
大佬免费直播 | 如何让 Hbase 更快、更稳、更省钱?
一转眼假期就过去了,又是一个金三银四,各大厂纷纷开始疯狂撒钱招人。Hbase 工程师作为大数据时代的香饽饽,更是被开出了天价,平均薪资高达 60 W!


但在工作中,我们在存储读写海量数据的时候经常会面临以下几个问题:
数据安全不丢失:数据分析挖掘都依赖于我们保存的数据,只有做到数据的无损,才有可能任意的定义指标,满足各种业务需求。
保证数据实时性:数据的实时性越来越重要,实时的数据能够更好的运维产品和调整策略,价值更高。单进程每秒接入3.5万数据以上,数据从产生到能够查询到结果这个间隔不会超过5秒。
业务需求快速响应:随着越来越快的业务发展和数据应用要求的提高,数据的查询需要更灵活,快速响应不同且多变的需求。最好是任意定义指标后能够实时查询出结果。
超大数据集,统计分析秒级响应:万亿数据量级,千级维度(非稀疏)的统计分析秒级响应。
这些也是大数据岗位面试中会遇到的高频问题。
明确海量大数据存储的 4 大难点
掌握万亿级数据快速随机读写的实现方案
揭秘拉勾网 HBase 存储设计与使用场景
针对海量用户数据,全方位掌握 HBase 存储调优
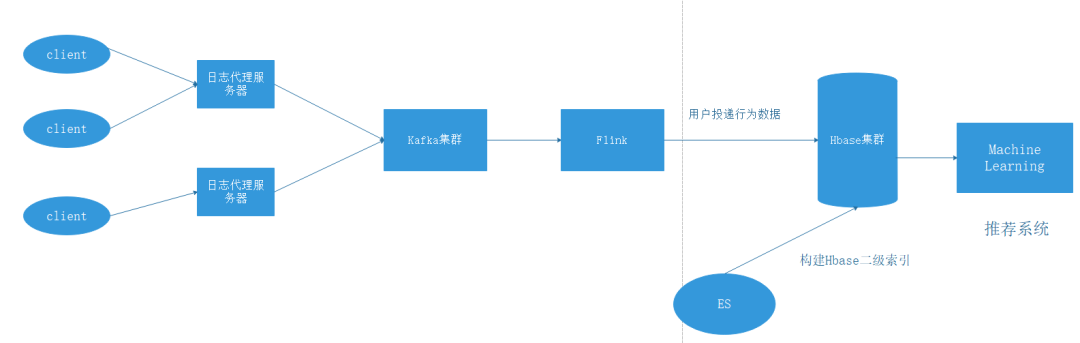
另外,直播结束后小助手还会发放 185 道大数据岗位的面试真题资料包,都是从美团、快手等大厂面试中整理出来的,想要的同学可以扫码获取直播链接哦。

课程大纲 | |
评论