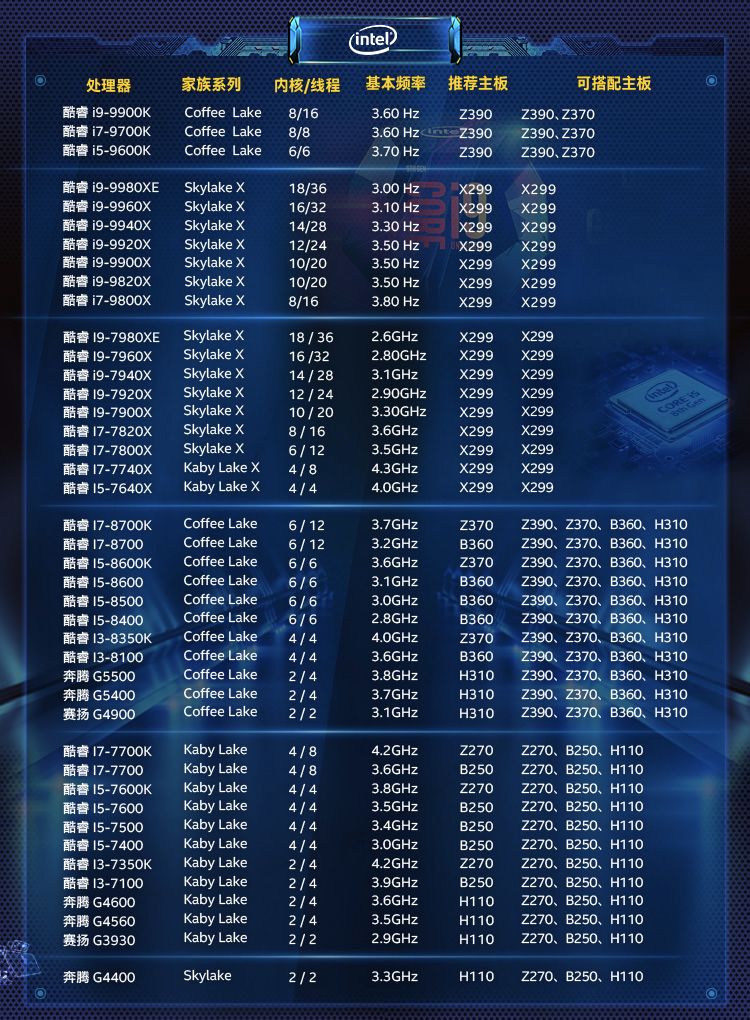
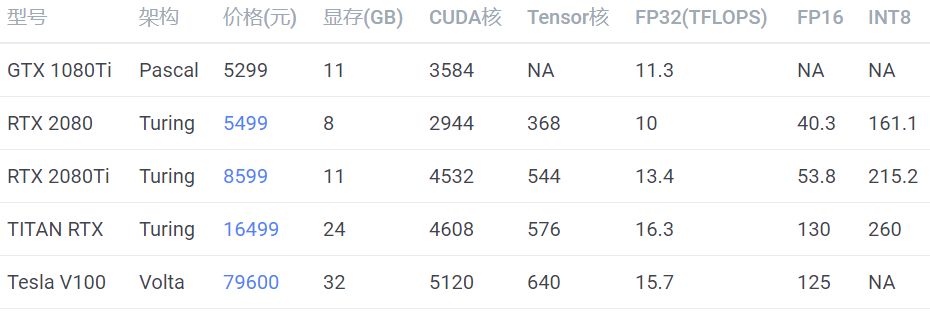
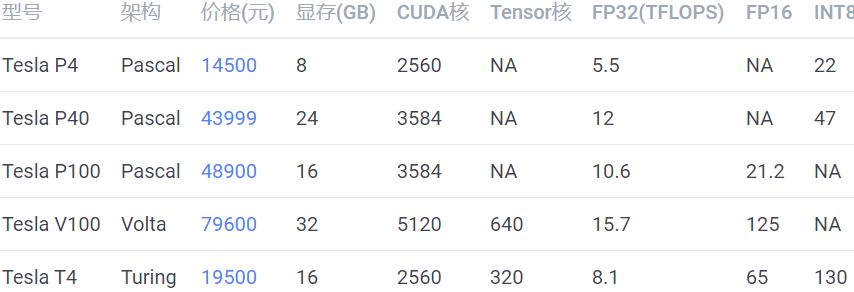
考虑成本可以买 RTX 2080Ti,想要高性能并且高性价比可以买 TITAN RTX,土豪可以选 Tesla V100。RTX 2080 显存较小,不推荐。GTX1080Ti 已经出了太久了,网上都是二手卡,不推荐。采购显卡的时候,一定要注意买涡轮版的,不要买两个或者三个风扇的版本,除非你只打算买一张卡。因为涡轮风扇的热是往外机箱外部吹的,所以可以很好地带走热量,散热比较好。如果买三个风扇的版本,插多卡的时候,上面的卡会把热量吹向第二张卡,导致第二张卡温度过高,影响性能。风扇显卡很有可能是超过双槽宽的,第二张卡可能插不上第二个 PCI-E 插槽,这个也需要注意。除了用于训练,还有一类卡是用于推断的(只预测,不训练),如:这些卡全部都是不带风扇的,但它们也需要散热,需要借助服务器强大的风扇被动散热,所以只能在专门设计的服务器上运行,具体请参考英伟达官网的说明。