CMU团队从数据的角度入手,探讨了神经网络中的泛化现象。他们认为,在未来,较为重要的一项技术可能是更直观地将人的视觉特征加入到模型中。
如何理解神经网络的泛化能力?CMU 的汪浩瀚、邢波等人在论文 High-frequency Component Helps Explain the Generalization of Convolutional Neural Network 中另辟蹊径,从数据的角度入手,探讨那些曾让我们百思不得其解的泛化现象。
论文链接:https://arxiv.org/pdf/1905.13545.pdf都是数据惹的祸
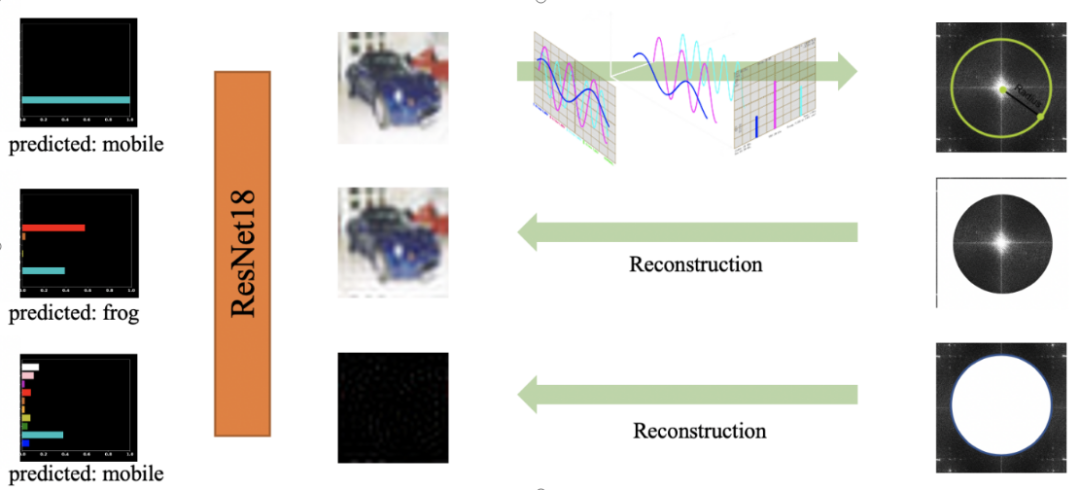
对神经网络泛化能力的理解一向是众多机器学习研究者追求的目标,而致力于解决相关问题的文章也已是浩如烟海。本文将考虑一个完全不同的角度:只需在图片数据上执行一个小小的操作,就能够帮助我们理解许多曾经百思不解的泛化现象(比如对抗攻击和 Batch Normalization 的功效等)。很多现象难以解释,可能是因为我们把数据想象的太简单了,简而言之:数据可能比模型更复杂。我们首先从一个有趣的现象开始(如图 1 所示):在 CIFAR10 数据集上训练一个 ResNet18 模型。我们选择一张测试图片,把这张图片输入进训练好的模型中,绘制出模型的预测概率,我们看到模型有很大的信心认为图片上的物体是「汽车」。如果我们将这张图片经过傅里叶变换投影到频域中,然后选取一个半径,用这个半径把频域切分称低频域和高频域;然后利用切分之后的频域重新构建图片,其中第二行的蓝色汽车是低频重建的图片,而第三行的黑色块是高频重建的图片(高频重建的图片几乎全部是肉眼不可见的噪音)。将这些重建的图片重新放回刚刚的模型中,我们可以发现一个很有趣的现象:第二行肉眼看起来与原图相似的低频重建图片被预测成了「青蛙」,而第三行肉眼完全无法识别的图片被模型预测成了「汽车」,与原图预测结果一致。 图 1. 人与模型视觉上的区别:低频重建的图片与原图看起来几乎一致,却被模型预测成了不同的 label。高频重建的图片人眼几乎无法识别,模型却能成功预测出原来的 label。尽管我们只在大约 600 张图片中发现了这个神奇的现象,但也足够引起警觉了。为什么会出现这种情况?
