
Kafka流 - 抑制
在这篇文章中,我将解释Kafka Streams抑制的概念。尽管它看起来很容易理解,但还是有一些内在的问题/事情是必须要了解的。这是我上一篇博文CDC分析的延续。
◆架构
一个典型的CDC架构可以表示为:。
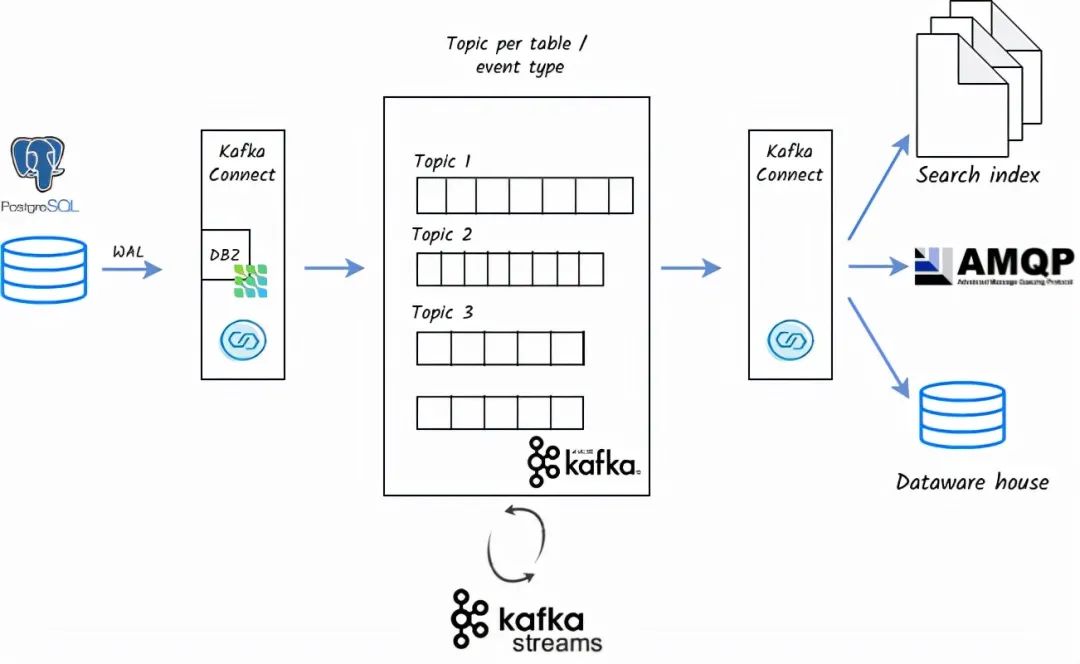
使用Kafka及其组件的CDC架构
在上述架构中。
单独的表交易信息被存储在Kafka的独立主题中。这些信息可以通过Kafka的sink连接器传输到目标目的地。
为了做聚合,如计数、统计、与其他流(CRM或静态内容)的连接,我们使用Kafka流。有些事情也可以用KSQL来完成,但是用KSQL实现需要额外的KSQL服务器和额外的部署来处理。相反,Kafka Streams是一种优雅的方式,它是一个独立的应用程序。
Kafka Streams应用程序可以用Java/Scala编写。
我的要求是将CDC事件流从多个表中加入,并每天创建统计。为了做到这一点,我们不得不使用Kafka Streams的抑制功能。
要理解Kafka流的压制概念,我们首先要理解聚合(Aggregation)。
◆聚合的概念
Kafka Streams Aggregation的概念与其他函数式编程(如Scala/Java Spark Streaming、Akka Streams)相当相似。这篇文章只是涵盖了其中一些重要的概念。关于详细的聚合概念,请访问confluent文档。

聚合的概念
聚合是一种有状态的转换操作,它被应用于相同键的记录。Kafka Streams支持以下聚合:聚合、计数和减少。你可以在KStream或KTable上运行groupBy(或其变体),这将分别产生一个KGroupedStream和KGroupedTable。
要在Kafka流中进行聚合,可以使用。
Count。用来计算元素的简单操作
Aggregation。
当我们希望改变结果类型时,就会使用聚合函数。聚合函数有两个关键部分。Initializer和Aggregator。当收到第一条记录时,初始化器被调用,并作为聚合器的起点。对于随后的记录,聚合器使用当前的记录和计算的聚合(直到现在)进行计算。从概念上讲,这是一个在无限数据集上进行的有状态计算。它是有状态的,因为计算当前状态要考虑到当前状态(键值记录)和最新状态(当前聚合)。这可以用于移动平均数、总和、计数等场景。Reduce。