性价比之选应该是 Tesla T4,但是发挥全部性能需要使用 TensorRT 深度优化,目前仍然存在许多坑,比如当你的网络使用了不支持的运算符时,需要自己实现。英伟达只允许这类卡在服务器上运行,像 GTX 1080Ti、RTX 2080Ti 都是不能在数据中心使用的。No Datacenter Deployment. The SOFTWARE isnot licensed for datacenter deployment, except that blockchain processing in adatacenter is permitted.
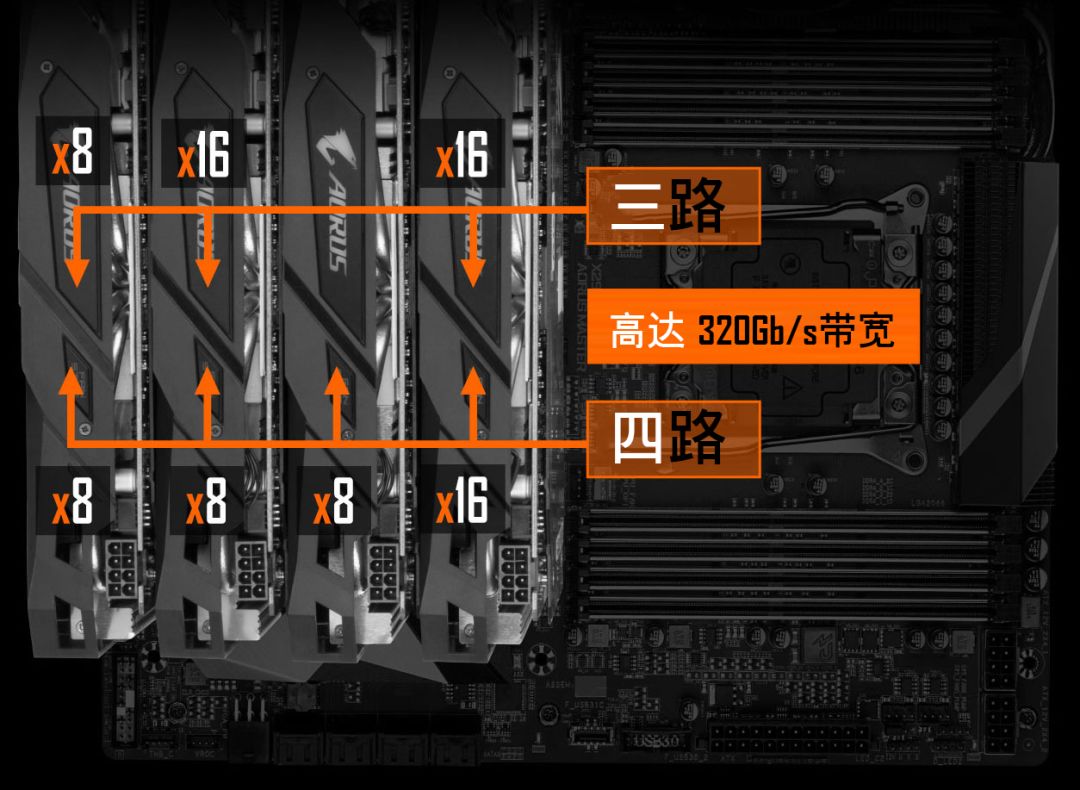
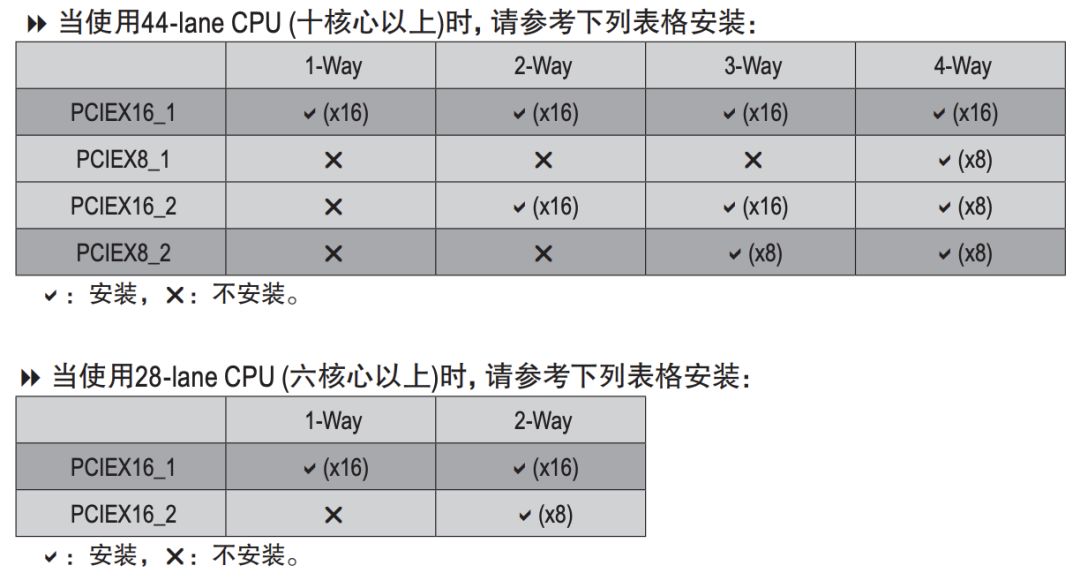
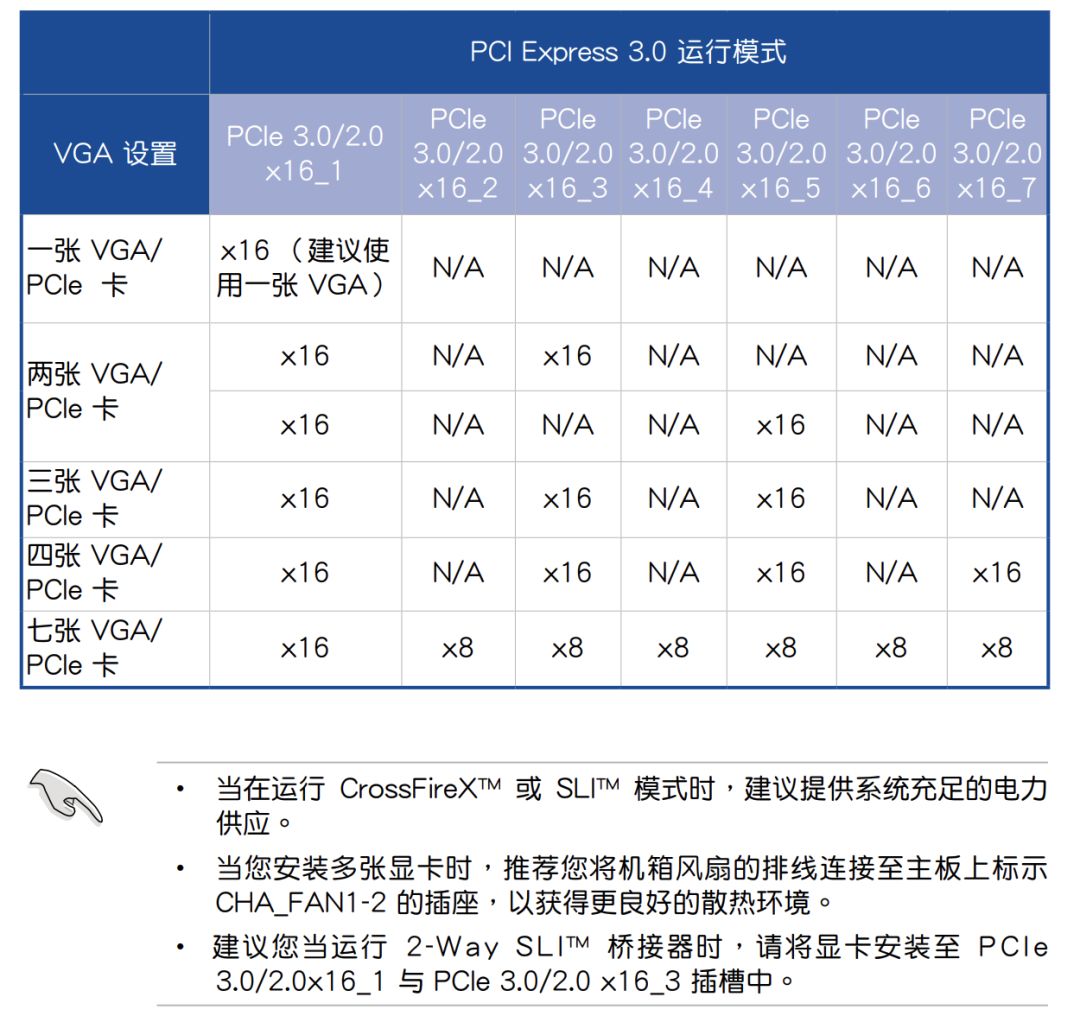
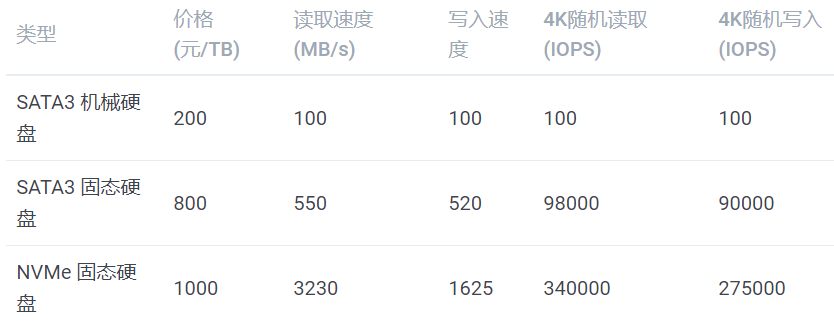
PCIE 3.0 x4(NVMe),速度 3.94GB/sSATA3 机械硬盘没有太好的数据来源,所以数据是经验值SATA3 固态硬盘数据来源:三星(SAMSUNG)1TB SSD固态硬盘 SATA3.0接口 860 EVONVMe 