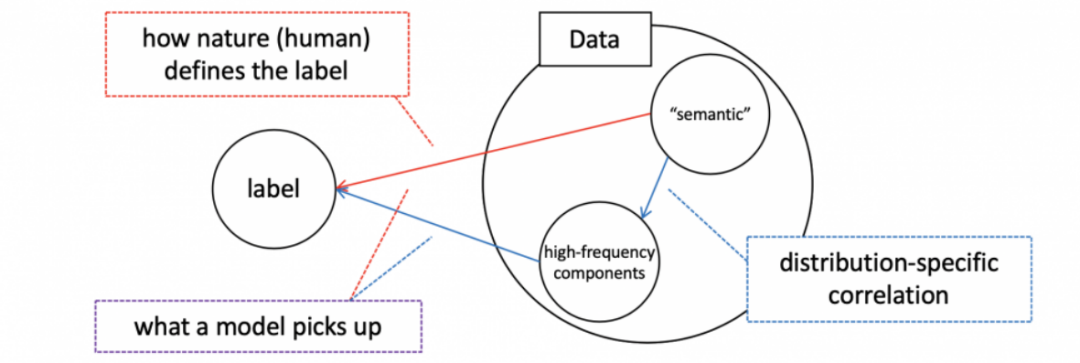
我们认为其中一个重要原因是在一个有限的数据集中存在着高频信息与图片所表达语义的相互关联(如图 2 所示):在一个同分布的有限数据集中可能存在着一些无法察觉的高频信号刚好与图片的语义有些关联,进而导致了这些高频信号与数据集 label 的相互关联。这样,当我们优化模型去降低损失函数时,我们并没有明确告知模型去学习语义还是高频信号,这导致模型随意学习各种可能会降低损失的信号。这样,尽管模型可能会达到较高的准确率,但它未必真的理解数据。图 2. 本文的最主要观点:在一个有限的数据集中,除了数据本身的内容和 label 的关联之外,还有一些数据内容和其中的高频噪音的关联。当训练一个模型的时候,如果我们没有指明模型应该学习数据想表达的内容还是这些高频信号,模型可能会无差别地学习数据本身的信号或者这些高频信号,而这将使得对模型泛化能力的评估出现各种难以解释的现象。而当我们理解了这种数据特征之后,诸如对抗攻击、Batch Normalization 的功效等泛化的多种神奇现象将迎刃而解。请注意:我们并没有说模型有捕捉高频信号的倾向性。这里的主要观点是:模型并没有任何理由忽略高频信息,从而导致模型学到了高频和语义的混合信息。那么,这种现象是否是好事呢?一方面,这个特点有机会让我们创造出能够超越人类视觉系统的模型,在同分布的数据集上甚至可以达到比人类水平更高的准确率。另一方面,这样的模型,尽管在同分布数据集上效果很好,但在其他不同分布的相似数据集上效果可能参差不齐(高频信息很可能在每个分布上是不一致的)。在这里,我们并不争辩哪个观点更正确,我们只是提供这些观测结果供大家探讨。关于泛化的一些解释
这个特点可以用来解释很多关于泛化的有趣现象,本文只涉及论文中的两点。为了更好地探究这些联系,我们利用对抗性训练(adversarial training, PGD)训练了一个可以抵御对抗性攻击的模型,进而研究该模型的卷积核特征,并比较了该卷积核与普通模型的卷积核的差别。我们发现,一个对对抗攻击鲁棒性更强的模型的卷积核看起来更加平滑(平滑指的是相邻位置的权重非常相似),如图 3 所示。很多数学工具可以帮我们证明平滑的卷积核能够有效地移除高频信号。这些结果将对抗性攻击的研究和数据中的高频信号联系了起来。图 3. 左:普通卷积神经网络的卷积核的可视化;右:对对抗攻击鲁棒的卷积神经网络的卷积核的可视化。有了这些观测结果,一个更有趣的问题就是我们是否可以通过将卷积核变得更加平滑来提高模型的对抗攻击鲁棒性。为了探究这个问题,我们测试了如下三种方法:对于一个训练好的模型,我们调整其权重,使卷积核变得更加平滑;在训练卷积神经网络的过程中增加正则化,使得相邻位置的权重更加接近。我们很希望这些调整可以增加模型的对抗鲁棒性,可是很遗憾,我们只观测到了很小一部分的提升。这样,我们大概可以得出结论:对抗鲁棒性较好的模型卷积核更加平滑,然而卷积核更加平滑的模型对抗鲁棒性未必更好。换言之:高频信息是对抗攻击的一部分,但并非全部。然而,另一个策略确确实实可以提高模型的对抗鲁棒性:值得说明的是,这个方法虽然有机会在工业界大展拳脚,但是对抗攻击和防御的科研社区通常不太认可类似的图片预处理方法。关于 Batch Normalization 的神奇功效