你可以使用Reduce来组合数值流。上面提到的聚合操作是Reduce的一种通用形式。reduce操作的结果类型不能被改变。在我们的案例中,使用窗口化操作的Reduce就足够了。
在Kafka Streams中,有不同的窗口处理方式。请参考文档。我们对1天的Tumbling时间窗口感兴趣。
注意:所有的聚合操作都会忽略空键的记录,这是显而易见的,因为这些函数集的目标就是对特定键的记录进行操作。因此,我们需要确f保我们首先对我们的事件流做selectKeyoperation。
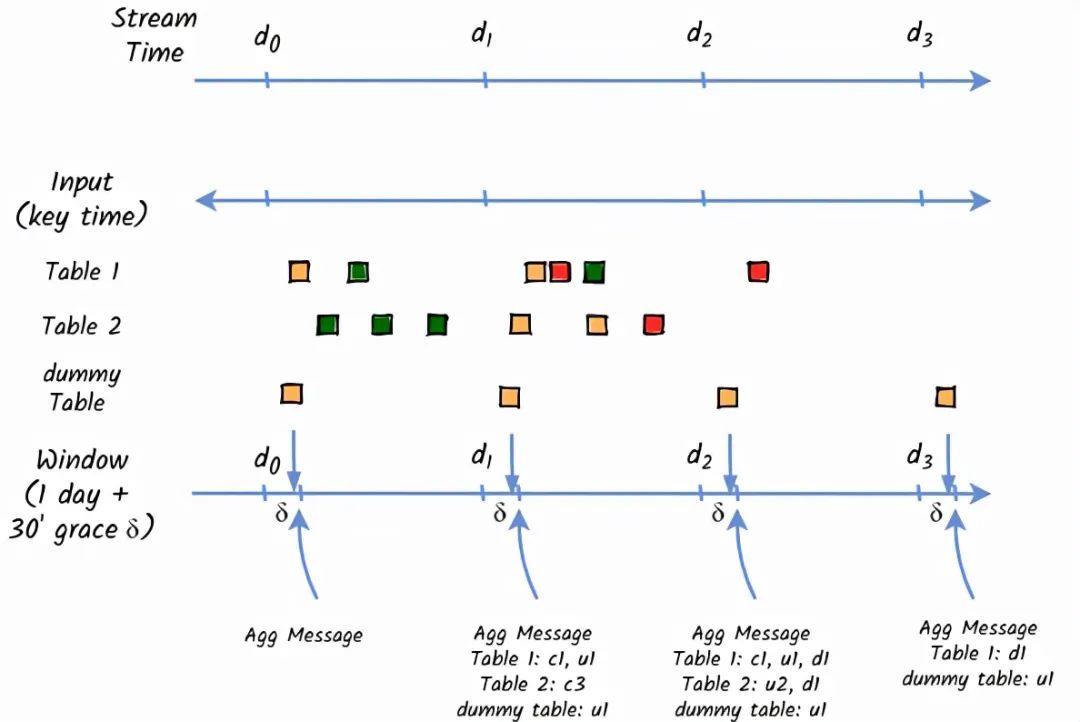
Kafka-streams-windowing
在程序中添加suppress(untilWindowClose...)告诉Kafka Streams抑制所有来自reduce操作的输出结果,直到 "窗口关闭"。" 当窗口关闭时,它的结果不能再改变,所以任何从suppress(untilWindowClose...)出来的结果都是其窗口的最终结果。
根据上述文件中的定义,我们希望每天在宽限期过后产生一个汇总的统计信息(与UTC一致)。但是,有一个注意点。在遇到相同的group-by key之前,suppress不会刷新聚合的记录!!。
在CDC事件流中,每个表都会有自己的PK,我们不能用它作为事件流的键。
为了在所有事件中使用相同的group-by key,我不得不在创建统计信息时在转换步骤中对key进行硬编码,如 "KeyValue.pair("store-key", statistic)"。然后,groupByKey()将正确地将所有的统计信息分组。
在CDC架构中,我们不能期望在宽限期后就有DB操作发生。在非高峰期/周末,可能没有数据库操作。但我们仍然需要生成聚合消息。
