
[Flutter 渲染优化系列] Flutter 渲染性能问题分析

作者:易旭昕
原文链接:https://zhuanlan.zhihu.com/p/354631257
本文由作者授权发布。
易老师写了很多篇关于 Flutter 渲染引擎的文章,讲的非常深入,我从中学到了很多,昨天很有幸的加到易老师微信,表达了一番崇敬之情,易老师人非常好,也非常谦逊。
最后表达一点小小的心意,发了个红包,不管怎么说,学到了很多知识,知识是无价的,不过易老师并没有收,大家也可以到易老师到博客中看看其他文章,点赞、转发也是一种支持,后面我也会继续分享易老师的文章。
正文
我在Flutter vs Chromium 动画渲染的对比分析一文中对 Flutter 和 Web (Chromium) 的各种动画的理论性能优劣进行了分析,其中一个主要结论是,由于惯性滚动处理机制和光栅化机制的不同,Web (Chromium) 的惯性滚动动画性能理论上要远远优于 Flutter。而在一些已经上线的使用 Flutter 的业务中,业务方也持续给我们反馈了这些业务在中低端 Android 手机上存在比较严重的惯性滚动性能问题:
业务 A 的页面较为简单,但是在低端手机上平均帧率在 40 ~ 50 之间,中端手机在 50 ~ 55 之间,低端机存在较为明显的卡顿问题; 业务 B 的页面比较复杂,业务逻辑也较为复杂,在低端手机上平均帧率更是低到最低 30 多帧(35 ~ 45 之间),中端手机也是在 50 左右,并且存在较为频繁的长时间卡顿,低端机存在比较严重的卡顿问题,中端机也不太流畅;
而以我们长期的经验数据,对于 Web 来说,即使在低端手机上,较为复杂的页面惯性滚动帧率一般也在 50 以上,也较少长时间的卡顿,达到基本流畅的水平。并且刚好业务 B 有完全一样的 Native 版本,它对比 Flutter 版本,帧率普遍高了 5 ~ 10 帧左右。
所以虽然我们没有找到同一个页面的三个不同版本进行严格的比对,但是基于上述的测试数据和我们长期的经验,很容易得出结论是,在惯性滚动的性能上:
Web (Chromium) > Native (Android) > Flutter (Android)
我们在不同设备上对上述业务页面在惯性滚动过程中进行 trace 的抓取,结合 Flutter 的代码对 trace 文件进行分析,了解 Flutter 渲染流水线在惯性滚动过程中各个环节的调度,了解各个环节的可能耗时和哪些环节可能成为性能瓶颈。在分析的过程中,我们对 Flutter 的渲染机制有了更深入的了解,这篇文章就是对比 Web (Chromium) 和 Native (Android),对 Flutter 的渲染性能问题进行深入分析,特别是分析惯性滚动性能糟糕的原因。
\1. 这里的帧率数据给的是一个范围是因为我们使用了几种不同的滚动速度进行测试,一般来说滚动速度越快,平均帧率就越低
\2. iPhone 基本不存在所谓的低端机,iOS 整体表现都还可以,不同实现的差异不大,所以我们目前主要的测试和优化都是在 Android 上进行
写在前面的结论
Flutter 有很多优点,特别是对于开发者来说,跨平台多端支持,丰富的 UI 组件库和交互效果,声明式 UI,React 的更新方式,Hot-reload 提高开发效率等等。虽然它在渲染性能上有不少缺陷,但是某种程度上,某些缺陷也是为了实现更高层次的设计目标而不得不承受的结果。
比如 Dart 语言原生对异步编程有良好的支持,应用开发者不需要去编写复杂和容易出问题的多线程代码,就可以有效地避免主线程长时间阻塞,编写出性能良好的 UI。但是在惯性滚动这样对性能要求非常高场景下,可能几毫秒的阻塞都会导致掉帧,缺少真正的多线程编程能力某种程度就变成了一种阻碍(Android 上你甚至可以在其它线程对 View 做非 UI 直接相关的操作)。
又比如使用 Immutable Widget 作为 UI Configuration 的设计是声明式 UI 和 Hot-reload 的基础,但还是会引入额外的开销和丧失足够的灵活性,应用无法直接控制 UI 组件的生命周期,无法直接控制 UI 组件的布局和绘制,这同样妨碍了惯性滚动的性能优化。
而对我们内核团队来说,要做的就是在理解 Flutter 这些缺陷的同时,去研究是否存在有效地进行局部改进,或者从其它设计层面上对某些缺陷进行规避的方法,让应用开发者既可以充分利用 Flutter 的优势,又不用过于担心它存在的问题。
总的来说下半年的工作目前看来还是取得了不错的成果,也基本实现了让 Flutter 惯性滚动性能对标原生的目标,下图比较直观地展示了我们优化的结果。
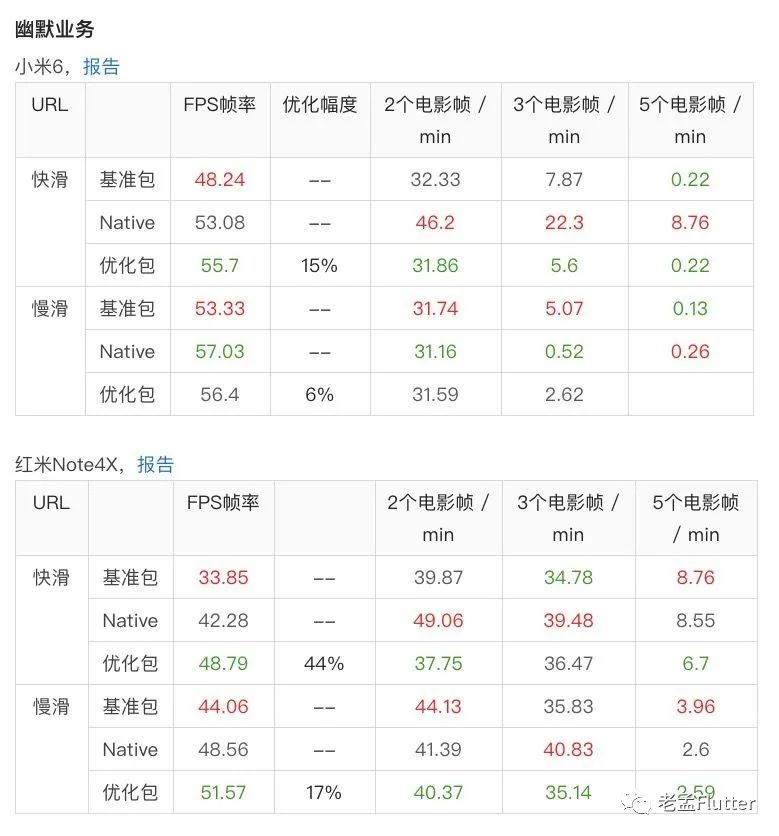
这里电影帧是指 1000 / 24 约 40毫秒,2个电影帧 / min 是指连续滚动一分钟内出现超过 80 毫秒卡顿的次数
Web (Chromium) vs Flutter
Web (Chromium) 在惯性滚动上是有非常明显的机制优势的,这跟 Web 渲染引擎为了适应 Web 页面的高复杂度,高不确定性有关,甚至某种程度上牺牲了一些渲染效果和其它动画的渲染性能。Web (Chromium) 在惯性滚动上的优势主要体现在以上两方面:
Chromium 有完整独立的合成器驱动惯性滚动动画的运行,有独立的合成线程,惯性滚动动画的更新和主线程更新 DOM 树是不同步的,主线程运行 JS,Build & Layout 不会阻塞合成线程; Chromium 的分块异步光栅化机制一方面减少了惯性滚动动画过程中图层的重复光栅化,另一方面光栅化不会阻塞合成线程的合成输出;
对比 Web (Chromium),Flutter 在上述两方面都存在比较明显的劣势:

Flutter 需要依赖于 Relayout 来驱动惯性滚动动画,滚动容器内的元素在滚动过程中每一帧都需要 Relayout,不过这个一般耗时不高。Flutter 的无限长列表一般都采用 Lazy Build 的方式生成列表单元,当列表单元接近可见区域的时候,框架才调用应用提供的 Builder 生成列表单元的 Widget 树并进行布局,新挂载的列表单元的 Build & Layout 通常耗时较长,在上述业务页面中,可能耗费 10 毫秒以上,甚至几十毫秒,特别是单帧内需要 Build 多个单元的情况,它们是导致掉帧的主要原因。从上图 trace 中我们很容易发现,正常速度滚动下,在 Flutter UI 线程 Frame 的阶段,大部分情况下耗时不高,但是每几帧就会出现一次耗时较长的 Frame,从上图看耗时较长的 Frame 已经接近甚至超过一个 vsync 周期,滚动速度越快,出现耗时较长的 Frame 的频率就越高,耗时也可能越长,它的耗时主要就来自新挂载列表单元的 Build & Layout。
Flutter 采用的以直接光栅化为主,间接光栅化为辅的同步光栅化机制,在合成输出过程中进行光栅化,光栅化的耗时会直接影响动画的性能。以实际业务为例子:
业务 A 的页面较为简单,光栅化耗时大部分在 3 ~ 5 毫秒之间,除了偶尔波动较高外,基本没有造成阻塞,所以业务 A 的大部分掉帧都是 Flutter UI 线程的 Frame 耗时较高导致; 业务 B 的页面比较复杂,光栅化耗时大部分在 7 ~ 10 毫秒之间,偶尔波动超过 10 毫秒,所以部分掉帧主要是光栅化导致的; 实际上我们还碰到一个页面因为大范围使用 Backdrop Filter 导致光栅化耗时非常高,在低端机上只有 10 ~ 20帧,不过这个可以在应用层面做一些优化来避免;
