
【Python】Python抓取了王力宏事件的相关报道,发现了一个更大的瓜

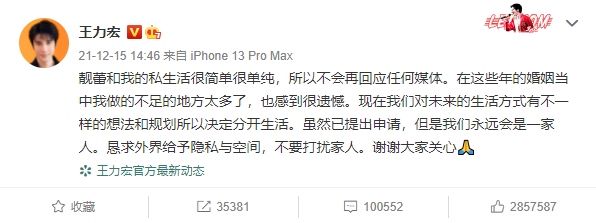
有网友还对他的前妻的发文做了一个简短的总结,如下图所示

@retry(stop=stop_after_attempt(7))
def do_requests(uid, pageNum):
headers = {
"cookie": "SCF=Anhuv5v0Lu8oFE06-PmKm-uqVmUQgSwrLYauTMNCvEmRH0iOd-jT0poB-pgkpX_aJsOYqZjgw_F8TAZ0SL_aE9Q.; _T_WM=32be9637e54d4f58408755d6f8100d5c; SUB=_2A25MueV4DeRhGeRN7lQY8ynEwziIHXVsRYswrDV6PUJbkdAKLRPSkW1NU7D9XCuoP6vJEUUVjb0HcSPigsLzxFaW; SSOLoginState=1639814440",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36"
}
url = "https://weibo.cn/repost/L6w2sfDXb?&uid={}&&page={}".format(uid, pageNum)
response = requests.get(url, headers = headers)
return response.text
def get_comment(html_data):
html_text = BeautifulSoup(html_data, 'lxml')
comment_list = html_text.select("span.ctt")
return comment_list
然后我们根据抓取到的评论生成词云图,代码如下
def jieba_():
stop_words = set([line.strip() for line in open("chineseStopWords.txt", encoding="GBK").readlines()])
for word in ["回复", "有没有"]:
stop_words.add(word)
comment_list = []
with open("comment_data.txt", "r", encoding="utf-8") as comment_data_list:
for comment in comment_data_list:
comment_list.append(comment)
text = ", ".join(comment_list)
word_num = jieba.lcut(text, cut_all=False)
rule = re.compile(r"^[\u4e00-\u9fa5]+$")
word_num_selected = [word for word in word_num if word not in stop_words and
re.search(rule, word) and len(word) >= 2]
return word_num_selected
def plot_word_cloud(text):
# 打开词云背景图
cloud_mask = np.array(Image.open('gua_1.jpg'))
# 定义词云的一些属性
wc = WordCloud(
# 背景图分割颜色为白色
background_color='white',
# 背景图样
mask=cloud_mask,
# 显示最大词数
max_words=200,
# 显示中文
font_path='KAITI.ttf',
# 最大尺寸
max_font_size=100
)
text_ = ", ".join(text)
# 词云函数
x = wc.generate(text_)
# 生成词云图片
image = x.to_image()
# 展示词云图片
image.show()
# 保存词云图片
wc.to_file('melon_1.png')


往期精彩回顾 本站qq群955171419,加入微信群请扫码:
评论