CDH6.3.2企业级安装实战(二)
五、HDFS HA配置
启用和禁用高可用性会导致HDFS服务以及所有依赖HDFS的服务中断。在启用或禁用HA之前,请确保集群上没有正在运行的作业。
启动 HA 前,存在 SecondaryNameNode:
1、启用 High Avaliaability
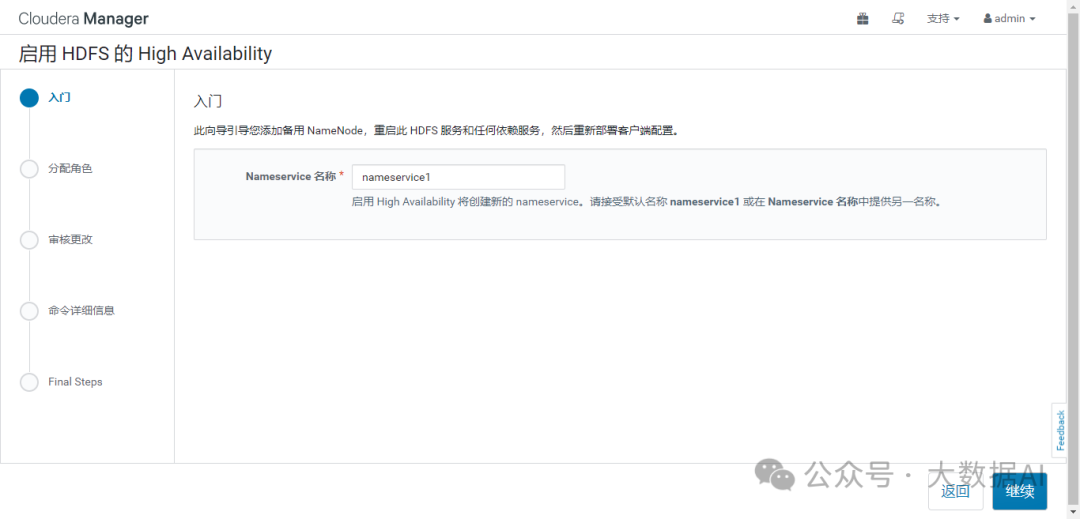
2、Nameservice 名称
我们建议在具有与 NameNode 相似硬件规格的机器上承载 JournalNode。通常,NameNode 和 ResourceManager 的主机都是不错的选择。您必须要有至少三个以上的奇数 JournalNode。
JournalNode的作用是共享存储,它是主备NameNode节点都可读写的共享目录,系统是否可用也受限于共享目录是否可用, JournalNode的实现使用的是类Paxos思想。就是多数服从少数。要想区分多和少,就只能是奇数个节点。不是说至少3个,你部署一个,应该是没问题的。
在往JournalNode写数据的时候,是并发多个节点同时写的,只要有 n / 2 + 1个节点返回成功,就代表数据写入成功,这样即不影响效率,又能保证数据的安全。
3、分配角色
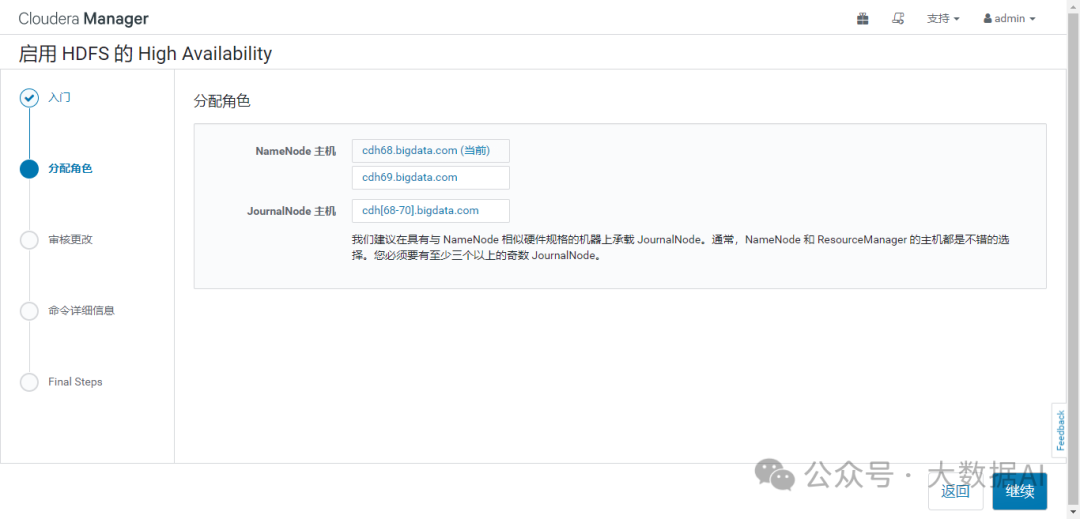
这里必须至少有三个JournalNode守护程序,因为必须将 edit log 修改内容写入大多数JournalNode。
HA是使用Quorum-based storage来实现的。Quorum-based storage依赖于一组JournalNode,每个JournalNode维护一个本地编辑目录,该目录将对修改的记录记录到名称空间元数据中。
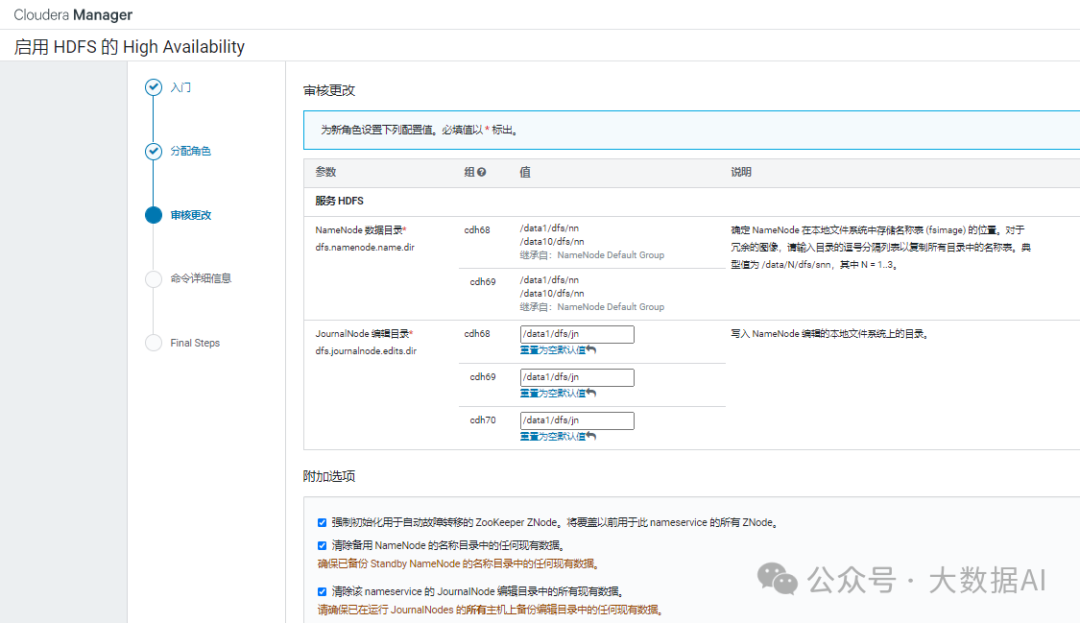
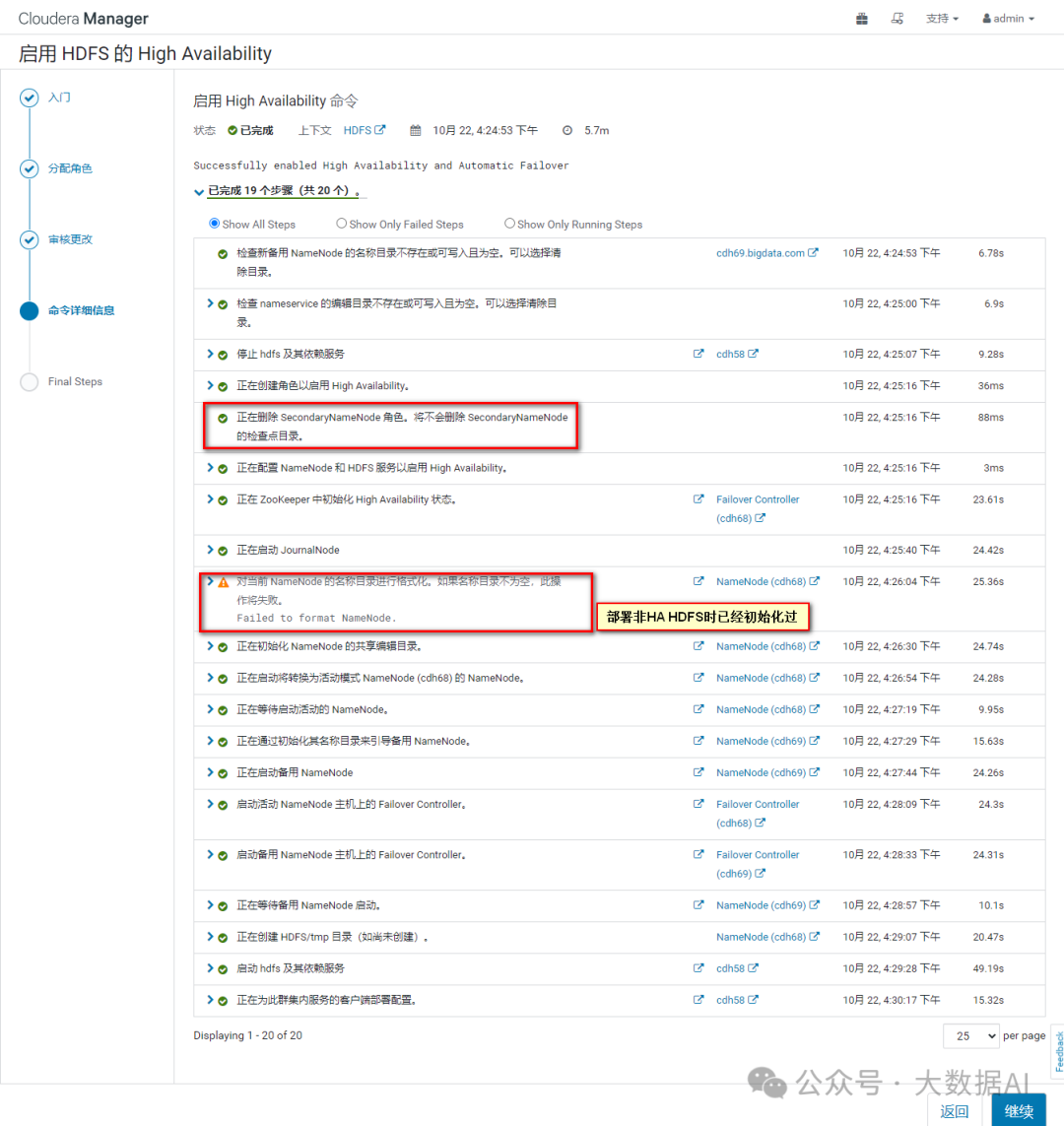
4、部署完成
dfs.namenode.name.dir
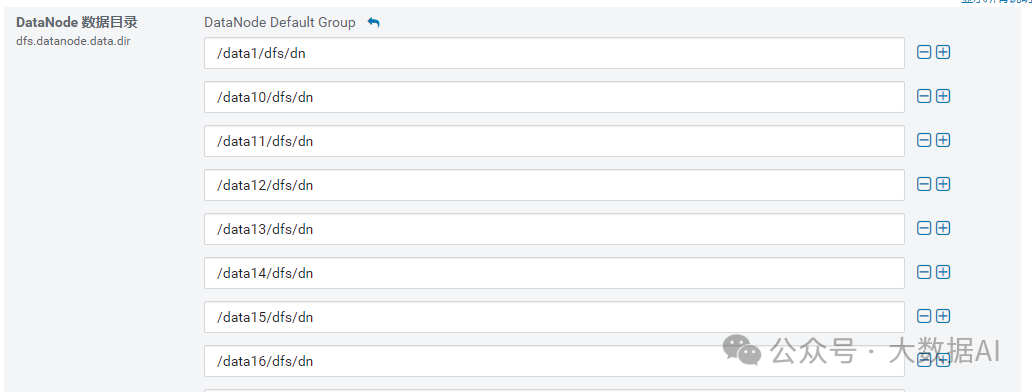
dfs.namenode.name.dir

dfs.namenode.edits.dir

dfs.datanode.data.dir.perm
 DataNode 数据目录权限
DataNode 数据目录权限5、查看HA
namenode active
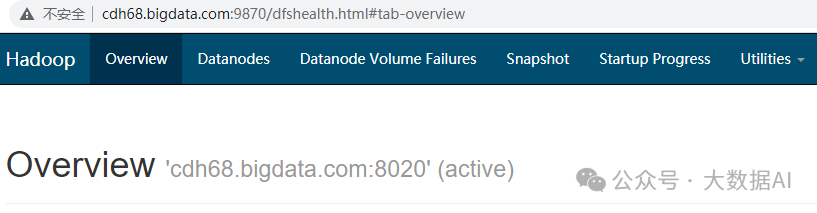
name standby
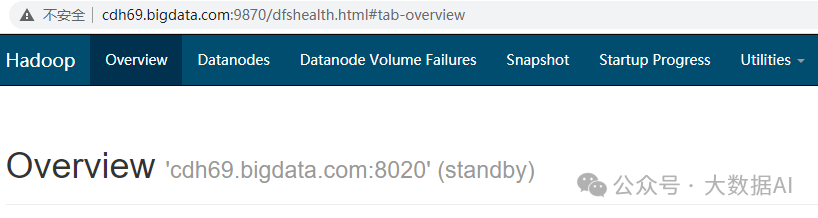
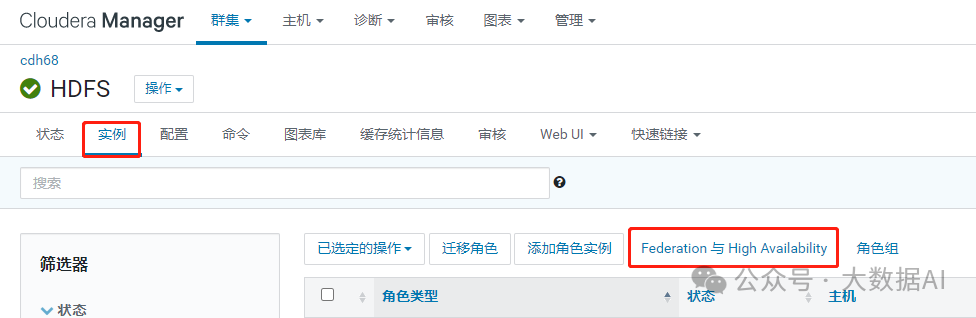
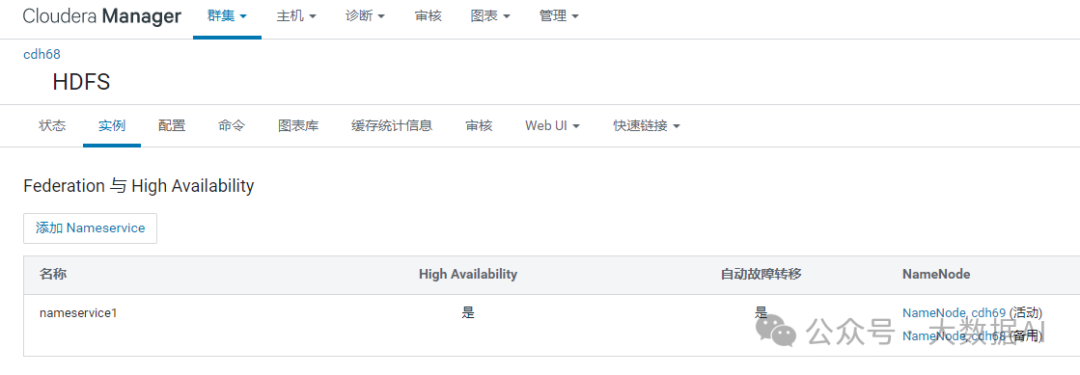
6、查看nameservice
HDFS 实例 --> Federation 与 High Availability
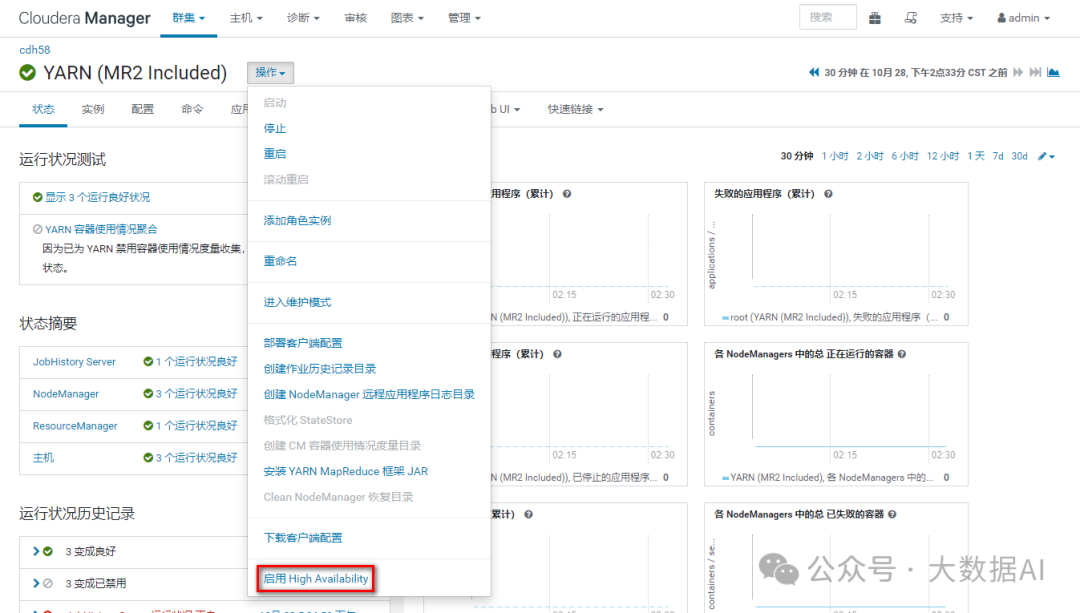
六、YARN HA 配置
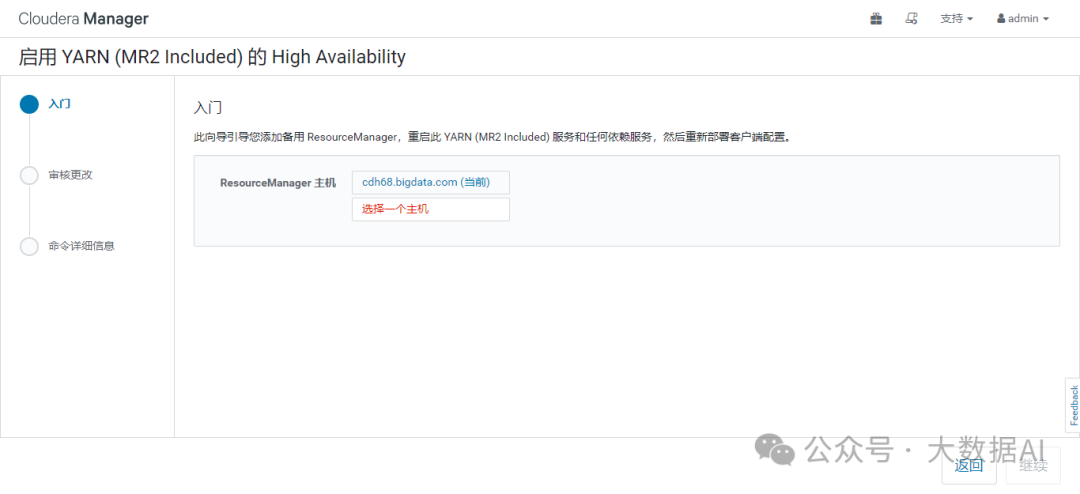
1、启用 High Availability
2、选择HA主机
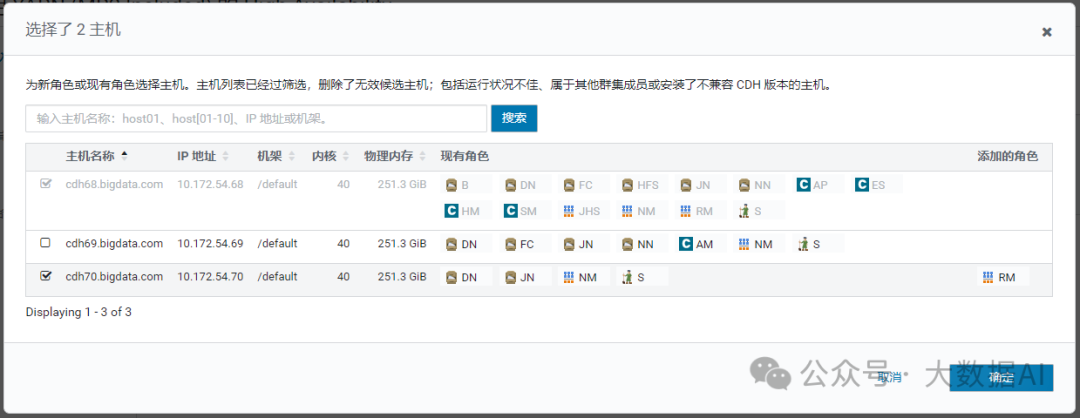
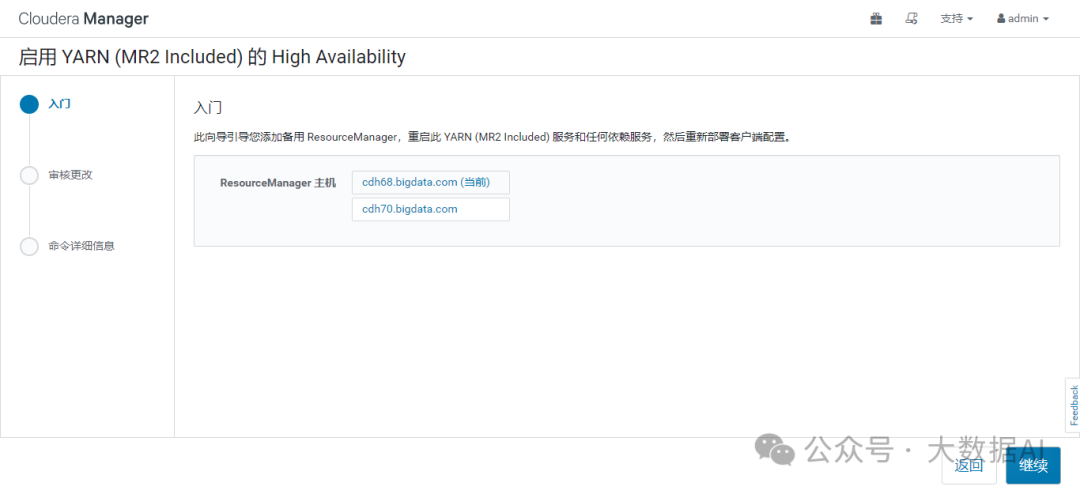
3、部署完成
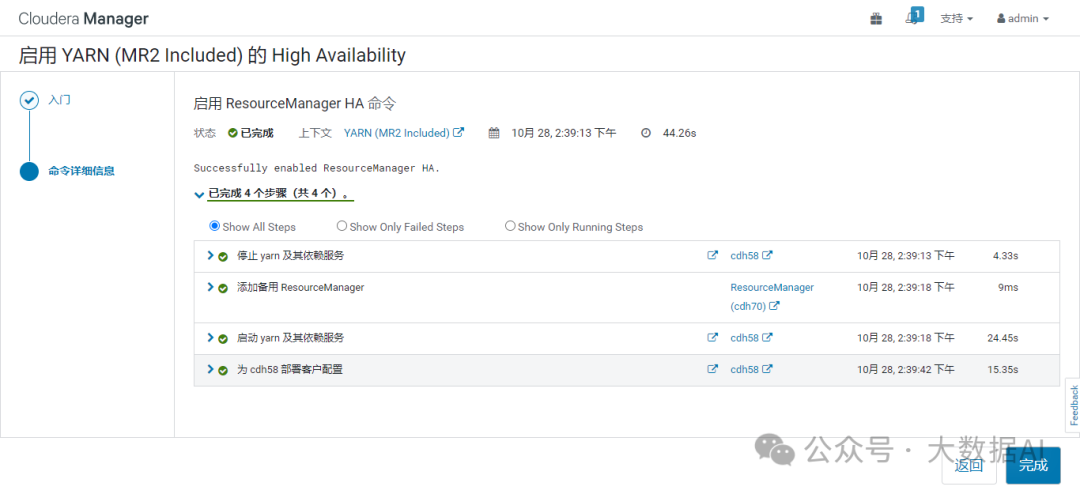
4、查看HA
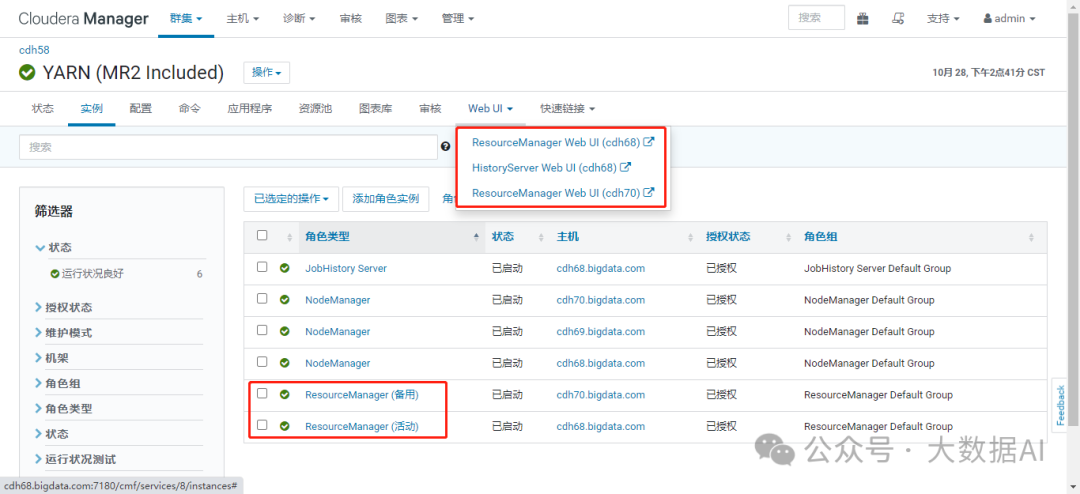
