
好未来开源首个在线教学中文预训练模型
【公众号回复 “1024”,免费领取程序员赚钱实操经验】

大家好,我是章鱼猫。
今天推荐的这个项目是「edu-bert」,是好未来开源的教育领域首个在线教学中文预训练模型 TAL-EduBERT。
背景
在线教育领域 NLP 的研究、应用和发展有两大挑战:
一是从音视频转录出来的文本数据中,存在着较多的 ASR 错误,这些错误可能会对文本处理相关任务的效果造成较大的影响;
二是数据中含有大量的教育领域特有的专有词汇,现有的通用领域的开源词向量和开源预训练语言模型(如 Google BERT Base,Roberta 等)对于这些词汇的语义表示能力有限,进而会影响后续任务的效果。
为了帮助解决这两个问题,好未来 AI 中台机器学习团队从多个来源收集了超过 2000 万条(约包含 3.8 亿 Tokens)的教育领域中文 ASR 文本数据,基于此建立了教育领域首个在线教学中文预训练模型 TAL-EduBERT,并把其推至开源。
模型结构
TAL-EduBERT 在网络结构上,采用与 Google BERT Base 相同的结构,包含 12 层的 Transformer 编码器、768 个隐藏单元以及 12 个 multi-head attention的head。之所以使用 BERT Base 的网络结构,是因为考虑到实际使用的便捷性和普遍性,后续会进一步开源其他教育领域 ASR 预训练语言模型。
训练语料
TAL-EduBERT 所采用的预训练语料,主要源于好未来内部积淀的海量教师教学语音经 ASR 转录而得到的文本,对于语料进行筛选、预处理后,选取了超过 2000 万条教育 ASR 文本,大约包含 3.8 亿 Tokens。
预训练方式
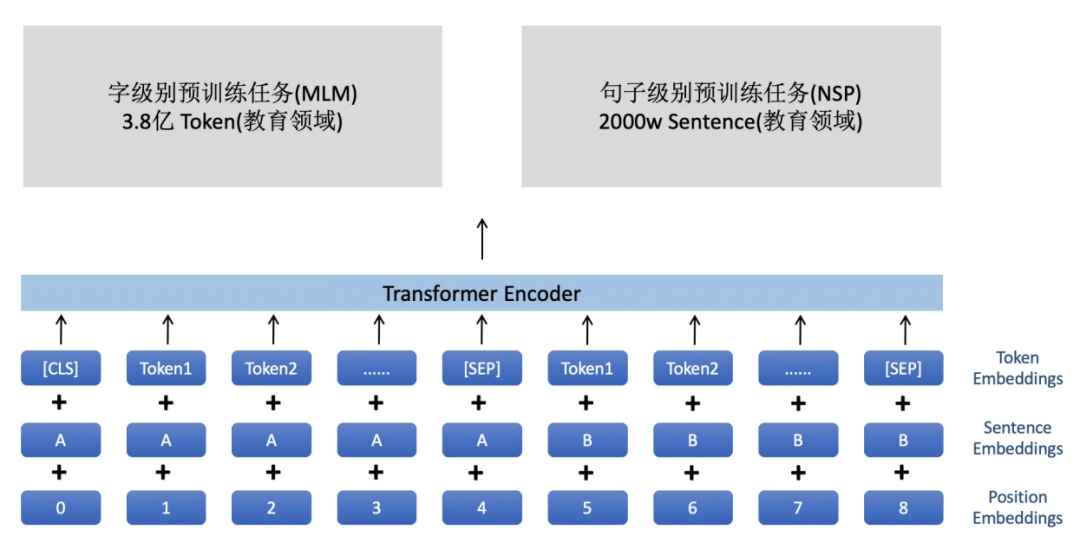
适用范围
相较于 Google BERT Base和Roberta,TAL-EduBERT 基于大量教育 ASR 文本数据训练,因此对于 ASR 的识别错误具有较强的鲁棒性,并且在教育场景的下游任务上也具有较好的效果。鉴于此,推荐从事教育,并且工作内容与 ASR 文本相关的 NLP 算法工程师使用我们的模型,希望能通过本次的开源,推进自然语言处理在教育领域的应用和发展。
使用方法
与 Google 发布的原生 BERT 使用方式一致,支持 transformers 包,因此在使用时,直接进行模型路径替换即可。
开源项目地址:https://github.com/tal-tech/edu-bert
开源项目组织:好未来技术
推荐阅读:
---特别推荐---
特别推荐:一个新的优质的推荐高效工具,软件,插件的公众号,每天给大家分享优秀的效率工具,「程序员掘金」,专门为程序员挖掘好东西的一个公众号,非常值得大家关注。