
pandas中鲜为人知的隐藏排序技巧

添加微信号"CNFeffery"加入技术交流群
❝本文完整示例代码及文件已上传至我的
❞Github仓库https://github.com/CNFeffery/PythonPracticalSkills
这是我的系列文章「Python实用秘技」的第7期,本系列立足于笔者日常工作中使用Python积累的心得体会,每一期为大家带来一个几分钟内就可学会的简单小技巧。
作为系列第7期,我们即将学习的是:在pandas中实现自然排序顺序。

自然排序顺序(Natural sort order),不同于默认排序针对字符串逐个比较对应位置字符的ASCII码的方式,它更关注字符串实际相对大小意义的排序,举个常见的例子,假如我们有下面这样的一张表,其中value字段是百分比格式的字符串:
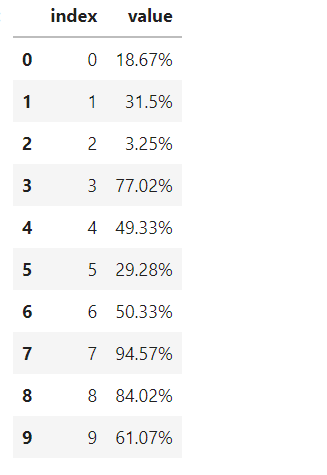
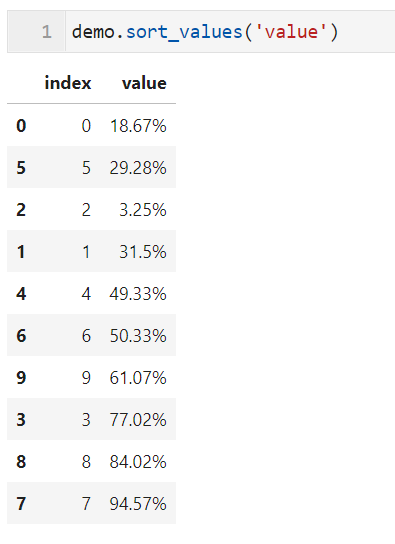
这时如果直接照常基于value字段进行排序,得到的结果明显不符合数据实际意义:
而我们今天要介绍的技巧,就需要用到第三方库natsort,使用pip install natsort完成安装后,利用其index_natsorted()对目标字段进行自然顺序排序,再配合np.argsort()以及pandas的sort_values()中的key参数,就可以通过自定义lambda函数,实现利用目标字段自然排序顺序进行正确排序的目的:
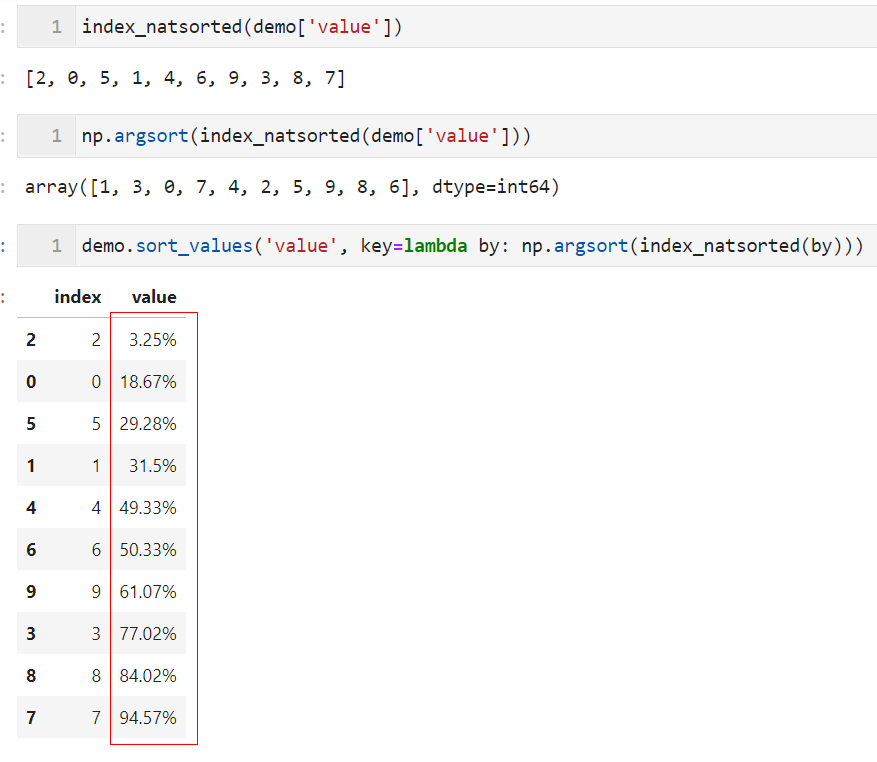
可以看到,此时得到的排序结果完美符合我们的需求~
更多natsort知识欢迎前往https://github.com/SethMMorton/natsort学习更多。
本期分享结束,咱们下回见~👋
加入知识星球【我们谈论数据科学】
500+小伙伴一起学习!
· 推荐阅读 ·
评论