
矩阵与矩阵乘积简介
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

【导读】向量是存储和操作数据的一种有用的方法。可以用箭头或数字数组来表示它们。然而,创建更复杂的数据结构是有帮助的,而这正是需要引入矩阵的地方。
矩阵它们是正方形或矩形数组,包含按两个维度:行和列。你可以把它们看作是一个电子表格。通常,你会在数学上下文中看到术语矩阵,在Numpy上下文中看到二维数组。
在矩阵的上下文中,术语维度不同于向量表示的维数(空间维数)。当我们说矩阵是二维数组时,意味着数组中有两个方向:行和列。
矩阵表示如下:
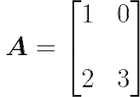
矩阵A有两行两列,但你可以想象矩阵有任何形状。更一般地说,如果矩阵有m行和n列,并且包含实值,可以用以下符号来刻画它:「A」∈ℝ(m×n)。
你可以使用不带粗体的矩阵名称引用矩阵中的元素,但是后面需要跟着行索引和列索引。例如,表示第一行和第二列中的元素。
按照惯例,第一个索引用于行,第二个索引用于列。例如,上面提到的例子位于矩阵A的第二行和第一列,因此它被表示为
矩阵分量可以写如下:

图1:矩阵是二维数组。行数通常用m表示,列数用n表示。
数组的形状给出了每个维度中元素的数量,如图1所示。由于此矩阵是二维的(行和列),因此需要两个值来描述形状(按此顺序排列的行数和列数)。
让我们先用这个方法np.array()创建一个2维numpy数组
A = np.array([[2.1, 7.9, 8.4],
[3.0, 4.5, 2.3],
[12.2, 6.6, 8.9],
[1.8, 1., 8.2]])
注意,我们使用数组中的数组([[]])来创建二维数组。这与创建一维数组的不同之处在于所使用的方括号数。
与向量一样,可以访问Numpy数组的shape属性:
A.shape
你可以看到该形状包含两个数字:它们分别对应于行数和列数。
要获得矩阵元素,需要两个索引:一个引用行索引,一个引用列索引。
使用Numpy,索引过程与向量的索引过程相同。你只需要指定两个索引。我们再来看下面的矩阵A:
A = np.array([[2.1, 7.9, 8.4],
[3.0, 4.5, 2.3],
[12.2, 6.6, 8.9],
[1.8, 1.3, 8.2]])
可以使用以下语法获取特定元素:
A[1, 2]
[1,2]返回行索引为1、列索引为2(以零为基础的索引)的元素。
要获得完整的列,可以使用冒号:
A[:, 0]
array([ 2.1, 3. , 12.2, 1.8])
这将返回第一列(索引0),因为冒号表示我们需要从第一行到最后一行的元素。同样,要获取特定行,可以执行以下操作:
A[1, :]
array([3. , 4.5, 2.3])
能够操纵包含数据的矩阵是数据科学家的一项基本技能。检查数据的形状对于确保数据的组织方式非常重要。了解使用Sklearn或Tensorflow等库所需的数据形状也很重要。
对于Numpy,如果数组是向量(1D Numpy数组),则shape是单个数字:
v = np.array([1, 2, 3])
v.shape
如果是矩阵,则形状有两个数字(行和列中的值的数目)。例如:
A = np.array([[2.1, 7.9, 8.4]])
A.shape
形状的第一个数字是1。使用两个方括号[[和]],可以创建一个二维数组(矩阵)。
矩阵乘积
你将在数据科学基础数学中学习乘积。矩阵的等价运算称为矩阵乘积或矩阵乘法。它接受两个矩阵并返回另一个矩阵。这是线性代数中的一个核心运算。
矩阵乘积的更简单的情况是介于矩阵和向量之间(可以将其视为矩阵乘积,其中一个向量只有一列)。
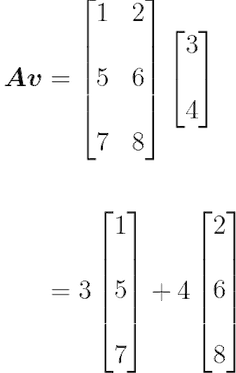
说明了矩阵和向量之间乘积的步骤。让我们考虑矩阵的第一行。在向量(值3和4)和考虑的行(值1和2)之间进行点积。第一行的第一个值的与第一列的第一个值(1⋅3)和第一行第二个值与第一列的第二个值(2⋅4)。它给你计算的矩阵的第一个元素是(1⋅3 + 2⋅4 = 11)。
你可以看到矩阵乘积与点积相关。这就像把矩阵A分成三行并应用点积(如数据科学的基本数学)。
让我们看看它是如何与numpy一起工作的。
A = np.array([
[1, 2],
[5, 6],
[7, 8]
])
v = np.array([3, 4]).reshape(-1, 1)
A @ v
array([[11], [39], [53]])
