本来昨晚全身心准备学习材料来,但是无意中检索到三本统计学的pdf,分别翻看了一遍。
第一本统计学,一共130+页,全书一气呵成,很少见到把统计学的概念串联的,这么好的,所以忍不住再发出来。
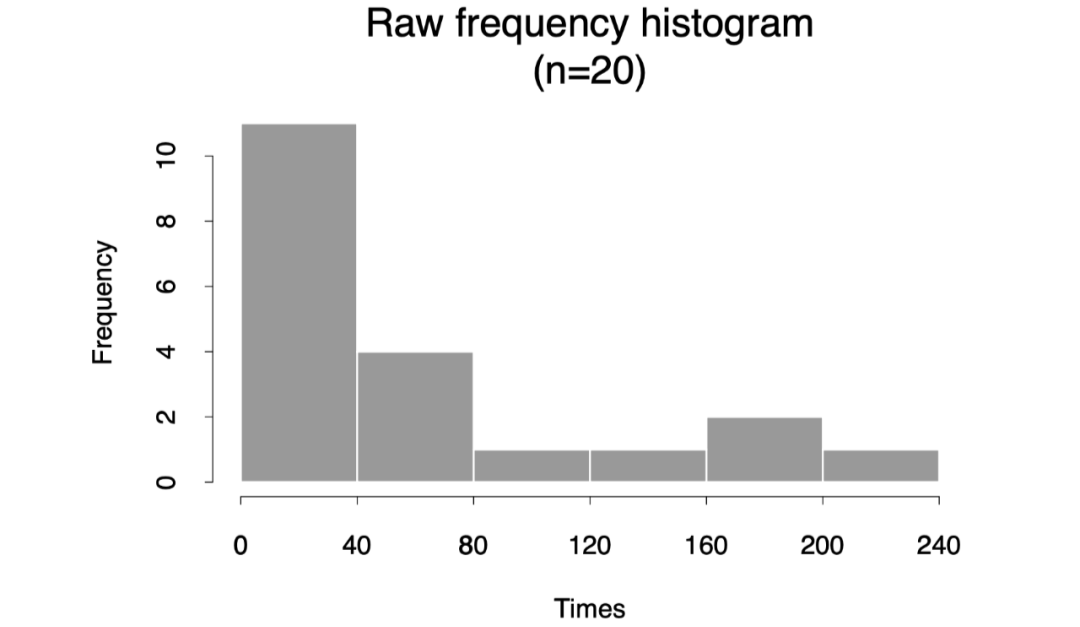
书中一幅图,原始频率分布直方图
这也是此书的一大特点,它不是一上来累计概念,而是从最基本的统计常识演绎出统计学的主要理论概念,写的比较通俗。做到这点,显然不容易。需要很深的统计学功底,并有很长地应用统计学的实践经历,才有可能写出来。
三本统计学书PDF已经打包好,获取步骤如下:
1. 点击下方👇名片,关注公众号「数据STUDIO」(非本号)
2. 回复关键词:2022
注:此次建议复制,不然容易打错
▲点击关注「数据STUDIO」回复2022
第二本,统计学与数据分析,这本书适合初学者和各种背景的自学者,包括社会学、生物学、经济学、心理学、医学等。每一章的介绍都非常详细、通俗易懂,还会在附录补充详细的严格的数学推导证明,供不同需求的读者阅读。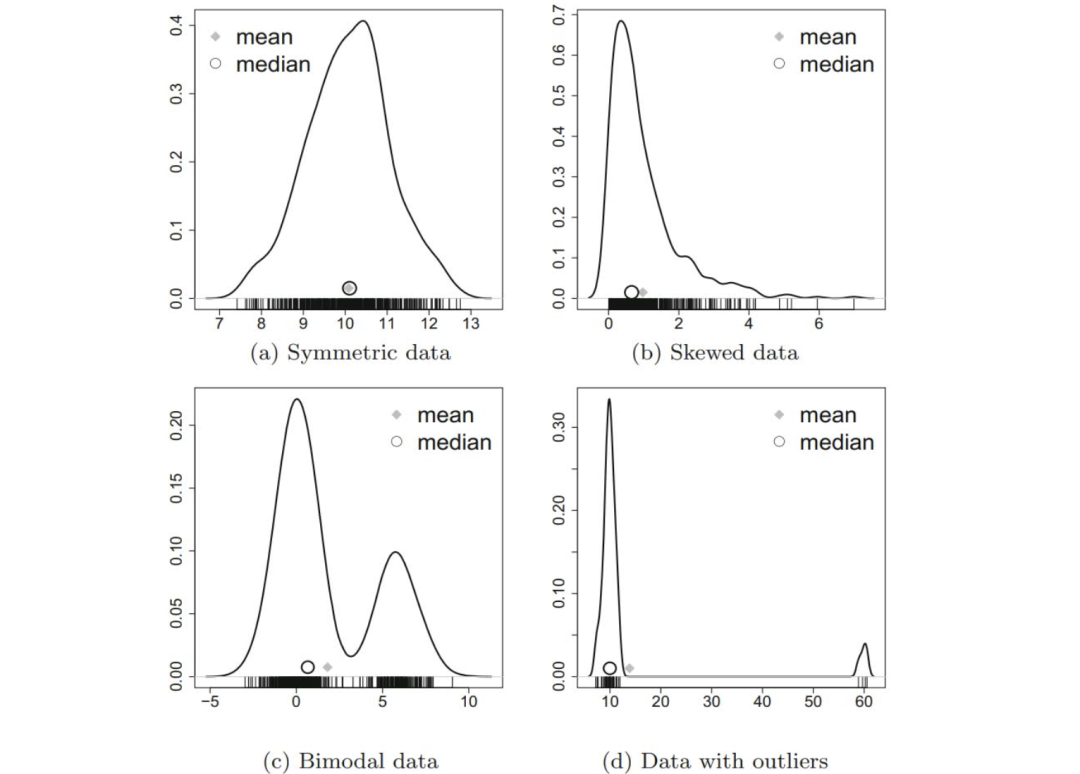
不同数据的算术平均数和中位数
第三本是机器学习中的统计学,本书介绍了机器学习的新趋势,深度学习和强化学习的基础知识,并提供了适当的示例。帮助新手快速掌握各种基础知识,同时也让有经验的专业人士更新他们对各种概念的知识,并在他们选择的数据上应用算法时更清晰。
每一章都开源了数据集及代码
第一章,从统计到机器学习的旅程,介绍了所有必要的基础和基本的统计和机器学习模块。在本章中,所有的基本原理都通过Python和R代码示例进行了解释。第二章,统计和机器学习的并行性,比较了统计建模和机器学习之间的差异。第三章,逻辑回归与随机森林,描述了逻辑回归与随机森林之间的比较,使用一个分类例子,解释了这两个建模过程的详细步骤。在本章结束时,您将对统计数据流和机器学习有一个完整的了解。第四章,基于树的机器学习模型,重点介绍了行业从业者使用的各种基于树的机器学习模型,包括决策树、bagging、随机森林、AdaBoost、梯度推进和XGBoost。第五章,K-Nearest Neighbors和Naive Bayes,阐述了机器学习的简单方法。用乳腺癌数据来解释k近邻。通过一个使用各种NLP预处理技术的消息分类例子来解释朴素贝叶斯模型。第六章,支持向量机和神经网络,描述了支持向量机中涉及的各种功能和核的使用。然后介绍神经网络。本章将详尽地介绍深度学习的基础知识。第七章,推荐系统,向我们展示了如何根据相似的用户找到相似的电影,这是基于用户-用户相似度矩阵。第二部分基于movie-movies相似度矩阵给出推荐,该矩阵使用余弦相似度提取相似电影。最后,应用了协同过滤技术,该技术考虑了用户和电影来确定推荐,并采用了交替使用的最小二乘方法。第八章,无监督学习,介绍了各种技术,如k-均值聚类,主成分分析,奇异值分解,以及基于深度学习的深度自动编码器。最后解释了为什么深度自动编码器比传统的PCA技术更强大。第九章,强化学习,提供了详尽的技术,学习最优路径,以达到一个目标的情景状态,如马尔可夫决策过程,动态规划,蒙特卡罗方法,和时间差异学习。最后,提供了一些使用机器学习和强化学习的优秀应用的用例。
三本统计学书PDF已经打包好,获取步骤如下:
1. 点击下方👇名片,关注公众号「数据STUDIO」(非本号)
2. 回复关键词:2022
注:此次建议复制,不然容易打错
▲点击关注「数据STUDIO」回复2022
🏴☠️宝藏级🏴☠️ 原创公众号 『数据STUDIO』,内容超级硬核。公众号以Python为核心语言,垂直于数据科学领域,包括可戳👉 Python|MySQL |数据分析|数据可视化|机器学习与数据挖掘|爬虫 等相关知识,从入门到进阶!
长按👇关注- 数据STUDIO -设为星标,干货速递