七、安装之后
1、Testing the Installation
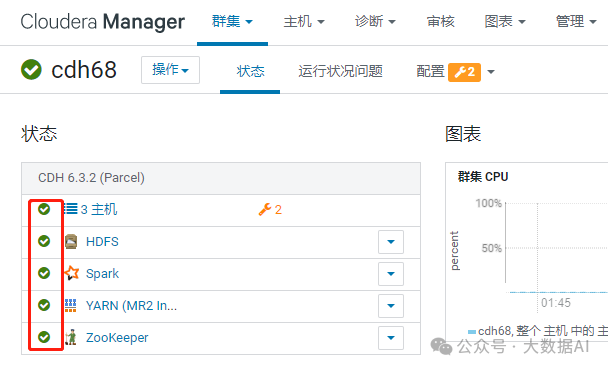
 表示Good Health
表示Good Health
检查主机心跳
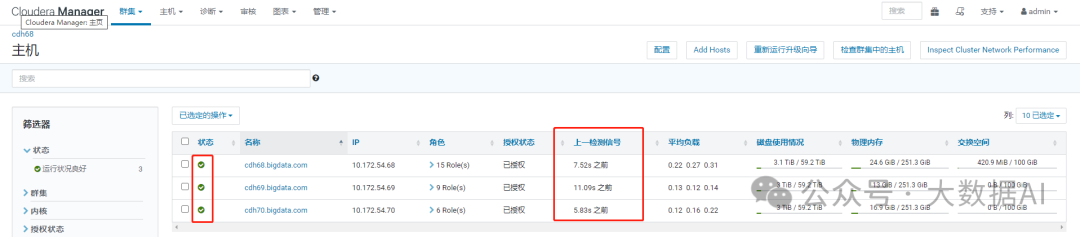
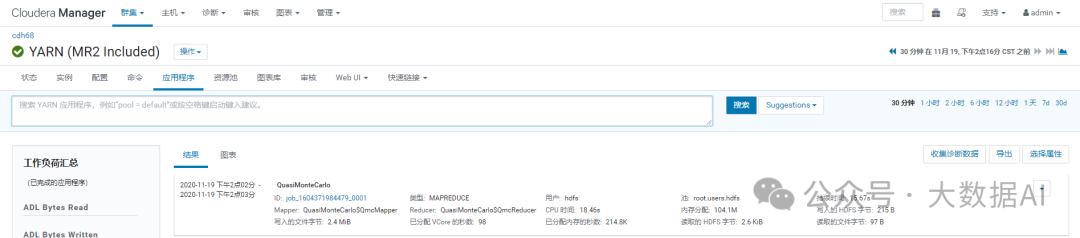
Running a MapReduce Job
[cuadmin@cdh68 ~]$ sudo -u hdfs hadoop jar /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar pi 10 100
Number of Maps = 10
Samples per Map = 100
Wrote input for Map #0
Wrote input for Map #1
Wrote input for Map #2
Wrote input for Map #3
Wrote input for Map #4
Wrote input for Map #5
Wrote input for Map #6
Wrote input for Map #7
Wrote input for Map #8
Wrote input for Map #9
Starting Job
20/11/19 14:02:39 INFO impl.YarnClientImpl: Submitted application application_1604371984479_0001
20/11/19 14:02:39 INFO mapreduce.Job: The url to track the job: http://cdh68.bigdata.com:8088/proxy/application_1604371984479_0001/
20/11/19 14:02:39 INFO mapreduce.Job: Running job: job_1604371984479_0001
20/11/19 14:02:48 INFO mapreduce.Job: Job job_1604371984479_0001 running in uber mode : false
20/11/19 14:02:48 INFO mapreduce.Job: map 0% reduce 0%
20/11/19 14:02:55 INFO mapreduce.Job: map 100% reduce 0%
20/11/19 14:03:03 INFO mapreduce.Job: map 100% reduce 100%
20/11/19 14:03:03 INFO mapreduce.Job: Job job_1604371984479_0001 completed successfully
20/11/19 14:03:03 INFO mapreduce.Job: Counters: 54
Job Finished in 25.901 seconds
Estimated value of Pi is 3.14800000000000000000
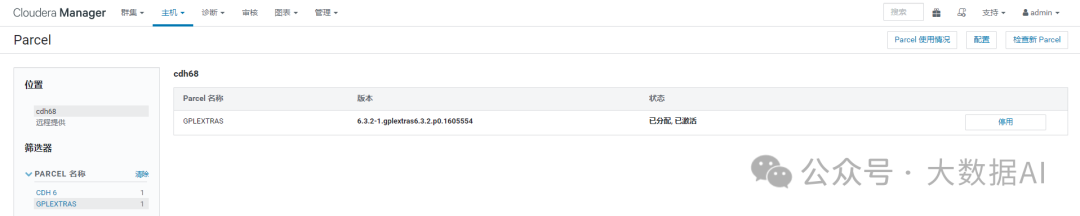
2、Installing the GPL Extras Parcel
GPL Extras contains functionality for compressing data using the LZO compression algorithm.
-
Download, distribute, and activate the parcel.
在配置 CDH 远程仓库时,我们已经下载了 GPL Parcel包,故安装集群时已经激活。
-
The LZO parcels require that the underlying operating system has the native LZO packages installed. If they are not installed on all cluster hosts, you can install them as follows:
sudo yum install lzo
八、Hive安装
1、安装
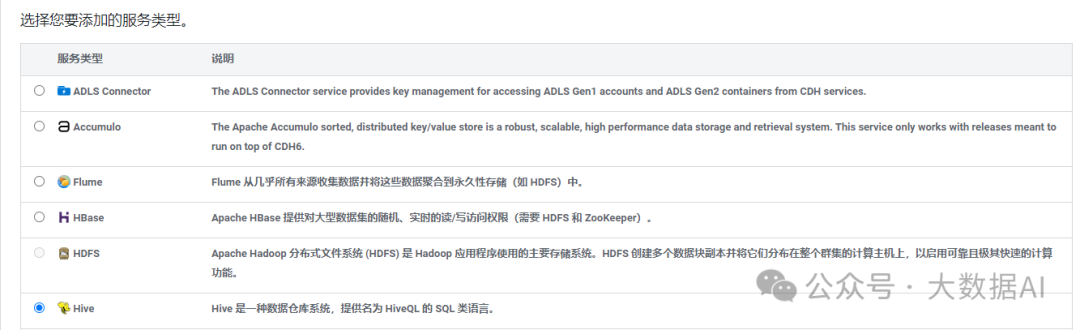
- 添加服务
- 选择Hive服务
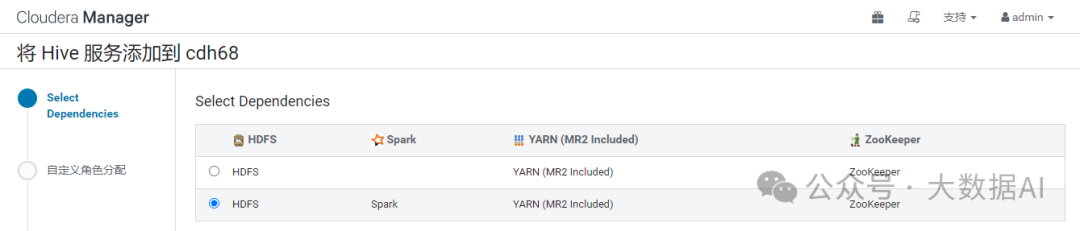
- 选择依赖
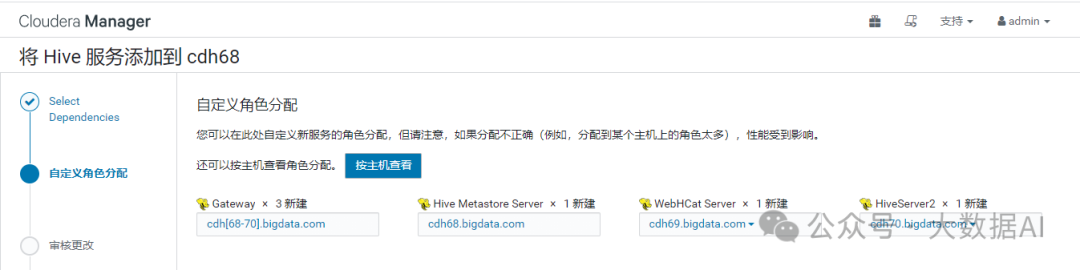
- 自定义角色分配
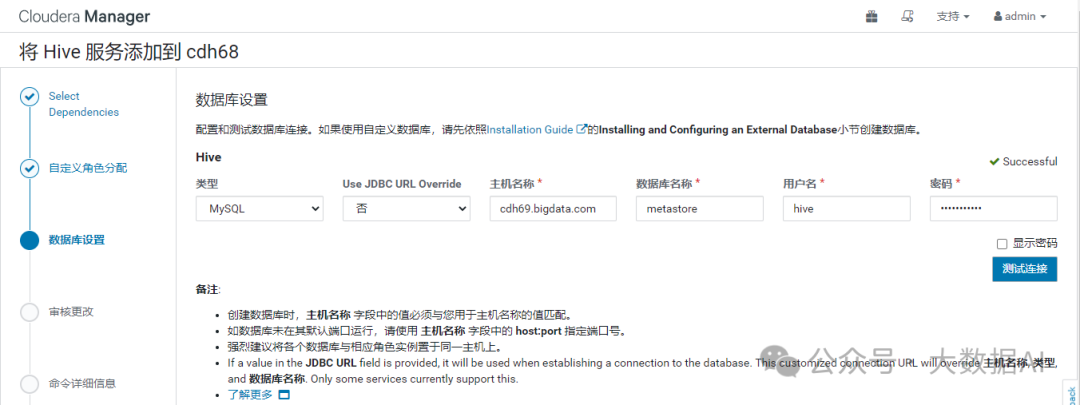
- 数据库设置
- 审核更改
- 命令详细信息
如果报如下错误:
HiveMetaException: Failed to retrieve schema tables from Hive Metastore DB,Not supported
Mysql JDBC驱动包导致的,使用yum安装的驱动包不可用。下载并使用较新版本的驱动包可解决这个问题。
驱动包最新版本是5.1.49,亲测可用。
- 汇总
- 查看状态
2、生产环境部署架构
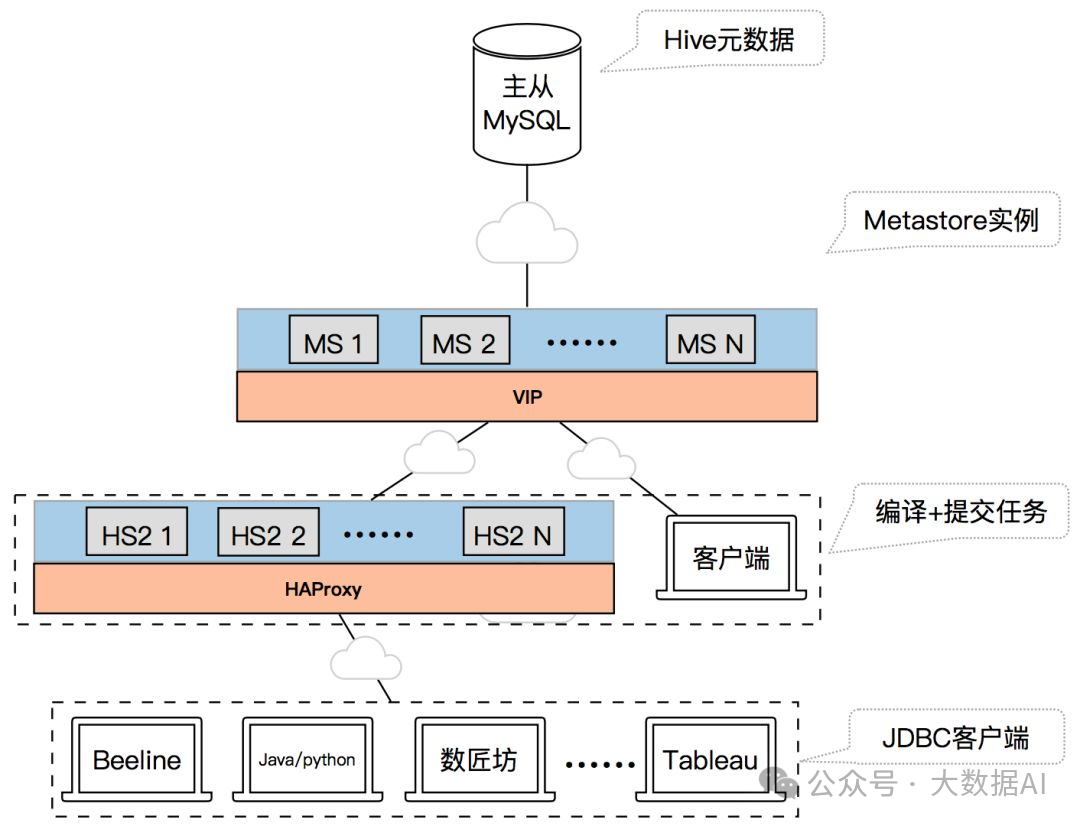
该架构体系中用户使用的 Hive 客户端或者 Hivesever2 服务、Spark 引擎、Presto 引擎等都是访问统一 Hive Metastore 服务获取 Hive 元数据。
Hive Metastore 服务主要是使用 LVS + 多个 Hive Metastore 实例组成。所有的 Hive Metastore 实例共享一套主从 MySQL 环境作为 Hive 元数据存储 DB。
3、Hive Metastore Server HA
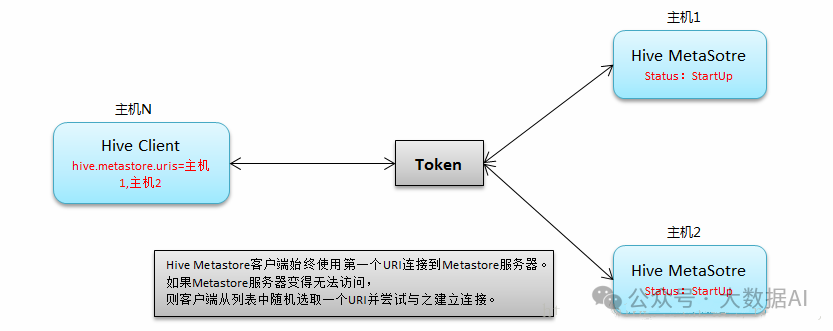
Metastore HA解决方案被设计用来处理metastore服务故障。当一个部署的metastore宕机时,metastore服务可能持续相当长的时间不可用,直到服务被重新拉起。为了避免这种服务中断情况,需要部署Hive Metastore HA模式。Cloudera建议Metastore的每个实例在单独的集群主机上运行,突出高可用作用。
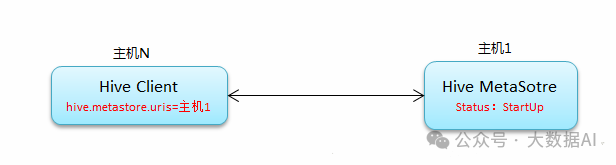
1、工作原理
常规连接:
Metastore HA:
2、配置 Metastore HA
官方教程:https://docs.cloudera.com/documentation/enterprise/6/6.3/topics/admin_ha_hivemetastore.html
未配置HA之前只有一个Metastore:
hive-site.xml配置如下:
<property>
<name>hive.metastore.uris</name>
<value>thrift://cdh68.bigdata.com:9083</value>
</property>
新增一个Hive Metastore Server
部署Hive Metastore Server
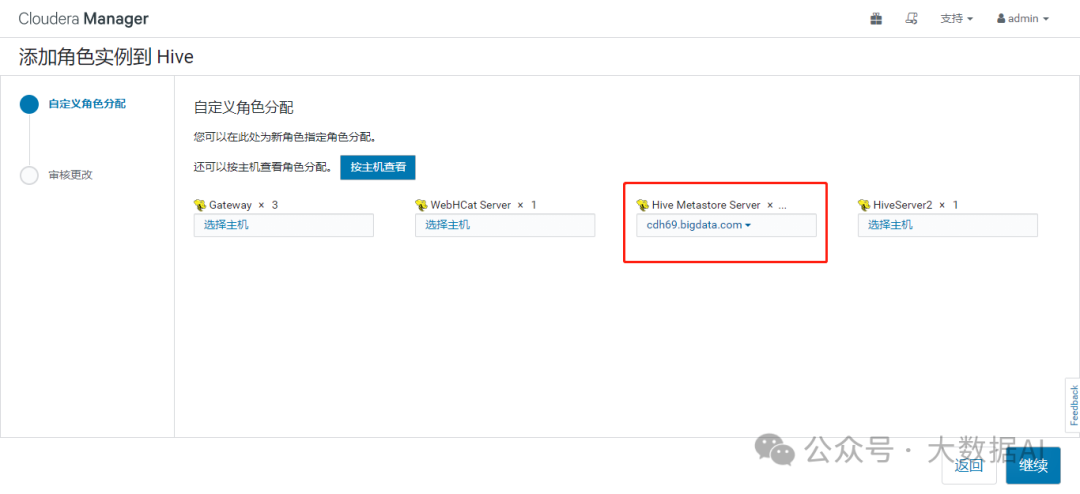
配置更新明细
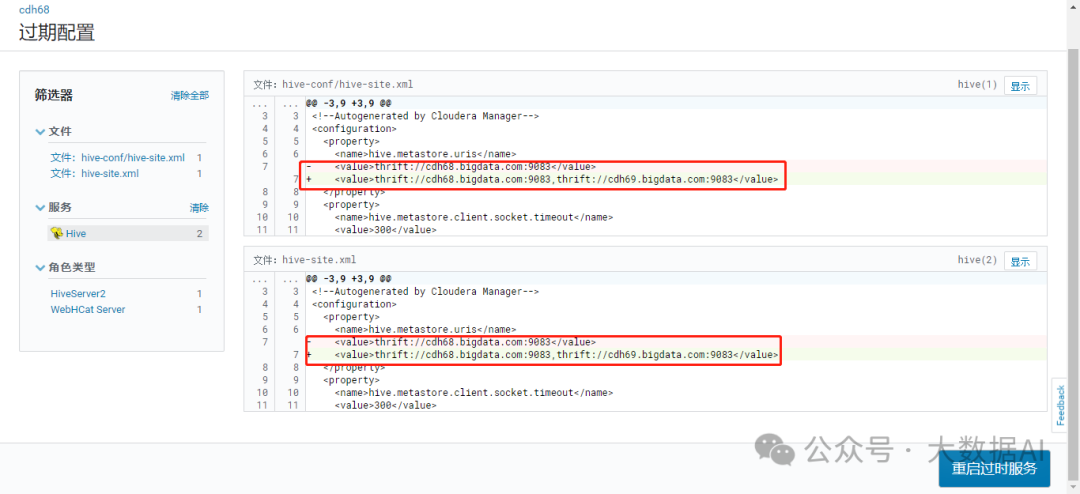
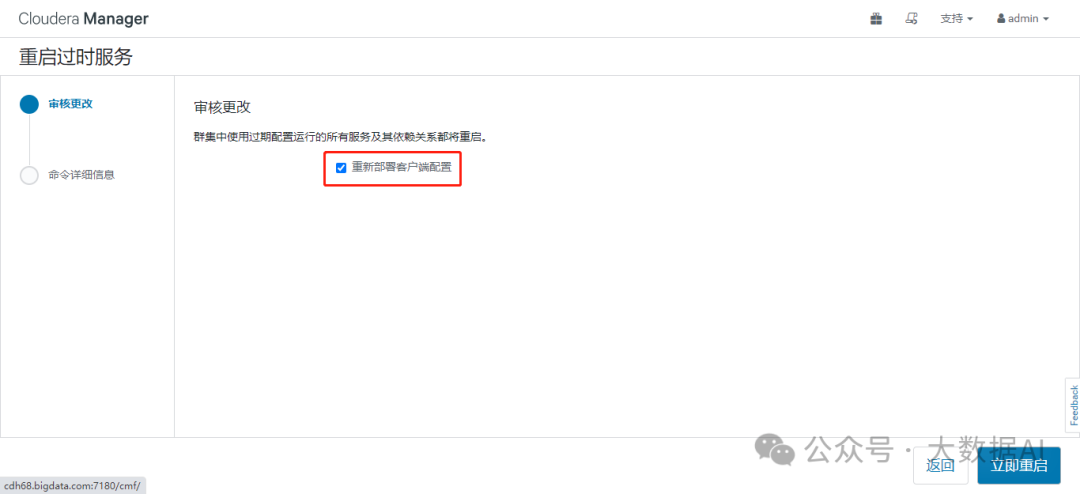
重启服务,重新部署客户端配置
查看部署的 Hive Metastore Server
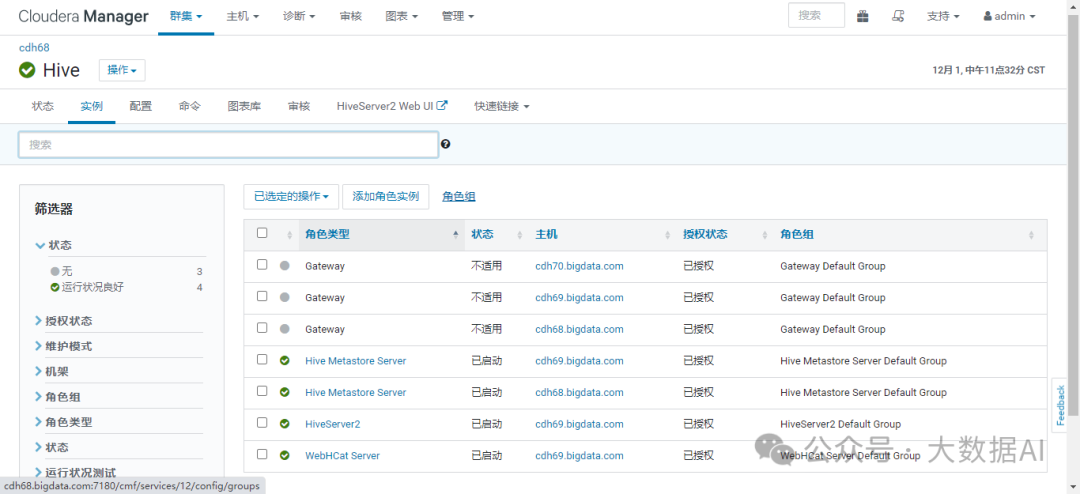
查看hive-site.xml配置文件:
<property>
<name>hive.metastore.uris</name>
<value>thrift://cdh68.bigdata.com:9083,thrift://cdh69.bigdata.com:9083</value>
</property>
4、HiveServer2 HA
官方教程:https://docs.cloudera.com/documentation/enterprise/6/6.3/topics/admin_ha_hiveserver2.html
在生产环境中使用Hive,强烈建议使用HiveServer2来提供服务,好处很多:
- 在应用端不用部署Hadoop和Hive客户端;
- 相比hive-cli方式,HiveServer2不用直接将HDFS和Metastore暴漏给用户;
- 有安全认证机制,并且支持自定义权限校验;
- 有HA机制,解决应用端的并发和负载均衡问题;
- JDBC方式,可以使用任何语言,方便与应用进行数据交互;
- 从2.0开始,HiveServer2提供了WEB UI。
如果使用HiveServer2的Client并发比较少,可以使用一个HiveServer2实例,没问题。
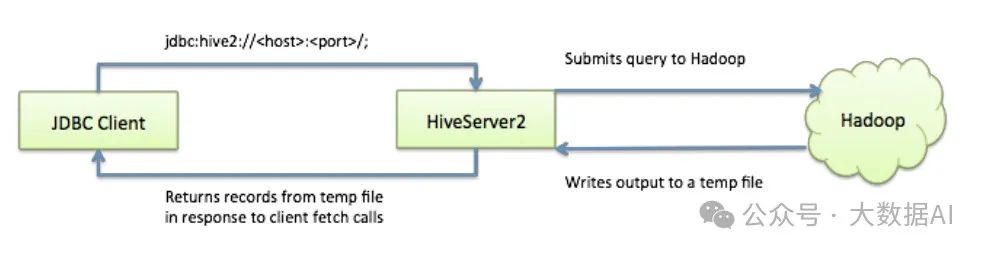
但如果这一个实例挂掉,那么会导致所有的应用连接失败。
1、新增 HiveServer2实例
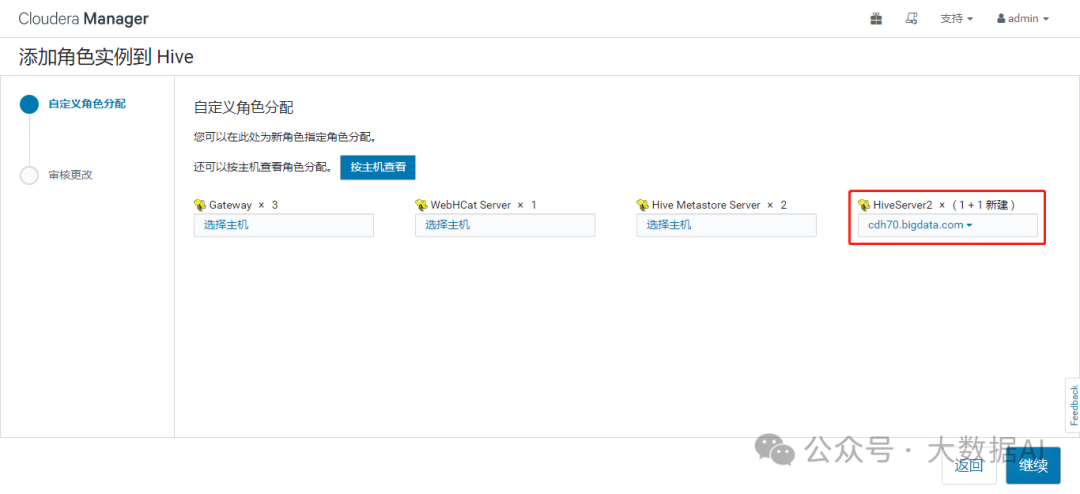
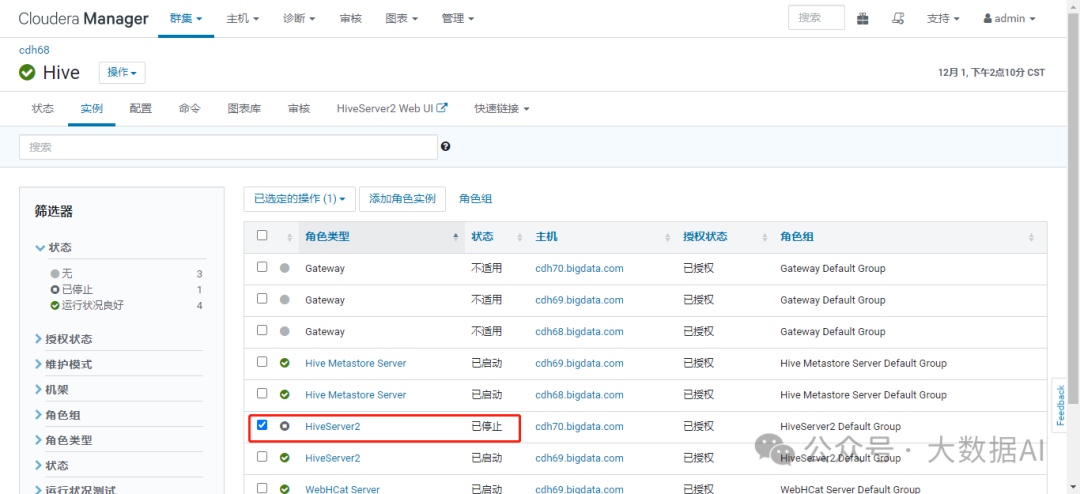
启动新增的 HiveServer2
查看新增HiveServer2实例
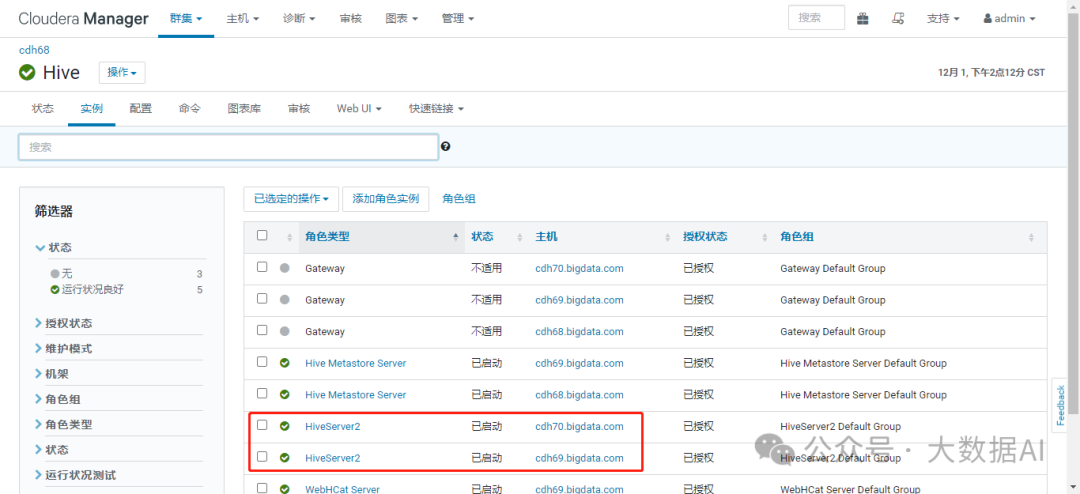
2、使用nginx实现HiveServer2 HA
我们常常会碰到企业已经在用Nginx,Nginx毕竟在http和反向代理这块是最优秀的,这个时候我们就需要考虑复用Nginx。
-
安装nginx
[song@cdh68 ~]$ sudo yum install -y nginx
-
配置HiveServer2负载均衡策略
/etc/nginx/nginx.cfg
stream{
log_format basic '$remote_addr [$time_local] ' '$protocol $status $bytes_sent $bytes_received' '$session_time';
upstream hiveserver2 {
least_conn; #路由策略:least_conn:最少连接
server cdh69.bigdata.com:10000;
server cdh70.bigdata.com:1000;
}
server{ #hiveserver2 jdbc 负载均衡
listen 10010;
proxy_pass hiveserver2;
}
}
重新加载Nginx配置
[song@cdh68 ~]$ sudo nginx -s reload
-
JDBC Beeline测试
[song@cdh68 ~]$ beeline -u jdbc:hive2://cdh68.bigdata.com:10010/default -n song
Connecting to jdbc:hive2://cdh68.bigdata.com:10010/default
Connected to: Apache Hive (version 2.1.1-cdh6.3.2)
Driver: Hive JDBC (version 2.1.1-cdh6.3.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 2.1.1-cdh6.3.2 by Apache Hive
0: jdbc:hive2://cdh68.bigdata.com:10010/defau> show databases;
+----------------+
| database_name |
+----------------+
| default |
+----------------+
1 row selected (0.595 seconds)
0: jdbc:hive2://cdh68.bigdata.com:10010/defau>
-
配置HiveServer2 Balancer

此方法nginx存在单点故障,可以使用keepalive + nginx实现高可用
3、使用Zookeeper实现HiveServer2 HA
Hive从0.14开始,使用Zookeeper实现了HiveServer2的HA功能(ZooKeeper Service Discovery),Client端可以通过指定一个nameSpace来连接HiveServer2,而不是指定某一个host和port;
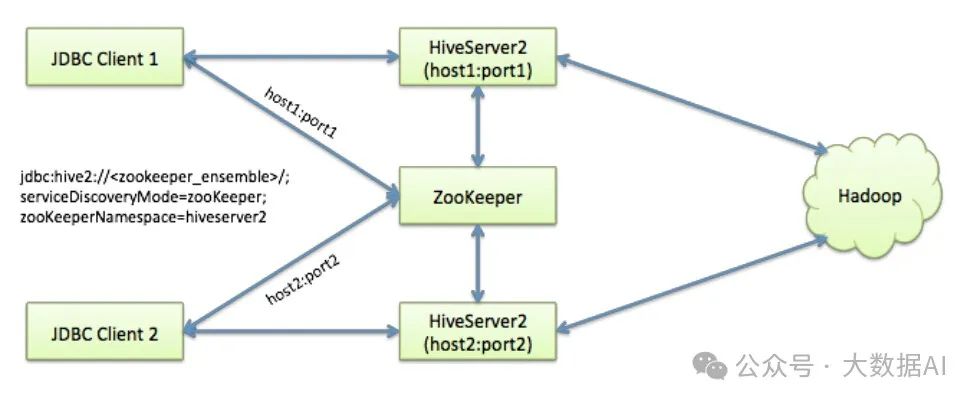
JDBC Client 首先访问Zookeeper,然后返回HiveServer2的host:port, 然后JDBC Client在根据Zookeeper返回的host:port 连接HiveServer2。
-
修改配置问题
具体配置如下 (在hive-site.xml中或者hiveserver2-site.xml 进行配置
这里注意 如果你在hiveserver2-site.xml 和hive-site.xml 均配置了一个参数,hiveserver2-site.xml将会覆盖hive-site.xml中的参数)
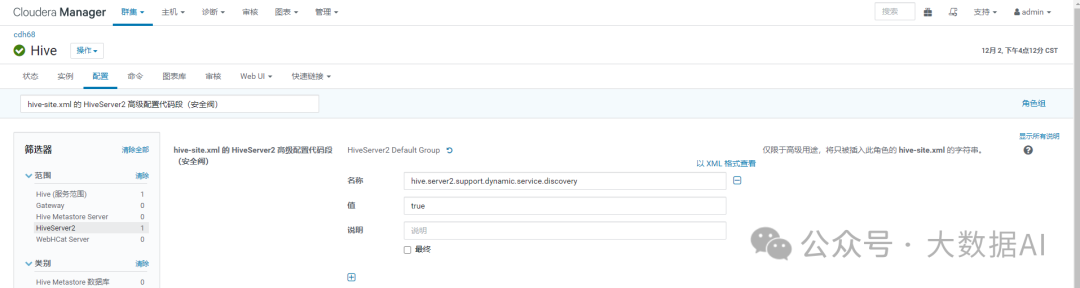
打开 Hive -> 配置-> 类别-> 高级,搜索"hive-site.xml 的 HiveServer2 高级配置代码段(安全阀)" 增加配置:
<property>
<name>hive.server2.support.dynamic.service.discovery</name>
<value>true</value>
</property>
下面可以不用设置,默认会直接在zookeeper创建 /hiveserver2,如果多个hive集群共用同一个zookeeper就需要单独设置):
<property>
<name>hive.server2.zookeeper.namespace</name>
<value>hiveserver2_zk</value>
</property>
重启 hiveserver2 服务并注册到 zookeeper。
-
验证zookeeper是否有hiveserver2信息
[song@cdh68 ~]$ zookeeper-client
[zk: localhost:2181(CONNECTED) 0] ls /
[hiveserver2, zookeeper, yarn-leader-election, hadoop-ha, rmstore, hive_zookeeper_namespace_hive]
[zk: localhost:2181(CONNECTED) 2] ls /hiveserver2
[serverUri=cdh69.bigdata.com:10000;version=2.1.1-cdh6.3.2;sequence=0000000001, serverUri=cdh70.bigdata.com:10000;version=2.1.1-cdh6.3.2;sequence=0000000000]
[zk: localhost:2181(CONNECTED) 3]
-
Beeline验证
JDBC连接的URL格式为:
jdbc:hive2://<zookeeper quorum>/<dbName>;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2
其中:
[song@cdh68 ~]$ beeline
beeline> !connect jdbc:hive2://cdh68.bigdata.com:2181,cdh69.bigdata.com:2181,cdh70.bigdata.com:2181/;serviceDiscoveryMode=zookeeper;zookeeperNamespace=hiveserver2 song ""
Connecting to jdbc:hive2://cdh68.bigdata.com:2181,cdh69.bigdata.com:2181,cdh70.bigdata.com:2181/;serviceDiscoveryMode=zookeeper;zookeeperNamespace=hiveserver2
20/12/02 17:21:36 [main]: INFO jdbc.HiveConnection: Connected to cdh69.bigdata.com:10000
Connected to: Apache Hive (version 2.1.1-cdh6.3.2)
Driver: Hive JDBC (version 2.1.1-cdh6.3.2)
+----------------+
| database_name |
+----------------+
| default |
+----------------+
1 row selected (0.686 seconds)
0: jdbc:hive2://cdh68.bigdata.com:2181,cdh69.>
遇到的问题:
[song@cdh68 ~]$ beeline -u jdbc:hive2://cdh68.bigdata.com:2181,cdh69.bigdata.com:2181,cdh70.bigdata.com:2181/;serviceDiscoveryMode=zookeeper;zookeeperNamespace=hiveserver2 song ""
Connecting to jdbc:hive2://cdh68.bigdata.com:2181,cdh69.bigdata.com:2181,cdh70.bigdata.com:2181/
20/12/02 17:34:29 [main]: WARN jdbc.HiveConnection: Failed to connect to cdh68.bigdata.com:2181
Unexpected end of file when reading from HS2 server. The root cause might be too many concurrent connections. Please ask the administrator to check the number of active connections, and adjust hive.server2.thrift.max.worker.threads if applicable.
Error: Could not open client transport with JDBC Uri: jdbc:hive2://cdh68.bigdata.com:2181/: null (state=08S01,code=0)
Beeline version 2.1.1-cdh6.3.2 by Apache Hive
beeline>
- 为Zookeeper的集群链接串,如zkNode1:2181,zkNode2:2181,zkNode3:2181
- 为Hive数据库,默认为default
- serviceDiscoveryMode=zooKeeper 指定模式为zooKeeper
- zooKeeperNamespace=hiveserver2 指定ZK中的nameSpace,即参数hive.server2.zookeeper.namespace所定义,默认为hiveserver2
九、Sqoop安装
-
添加服务
-
选择服务
-
自定义角色分配
-
命令详细信息
-
汇总
-
查看
十、HBase安装
1、安装
1.1 选择HBase服务
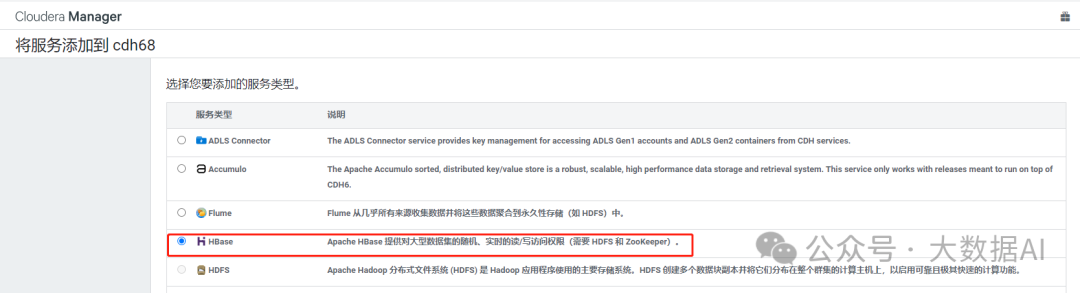
1.2 自定义角色分配
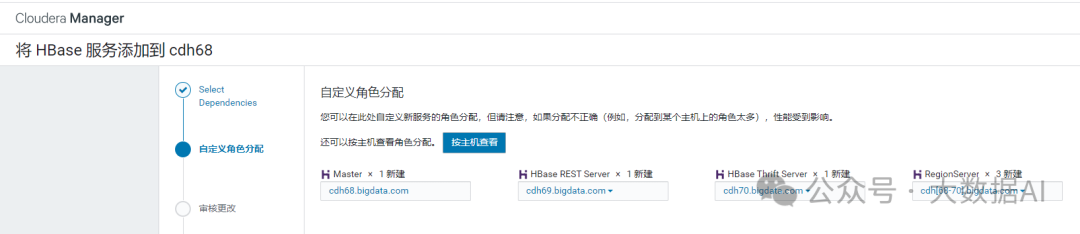
1.3 审核更改
1.4 命令详细信息
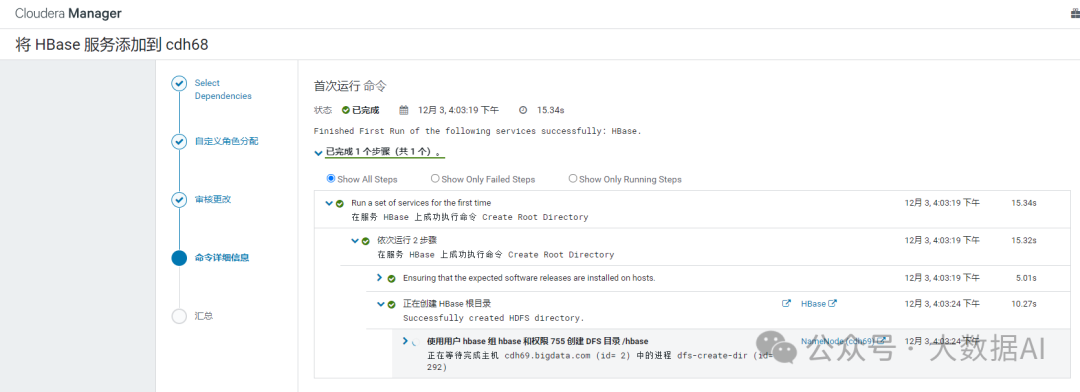
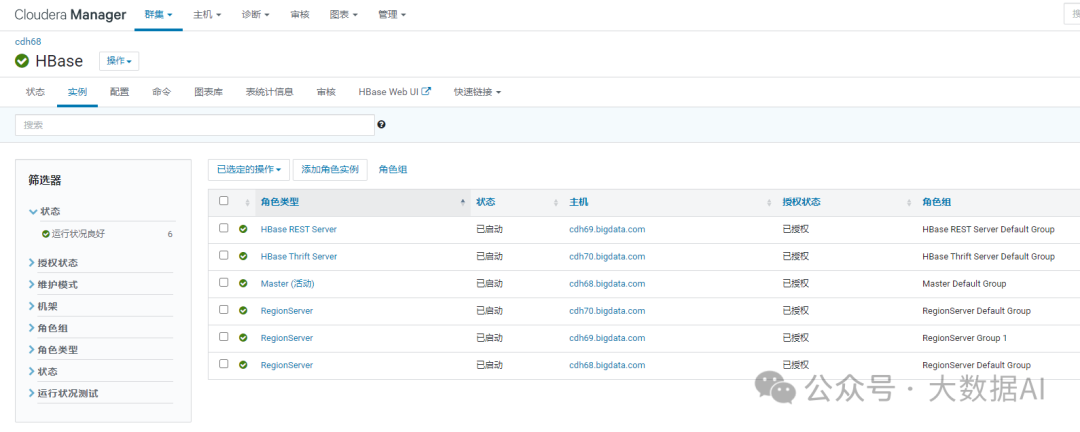
1.5 重启并查看
2、HBase HA
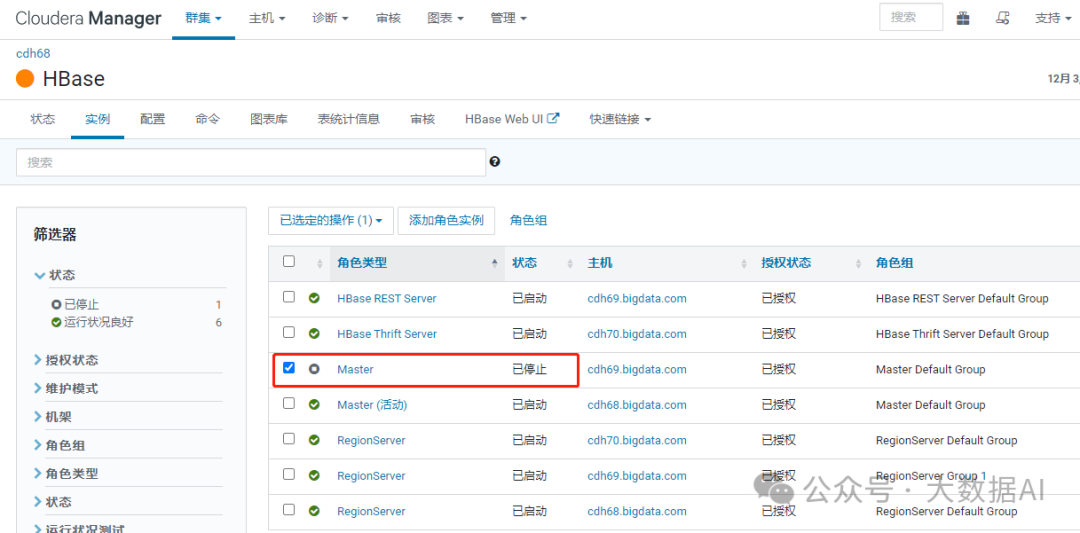
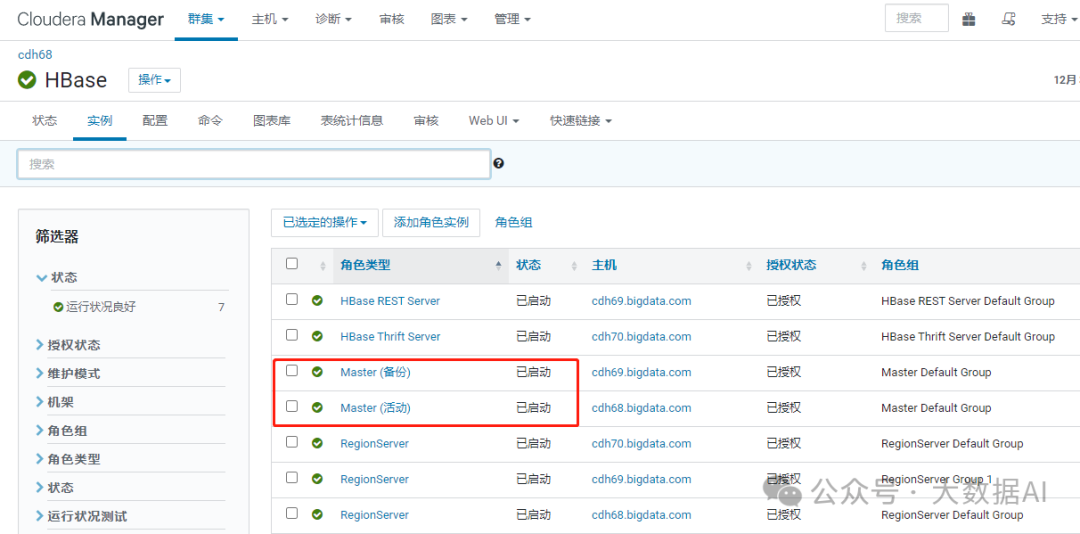
HBase 可以运行在多 Master 环境下,即集群中同时有多个 HMaster 实例,但只有一个HMaster 运行并接管整个集群。当一个 HMaster 激活时,Zookeeper 同时给它一个租期,当HMaster 的租期耗尽或意外停止时,Zookeeper 会及时运行另一个 HMaster 来接替它的工作
1、添加角色实例
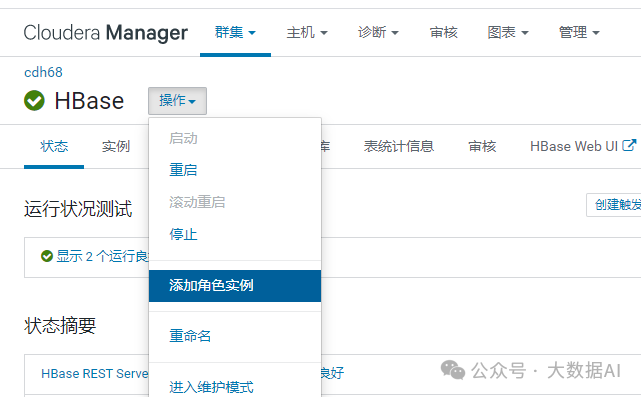
2、添加HMaster
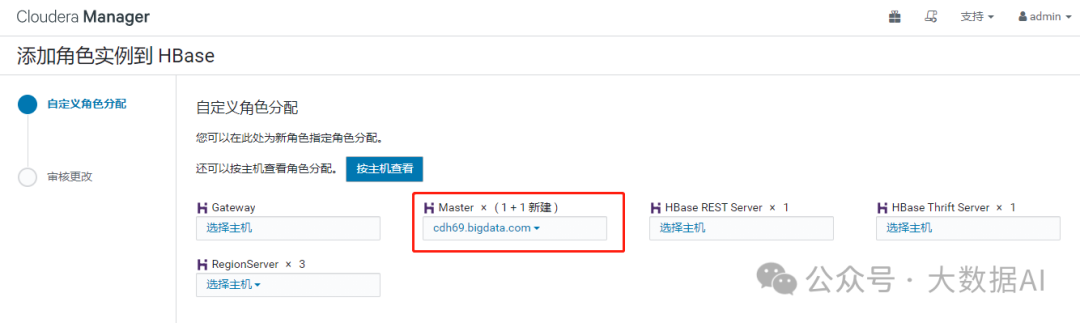
3、启动HMaster
十一、Oozie
1、安装
1.1 选择服务
1.2 选择依赖
1.3自定义角色分配
1.4 数据库设置
1.5 审核更改
1.6 命令详细信息
1.7 完成
2、Oozie Web console
CM安装完Oozie服务后,并没有安装好Oozie Web,如下如所示:
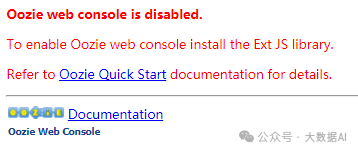
缺少ExtJs library:
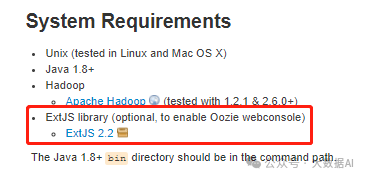
2.1 安装ExtJs 2.2
从网上下载ext-2.2.zip,并上传到服务器。 oozie安装时,所需要的js文件在ext-2.2.zip中,需要解压到oozie根目录/libext/文件中:
[song@cdh70 ~]$ sudo cp ext-2.2.zip /opt/cloudera/parcels/CDH/lib/oozie/libext/
[song@cdh70 ~]$ cd /opt/cloudera/parcels/CDH/lib/oozie/libext/
[song@cdh70 libext]$ sudo unzip ext-2.2.zip
[song@cdh70 libext]$ sudo chown oozie:oozie -R ext-2.2
再次访问 Oozie Web UI,可以正常访问了。
2.2 更改时区
3、Oozie HA
官方教程:https://docs.cloudera.com/documentation/enterprise/latest/topics/cdh_hag_oozie_ha.html
3.1 Nginx 配置 Oozie 负载均衡
[song@cdh68 ~]$ sudo vim /etc/nginx/nginx.conf
stream{
log_format basic '$remote_addr [$time_local] ' '$protocol $status $bytes_sent $bytes_received' '$session_time';
upstream oozie_ha {
least_conn; #路由策略:least_conn:最少连接