请注意,我们使用了reshape函数将向量重塑为一个2乘1的矩阵(-11告诉Numpy猜测剩余的数字)。如果没有它,你将以一维数组结束,而不是这里的二维数组(只有一列的矩阵)。
还有另一种方法来考虑矩阵乘积。你可以考虑向量包含了对矩阵的每一列加权的值。它清楚地表明,向量的长度需要等于应用向量的矩阵的列数。
下图可能有助于将这个概念形象化。可以将向量值(3和4)视为应用于矩阵列的权重。前面看到的标量乘法规则会产生与以前相同的结果。
使用最后一个示例,可以编写A和v之间的乘积,如下所示:
这一点很重要,因为正如你在数据科学基础数学中看到的更多细节,它表明Av是A的列的线性组合,系数是v的值。
另外,你可以看到矩阵的形状和向量的形状必须匹配才能得到乘积。
矩阵乘积类似于矩阵向量积,但应用于第二个矩阵的每一列。
使用Numpy,可以精确地计算矩阵乘积:
A = np.array([
[1, 2],
[5, 6],
[7, 8],
])
B = np.array([
[3, 9],
[4, 0]
])
A @ B
array([[11, 9], [39, 45], [53, 63]])
与矩阵向量积一样,第一个矩阵的列数必须与第二个矩阵的行数相匹配。
结果矩阵的行数与第一个矩阵的行数相同,列数与第二个矩阵的列数相同。
我们试试吧。
A = np.array([
[1, 4],
[2, 5],
[3, 6],
])
B = np.array([
[1, 4, 7],
[2, 5, 2],
])
矩阵A和B有不同的形状。让我们计算他们的乘积:
A @ B
array([[ 9, 24, 15], [12, 33, 24], [15, 42, 33]])
你可以看到A⋅B的结果是一个3乘3的矩阵。这个形状来自A(3)的行数和B(3)的列数。
可以使用矩阵与其转置矩阵之间的乘积计算数据集的协方差矩阵。然后,除以观测值(或贝塞尔修正值减去1)。但是你需要事先确保变量的中心在零附近(这可以通过减去平均值来实现)。
让我们模拟以下变量x、y和z:
x = np.random.normal(10, 2, 100)
y = x * 1.5 + np.random.normal(25, 5, 100)
z = x * 2 + np.random.normal(0, 1, 100)
使用Numpy,协方差矩阵为:
np.cov([x, y, z])
array([[ 4.0387007 , 4.7760502 , 8.03240398], [ 4.7760502 , 32.90550824, 9.14610037], [ 8.03240398, 9.14610037, 16.99386265]])
现在,使用矩阵乘积,首先进行堆叠:
X = np.vstack([x, y, z]).T
X.shape
你可以看到变量X是一个100×3的矩阵:100行对应于观察值,3列对应于特征。然后,把这个矩阵减去均值:
X = X - X.mean(axis=0)
最后,计算协方差矩阵:
(X.T @ X) / (X.shape[0] - 1)
array([[ 4.0387007 , 4.7760502 , 8.03240398], [ 4.7760502 , 32.90550824, 9.14610037], [ 8.03240398, 9.14610037, 16.99386265]])
你会得到一个协方差矩阵,与函数np.cov中得到的协方差矩阵相似,这一点很重要,要记住一个矩阵的转置乘积对应于协方差矩阵。
两个矩阵之间乘积的转置定义如下:

例如,取以下矩阵A和B:
A = np.array([
[1, 4],
[2, 5],
[3, 6],
])
B = np.array([
[1, 4, 7],
[2, 5, 2],
])
你可以检查(AB)^T和B^T A^T的结果:
(A @ B).T
array([[ 9, 12, 15], [24, 33, 42], [15, 24, 33]])
B.T @ A.T
array([[ 9, 12, 15], [24, 33, 42], [15, 24, 33]])
这可能是令人惊讶的首先,两个向量或矩阵在括号中的顺序必须改变,以满足等价性。我们来看看操作的细节。
下图显示,如果改变向量和矩阵的顺序,矩阵乘积的转置等于转置的乘积。
可以将此属性应用于两个以上的矩阵或向量。例如,
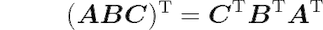
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~