
【机器学习基础】说模型过拟合的时候,说的是什么?
前言
机器学习中,模型的拟合效果意味着对新数据的预测能力的强弱(泛化能力)。而程序员评价模型拟合效果时,常说“过拟合”及“欠拟合”,那究竟什么是过/欠拟合呢?什么指标可以判断拟合效果?以及如何优化?
欠拟合&过拟合的概念
注:在机器学习或人工神经网络中,过拟合与欠拟合有时也被称为“过训练”和“欠训练”,本文不做术语差异上的专业区分。
欠拟合是指相较于数据而言,模型参数过少或者模型结构过于简单,以至于无法学习到数据中的规律。
过拟合是指模型只过分地匹配特定数据集,以至于对其他数据无良好地拟合及预测。其本质是模型从训练数据中学习到了统计噪声,由此分析影响因素有:
训练数据过于局部片面,模型学习到与真实数据不相符的噪音; 训练数据的噪音数据干扰过大,大到模型过分记住了噪音特征,反而忽略了真实的输入输出间的关系; 过于复杂的参数或结构模型(相较于数据而言),在可以“完美地”适应数据的同时,也学习更多的噪声; 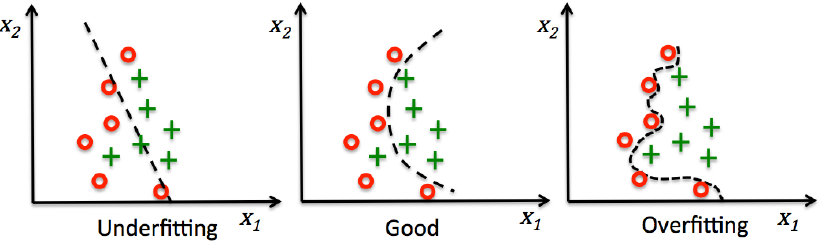 如上图以虚线的区分效果来形象表示模型的拟合效果。Underfitting代表欠拟合模型,Overfitting代表过拟合模型,Good代表拟合良好的模型。
如上图以虚线的区分效果来形象表示模型的拟合效果。Underfitting代表欠拟合模型,Overfitting代表过拟合模型,Good代表拟合良好的模型。
拟合效果的评估方式
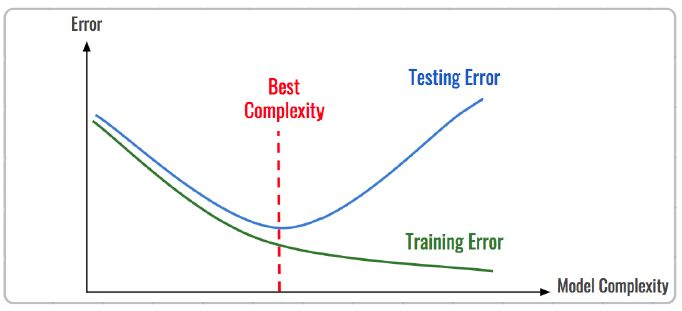 现实中通常由训练误差及测试误差(泛化误差)评估模型的学习程度及泛化能力。
现实中通常由训练误差及测试误差(泛化误差)评估模型的学习程度及泛化能力。
欠拟合时训练误差和测试误差在均较高,随着训练时间及模型复杂度的增加而下降。在到达一个拟合最优的临界点之后,训练误差下降,测试误差上升,这个时候就进入了过拟合区域。它们的误差情况差异如下表所示: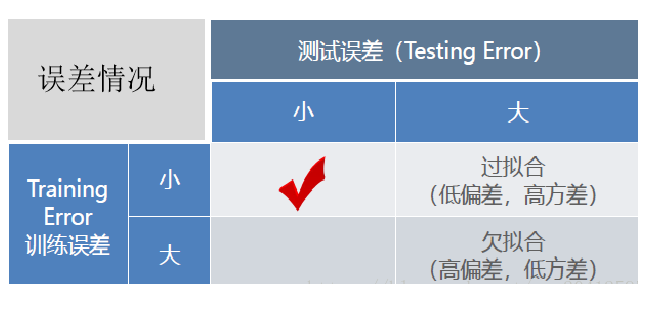
拟合效果的深入分析
对于拟合效果除了通过训练、测试的误差估计其泛化误差及判断拟合程度之外,我们往往还希望了解它为什么具有这样的泛化性能。统计学常用“偏差-方差分解”(bias-variance decomposition)来分析模型的泛化性能:其泛化误差为偏差、方差与噪声之和。
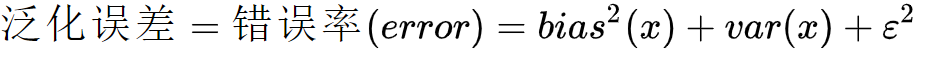
噪声(ε) 表达了在当前任务上任何学习算法所能达到的泛化误差的下界,即刻画了学习问题本身(客观存在)的难度。
偏差(Bias) 是指用所有可能的训练数据集训练出的所有模型的输出值与真实值之间的差异,刻画了模型的拟合能力。偏差较小即模型预测准确度越高,表示模型拟合程度越高。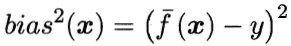
