
识别速度3.6ms/帧!人像抠图、工业质检、遥感识别,用这一个分割模型就够了
支撑影视人像抠图、医疗影像分析、自动驾驶感知等万亿级市场背后的核心技术是什么?那就要说到顶顶重要的图像分割技术。相比目标检测、图像分类等技术,图像分割需要将每个像素点进行分类,在精细的图像识别任务中不可替代,也是智能视觉算法工程师拥有关键核心竞争力的关键!

图1 图像分割应用
正因如此,DeepLabv3、OCRNet、BiseNetv2、Fast-SCNN等优秀算法层出不穷,然而在实际产业落地过程中往往需要综合考虑硬件性能、精度等多方面因素,对算法的需求也是苛刻的。往往业界算法在保障高识别精度的情况下,就会牺牲算法运行速度;反之追求速度,则会带来精度的大幅度损失。
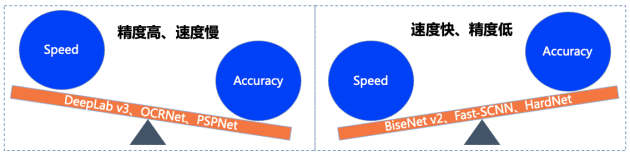
图2 各算法速度与精度平衡情况示意
如何能同时实现速度和精度的均衡,在当前云、边、端多场景协同的产业大趋势下高标准满足产业需求,是各届研究人员致力投入的方向。
PP-LiteSeg就是这样一个同时兼顾精度与速度的SOTA(业界最佳)语义分割模型。它基于Cityscapes数据集,在1080ti上精度为mIoU 72.0时,速度高达273.6 FPS , (mIoU 77.5 时,FPS为102.6),超越现有CVPR SOTA模型STDC,真正实现了精度和速度的SOTA均衡。
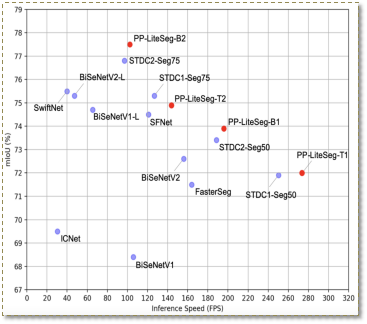
图3 PP-LiteSeg精度/速度说明
空口无凭,欢迎优秀的你直接试用! (记得Star收藏跟进最新状态)
传送门:
https://github.com/PaddlePaddle/PaddleSeg

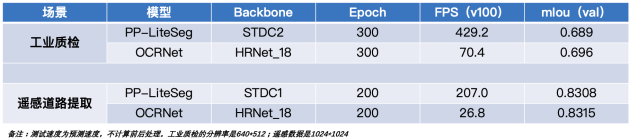

图4 PP-LiteSeg和OCRNet在某工业质检数据集识别情况对比

图4 PP-LiteSeg和OCRNet在deepglobe数据集识别情况对比
那PP-LiteSeg为何可以拥有这么优秀的效果呢?
PP-LiteSeg提出三个创新模块:灵活的解码模块(FLD)、注意力融合模块(UAFM)、简易金字塔池化模块(SPPM)。FLD灵活调整解码模块中通道数,平衡编码模块和解码模块的计算量,使得整个模型更加高效;UAFM模块效地加强特征表示,更好地提升了模型的精度;SPPM模块减小了中间特征图的通道数、移除了跳跃连接,使得模型性能进一步提升。
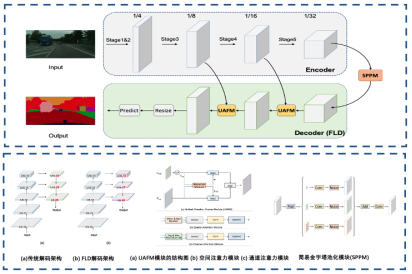
图5 PP-LiteSeg 模型结构和优化点
正是基于这些模块的设计与改进,最终PP-LiteSeg超越其他方法,在1080ti上精度为mIoU 72.0时,速度高达273.6 FPS , (mIoU 77.5 时,FPS为102.6),实现了精度和速度的SOTA平衡。更多关于PP-LiteSeg的内容,请参考:
https://github.com/PaddlePaddle/PaddleSeg/tree/release/2.5/configs/pp_liteseg
直播预告
为了让开发者们更深入的了解PP-LiteSeg这个SOTA模型,解决落地应用难点,掌握产业实践的核心能力,飞桨团队精心准备了精品直播课!

扫码报名直播课
进入技术交流群
4月26日20:30,百度资深高工将为我们详细介绍精度和速度平衡的PP-LiteSeg,对其原理及使用方式进行拆解,更有汽车金属垫片缺陷分割实战,加上直播现场互动答疑,还在等什么!抓紧扫码上车吧!

图1
图4:合作伙伴提供质检数据样例
图5:源于deepglobe数据集
END