server cdh69.bigdata.com:11000;
server cdh70.bigdata.com:11000;
}
server{ # oozie 负载均衡
listen 11000;
proxy_pass oozie_ha;
}
}
[song@cdh68 ~]$ sudo nginx -s reload
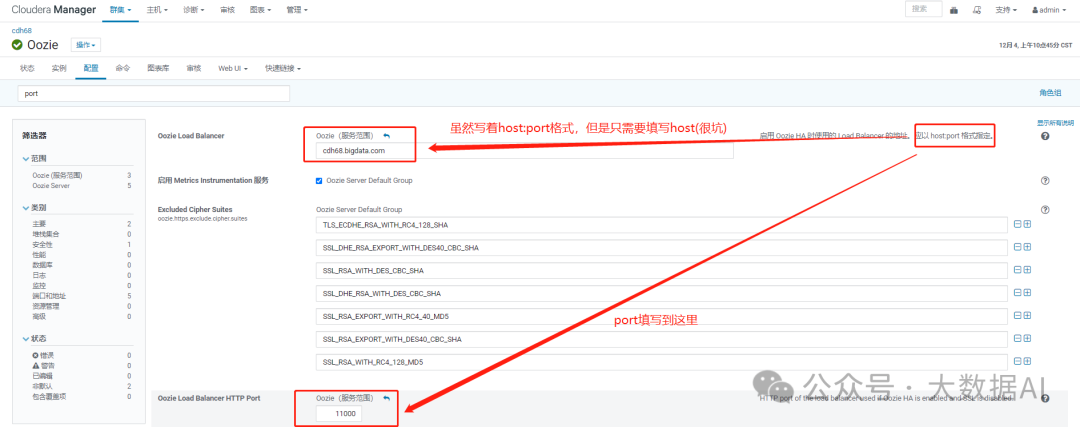
3.2 CM 启用 Oozie HA
-
填写 Oozie Load Banlancer 和 HTTP Port
-
启用High Availability
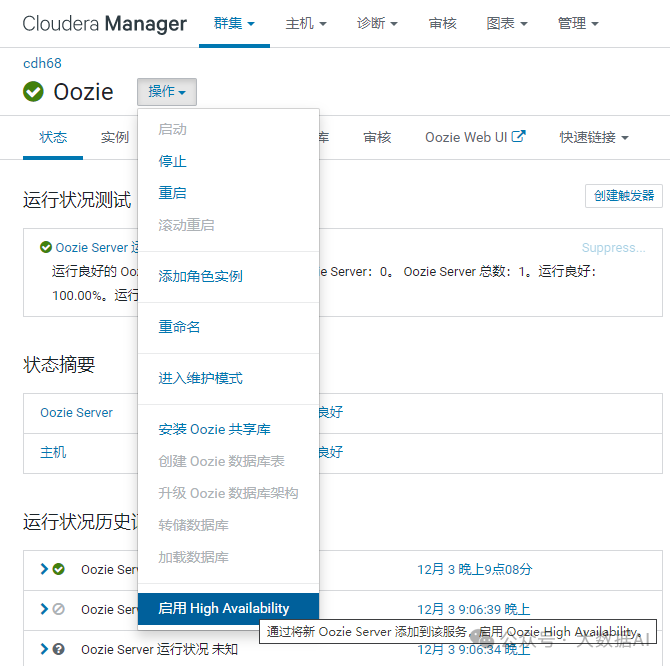
- 添加备用Oozie Server
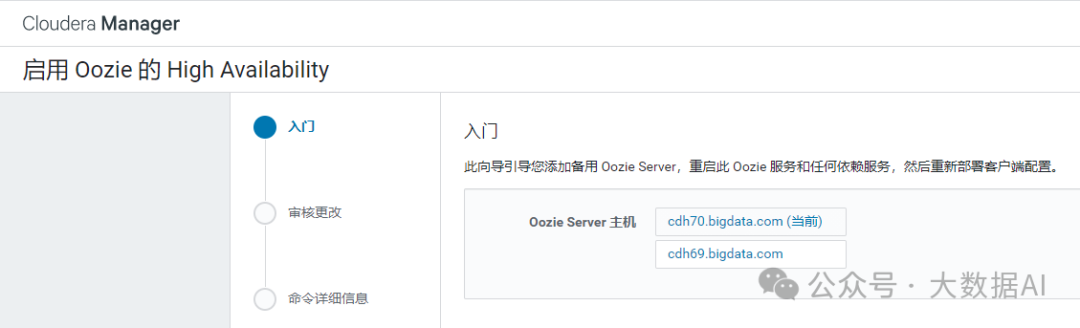
- 配置Oozie Load Balancer
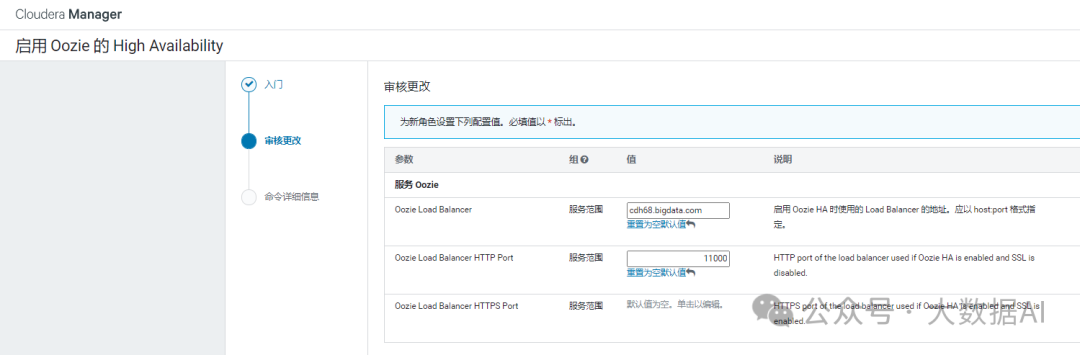
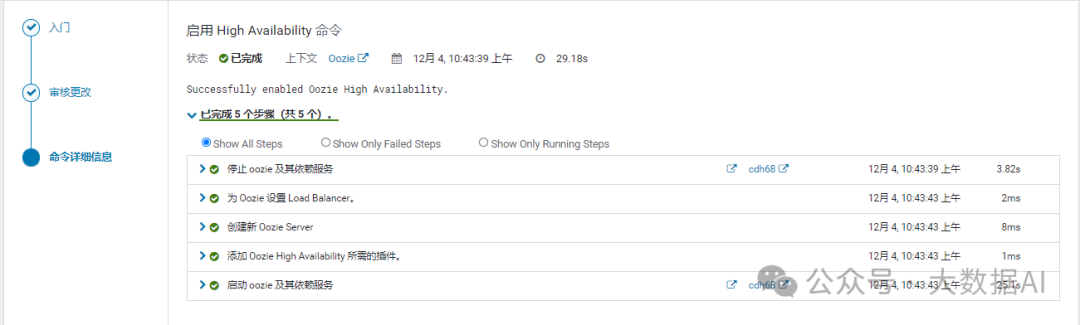
- 命令详细信息
3.3 配置备用Oozie Server的Web console
[song@cdh70 ~]$ scp ext-2.2.zip cdh69.bigdata.com:~
[song@cdh69 ~]$ sudo cp ext-2.2.zip /opt/cloudera/parcels/CDH/lib/oozie/libext/
[song@cdh69 ~]$ cd /opt/cloudera/parcels/CDH/lib/oozie/libext/
[song@cdh69 libext]$ sudo unzip ext-2.2.zip
[song@cdh69 libext]$ sudo chown oozie:oozie -R ext-2.2
3.4 查看Oozie HA
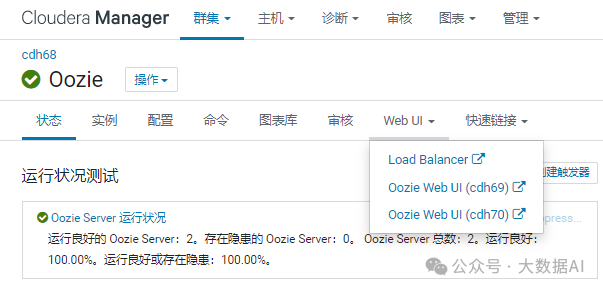
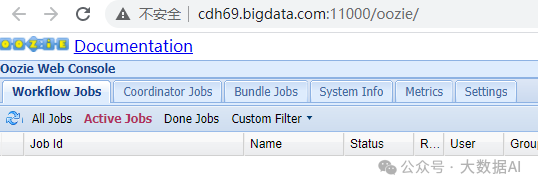
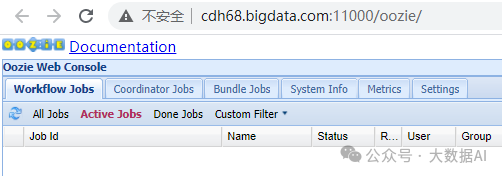
十二、Phoenix安装
1、安装
1.1 安装 phoenix parcel
从https://archive.cloudera.com/phoenix/6.2.0/parcels/下载对应操作系统parcel包。
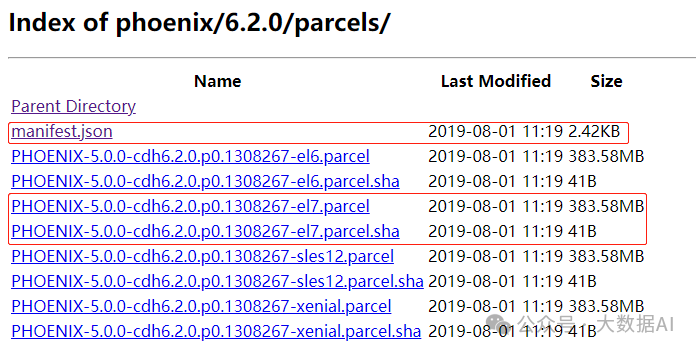
上传到服务器,并启动http服务:
[cuadmin@cdh68 phoenix]$ pwd
/data1/software/cloudera-repos/phoenix
[cuadmin@cdh68 phoenix]$ ll
total 392812
-rw-r--r-- 1 cuadmin cuadmin 2478 Dec 8 20:06 manifest.json
-rw-r--r-- 1 cuadmin cuadmin 402216960 Dec 8 20:10 PHOENIX-5.0.0-cdh6.2.0.p0.1308267-el7.parcel
-rw-r--r-- 1 cuadmin cuadmin 41 Dec 8 20:15 PHOENIX-5.0.0-cdh6.2.0.p0.1308267-el7.parcel.sha
配置Nginx:
server {
listen 8666;
server_name localhost;
location / {
root /data1/software/cloudera-repos;
autoindex on;
}
}
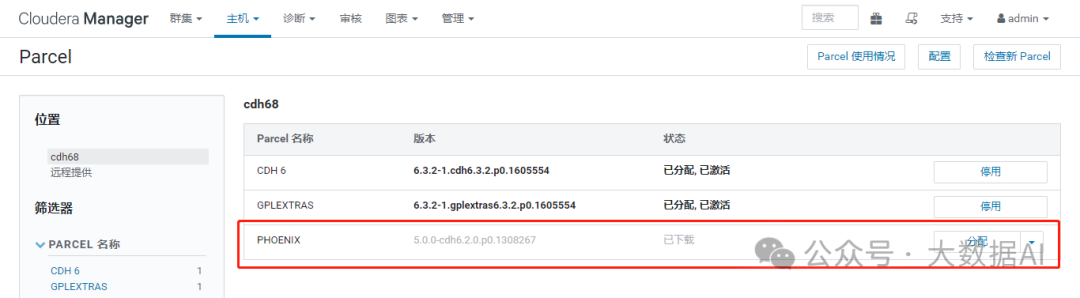
查看phoenix parcels
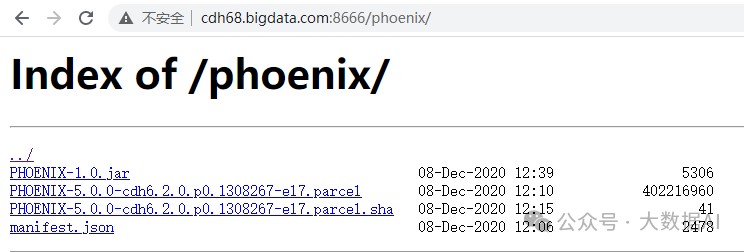
将Phoenix parcel包位置添加到“远程Parcel存储库URL”中
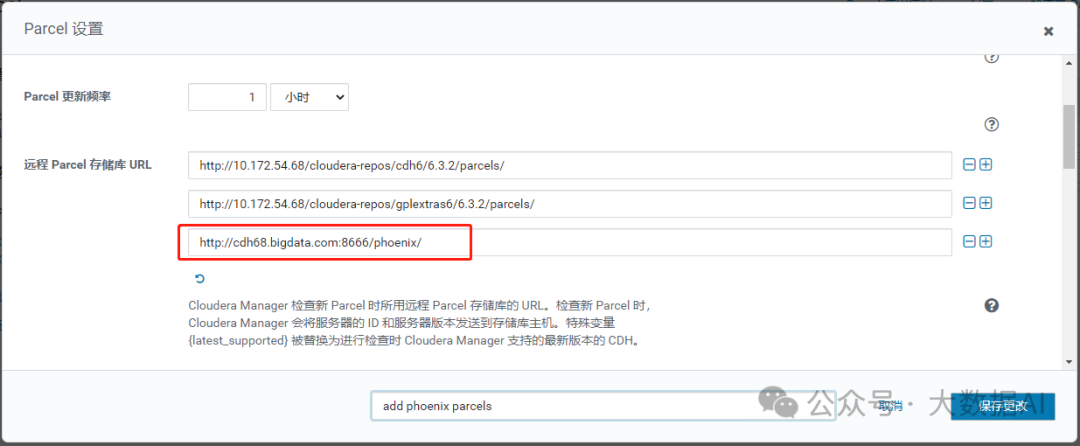
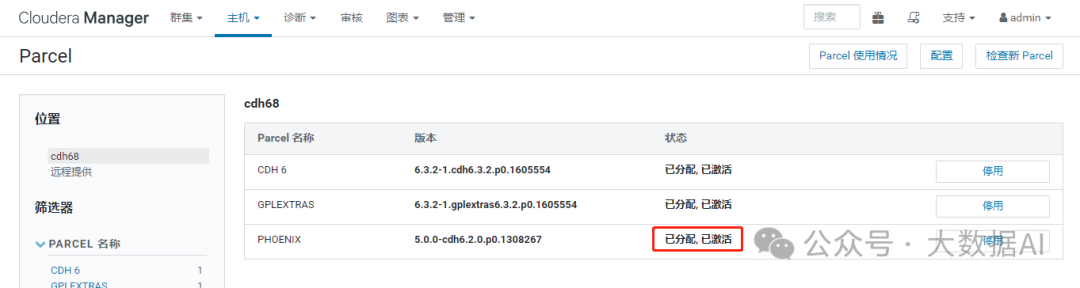
下载、分配、激活 phoenix parcel
1.2 安装 CSD 服务
在CDH中添加Phoenix服务之前,必须安装Custom Service Descriptor(CSD)文件。
否则,在添加服务中找不到Phoenix服务。
从 https://archive.cloudera.com/phoenix/6.2.0/csd/ 下载 csd文件 PHOENIX-1.0.jar
