
多模态模型GILL:生成+理解,CMU华人博士新作
本文 新智元 编辑:桃子
【新智元导读】CMU全新多模态模型GILL,能够生成图像、检索图像,还能进行多模态对话。
近日,来自CMU的研究人员全新提出了一种多模态模型GILL。

论文地址:https://arxiv.org/pdf/2305.17216.pdf
它可以将文本或图像作为prompt,完成多模态对话。具体来说,可以实现生成文本、检索图像、生成新图像。
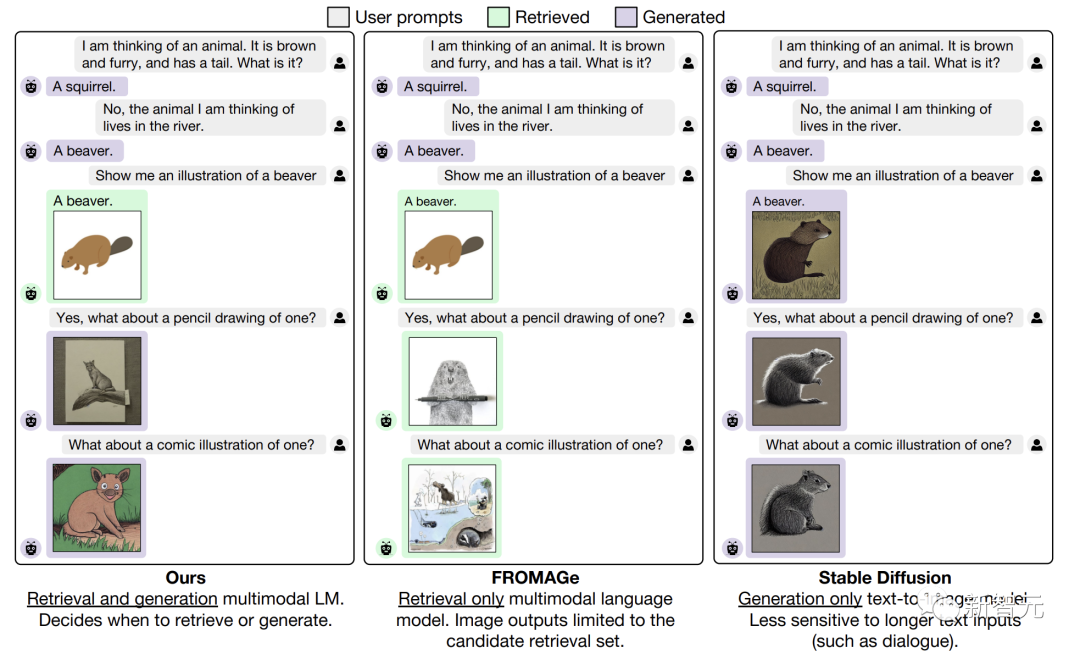
甚至,GILL还能从预先指定的数据集中进行图像检索,并在推理时决定是检索还是生成。
值得一提的是,通过嵌入空间之间的映射,CMU团队将冻结的大模型,与预训练的文生图模型相结合。
这样一来,GILL就能够实现广泛的应用,并且在多个文本到图像任务中优于基于Stable Diffusion等生成模型。
先来看一波演示。
演示
GILL能够将LLM预训练和冻结能力推广到许多不同任务中。具体包括:
https://huggingface.co/spaces/jykoh/gill
多模态对话生成
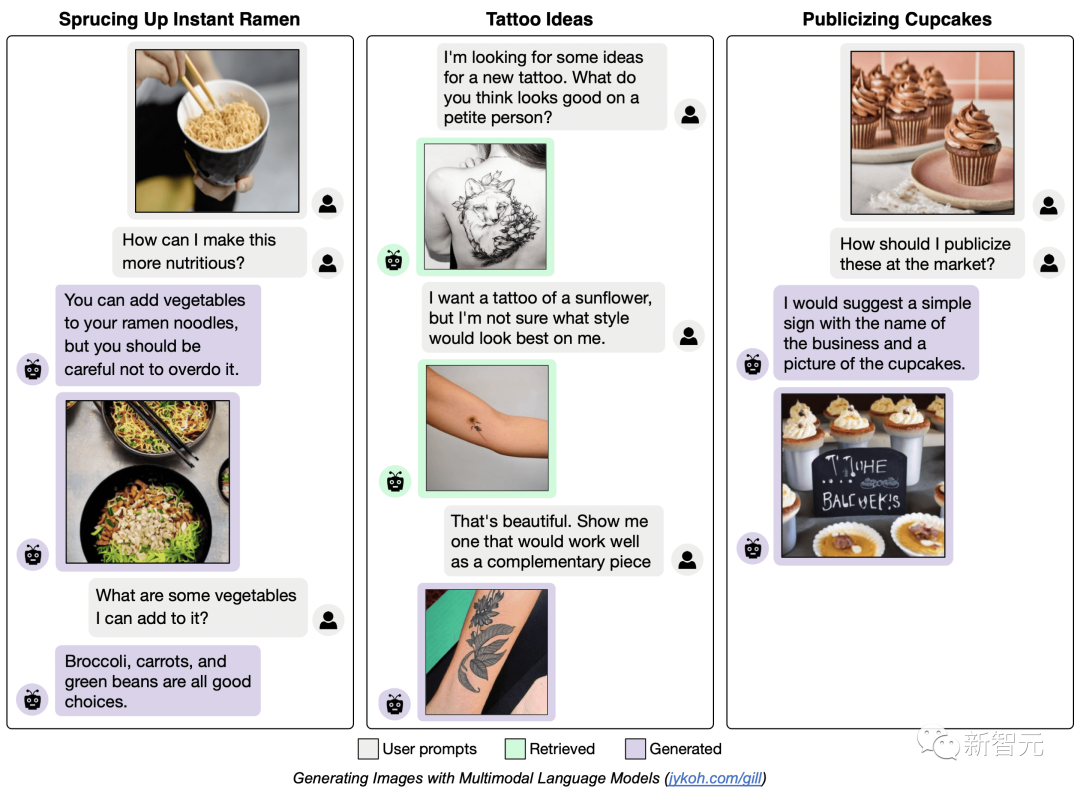
你可以提示GILL生成类似对话的文本,可以做到图像检索、图像生成,甚至多模态对话。
比如,你可以问它如何做拉面更有营养?GILL给出了加入蔬菜的建议。
我想要一款纹身。GILL瞬间就给你生成了符合要求的图案。
如何在市场上宣传这些蛋糕?GILL建议用一个简单的标牌,上面附上企业名称和小蛋糕的图片。
从视觉故事生成图像
另外,GILL还可以根据交错的图像和文本输入来生成更相关的图像。

多模态大模型GILL
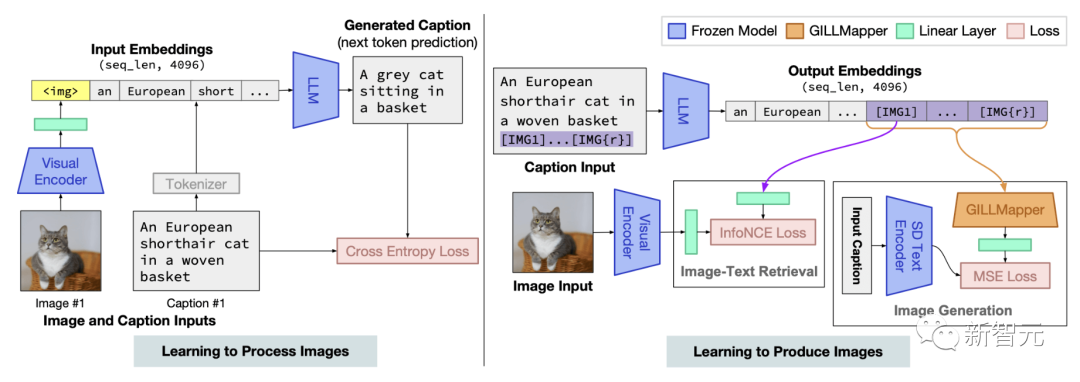
GILL的全称是:Generating Images with Large Language Models,即用大型语言模型生成图像。
它能够处理任意交错的图像和文本输入,以生成文本、检索图像,和生成新图像。
GILL模型架构概览。通过描述损失进行训练,以学习处理图像(左),并通过图像检索和图像生成损失进行训练,以学习生成图像(右)
研究表明,尽管2种模型使用完全不同的文本编码器,但可以有效地将冻结的纯文本LLM的输出嵌入空间,映射到冻结文本-图像生成模型,即Stable Diffusion的嵌入空间。
与其他需要交错图像-文本训练数据的方法相比,研究人员通过微调图像-描述对上的少量参数来实现这一点。
这个方法计算高效,并且不需要在训练时运行图像生成模型。
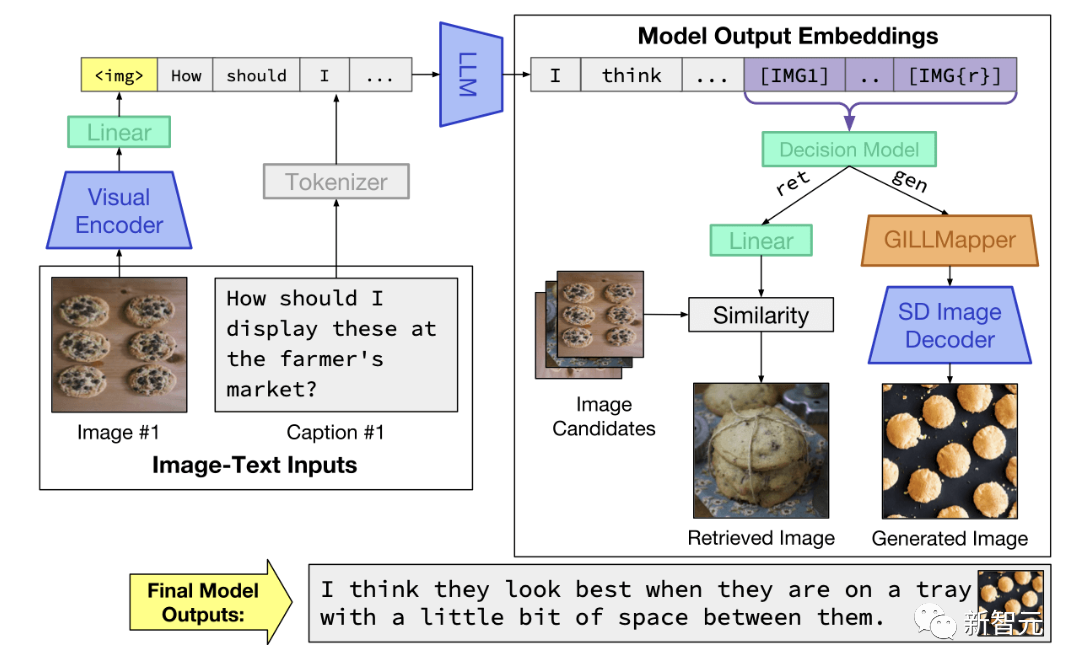
GILL的推理时间过程。该模型接受图像和文本输入,并生成与图像嵌入交错的文本。在决定是否检索或生成特定的token集后,并返回适当的图像输出
在推理过程中,模型接受任意交错的图像和文本输入,并产生与图像嵌入交错的文本。在决定是检索还是生成一组特定的标记后,它返回适当的图像输出(检索或生成)
在推理过程中,该模型接收任意交错的图像和文本输入,并生成交错图像嵌入的文本。在决定是检索还是生成一组特定的标记后,它会返回相应的图像输出(检索或生成)。
实验结果
上下文图像生成
为了测试模型在全新图像生成的基线方法的能力,研究人员在VIST和VisDial数据集上进行了实验。
这些数据集与之前的研究中使用的数据集相同,用于对多模态文本和图像上下文条件下的图像检索进行基准测试。
GILL模型组合了多模态信息以产生相关的图像和文本输出,性能优于仅限于图像检索的基线模型。

评估指标
评估的重点是生成模型处理复杂语言描述的能力。因此,研究人员计算了衡量生成图像内容相关性的指标。
这里,有2个指标来评估模型:
1. CLIP相似度:使用CLIP ViT-L图像编码器来生成生成图像和相应真实图像的合并表示,并得出它们的余弦相似度。分数越高表示生成的图像与真实图像越相似。
2.学习感知图像块相似度(LPIPS):LPIPS评估图像块之间的距离。测量真实图像和生成图像之间的LPIPS。较低的值表示2个图像在感知空间中更接近,而较高的值表示2个图像更不相似。
从视觉故事生成
VIST是一个用于顺序视觉和语言任务的数据集,其中包含构成故事的5个图像和文本序列的示例。
评估结果显示,将GILL与文本到图像生成基线进行比较。
当2个模型都输入一个故事描述时,性能相当,SD获得了比较好的CLIP相似度得分,并且两个模型获得了相似的 LPIPS。
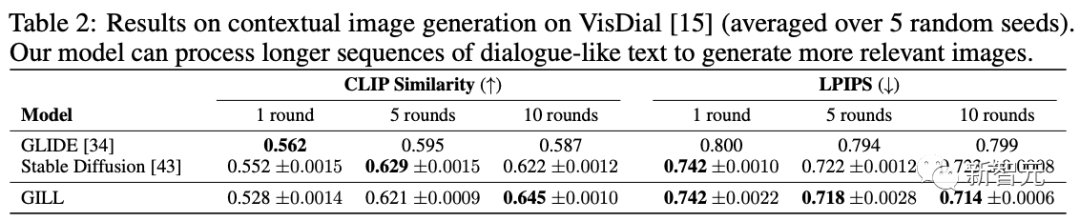
然而,当所有5个故事描述都作为输入提供时,GILL优于SD,将CLIP相似度从0.598提高到0.612,将LPIPS从0.704 提高到0.6。
有趣的是,当进一步提供完整的多模态上下文时,GILL得到了显着改进,获得了0.641的CLIP相似度和0.3的LPIPS。

从视觉对话生成
研究人员还在VisDial数据集上测试了模型。
与VIST类似,评估模型准确合成所描述图像的能力,并提供越来越多的问答对话上下文作为输入。
评估结果显示,输入长度较短时,SD优于GILL。
然而,当输入上下文增加时,GILL逐渐改进,并且可以合成与真实图像更相似的图像。
当提供完整的10轮对话时,GILL的性能显着优于SD,比CLIP相似度(0.622-0.645)和LPIPS(0.723-0.714)都有所提高。
这些结果,进一步凸显了GILL在处理类似对话的长文本输入方面的有效性。
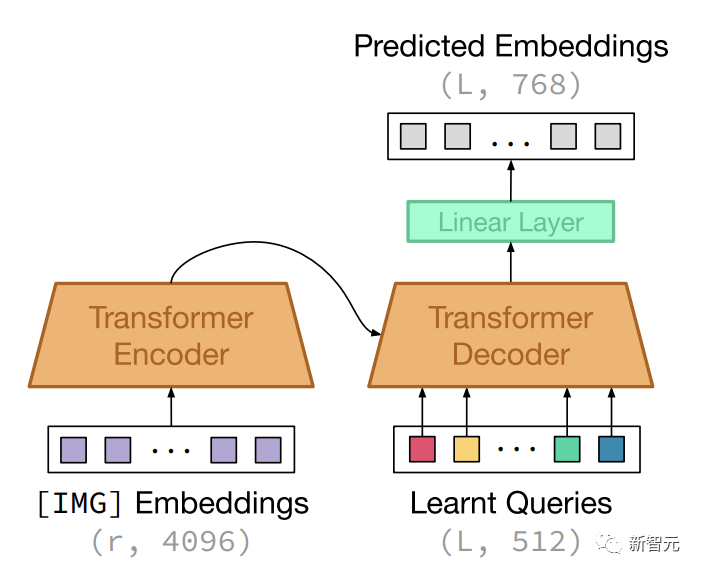
研究人员还引入了GILLMapper模块,允许模型有效地映射到Stable Diffusion图像生成骨干网,在PartiPrompts的许多示例中优于或匹配SD。

GILLMapper模型架构以隐藏的 [IMG] 表示和学习的查询嵌入向量序列为条件。
局限性
虽然GILL引入了许多令人兴奋的功能,但它是一个早期的研究原型,有几个局限性。
- GILL的许多功能依赖于LLM主架构。因此,它也继承了LLM典型的许多问题:
- GILL并不总是在提示时产生图像,或者当它对对话有用时。
- GILL的局限性在于它有限的视觉处理。目前,研究只使用4个视觉向量来表示每个输入图像(由于计算限制),这可能无法捕获下游任务所需的所有相关视觉信息。
- GILL继承了LLM的一些意外行为,例如潜在的幻觉,它生成的内容是错误的,或者与输入数据无关。它有时还会生成重复的文本,并且并不总是生成连贯的对话文本。
作者介绍
Jing Yu Koh
Jing Yu Koh是CMU机器学习系的二年级博士生,导师是Daniel Fried和Ruslan Salakhutdinov。
目前,他主要的研究方向是基础语言理解。
丹尼尔·弗里德和鲁斯兰·萨拉库蒂诺夫为我提供建议。我致力于基础语言理解,通常是在视觉和语言问题的背景下。
在此之前,他是谷歌研究中心的一名研究工程师,在那里研究视觉和语言问题以及生成模型。

参考资料:
https://www.cxs.cmu.edu/news/2023/gill
https://jykoh.com/gill
关注公众号【机器学习与AI生成创作】,更多精彩等你来读
卧剿,6万字!30个方向130篇!CVPR 2023 最全 AIGC 论文!一口气读完
深入浅出stable diffusion:AI作画技术背后的潜在扩散模型论文解读
深入浅出ControlNet,一种可控生成的AIGC绘画生成算法!
 戳我,查看GAN的系列专辑~!
戳我,查看GAN的系列专辑~!一杯奶茶,成为AIGC+CV视觉的前沿弄潮儿!
最新最全100篇汇总!生成扩散模型Diffusion Models
ECCV2022 | 生成对抗网络GAN部分论文汇总
CVPR 2022 | 25+方向、最新50篇GAN论文
ICCV 2021 | 35个主题GAN论文汇总
超110篇!CVPR 2021最全GAN论文梳理
超100篇!CVPR 2020最全GAN论文梳理
附下载 |《TensorFlow 2.0 深度学习算法实战》
《礼记·学记》有云:独学而无友,则孤陋而寡闻
点击一杯奶茶,成为AIGC+CV视觉的前沿弄潮儿!,加入 AI生成创作与计算机视觉 知识星球!
评论