
CNN终于杀回来了!京东AI开源最强ResNet变体CoTNet:即插即用的视觉识别模块

极市导读
本文创造性的将Transformer中的自注意力机制的动态上下文信息聚合与卷积的静态上下文信息聚合进行了集成,提出了一种新颖的Transformer风格的“即插即用”CoT模块,它可以直接替换现有ResNet架构Bottleneck中的3✖️3卷积并取得显著的性能提升。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

paper: https://arxiv.org/abs/2107.12292
code: https://github.com/JDAI-CV/CoTNet
本文是京东AI研究院梅涛团队在自注意力机制方面的探索,不同于现有注意力机制仅采用局部或者全局方式进行上下文信息获取,他们创造性的将Transformer中的自注意力机制的动态上下文信息聚合与卷积的静态上下文信息聚合进行了集成,提出了一种新颖的Transformer风格的“即插即用”CoT模块,它可以直接替换现有ResNet架构Bottleneck中的卷积并取得显著的性能提升。无论是ImageNet分类,还是COCO检测与分割,所提CoTNet架构均取得了显著性能提升且参数量与FLOPs保持同水平。比如,相比EfficientNet-B6的84.3%,所提SE-CoTNetD-152取得了84.6%同时具有快2.75倍的推理速度。
Abstract
Transformer极大的促进了NLP领域的发展,Transformer风格的网络架构近期在CV领域也掀起了一波浪潮并取得了极具竞争力的结果。尽管如此,现有的架构直接在2D特征图上执行自注意力并得到注意力矩阵,但是关于近邻丰富的上下文信息却并未得到充分探索。
本文设计了一种新颖的Transformer风格模块CoT(Contextual Transformer, CoT)用于视觉识别,该设计充分利用输入的上下文信息并引导动态注意力矩阵的学习,进而提升了视觉表达能力。技术上来讲,CoT模块首先通过卷积对输入keys进行上下文信息编码得到关于输入的静态上下文表达;进一步将编码keys与输入query进行拼接并通过两个连续卷积学习动态多头注意力矩阵;所得注意力矩阵与输入values相乘即可得到关于输入的动态上下文表达。静态上下文表达与动态上下文表达的融合结果作为该模块的输出。所提CoT模块可以作为“即插即用”模块替换ResNet中的卷积并得到Transformer风格的架构,故而称之为CoTNet(Contextual Transformer Network)。
多个领域(包含图像分类、目标检测、实例分割)的充分实验结果表明:CoTNet是一种更强的骨干网络。比如,在ImageNet分类任务中,相比ResNeSt101,CoTNet取得了0.9%的性能提升;在COCO目标检测与实例分割任务中,相比ResNeSt,CoT分别取得了1.5%与0.7%mAP指标提升。
Method
我们首先对现有骨干网络中采用的传统自注意力模块进行简单介绍;然后引入了本文所设计的Transformer风格的模块;最后再引入基于所提CoT模块构建的CoTNet、CoTNeXt等等架构。
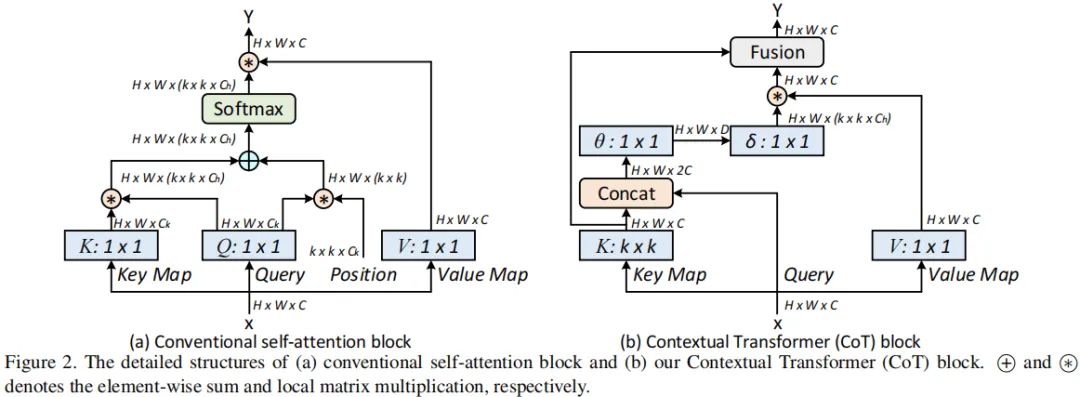
Multi-head Self-attention in Vision Backbones
上面Figure-a给出了现有骨干中的多头自注意力模块架构图。具体来说,给定2D输入特征X(尺寸为),我们通过如下公式将其变换为queries、keys以及values:
注:这里采用的是卷积。然后我们在K与Q之间计算局部相关矩阵R:
局部相关矩阵R进一步通过位置信息进行丰富化:
接下来,通过对上述局部相关矩阵进行归一化即得到注意力矩阵A :
最后,通过values与注意力矩阵A相乘即得到增强后特征Y:
Contextual Transformer Block
传统的自注意力仅在空域进行信息交互,依赖于输入自身,即相关性通过独立的方式学习所得,而忽视了近邻间丰富的上下文信息。这无疑会严重限制2D特征图的自注意力学习能力。为缓解该问题,我们构建了一种新的Transformer风格的模块CoT(见上面的Figure2-b),它将上下文信息挖掘与自注意力学习集成到统一架构中。本文的出发点:充分探索近邻间的上下文信息以一种高效方式提升自注意力学习,进而提升输出特征的表达能力。
具体来说,假设输入2D特征,keys, queries以及values分别定义为。不同于传统自注意力采用卷积编码keys,CoT模块首先采用组卷积提取上下文信息,所得自然的可以反应近邻间的上下文信息,我们将其视作输入X的静态上下文表达。
然后,将前述所得keys与Q进行拼接并通过两个连续卷积计算注意力矩阵:
换句话说,每个位置局部相关矩阵基于query与keys学习所得,而非独立的query-key对。这种处理方式可以通过额外的静态上下文提升自注意力学习能力。接下来,基于上述所得注意力矩阵A,我们生成增强特征:
上述所得增强特征可以捕获关于输入的动态特征交互,我们将其称之为输入X的动态上下文表达。最后,我们将上述两种上下文表达通过注意力机制融合(比如SKNet中的注意力融合机制)即可得到CoT模块的输出。