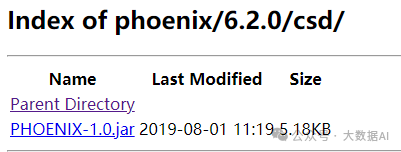
-
确定CSD文件存放位置
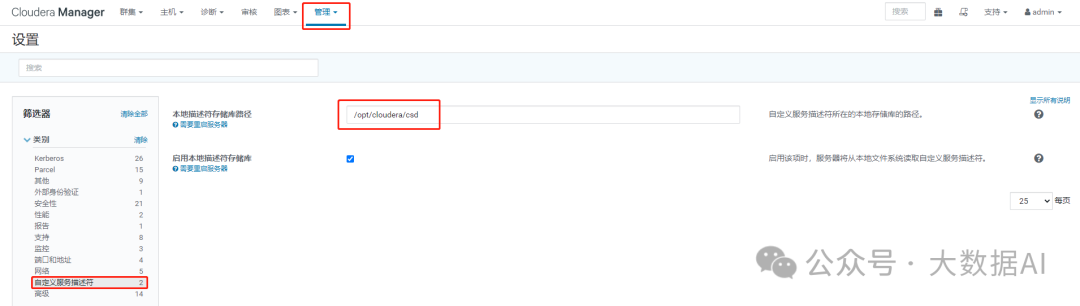
-
上传csd文件,然后重启Cloudera Manager服务
登录Cloudera Manager所在主机执行以下命令:
[cuadmin@cdh68 phoenix]$ sudo cp PHOENIX-1.0.jar /opt/cloudera/csd/
[cuadmin@cdh68 ~]$ sudo chown cloudera-scm:cloudera-scm /opt/cloudera/csd/PHOENIX-1.0.jar
[cuadmin@cdh68 ~]$ ll /opt/cloudera/csd/
-rw-r----- 1 cloudera-scm cloudera-scm 5306 Dec 9 09:51 PHOENIX-1.0.jar
[cuadmin@cdh68 ~]$ sudo systemctl restart cloudera-scm-server
-
登录Cloudera Manager,重启 Cloudera Management Service
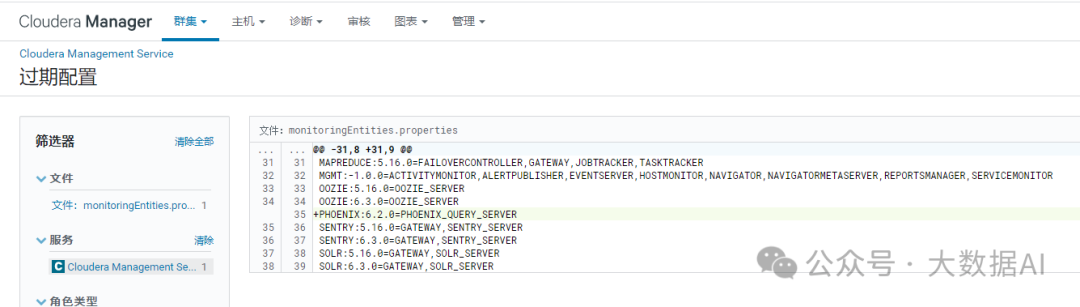
1.3 添加 Phoenix 服务
添加服务
自定义角色分配
查看Phoenix服务
1.4 配置HBase以用于Phoenix
-
添加属性
选择“Hbase”->“配置”,搜索“hbase-site.xml 的 HBase 服务高级配置代码段(安全阀)”,单击“以XML格式查看”,并添加以下属性:
<property>
<name>hbase.regionserver.wal.codec</name>
<value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value>
</property>
<property>
<name>phoenix.functions.allowUserDefinedFunctions</name>
<value>true</value>
<description>enable UDF functions</description>
</property>
<property>
<name>phoenix.schema.mapSystemTablesToNamespace</name>
<value>true</value>
</property>
<property>
<name>phoenix.schema.isNamespaceMappingEnabled</name>
<value>true</value>
</property>
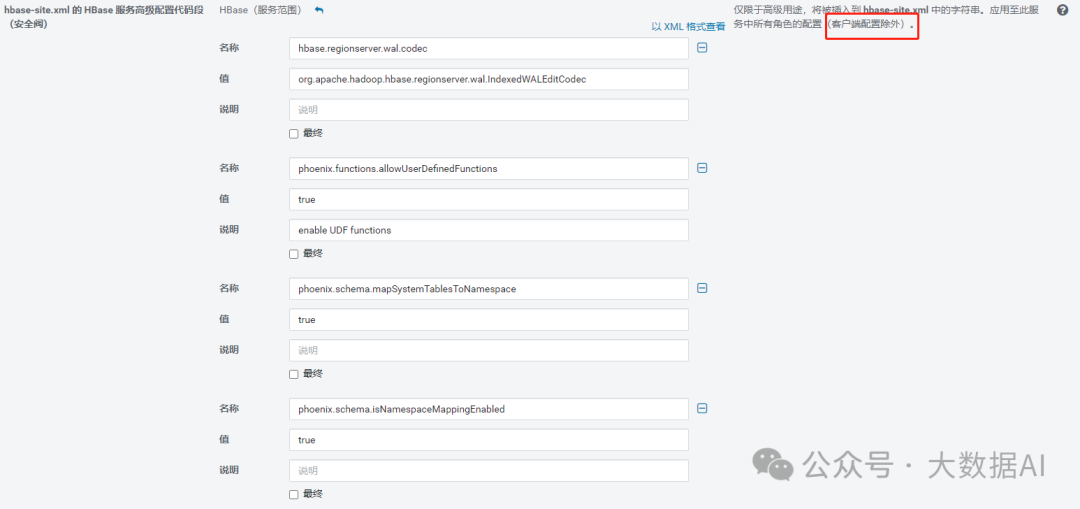
- 将hbase.regionserver.wal.codec定义写入预写日志(“wal”)编码。
- 设置phoenix.functions.allowUserDefinedFunctions属性启用用户自定义函数(UDF)。
- 开启Phoenix Schema 与 HBase namespace的对应关系
重启HBase
1.5 验证
Phoenix连接异常:
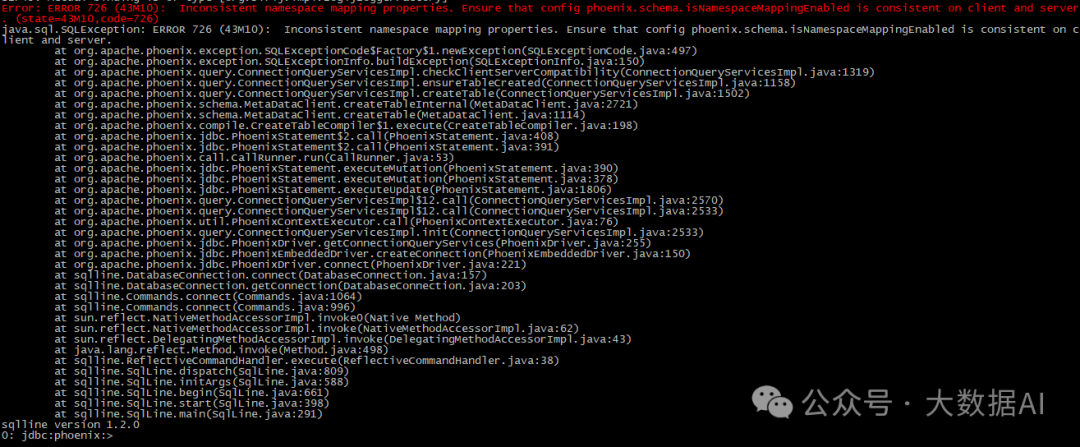
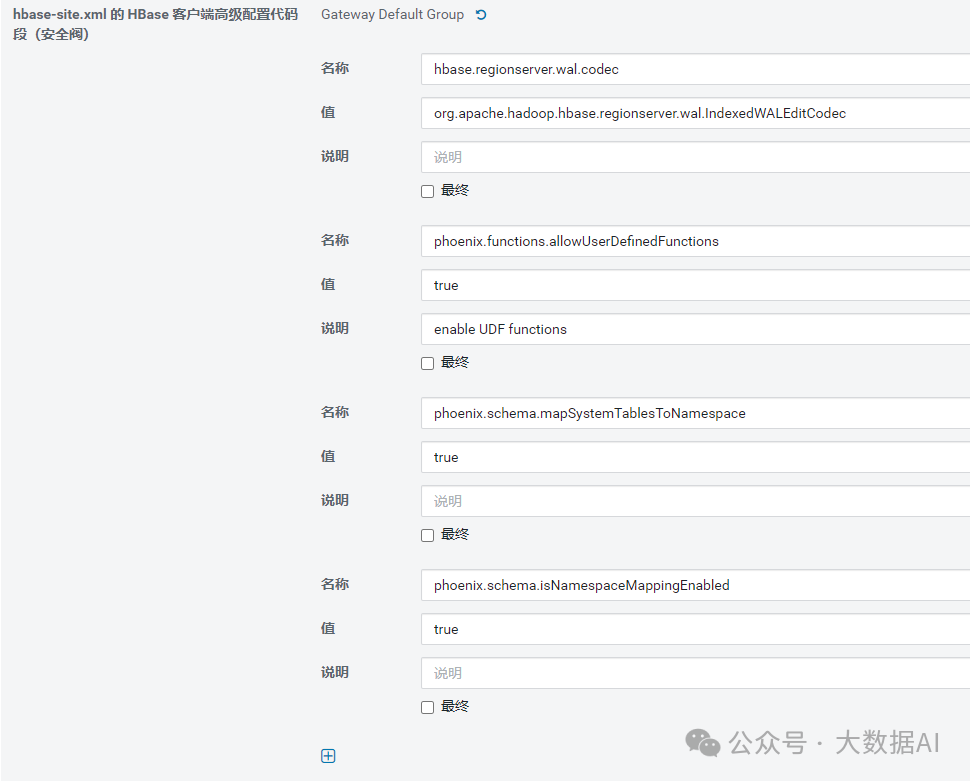
原因:1.4的配置不包括客户端配置,故需要在客户端重新配置一遍:

在hbase-site.xml 的 HBase 客户端高级配置代码段(安全阀)中重新配置:
部署客户端配置
可以看到配置在/etc/hbase/conf目录下:
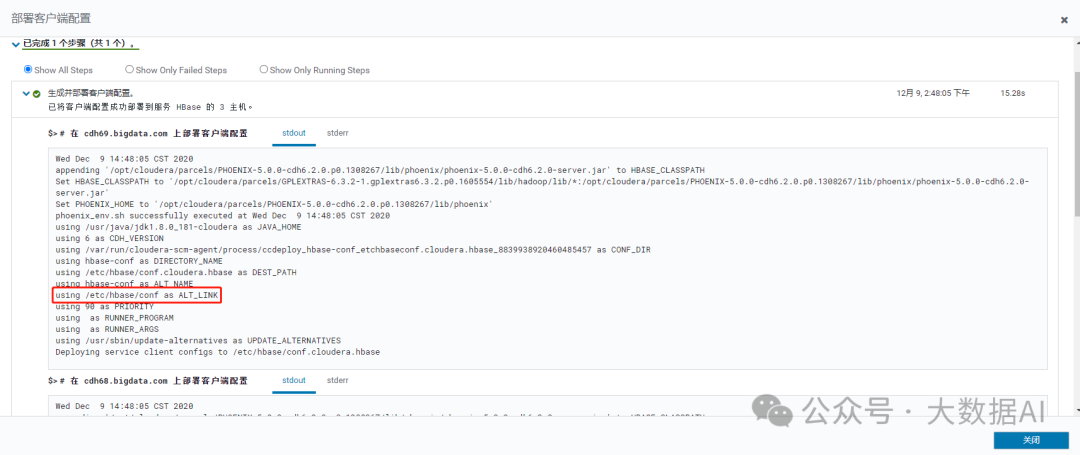
在次运行,出现如下错误:
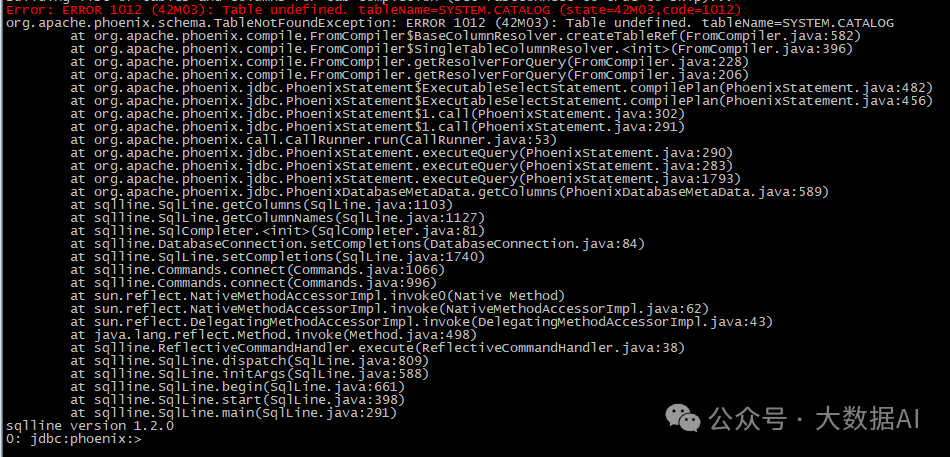
解决方案:
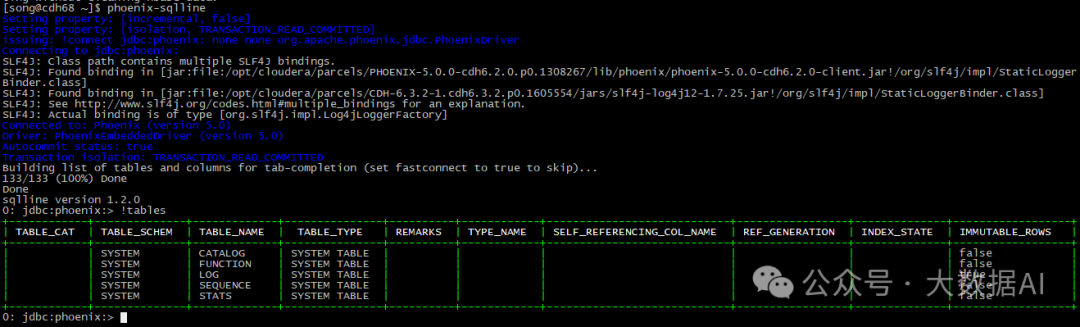
[song@cdh68 ~]$ hbase clean --cleanZk
ZNode(s) [cdh69.bigdata.com,16020,1607489641049, cdh68.bigdata.com,16020,1607489641121, cdh70.bigdata.com,16020,1607489641424] of regionservers are not expired. Exiting without cleaning hbase data.
再次验证:
十三、Hue
1、安装
添加Hue服务:
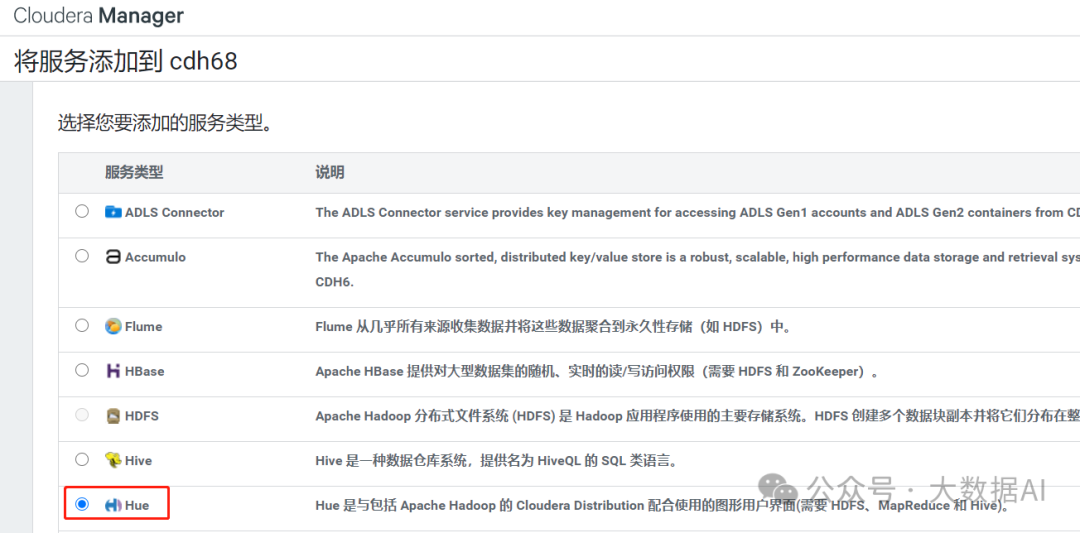
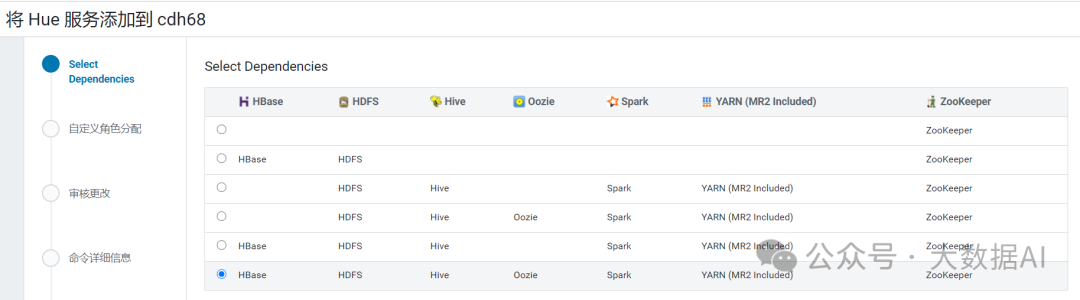
选择依赖:
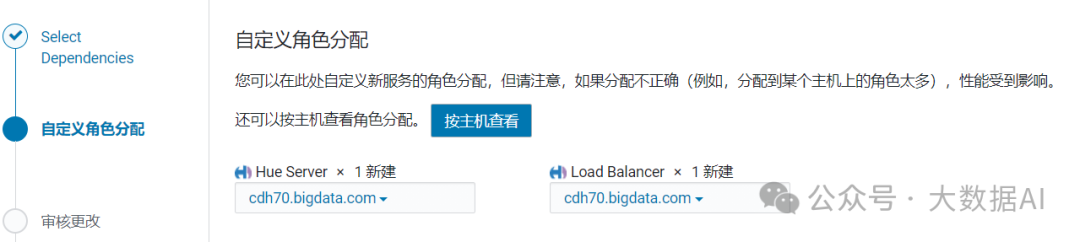
自定义角色分配:
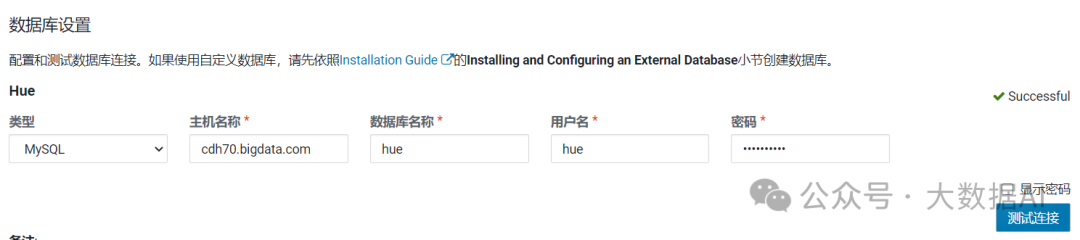
数据库设置:
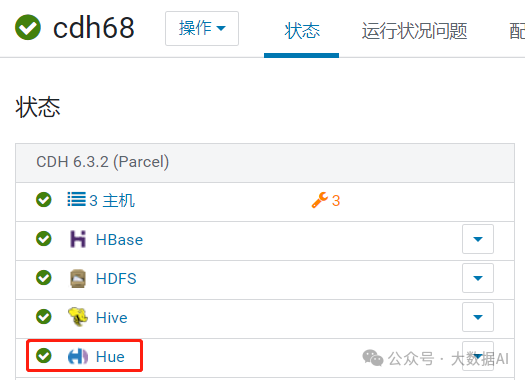
完成:
2、Hue HA
添加多个Load Blancer和Hue Server
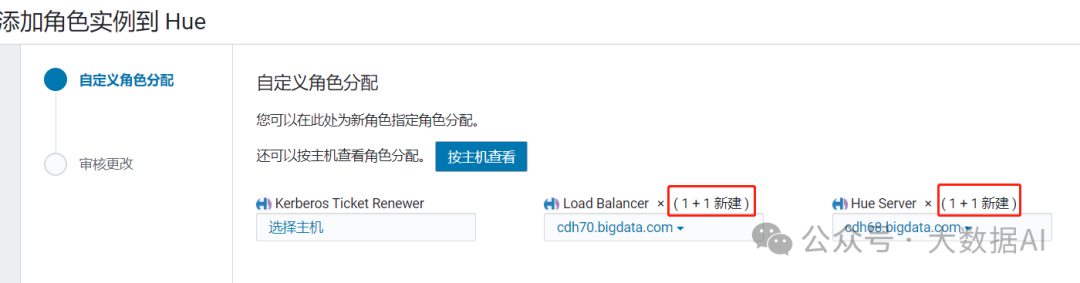
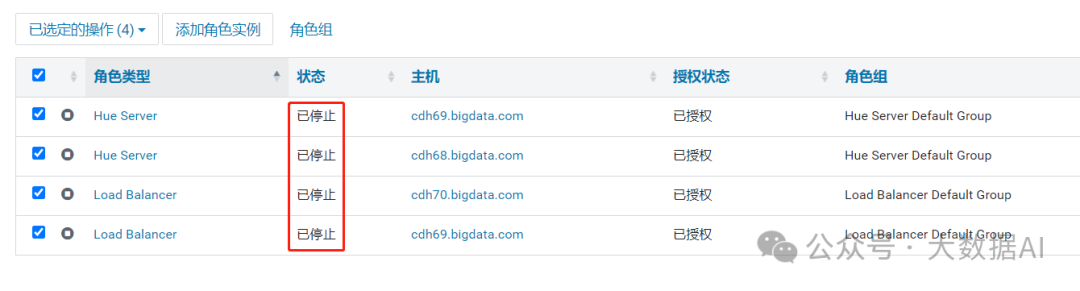
重启实例
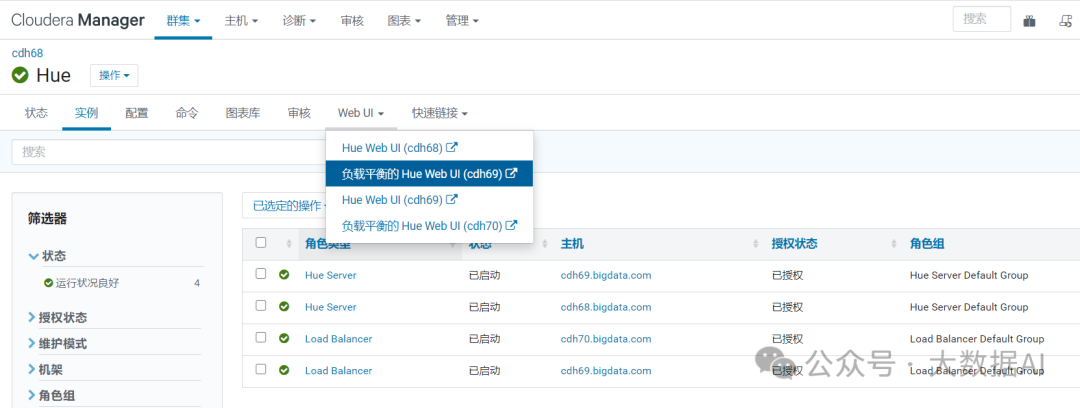
使用负载均衡登录:
3、配置
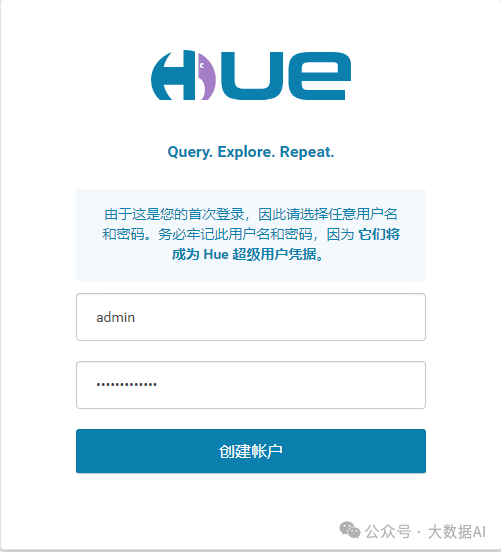
首次登录:
1、Configuring Hue to Work with HDFS HA Using Cloudera Manager
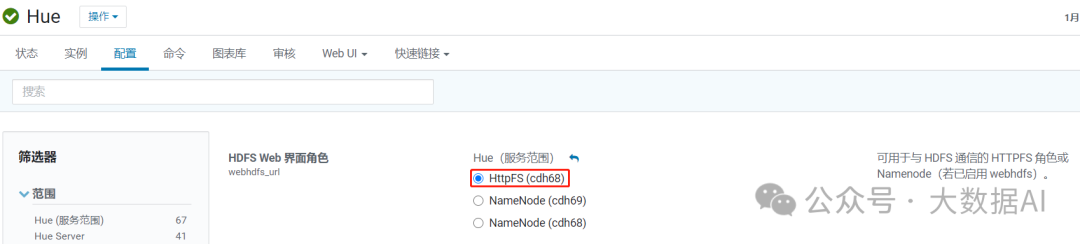
选用HttpFS即可
2、配置Hbase
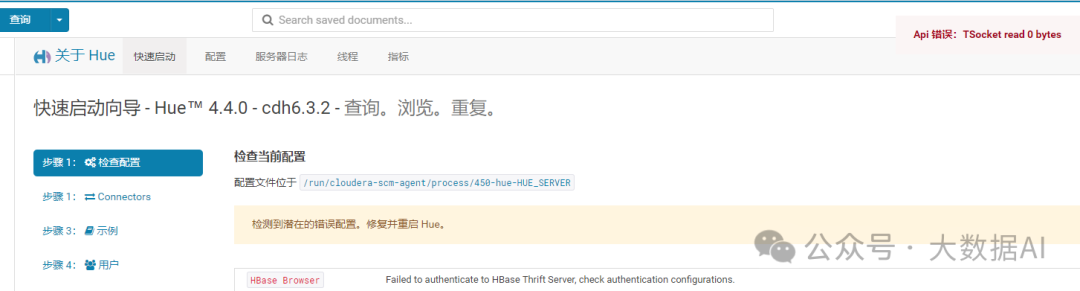
解决方案:
-
enable
hbase.regionserver.thrift.http
hbase.thrift.support.proxyuser

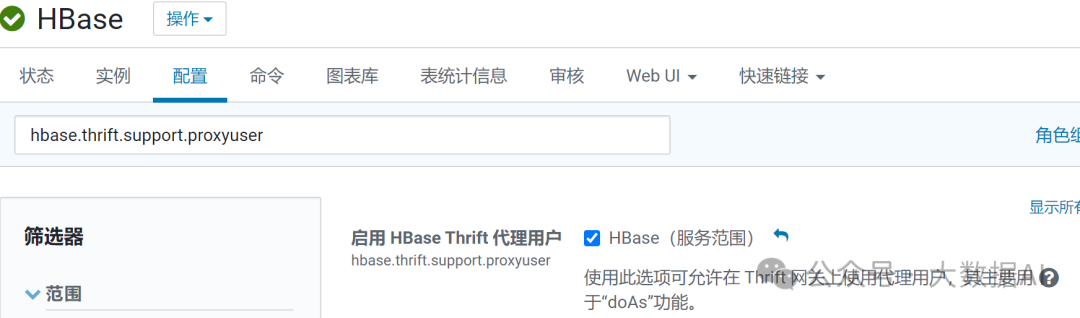
-
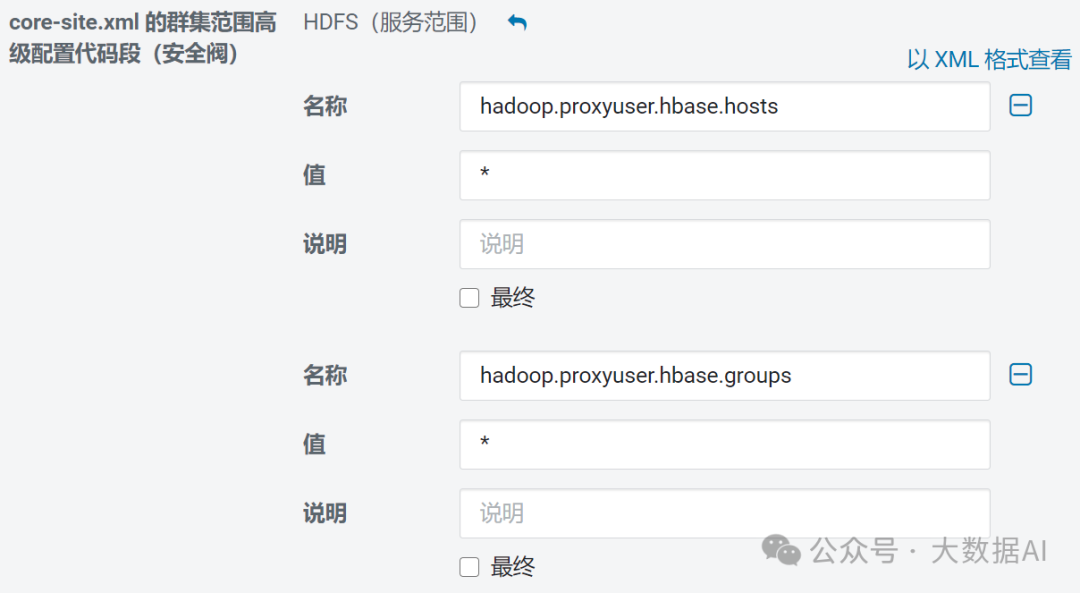
add the config into the hdfs core-site.xml
<property>
<name>hadoop.proxyuser.hbase.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hbase.groups</name>
<value>*</value>
</property>