据
回复的最后一项组成元素是hits,这项相当长因为它包含了匹配文档的数组。数组之前包含了几项统计数据:
"total" : 10,
"max_score" : 1.4880564
total表示匹配文档的总数,max_score是这些匹配文档的最高得分。文档得分,是该文档和给定搜索条件的相关性衡量,得分默认是通过TF-IDF算法进行计算的。
匹配文档的总数和回复中的文档数量可能并不相同。ES默认限制结果数为10,可使用size参数修改返回的结果数量。查看total字段的值,可以获取匹配搜索条件的精确文档数量。
(4)结果文档
"hits" : [
{
"_index" : "get-together",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.4880564,
"_source" : {
"name" : "Elasticsearch Denver"
}
}
]
结果中包括每个匹配文档所属的索引、类型、它的ID、得分,以及搜索查询中所指定的字段的值。查询中使用了_source=name,location_event.name。如果结果中某个指定字段的值为空,缺省没有该字段的定义,就像结果中没有location_event.name字段。这点和数据库不同,数据库是有schema的,字段值和表定义分开处理,即使某字段没有值,结果中该字段也会有个NULL值。如果不指定需要哪些字段,会返回“_source”中的所有字段。_source是一个特殊的字段,ES默认在其中存储原始的JSON文档。
3. 如何搜索
(1)设置查询的字符串选项
query_string提供了除字符串之外的更多选项。例如,如果搜索“Elasticsearch san Francisco”,ES默认查询所有字段。如果想在名称和标题中查询,需要指定:
"fields": ["name", "title"]
ES默认返回匹配了任一指定关键词的文档(默认的操作符是OR)。如果希望匹配所有的关键词,需要指定:
"default_operator": "AND"
修改后的查询如下:
curl "172.16.1.127:9200/get-together/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query": {
"query_string": {
"query": "elasticsearch",
"fields": ["name", "title"],
"default_operator": "AND"
}
}
}'
查询字符串是指定搜索条件的强大工具。ES分析字符串并理解所查找的词条和其它选项,如字段和操作符,然后执行查询。这项功能是从Lucene继承而来。
(2)选择合适的查询类型
除query_string外,ES还有很多其它类型的查询。例如,如果在name字段中只查找“elasticsearch”一个词,term查询更直接:
curl "172.16.1.127:9200/get-together/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query": {
"term": {
"name": "elasticsearch"
}
}
}'
(3)使用过滤器
如果不需要通过结果得分返回结果,可以使用过滤器查询替代。过滤器查询只关心一条结果是否匹配搜索条件,因此过滤器查询更快,而且更容易缓存。例如:
curl "172.16.1.127:9200/get-together/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query": {
"bool": {
"filter": {
"term": {
"name": "elasticsearch"
}
}
}
}
}'
返回的结果和同样词条的查询相同,但结果没有根据得分排序,因为所有的结果得分都是0。
(4)应用聚合
除了查询和过滤,还可以通过聚合进行各种统计。例如实现SQL的简单聚合:
select count(*), organizer from get-together group by organizer;
ES查询命令如下:
curl 172.16.1.127:9200/get-together/_doc/_search?pretty -H 'Content-Type: application/json' -d '
{
"aggregations": {
"organizers": {
"terms": {
"field": "organizer"
}
}
}
}'
当在get-together索引上执行此聚合查询时,报以下错误:
"Fielddata is disabled on text fields by default. Set fielddata=true on [organizer] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead."