总的来说,Flutter 在惯性滚动过程的掉帧大部分都来自 Flutter UI 线程的阻塞,新挂载列表单元的 Build & Layout 耗时过长是主要原因。但是对于一些比较复杂的页面,光栅化耗时较长也是一个导致掉帧的原因。
我们在 Chromium 光栅化改造 - 混合光栅化 对比了不同光栅化机制在合成输出过程中的光栅化+合成输出的耗时,异步光栅化机制在这方面会有明显的优势,这也是我们在 U4 4.0 上采用了混合光栅化的原因
Flutter 虽然提供了 KeepLive 机制用于避免列表单元滚出可见区域被回收,重新滚入可见区域又重新 Rebuild & Relayout,但是 KeepLive 机制并不适用于第一次显示的列表单元,并且在无限长列表场景很容易造成内存爆炸,适用场景不多
Native (Android) vs Flutter
如果说 Web (Chromium) 因为机制的原因,惯性滚动性能明显优于 Flutter,这个比较容易理解。那么 Native (Android) 在机制上其实跟 Flutter 是比较类似的,为什么它的性能也会优于 Flutter 呢?
Android 无限长列表一般使用 RecyclerView 实现,而 RecyclerView 支持子 View 树级别的复用,使得新挂载的列表单元在 RecyclerView 的支持下,只需要更新复用的子 View 树的数据然后局部重排即可,耗时会大大少于 Flutter 整个列表单元的完整 Build & Layout,这是 Native (Android) 的无限长列表滚动更流畅的主要原因。不过除此以外,还有很多因素也会影响到 Flutter 的流畅度。
跟 Native 相比较,Flutter UI 线程会显得更拥挤。Dart Isolate 的内存堆是隔离的,这点比较像 JavaScript,Isolate 之间的关系更像是多进程而不是多线程,导致了一些多线程优化很难实现。应用通常要注册多个回调来处理外部传入的数据或者事件,这些回调接收外部数据或者事件,进行处理后更新内部数据(Model),通常这些回调都需要在 UI 线程执行。如果它们集中频繁地发生,即使单次耗时不高,也很容易造成 Flutter UI 线程的阻塞,简单说就是这些非 UI 任务的频繁执行可能会导致惯性滚动过程中 UI 任务的延迟,最终导致掉帧,但是 Dart Isolate 的限制,对内部数据的更新又必须在 UI 线程上进行。
大部分应用都是局部使用 Flutter 开发,需要跟 Native 进行混用,这就导致了应用很难使用 SurfaceView,而需要使用 TextureView。TextureView 会带来一些额外的性能问题,除了更高的 GPU 开销外,TextureView 的绘制机制也容易出现因为调度的不合理而导致掉帧。
最后虽然 Android 和 Flutter 都是以直接光栅化为主,间接光栅化为辅的同步光栅化机制。但是将 Skia 作为 UI 的光栅化引擎,比起为 UI 专门定制的光栅化引擎可能还是存在一些缺陷:
Skia GPU 光栅化的过程,涉及将通用的 2D 绘制指令转换成一种接近 GPU 指令的内部形式,然后经过进一步优化后输出最终的 GPU 指令,为 UI 专门定制的光栅化引擎理论上可以缓存第一步的结果,减少每一帧光栅化的耗时; Skia 作为一个通用的光栅化引擎,内部实现是线程无感的,而为 UI 专门定制的光栅化引擎可以更容易使用多线程来将光栅化过程中部分 CPU 工作并行化,比如生成字型或者路径顶点等任务;
不过我们没有实际去比较两者的光栅化性能差异,这里只是一些理论分析。
TextureView 的调度问题更详细的信息可以参考我的文章TextureView 的血与泪