方差(Variance) 是指不同的训练数据集训练出的模型对同预测样本输出值之间的差异,刻画了训练数据扰动所造成的影响。方差较大即模型预测值越不稳定,表示模型(过)拟合程度越高,受训练集扰动影响越大。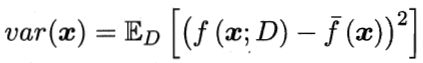 如下用靶心图形象表示不同方差及偏差下模型预测的差异:
如下用靶心图形象表示不同方差及偏差下模型预测的差异:
偏差越小,模型预测值与目标值差异越小,预测值越准确;
方差越小,不同的训练数据集训练出的模型对同预测样本预测值差异越小,预测值越集中;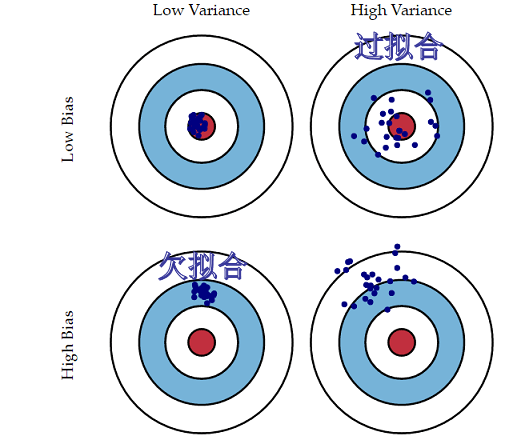
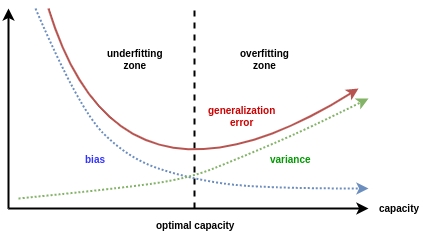
“偏差-方差分解” 说明,模型拟合过程的泛化性能是由学习算法的能力、数据的充分性以及学习任务本身的难度所共同决定的。
当模型欠拟合时:模型准确度不高(高偏差),受训练数据的扰动影响较小(低方差),其泛化误差大主要由高的偏差导致。
当模型过拟合时:模型准确度较高(低偏差),模型容易学习到训练数据扰动的噪音(高方差),其泛化误差大由高的方差导致。
拟合效果的优化方法
可结合交叉验证评估模型的表现,可较准确判断拟合程度。在优化欠/过拟合现象上,主要有如下方法:
模型欠拟合
增加特征维度:如增加新业务层面特征,特征衍生来增大特征假设空间,以增加特征的表达能力; 增加模型复杂度:如增加模型训练时间、结构复杂度,尝试复杂非线性模型等,以增加模型的学习能力;
模型过拟合
增加数据: 如寻找更多训练数据样本,数据增强等,以减少对局部数据的依赖;
特征选择:通过筛选掉冗余特征,减少冗余特征产生噪声干扰;
降低模型复杂度:
简化模型结构:如减少神经网络深度,决策树的数目等。
L1/L2正则化:通过在代价函数加入正则项(权重整体的值)作为惩罚项,以限制模型学习的权重。
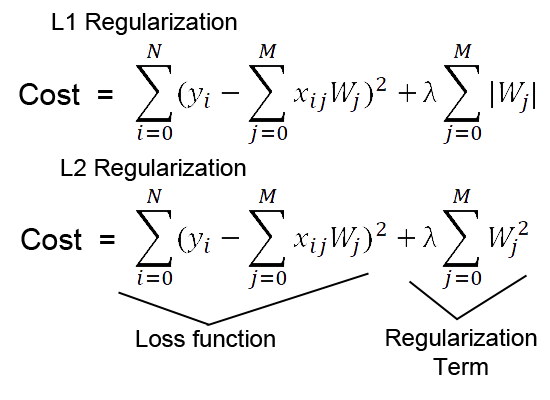
(拓展:通过在神经网络的网络层引入随机的噪声,也有类似L2正则化的效果)
提前停止(Early stopping):通过迭代次数截断的方法,以限制模型学习的权重。
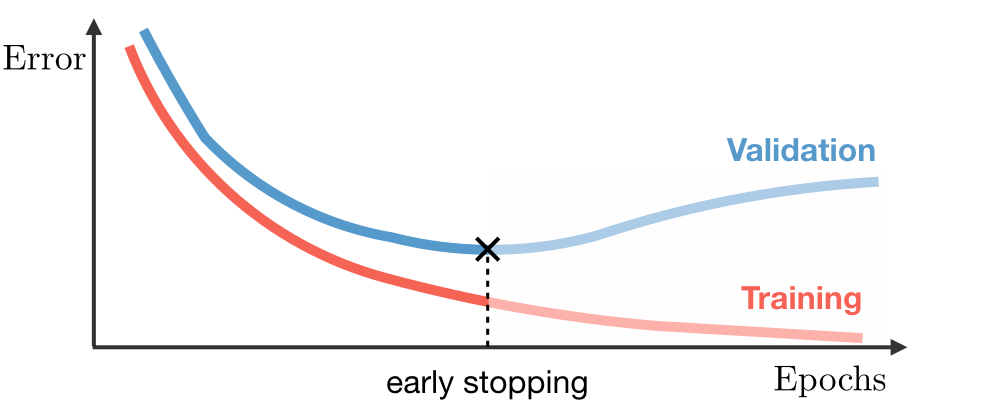
结合多个模型: 集成学习:如随机森林(bagging法)通过训练样本有放回抽样和随机特征选择训练多个模型,综合决策,可以减少对部分数据/模型的依赖,减少方差及误差;
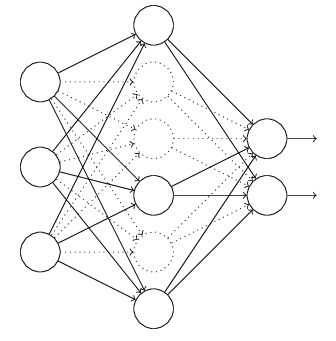
Dropout:神经网络的前向传播过程中每次按一定的概率(比如50%)随机地“暂停”一部分神经元的作用。这类似于多种网络结构模型bagging取平均决策,且模型不会依赖某些局部的特征,从而有更好泛化性能。
往期精彩回顾
本站qq群704220115,加入微信群请扫码: