
机器学习深度研究:特征选择中几个重要的统计学概念
↑↑↑点击上方蓝字,回复资料,10个G的惊喜

问题引出
当我们拿到数据并对其进行了数据预处理,但还不能直接拿去训练模型,还需要选择有意义的特征(即特征选择),这样做有四个好处:
1、避免维度灾难
2、降低学习难度
3、减少过拟合
4、增强对特征和特征值之间的理解
常见的特征选择有三种方法:
过滤法(Filter):先对数据集进行特征选择,然后再训练学习器,特征选择过程与后续学习器无关。
包装法(Wrapper):根据目标函数(通常是预测效果评分),每次选择若干特征,或者排除若干特征。
嵌入法(Embedding):先使用机器学习模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征。
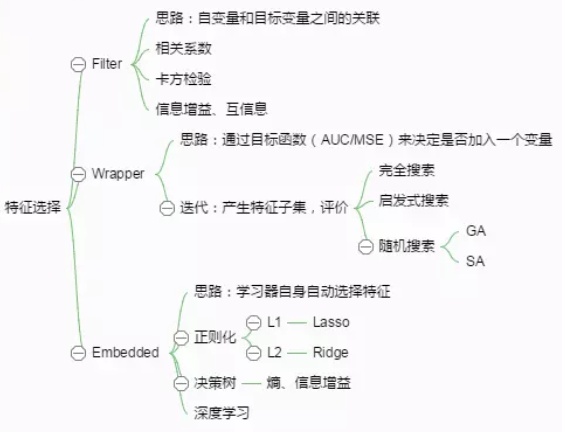
其中,过滤法是最简单,最易于运行和最易于理解的。
过滤法核心思路就是考察自变量和目标变量之间的关联性、相关性,设定阈值,优先选择与目标相关性高的特征。
主要方法:
1、分类问题:卡方检验(chi2),F检验(f_classif), 互信息(mutual_info_classif)
2、回归问题:相关系数(f_regression), 信息系数(mutual_info_regression)
卡方检验、F检验、互信息、相关系数、信息系数
这些都是统计学领域的概念,在sklearn特征选择中被使用,所以在解释这些概念时,我也重点参考了sklearn文档。
卡方检验百科定义:
卡方检验就是统计样本的实际观测值与理论推断值之间的偏离程度,实际观测值与理论推断值之间的偏离程度就决定卡方值的大小,如果卡方值越大,二者偏差程度越大;反之,二者偏差越小;若两个值完全相等时,卡方值就为0,表明理论值完全符合。
卡方值 计算公式
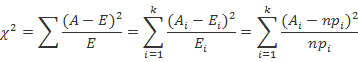
不要望公式兴叹,其实只需掌握到第一个等号后就行了:A为实际值,T为理论值。
F检验
F检验和方差分析(ANOVA)是一回事,主要用于两个及两个以上样本均数差别的显著性检验。方差分析的基本原理是认为不同处理组的均数间的差别基本来源有两个:(1) 实验条件,即不同的处理造成的差异,称为组间差异。用变量在各组的均值与总均值之偏差平方和的总和表示,记作,组间自由度。
(2) 随机误差,如测量误差造成的差异或个体间的差异,称为组内差异,用变量在各组的均值与该组内变量值之偏差平方和的总和表示, 记作,组内自由度。

利用f值可以判断假设H0是否成立:值越大,大到一定程度时,就有理由拒绝零假设,认为不同总体下的均值存在显著差异。所以我们可以根据样本的某个特征的f值来判断特征对预测类别的帮助,值越大,预测能力也就越强,相关性就越大,从而基于此可以进行特征选择。
互信息(mutual_info_classif/regression)
互信息是变量间相互依赖性的量度。不同于相关系数,互信息并不局限于实值随机变量,它更加一般且决定着联合分布 p(X,Y) 和分解的边缘分布的乘积 p(X)p(Y) 的相似程度。
两个离散随机变量 X 和 Y 的互信息可以定义为:
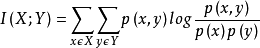
相关系数(f_regression)
相关系数是一种最简单的,能帮助理解特征和响应变量之间关系的方法,该方法衡量的是变量之间的线性相关性,结果的取值区间为[-1,1],-1表示完全的负相关,+1表示完全的正相关,0表示没有线性相关。
式中是代表所有样本的在i号特征上的取值的维列向量,分子上其实两个维列向量的内积,所以是一个数值,其实就是样本相关系数。
值越大,第i个特征和因变量y之间的相关性就越大,据此我们做特征选择。
P值 (P-value)