为了从压制中刷新聚集的记录,我不得不创建一个虚拟的DB操作(更新任何具有相同内容的表行,如update tableX set id=(select max(id) from tableX);。这个假的DB更新操作,我必须每天在宽限期后立即通过cronjob进行。也许这个cronjob可以取代ProcessorContext#schedule(), Processor#punctuate()(还没有尝试,因为我需要在这个应用程序中引入硬编码的表名)。
◆压制和重放问题
当我们重放来计算一个较长时期的汇总统计时,问题就更明显了。流媒体时间变得很奇怪,聚合窗口也过期了,我们得到以下警告。
2021-04-15 08:30:49 WARN 跳过过期窗口的记录。key=[statistics-store-msg-key] topic=[statistics-streaming-aggregates-statistics-stream-store-repartition] partition=[0] offset=[237] timestamp=[1618420920468] window=[1618358400000,1618444800000) expiration=[1618459200477] streamTime=[1618459200477]
为了防止这种过期的窗口并得到奇怪的汇总结果,我们需要将宽限期增加到相当大的数值,如下图所示。
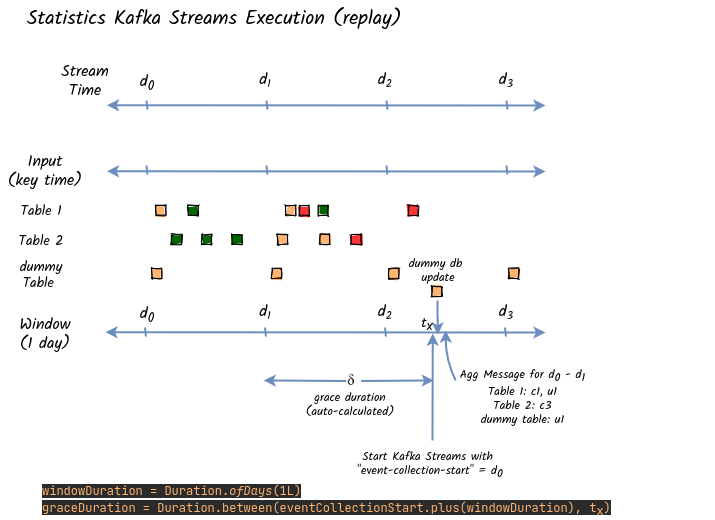
自动计算梯度长度
如上图所示,当我们进行重放并给出 "event-collection-start "时,我们应该自动设置 "grace duration"(足够大)。然后,kafka流将处理所有聚集的事件,没有任何过期。但最终的结果仍然不会被 "冲出 "压制窗口。我们需要通过在启动应用程序后创建一个假的更新来强行做到这一点。由于这是一个批处理程序,我们还需要 "kill $pid "来关闭(直到KIP-95完成:开放3年)。
我希望很多人像我一样在使用suppress时偶然发现了这个问题,对他们来说,这相当有用。
https://www.toutiao.com/a7019701596821340711/?log_from=7f9acd5df33cb_1635296895894