应用层面优化和局限性
针对 Flutter 的惯性滚动性能问题,不少应用也尝试了各种优化方案,比如闲鱼的方案就比较有代表性。针对新挂载列表单元的 Build & Layout 耗时过长,闲鱼的优化方案是 Element 复用和分帧渲染。
Element 复用其实就是参考 RecyclerView 的子 View 树复用,理论上可以避免重新创建列表单元的 Element 树和 RenderObject 树的时间开销。但是对比 Native,仍然需要重新构建 Widget 树,并把新的 Widget 树跟旧的 Element 树进行绑定,并通过 Element 树去更新 RenderObject 树。而 Native 则可以直接复用 View 树,然后更新若干子 View 的数据即可,这部分的开销仍然比优化过后的 Flutter 要低。
分帧渲染的思路是每个列表单元提供两个版本的 Widget 树,除了完整版,还有一个简化版作为占位符。如果单帧内已经 Build 过一个完整版本的单元,在需要 Build 第二个单元时就只 Build 简化的版本,这样可以避免单帧内多个列表单元的 Build & Layout 叠加在一起造成更大的阻塞。它的局限性是主要适用于列表单元较小,惯性滚动速度较快,一帧滚动会出现多个列表单元需要 Build & Layout 的场景,对避免更长时间的卡顿有一定作用。只是这个优化 Android Native 看起来也完全能做,并且因为 Android 应用可以直接控制 View 是否参与布局和绘制,理论上做起来也更简单,效果也更好。
总的来说,Flutter 应用的一些优化,要不是 Native 本来就已经实现,并且效果更好;就是 Native 同样也可以实现,而且实现起来更简单,效果也更好,并且其它一些影响 Flutter 性能的因素在应用层面无法进行优化。
所以 Flutter 应用优化起来可能比 Native 更麻烦,最后的效果也还是比不上 Native。一个优化后的 Flutter 应用,比起一个优化后的 Native 应用,在惯性滚动上还是会有一定性能差距。
我们的优化尝试
作为一个引擎团队,我们期望实现的目标是从框架和引擎层面对 Flutter 渲染流水线的方方面面进行优化,使应用在不需要改动或者极少量改动就能实现基本对标原生的惯性滚动流畅度,如果应用本身再进一步优化,甚至有可能获得优于原生的效果。
我们尝试了各式各样的优化,包括:
优化线程的优先级设置,更好地保障渲染流水线的前台线程,UI 和 Raster 线程不会因为无法获取到 CPU 调度而阻塞; 优化渲染流水线的 vsync 调度,减少一些不必要的耗时和空等; 优化渲染流水线针对 TextureView 绘制的调度,规避 TextureView 绘制机制的副作用; 重构渲染流水线的调度逻辑,通过更深的流水线深度来增加输出的吞吐量,使得输出更平稳连续; 优化一些布局算法,减少布局耗时; 优化新挂载列表单元的 Build & Layout 的调度,减少其成为性能瓶颈的可能,比如说将新挂载单元的 Build 和 Layout 拆分到不同帧去执行; 优化光栅化性能,比如更好地支持客户端使用类似 Web 开发的 Opacity Hack 的技巧,通过使用间接光栅化来减少光栅化耗时;
从目前来看,部分优化尝试的效果还是十分明显,有些优化的覆盖面很广,适用于几乎所有的场景,而有些优化对特定场景效果比较好。总的来说,测试的业务页面运行在我们优化过后的引擎,整体流畅度能够明显提升一个台阶,也基本实现了我们对标原生流畅度的目标。在后续的文章中,我会逐步介绍我们所做的一些优化,同时我们也会争取将一些优化的代码提交回社区。
Stay tune, my friends, stay tune...