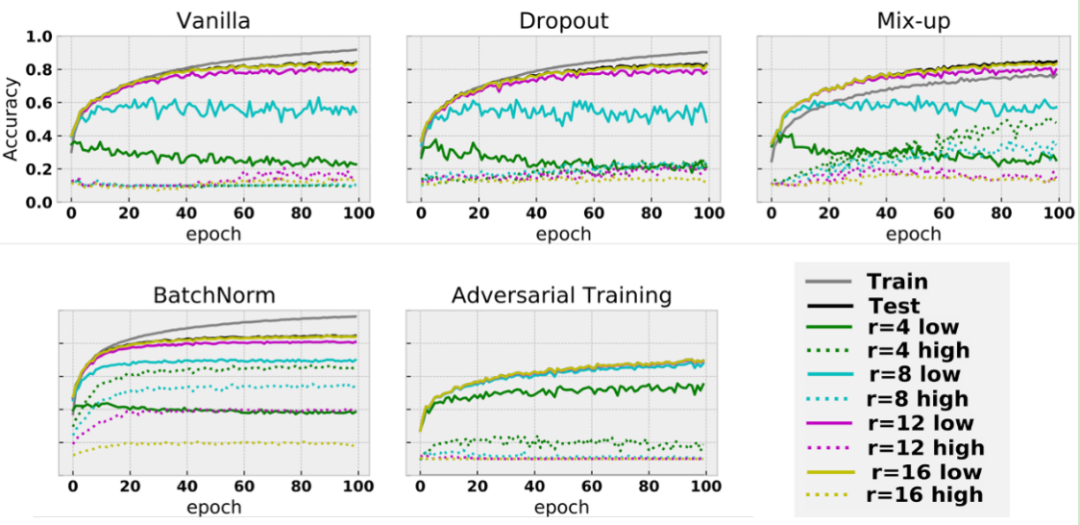
另一个很有趣的现象是 BatchNorm 的效果究竟来源于何处。BatchNorm 是当下深度学习,尤其是计算机视觉中的一个相当重要的技术。尽管成效斐然,BatchNorm 在训练中起到的作用似乎还没有得到很好地理解。我们的实验很有趣地从数据的角度上解释了 BatchNorm 的功效来自何方。图 4. 在训练过程中,测试准确率随着 epoch 数的变化。每一个板块描述的是一个不同的训练技巧。颜色代表着区分低频信息和高频信息的半径。实线代表低频信息,虚线代表高频信息。虚线越高,表示越多的高频信息被学习到了。在图 4 中,随着训练 epoch 数的增加,我们汇报了在训练过程中不同测试集的测试准确率,这些测试集是由不同的半径生成的,其中实线代表了低频数据,虚线代表了高频信息。虚线越高,一个模型就学到了越多的高频信息。很意外的是,利用 BatchNorm 训练出来的模型学到了大量的高频信息:我们可以看到,BatchNorm 对应板块的虚线远远高于其他板块的虚线。这些结果说明 BatchNorm 之所以能够如此有效地提高模型的准确率,可能是在鼓励模型大量使用高频信息。正如前文所说的,在一个数据集里有各种信号,如果一个模型能利用更多的信号,那么它很有可能具备更高的准确率,这也符合我们所熟知的 BatchNorm 能够有效提高测试准确率的特点。直观上来讲,我们猜测 BatchNorm 的优势来源于高频信息的像素值通常比较小(比如在图 1 中,高频重构的图片几乎只是一个黑色的方块)。而 BatchNorm 可能通过 normalization 提高了这个较小的值,使得模型更容易学到相关的信息。那么 BatchNorm 的这个特点代表了什么呢?我们觉得这个特点可能要让工业界和学术界重新审视 BatchNorm 的效果,尤其是要训练的模型在很多数据集上需要有较为稳定的表现的时候。我们发现的这个结论也与其他的结果相互关联,如 Batch Normalization is a Cause of Adversarial Vulnerability。结论
论文还讨论了一些其他的相关问题,例如著名的「rethinking the generalization」论文提到的问题,模型鲁棒性和准确率之间的平衡,还有相关现象在目标检测领域中的讨论。1、由于高频信息很可能随着数据集的变化而变化,SOTA 可能没有我们想象的那么重要,而模型的表现和人的视觉能否相互呼应要重要的多。2、对于计算机视觉,我们可能需要新的测试模式,比如在原有测试集的基础上,同样测试低频信息重构之后的数据集。3、未来,更加直观地把人的视觉特征加入模型中的技术可能会比较重要。
推荐阅读
添加极市小助手微信(ID : cvmart2),备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳),即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群:每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
觉得有用麻烦给个在看啦~