ES聚合使用一个叫Doc Values的数据结构。Doc Values使聚合更快、更高效且内存友好。Doc Values的存在是因为倒排索引只对某些操作是高效的。倒排索引的优势在于查找包含某个条目的文档,而反过来确定哪些条目在单个文档里并不高效。
Doc Values结构类似如下:
Doc Terms
Doc_1 | brown, dog, fox, jumped, lazy, over, quick, the Doc_2 | brown, dogs, foxes, in, lazy, leap, over, quick, summer Doc_3 | dog, dogs, fox, jumped, over, quick, the
Doc values在索引时生成,伴随倒排索引创建。像倒排索引一样基于per-segment,且是不可变,被序列化存储到磁盘。通过序列化持久化数据结构到磁盘,可以用操作系统的文件缓存来代替JVM heap。但是当工作空间需要的内存很大时,Doc Values会被置换出内存,这样会导致访问速度降低,但是如果放在JVM heap,将直接导致内存溢出错误。
Doc Values默认对除了分词的所有字段起作用。因为分词字段产生太多tokens且Doc Values对其并不是很有效。Doc Values默认开启,如果不执行基于一个确定的子段聚合、排序或执行脚本(Script ),可以选择关闭Doc Values,这可以节省磁盘空间,提高索引数据的速度。
text字段不支持doc_values,text使用fielddata,一种在查询时期生成在缓存里的数据结构。当字段在首次sort、aggregations或in a script时创建,读取磁盘上所有segment的倒排索引,反转 term<->doc 的关系,加载到jvm heap,它将在segment的整个生命周期内一直存在。fielddata很耗内存,默认禁用fielddata。text字段是先分词再索引的,因此,应该使用不分词的keyword用来聚合。
organizer字段的mapping如下:
"organizer" : {
"type" : "text"
}
正如错误提示中所指出的,要解决这个问题,可选择两种方式:一是设置fielddata=true,二是增加keyword字段。第一种方法可以即时生效,第二种方法需要重新索引数据才能生效。所以建议在创建index时,仔细定义mapping,以免以后修改结构产生问题。
第一种方式:
# 设置fielddata=true
curl -XPOST "172.16.1.127:9200/get-together/_mapping/_doc?pretty" -H 'Content-Type: application/json' -d'
{
"properties": {
"organizer": {
"type": "text",
"fielddata": "true"
}
}
}'
# 执行聚合查询
curl 172.16.1.127:9200/get-together/_doc/_search?pretty -H 'Content-Type: application/json' -d '
{
"aggregations": {
"organizers": {
"terms": {
"field": "organizer"
}
}
}
}'
第二种方式:
# 修改organizer字段的映射
curl -XPOST "172.16.1.127:9200/get-together/_mapping/_doc?pretty" -H 'Content-Type: application/json' -d'
{
"properties": {
"organizer": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}'
# 重新索引数据
# 在organizer.keyword字段上执行聚合
curl 172.16.1.127:9200/get-together/_doc/_search?pretty -H 'Content-Type: application/json' -d '
{
"aggregations": {
"organizers": {
"terms": {
"field": "organizer.keyword"
}
}
}
}'
返回的聚合结果如下:
"aggregations" : {
"organizers" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "Lee",
"doc_count" : 2
},
{
"key" : "Andy",
"doc_count" : 1
},
{
"key" : "Daniel",
"doc_count" : 1
},
{
"key" : "Mik",
"doc_count" : 1
},
{
"key" : "Tyler",
"doc_count" : 1
}
]
}
}
关于Doc Values和FieldData的更多说明,参见“Es官方文档整理-3.Doc Values和FieldData”。
4. 通过ID获取文档
为了获取一个具体的文档,必须要知道它所属的索引、类型和ID。然后就可以发送HTTP GET请求到这篇文档的URI:
curl '172.16.1.127:9200/get-together/_doc/1?pretty'
返回:
{
"_index" : "get-together",
"_type" : "_doc",
"_id" : "doesnt-exist",
"found" : false
}
通过ID获得文档要比搜索更快,所消耗的资源成本也更低。这也是实时完成的:只要索引操作完成了,新的文档就可以通过GET API获取。相比之下,搜索是近实时的,因为它们需要等待默认情况下每秒进行一次的刷新操作。这个思想和DB也类似,通过主键查询通常是查询数据最快的途径。


版权声明:
本文为大数据技术与架构整理,原作者独家授权。未经原作者允许转载追究侵权责任。编辑|冷眼丶微信公众号|import_bigdata文章不错?点个【在看】吧! ?