Contextual Transformer Networks
所提CoT的设计是一种统一的注意力模块,它可以作为ConvNet中标准卷积的替代。因此,我们可以将其替换现有ConvNet中的卷积进而提升其表达能力。
接下来,我们简要介绍一下如何将CoT模块嵌入到现有ResNet架构中且不会显著提升参数量。下表给出了将CoT模块嵌入到ResNet与ResNeXt中的信息示意,并将所得模型称之为CoTNet-50、CoTNeXt-50。当然,还可以将CoT模块嵌入到ResNet101中,更详细的嵌入方式可参考官方code。
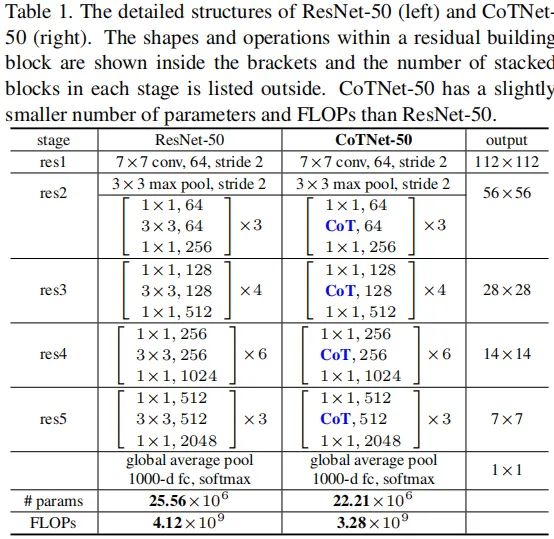
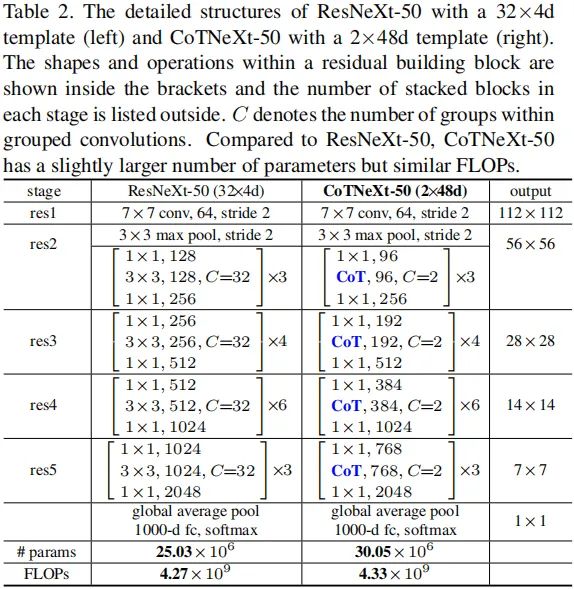
具体来说,CoTNet-50直接采用CoT替换Bottlenck中的卷积;类似的,CoTNeXt-50采用CoT模块替换对应的组卷积,为获得相似计算量,对通道数、分组数进行了调整:CoTNeXt-50的参数量是ResNeXt-50的1.2倍,FLOPs则是1.01倍。
Experiments
接下来,我们通过不同领域(包含ImageNet分类、COC目标检测以及实例分割)的实验评估所提CoTNet的性能。
ImageNet Classification
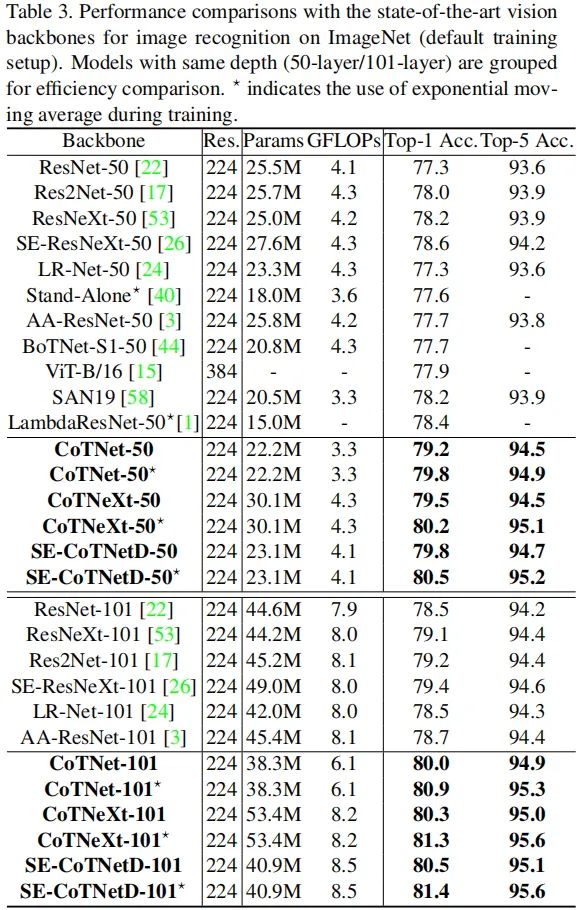
上表给出了ImageNet默认配置训练的性能对比,可以看到:
相比已有ResNet改进,在同等参数量与FLOPs约束下,所提CoTNet取得了最佳性能; 采用局部自注意力的LRNet-50与Stand-Alone取得了比ResNet50更佳的性能; 采用了全局自注意力的AA-ResNet-50与LambdaResNet-50取得了进一步的性能提升,但仍低于SE-ResNet; 同时利用局部与全局上下文信息的CoTNet取得了优于SE-ResNet的性能,这说明:上下文信息挖掘与自注意力学习的集成是一种有效的增强表达能力的方式。
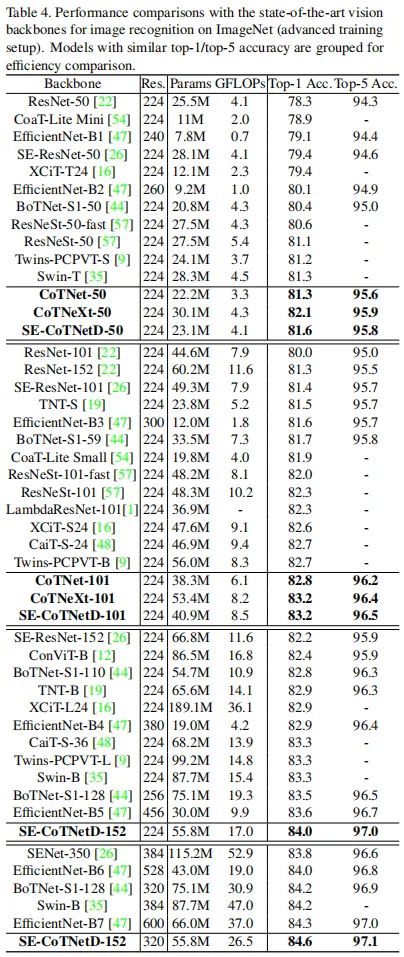
上表给出了更先进训练配置下的性能对比,从中可以看到:
所提CoTNet、CoTNeXt均具有比其他ResNet改进版更优的性能; 相比ResNeSt-50,ResNeSt-101,所提CoTNeXt-50与CoTNeXt-101分别取得了1.0%与0.9%的性能提升; 相比BoTNet,所提CoTNet同样具有更优的性能;甚至于,SE-CoTNetD-152(320)取得了比BoTNet-S1-128(320)、EfficientNet-B7更优的性能.
