
中文分词-词典逆向最大匹配法-JAVA实现
点击上方蓝色字体,选择“标星公众号”
优质文章,第一时间送达
测试环境
windows 10
IDEA 2020.1
JDK 1.8
算法描述
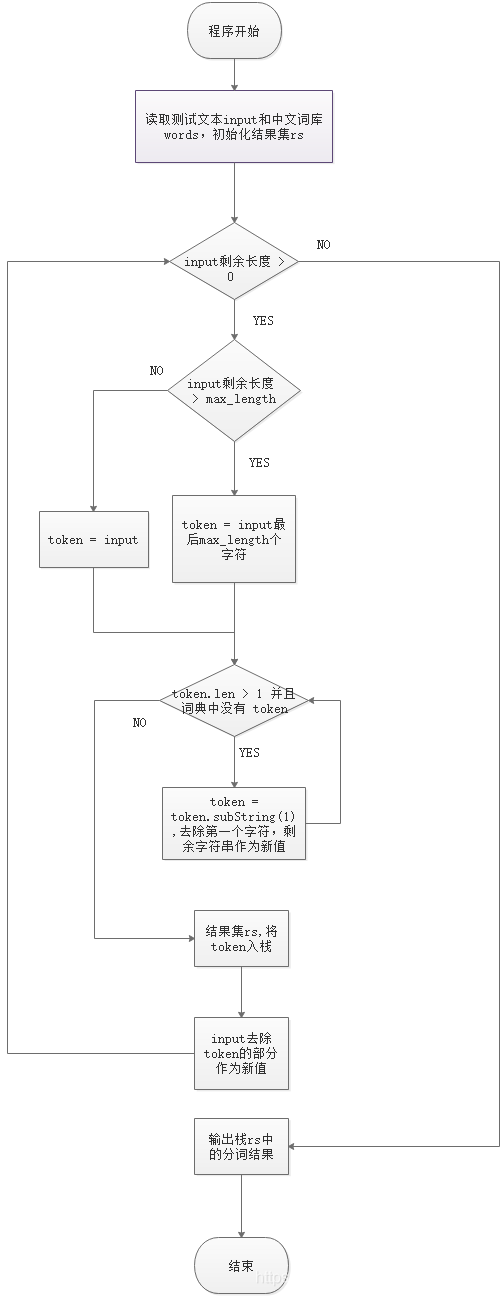
1、 首先读取词库,每个词用哈希表存储,查找效率高
2、 读取待分词句子input, 设置最大匹配长度 MAX
3、 input的长度是否大于0,如果是接着下一步,否则第8步
4、 input长度是否大于 MAX, 如果是,设置尝试匹配词语token = input后MAX个字符, 否则 token = input
5、 是否有:token的长度大于1并且token并未出现在词库中?是的话接着下一步,否则转至第7步
6、 token去掉最左的第一个字符作为新token, 转去第5步
7、 分词结果栈rs保存token,input去除token的部分作为新input,转至第3步
8、 输出分词结果rs,程序结束
流程图
源程序-JAVA实现
Words.java 负责读取词库文件并判断token是否存在词库中
package org.example;
import java.io.*;
import java.nio.charset.StandardCharsets;
import java.util.HashSet;
public class Words {
private HashSet<String> hashSet = new HashSet<>();
public void loadWordsData(String fileName) throws IOException {
BufferedReader br = null;
InputStreamReader isr = null;
FileInputStream fis = null;
File file = new File(fileName);
fis = new FileInputStream(file);
isr = new InputStreamReader(fis, StandardCharsets.UTF_8);
br = new BufferedReader(isr);
/*读取每一行内容即一个词,保存在哈希表中*/
String line = null;
while ((line = br.readLine()) != null) {
hashSet.add(line.replace(" ", ""));
}
}
/*词库中是否存在word*/
public boolean contains(String word) {
return hashSet.contains(word);
}
}
App.java 算法主流程
package org.example;
import java.io.IOException;
import java.util.ArrayDeque;
import java.util.Deque;
/**
* @author: Mr.Hu
* @create: 2021-04-07 15:52
*/
public class App {
public static void main(String[] args) throws IOException {
Words words = new Words();
words.loadWordsData("data.txt");
Deque<String> rs = new ArrayDeque<>();
String input = "普京跟特朗普在明天下雨之前学会加减乘除,吃完饭没时间睡觉,睡觉后去上大学";
String analysis = null; // 每次匹配的字符串
int head = 0; // head~tail-1为分词字符串
int tail = input.length(); // 余下的字符长度
final int max_length = 4; // 最大匹配长度
while (tail > 0) {
// 先尝试取最大匹配长度
if (tail > max_length) head = tail - max_length;
else head = 0; // 余下全部
analysis = input.substring(head, tail); // 截取
/*直到截取字符串只有一个字符或者字符串存在于词库中*/
while (analysis.length() > 1 && !words.contains(analysis)) {
analysis = analysis.substring(1); // 去除最左字符,即尝试匹配少一位
head++; // 下标往后
}
rs.push(analysis); // 栈中
tail = head; // 下一个截取字符串的尾巴是这次的头
}
for (String item : rs) {
System.out.print(item + " / "); // 词库中的词没有单字的
}
System.out.println();
}
}
data.txt 词库文件
普京
大学
天气
睡觉
下雨
吃饭
时间
特朗普
加减乘除
明天
之前
运行结果
普京 / 跟 / 特朗普 / 在 / 明天 / 下雨 / 之前 / 学 / 会 / 加减乘除 / , / 吃 / 完 / 饭 / 没 / 时间 / 睡觉 / , / 睡觉 / 后 / 去 / 上 / 大学 /
写在最后
分词算法还有很多,我这个算是比较机械、简单的了,可以自行去了解
Github开源词库:https://github.com/fighting41love/funNLP
————————————————
版权声明:本文为CSDN博主「优雅的发际线」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:
https://blog.csdn.net/HLL1234567/article/details/115515730
粉丝福利:Java从入门到入土学习路线图
👇👇👇

👆长按上方微信二维码 2 秒
感谢点赞支持下哈 