固态硬盘数据来源:英特尔(Intel)1TB SSD固态硬盘 M.2接口(NVMe协议) 760P系在面对大量小文件的时候,使用 NVMe 硬盘可以一分钟扫完 1000万文件,如果使用普通硬盘,那么就需要一天时间。为了节省生命,简化代码,硬盘建议选择 NVMe 协议的固态硬盘。如果你的主板不够新,没有NVMe 插槽,你可以使用 M.2 转接卡将 M.2 接口转为PCI-E 接口。内存容量的选择通常大于显存,比如单卡配 16GB 内存,四卡配 64GB 内存。由于有数据生成器(DataLoader),数据不必全部加载到内存里,通常不会成为瓶颈。先计算功率总和,如单卡 CPU 100W,显卡 250W,加上其他的大概 400W,那么就买 650W 的电源。双卡最好买 1000W 以上的电源,四卡最好买 1600W 的电源,我这里实测过四卡机用 1500W 的电源来带,跑起来所有的卡以后会因为电源不足而自动关机。一般墙上的插座只支持 220V 10A,也就是 2200W 的交流电,由于电源要把交流电转直流电,所以会有一些损耗,最高只有1600W,因此如果想要支持八卡,最好不要在家尝试。八卡一般是双电源,并且需要使用专用的 PDU 插座,并且使用的是 16A 插口,如果在家使用,会插不上墙上的插座。一般主板自带千兆网卡。如果需要组建多机多卡集群,请联系供应商咨询专业的解决方案。如果配单卡,可以直接买个普通机箱,注意显卡长度能放下就行。如果配四卡机器,建议买一个 Air 540 机箱,因为我正在用这一款。深度学习工作站装好系统以后就不需要显示器了,装系统的时候使用手边的显示器就行。深度学习工作站装好系统以后就不需要键盘鼠标了,装系统的时候使用手边的键盘鼠标就行。
参考链接
Turing 架构白皮书
Volta 架构白皮书
RTX 2080 Ti Deep Learning Benchmarks with TensorFlow - 2019
https://developer.nvidia.com/deep-learning-performance-training-inference
https://www.nvidia.cn/object/where-to-buy-tesla-catalog-cn.html
https://www.supermicro.org.cn/support/resources/gpu/
https://www.geforce.com/drivers/license/geforce