Object Detection
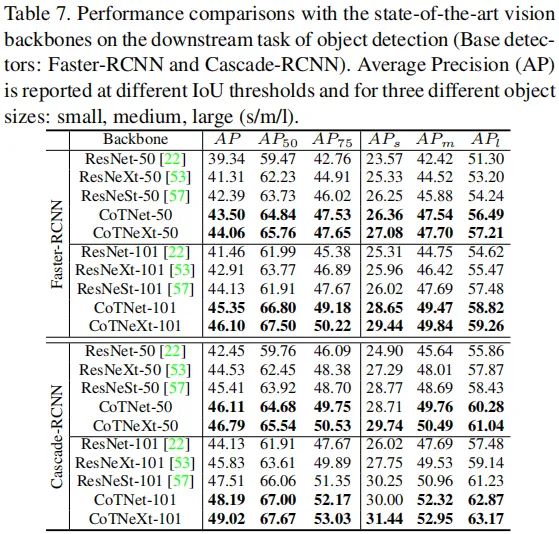
上表给出了COCO目标检测任务上的性能对比,从中可以看到:相比ResNet、ResNeSt等骨干,所提CoTNet取得了显著的性能提升。这说明:上下文信息挖掘与自注意力学习的集成是一种有效的特征增强方法,甚至可以很好的迁移到下游任务中。
Instance Segmentation
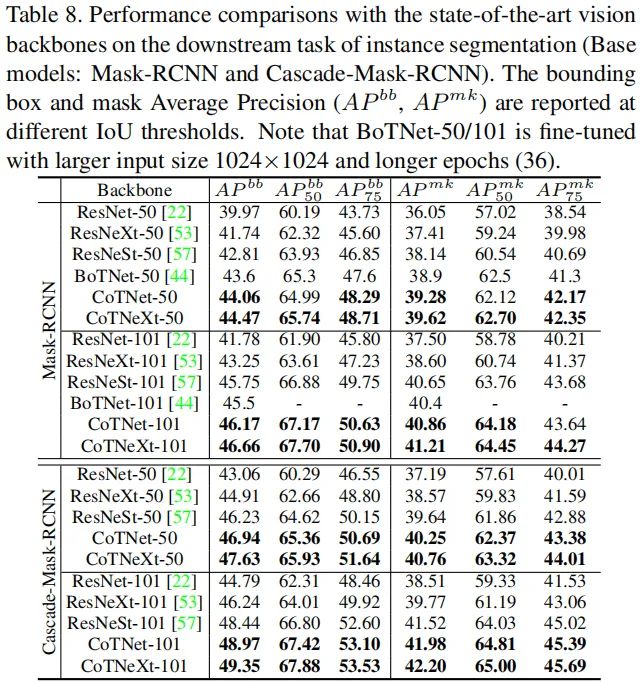
上表给出了COCO实例分割任务上的性能对比,从中可以看到:相比ResNet、ResNeSt等骨干,所提CoTNet取得了显著的性能提升。
Ablation Study
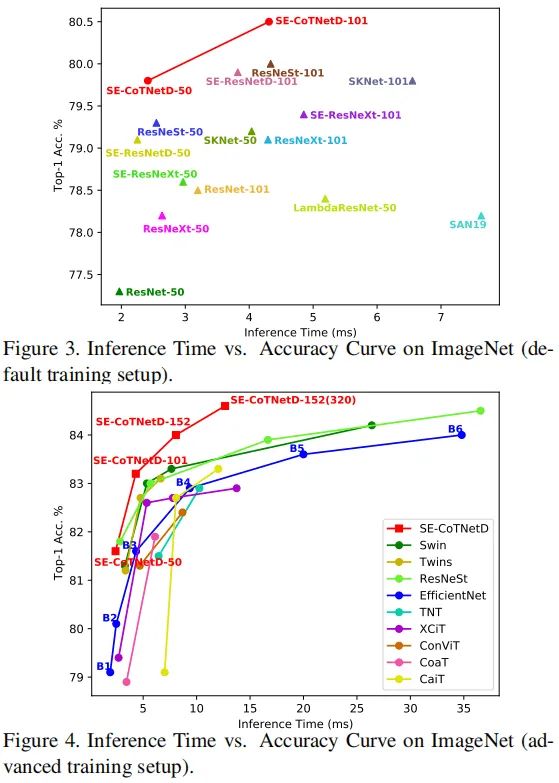
上面两个图给出了精度-推理耗时的对比,从中可以看到:相比其他骨干网络,CoTNet取得了最佳的top1精度,同时具有更少的推理耗时。也就是说,CoTNet具有更好的精度-速度均衡。比如,相比EfficientNet-B6,所提SE-CoTNetD-152(320)不仅精度高0.6%,推理速度还快2.75倍。
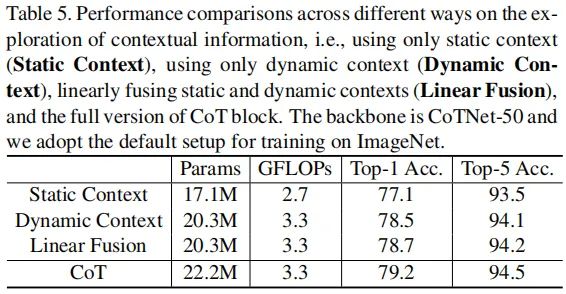
