
华录杯数据湖大赛:车道线识别 Top5方案
点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达
比赛名称:2020中国华录杯·数据湖算法大赛—定向算法赛(车道线识别)
比赛链接:https://dev.ehualu.com/dev/home/competition/competitionDetail?competitionId=1&source=DC
文章内容:决赛第五名方案,成绩为39.55
代码框架:使用PaddleSeg动态图和AI Stdudio,低代码量快速迭代打比赛。
分享链接:https://aistudio.baidu.com/aistudio/projectdetail/1248023
赛题说明
竞赛任务
要求参赛者利用提供的训练数据,设计一个车道线检测和分类模型,来检测测试数据中车道线的具体位置和类别。

数据集描述
本次赛题数据集包括x张手机拍摄的道路图片数据,并对这些图片数据标注了车道线的区域和类别,其中标注数据以灰度图的方式存储。
标注数据是与原图尺寸相同的单通道灰度图,其中背景像素的灰度值为0,不同类别的车道线像素分别为不同的灰度值,加上背景共有20类。


评审规则
与通常的图像分割任务一样,采用 mIoU 来评估结果。对于每一类,利用预测图像和真值图像,
数据分析
图像观察
观察图像数据,发现图像的上方一半区域是拍摄的建筑、天空等非路面信息,这些区域的像点都属于背景类别。这部分区域不必训练和预测。设定训练图像尺寸为1280X360
类别统计
利用PaddleSeg提供的工具,检查数据时发现各个类别数据不均衡,而且多个类别为零,选择忽略。
Doing label pixel statistics:
(label class, total pixel number, percentage) =
[(0, 17982127059, 0.9762),
(1, 104617183, 0.0057),
(2, 9012630, 0.0005),
(3, 121541931, 0.0066),
(4, 8284314, 0.0004),
(5, 2283958, 0.0001),
(6, 5635328, 0.0003),
(7, 4816484, 0.0003),
(8, 27060729, 0.0015),
(9, 24371550, 0.0013),
(10, 8857308, 0.0005),
(11, 308858, 0.0),
(12, 1328788, 0.0001),
(13, 5940530, 0.0003),
(14, 1795084, 0.0001),
(15, 632607, 0.0),
(16, 621556, 0.0),
(17, 307548, 0.0),
(18, 178659, 0.0),
(19, 110066696, 0.006)]
数据集
数据集是将初赛和复赛数据整合起来,9:1划分训练集和验证集数据增强
采用随机尺度缩放、随机变形等增强方式
方案思路
思路来源
英伟达的分层多尺度注意机制论文(https://arxiv.org/pdf/2005.10821.pdf),小尺度的物体(细杆、人)的分割效果,在高分辨率的图像(2.0x)上分割效果更好;而道路则在低分辨率(0.5x)的图像上分割效果更好。
2.端到端模型设计
一个Backbone,多个分割头早期融合,多尺度训练和融合预测
实现方式
提取特征的backbone
采用HRNet 通过并行多个分辨率的分支,加上不断进行不同分支之间的信息交互,同时达到强语义信息和精准位置信息的目的。
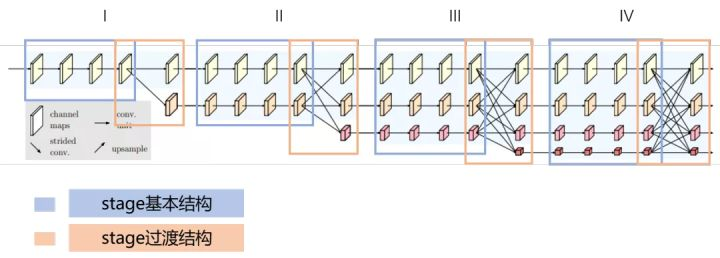
使用了PaddleSeg HRNet_W48预训练模型(https://bj.bcebos.com/paddleseg/dygraph/hrnet_w48_ssld.tar.gz)
语义头
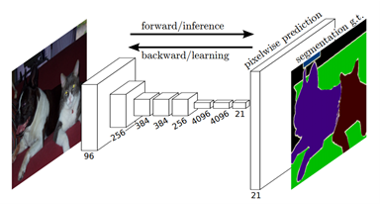
注意力头
代码说明
模型
模型是在FCN基础上修改为FCN2,源文件为/home/aistudio/PaddleSeg/dygraph/paddleseg/models/fcn2.py
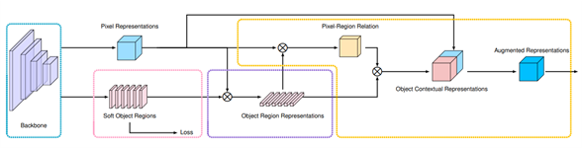
在FCN分割头基础增加OCR分割头
融合FCN和OCR分割头的结果:
模型初始化时:
FCN分割头:self.head = FCNHead(num_classes, backbone_indices, backbone_channels,channels)
增加了OCR分割头:self.Ohead = OCRHead(num_classes,backbone_channels)
前向计算时:
HrNet特征提取:feat_list = self.backbone(x)
FCN分割:logit_list = self.head(feat_list)
Ocr分割:logit_list1 = self.Ohead(feat_list)
两个分割头的结果平均融合:avg_logit=(logit_list[0]+logit_list1[0])/2
训练过程
配置文件为/home/aistudio/PaddleSeg/dygraph/benchmark/fcn2.yml
单尺度训练过程分为三次:
第一次,参数为
iters: 40000
learning_rate:0.01
decay:
type: poly
power: 0.9
end_lr: 0.0
optimizer:sgd,
crop_size: [1280, 360]
预训练模型为https://bj.bcebos.com/paddleseg/dygraph/hrnet_w48_ssld.tar.gz,单卡需要二十个小时左右。
第二次,参数为
iters: 40000
learning_rate:0.01
decay:
type: poly
power: 0.9
end_lr: 0.0
optimizer:sgd,
crop_size: [1280, 360]
预训练模型为第一次训练输出的best_model中的模型,单卡需要二十个小时左右;
最后一次,参数为
iters: 10000
learning_rate:0.001
decay:
type: poly
power: 0.9
end_lr: 0.0
optimizer:sgd,
crop_size: [1280, 360]
预训练模型为第二次训练输出的best_model中的模型,单卡需要十个小时左右。
由于时间关系,两个尺度的训练未完成,分别是用crop_size: [1280, 540]和crop_size: [1280,720],训练也可按如上过程进行。复赛B榜提交的结果是单模型的结果。
运行说明
