
如何“锚定”NLP模型中的语言智慧?丨长文评析语言探针

新智元推荐
新智元推荐
来源:数据实战派
作者:Keyur Faldu等
【新智元导读】本文由两位数据科学家 ——Keyur Faldu 和 Amit Sheth 所撰写,详细阐述了现代自然语言处理的兴起以及可解释性的必要,并结合对当前技术状况的调查,以更好地回答由 NLP 模型所引发的语言智慧相关的一些开放性问题。
当然,还有其他方面需要深入分析,例如:
更大的模型能够更好的编码语言知识吗?模型所捕获的语言知识在复杂性方面(维度大小,参数数量)如何变化?探索不同复杂度模型在辅助任务上的分类器性能,可以对此问题作出解释。
如何评估模型对语言知识进行编码的泛化能力?探针在编码语言知识上的成功可看作模型测试复杂数据时泛化能力的标志。例如,如果训练数据通常将 “主要助动词” 作为第一个动词,而广义的数据故意包含干扰因素,则 “主要助动词” 不再是第一个动词如何处理?在这种情况下,如果探针可以检测到 “主要助动词”,则可以将其归因于诸如语法解析树之类的语言特征,而非顺序位置特征。
我们可以解码语言知识,而不是依赖于浅层探针分类器标签吗?在探索解码语言知识的能力中发现,与解码或构建语言知识的任务相比,分类任务的复杂性相对较低,那能否使用内部表示构建一个完整的依存解析树呢?或许寻找恢复潜在语言知识的方法将会是一种非常有趣的体验。
探针的局限性是什么?当探针能够很好地完成辅助语言任务时,是由于某种相关性,还是有因果关系?考虑到深层而复杂的探针模型也具有记忆能力,很可能会导致过拟合现象。那么,如何验证探针所表达的语言知识的来源呢?可以尝试以下方案,在设计 “控制任务” 时,将探针的预测性能与控制任务的性能进行比较,便于揭秘探针的有效性和语言知识的来源。
我们可以注入语言知识吗?如果神经网络模型在训练端到端任务的过程中学习语言知识,那么,是否可以考虑注入语言知识(即语法解析树)来提高性能呢?
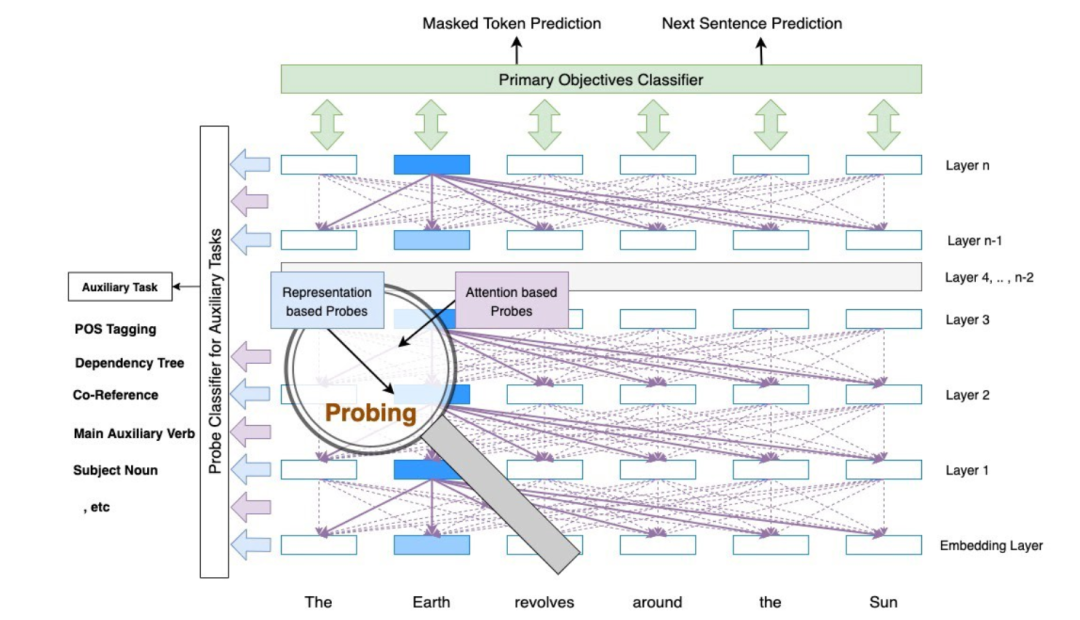
图 1 BERT 模型上的探针说明图
模型越大,效果越好?
文中,三个与句子结构相关的辅助任务考虑如下:
句子长度(Sentence length):句子嵌入是否在句子长度上编码信息?
单词内容(Word-content):是否可以根据句子嵌入来预测句子中是否包含某个单词?
单词顺序(Word-order)。给定句子嵌入和两个单词,能否确定两个单词的顺序?
这些探针基于句子嵌入,而该句子嵌入是由编码器 - 解码器模型和连续词袋模型(CBOW, Continuous Bag-of-Words Model)产生的最终表示的平均值来计算的。该论文的主要发现是 —— 大的模型可以更好地对语言知识进行编码。
如下所示:
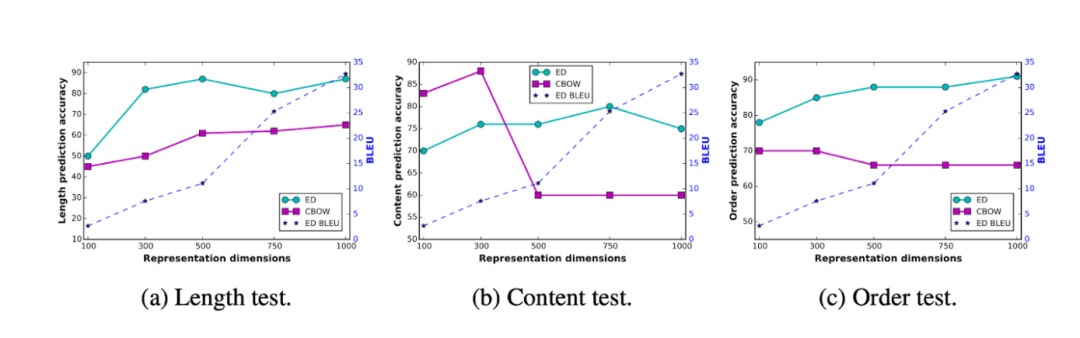
图 2 图片出处:ICLR 2017
泛化能力
 图 3 图片出处:ACL 2019
图 3 图片出处:ACL 2019
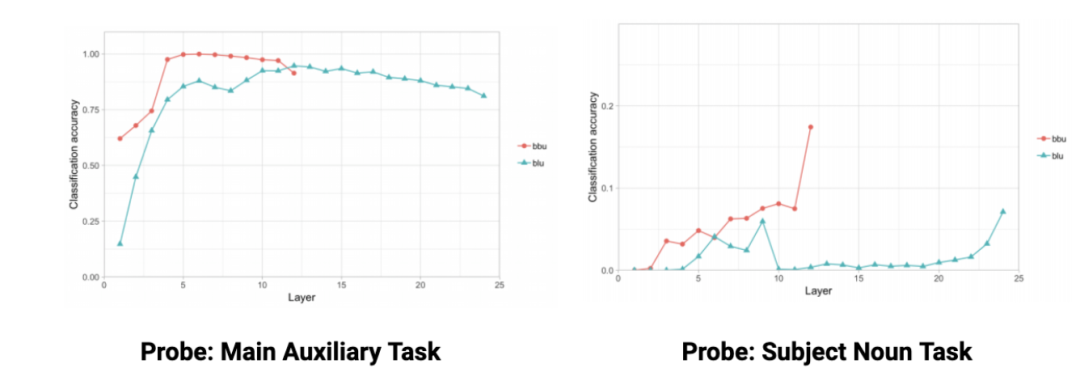
图 4 图片出处:ACL 2019
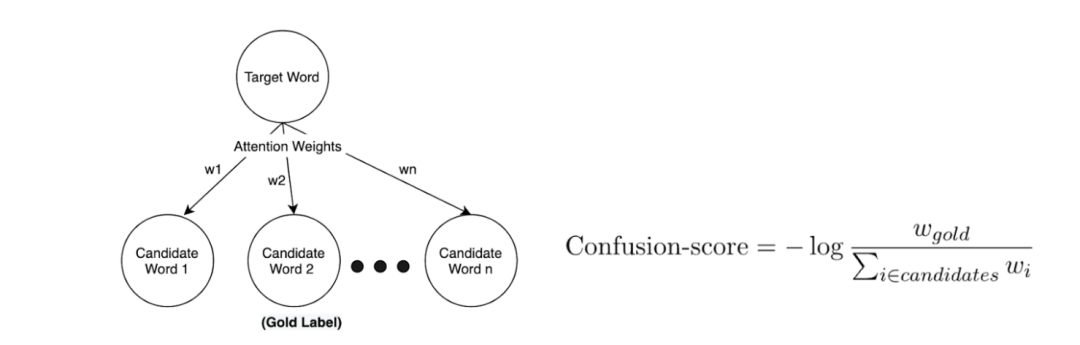
图 5 图片出处:ACL 2019

图 6 图片出处:ACL 2019
语言知识的解码能力
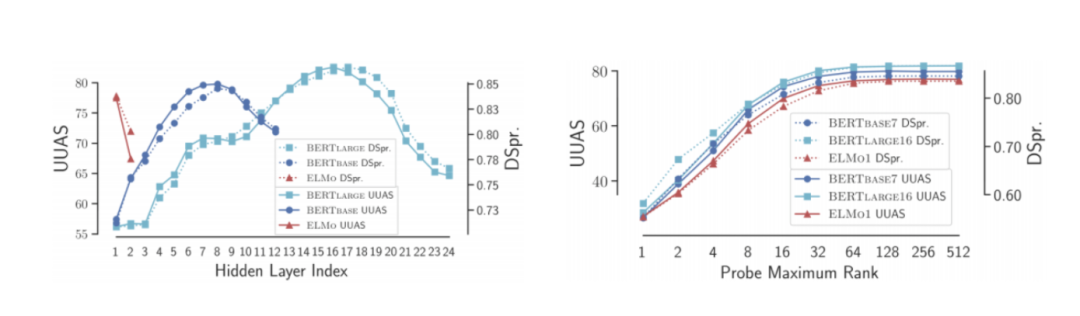
图 7 图片出处:NAACL 2019

图 8 图片出处:NAACL 2019
语言知识的局限和来源
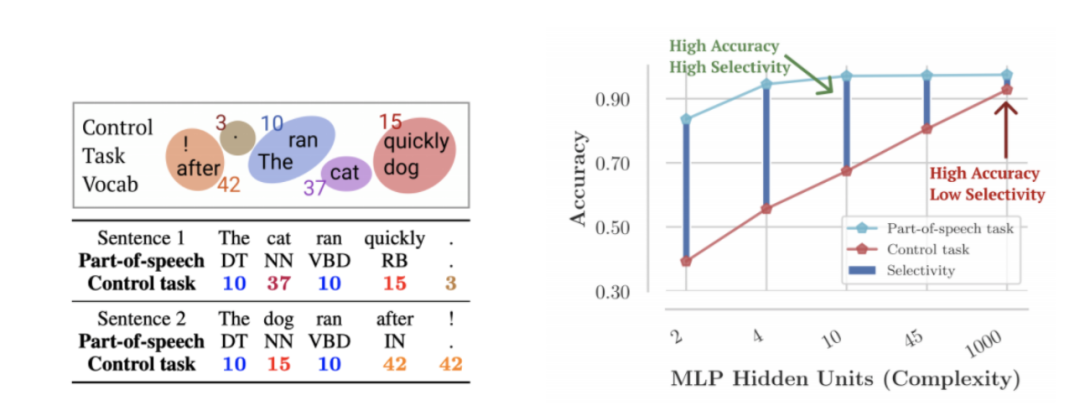
图 9 图片出处:EMNLP-2019
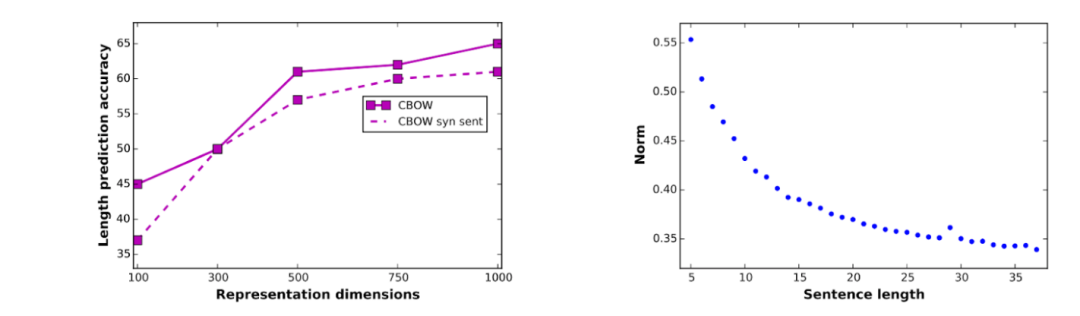
图 10 图片出处:ICLR 2017
注入语言知识

图 11 图片出处:TACL 2020
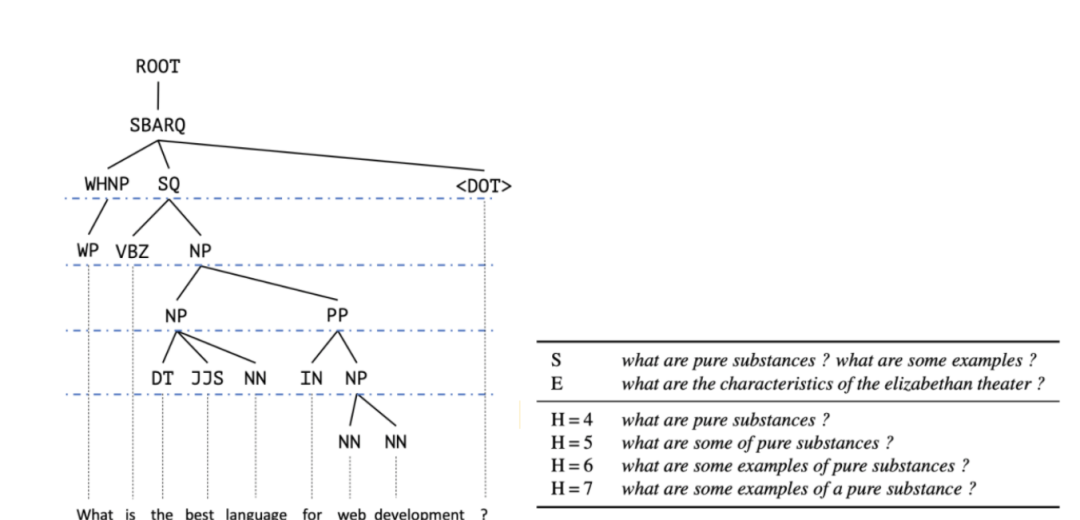
图 12 图片出处:TACL 2020
编码语言知识能否捕获其含义?
最小功能测试(MFT, Minimum Functionality Tests),其中使用预期的金标生成示例;
不变性测试(INV, INVariance Tests),其中从给定的示例中,创建新示例,其中金标被翻转;
方向预期测试(DIR, Directional Expectation Tests)对原始句子进行修改,金标往期望的方向(正向 / 负向)变化。
作者建议对于 NLP 模型的每一种能力,都尽量采用这三种测试方法测试一遍。
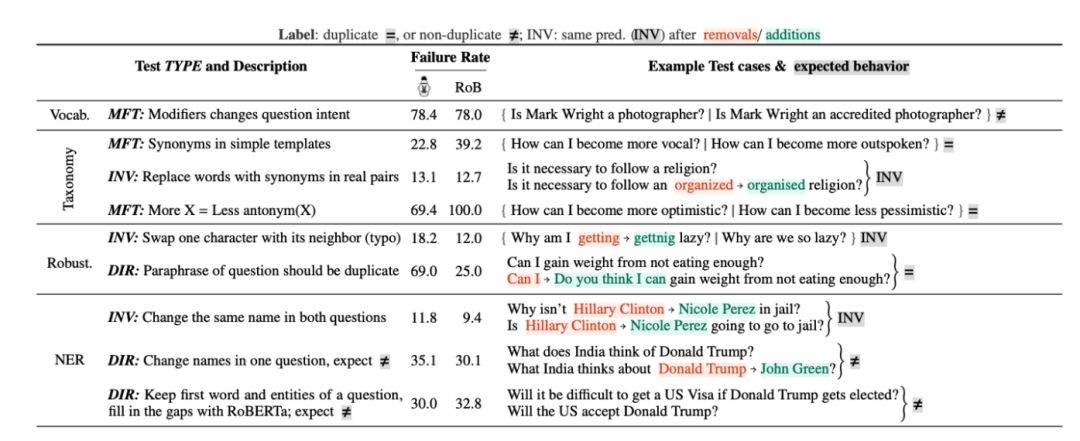
图 13 图片出处:ACL 2020
NLP 模型确实可以对语言知识进行编码,以解决某些下游 NLP 任务。
较大的模型或表示形式不一定更好编码语言知识。
为句法任务编码的语言知识可以泛化到具有复杂句子结构的测试数据,这归因于模型对语言语法的编码能力。
较深层次的探针可能会过度拟合并潜在地记忆辅助任务,从而导致我们对编码语言知识的估计过高,得出误判,所以,建议设计探针的控制任务。
提供语言知识后,模型可以更好地完成从此类知识中寻求指导的任务。
句法语言知识不足以捕捉自然语言理解的含义,甚至目前最前沿的模型离实现 NLP 任务所需的理解也尚有差距。