上表对比了不同上下文信息获取的性能对比,从中可以看到:
静态上下文方式(可视作无自注意力的ConvNet)仅取得77.1%的top1精度; 动态上下文方式可以取得78.5%的top1精度; 动静上下文简单的相加融合可以取得78.7%的top1精度; 通过注意力融合的方式集成动静上下文可以进一步将其性能提升到79.2%。
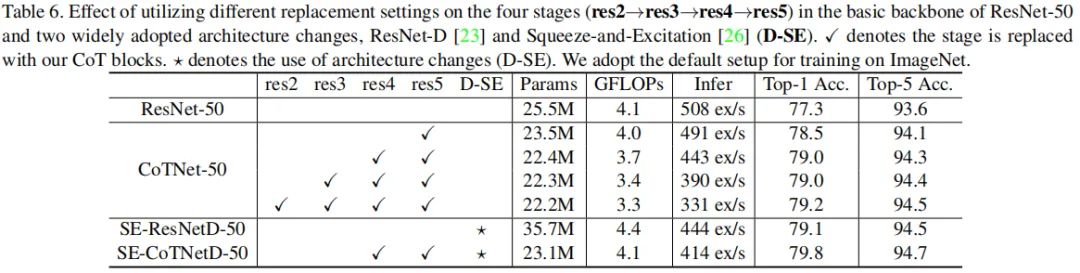
上表对比了不同阶段替换CoT以及SE注意力等改进的性能影响,从中可以看到:
提升替换CoT模块的数量可以有效提升模型的性能,而参数量与FLOPs不会显著变化;
相比SE-ResNetD-50,所提SE-CoTNetD-50取得了更佳的性能。
本文亮点总结
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“ICCV2021”获取最新论文合集~

# 极市平台签约作者#

happy
知乎:AIWalker
AIWalker运营、CV领域八年深耕码农
研究领域:专注low-level领域,同时对CNN、Transformer、MLP等前沿网络架构保持学习心态,对detection的落地应用甚感兴趣。
公众号:AIWalker
作品精选