AiStudio环境 python 3.7 PaddlePaddle 2.0.0rc PaddleSeg 0.6
代码在/home/aistudio/PaddleSeg/dygrap目录下,数据在/home/aistudio/data目录下。
本NoteBook可以直接运行训练,也可以生成版本后,通过创建任务进行训练。
使用脚本任务进,训练、评估和预测三步不可同时进行,导入任务执行结果,预测结果输出。
#解压数据集。数据集是将初赛和复赛数据整合起来
!unzip /home/aistudio/data/data61166/Dataset.zip -d /home/aistudio/data/
#使用PaddleSeg动态图,安装动态图环境
%cd /home/aistudio/PaddleSeg/dygraph
!export PYTHONPATH=`pwd`
!pip install -r requirements.txt
#切分数据集。生成训练集文件列表、验证集文件列表、测试集文件列表
import numpy as np
import os
base = '/home/aistudio/data/Dataset/'
with open('/home/aistudio/data/Dataset/labels.txt', 'w') as f:
for i in range(20):
f.write(str(i)+'\n')
imgs = os.listdir(base+'train/')
np.random.seed(5)
np.random.shuffle(imgs)
val_num = int(0.1 * len(imgs))
with open(os.path.join('/home/aistudio/data/Dataset/train.txt'), 'w') as f:
for pt in imgs[:-val_num]:
img = base+'train/'+pt
ann = base+'train_label/'+pt.replace('.jpg', '.png')
info = img + ' ' + ann +'\n'
f.write(info)
with open(os.path.join('/home/aistudio/data/Dataset/val.txt'), 'w') as f:
for pt in imgs[-val_num:]:
img = base+'train/'+pt
ann = base+'train_label/'+pt.replace('.jpg', '.png')
info = img + ' ' + ann + '\n'
f.write(info)
with open(os.path.join('/home/aistudio/data/Dataset/test.txt'), 'w') as f:
for pt in os.listdir(base+'testB/'):
img = base+'testB/'+pt
info = img + '\n'
f.write(info)
#训练
!export CUDA_VISIBLE_DEVICES=0
!python train.py --config /home/aistudio/PaddleSeg/dygraph/benchmark/fcn2.yml --do_eval --save_interval 5000 --save_dir /home/aistudio/PaddleSeg/dygraph/output/fcn2 >fcn2-train-1122.log
#评估
!export CUDA_VISIBLE_DEVICES=0
!python val.py --config /home/aistudio/PaddleSeg/dygraph/benchmark/fcn2.yml --model_path /home/aistudio/PaddleSeg/dygraph/output/model.pdparams >val.log
#预测 PaddleSeg/dygraph/paddleseg/core/predict.py 在原版本修改了,只输出单通道灰度图
#训练结束后,根据模型所在路径,修改后进行预测。
#复赛结果所用模型在/home/aistudio/PaddleSeg/dygraph/output/model.pdparams
!export CUDA_VISIBLE_DEVICES=0
!python predict.py --config /home/aistudio/PaddleSeg/dygraph/benchmark/fcn2.yml --model_path /home/aistudio/PaddleSeg/dygraph/output/model.pdparams --image_path /home/aistudio/data/Dataset/testB --save_dir /home/aistudio/PaddleSeg/dygraph/output/fcn2-1120/result
#多尺度预测融合。因多尺度训练未完成,无需执行此步
#多尺度训练结束后,根据模型所在路径,进行多尺度预测融合
!export CUDA_VISIBLE_DEVICES=0
!python mul_pred.py --config /home/aistudio/PaddleSeg/dygraph/benchmark/fcn2.yml --model_path /home/aistudio/PaddleSeg/dygraph/output/model.pdparams --image_path /home/aistudio/data/Dataset/testB --save_dir /home/aistudio/PaddleSeg/dygraph/output/fcn2-1120/mp_result
总结
单模型多分割头早期融合效果较好,还做过一个Gcnet和ANN融合的版本Gcnet2,相应的模型和配置文件与上面fcn2的目录相同,在本数据集也有一定的提升。
多尺度预测方法有待进一步验证。复赛提交的结果只是Fcn2的结果,因为时间所限,多尺度训练没有完成。在其他数据集上测试过,有一定的提升效果。
这是图像分割7日打卡营学习后,参加的第一个正式比赛,全程使用AI Studio和PaddleSeg。
非常感谢百度的老师们和开发者。

下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2020 在「AI算法与图像处理」公众号后台回复:CVPR2020,即可下载1467篇CVPR 2020论文 个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
觉得不错就点亮在看吧