P值,也就是常见到的 P-value。P 值是一种概率,指的是在 H0 假设为真的前提下,样本结果出现的概率。如果 P-value 很小,则说明在原假设为真的前提下,样本结果出现的概率很小,甚至很极端,这就反过来说明了原假设很大概率是错误的。通常,会设置一个显著性水平(significance level) 与 P-value 进行比较,如果 P-value < ,则说明在显著性水平 下拒绝原假设, 通常情况下设置为0.05。
sklearn特征选择——过滤法
sklearn过滤法特征选择方法
SelectBest 只保留 k 个最高分的特征;SelectPercentile 只保留用户指定百分比的最高得分的特征;使用常见的单变量统计检验:假正率SelectFpr,错误发现率selectFdr,或者总体错误率SelectFwe;GenericUnivariateSelect 通过结构化策略进行特征选择,通过超参数搜索估计器进行特征选择。
SelectKBest按照scores保留K个特征;
SelectPercentile按照scores保留指定百分比的特征;
SelectFpr、SelectFdr和SelectFwe对每个特征使用通用的单变量统计检验;
GenericUnivariateSelect允许使用可配置策略如超参数搜索估计器选择最佳的单变量选择策略。特征选择指标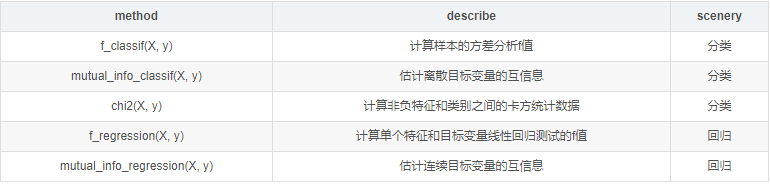 使用sklearn中SelectKBest函数进行特征选择,参数中的score_func选择:分类:chi2----卡方检验
使用sklearn中SelectKBest函数进行特征选择,参数中的score_func选择:分类:chi2----卡方检验
f_classif----方差分析,计算方差分析(ANOVA)的F值 (组间均方 / 组内均方)
mutual_info_classif----互信息,互信息方法可以捕捉任何一种统计依赖,但是作为非参数方法,需要更多的样本进行准确的估计
回归:f_regression----相关系数,计算每个变量与目标变量的相关系数,然后计算出F值和P值
mutual_info_regression----互信息,互信息度量 X 和 Y 共享的信息:它度量知道这两个变量其中一个,对另一个不确定度减少的程度。
sklearn过滤法特征选择-示例
在sklearn中,可以使用chi2这个类来做卡方检验得到所有特征的卡方值与显著性水平P临界值,我们可以给定卡方值阈值, 选择卡方值较大的部分特征。代码如下:
首先import包和实验数据:
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
from sklearn.datasets import load_iris
#导入IRIS数据集
iris = load_iris()
使用卡方检验来选择特征
model1 = SelectKBest(chi2, k=2)#选择k个最佳特征
model1.fit_transform(iris.data, iris.target)#iris.data是特征数据,iris.target是标签数据,该函数可以选择出k个特征
结果输出为:
array([[ 1.4, 0.2],
[ 1.4, 0.2],
[ 1.3, 0.2],
[ 1.5, 0.2],
[ 1.4, 0.2],
[ 1.7, 0.4],
[ 1.4, 0.3],
可以看出后使用卡方检验,选择出了后两个特征。如果我们还想查看卡方检验的p值和得分,可以使用第3步。
查看p-values和scores
model1.scores_ #得分
得分输出为:
array([ 10.81782088, 3.59449902, 116.16984746, 67.24482759])
可以看出后两个特征得分最高,与我们第二步的结果一致;
model1.pvalues_ #p-values
p值输出为:
array([ 4.47651499e-03, 1.65754167e-01, 5.94344354e-26, 2.50017968e-15])
可以看出后两个特征的p值最小,置信度也最高,与前面的结果一致。
