
线程池的内部构造过程分析:找找核心成员变量有哪些
我们在上一节中对为什么要用线程池,线程池的常见种类以及如何通过Executors框架创建线程池的几种方式都做了一步一图,大白话式的讲解。并且在上文的结束部分,我们还通过一张图对线程池的核心架构原理进行了展示,想必你还有印象。
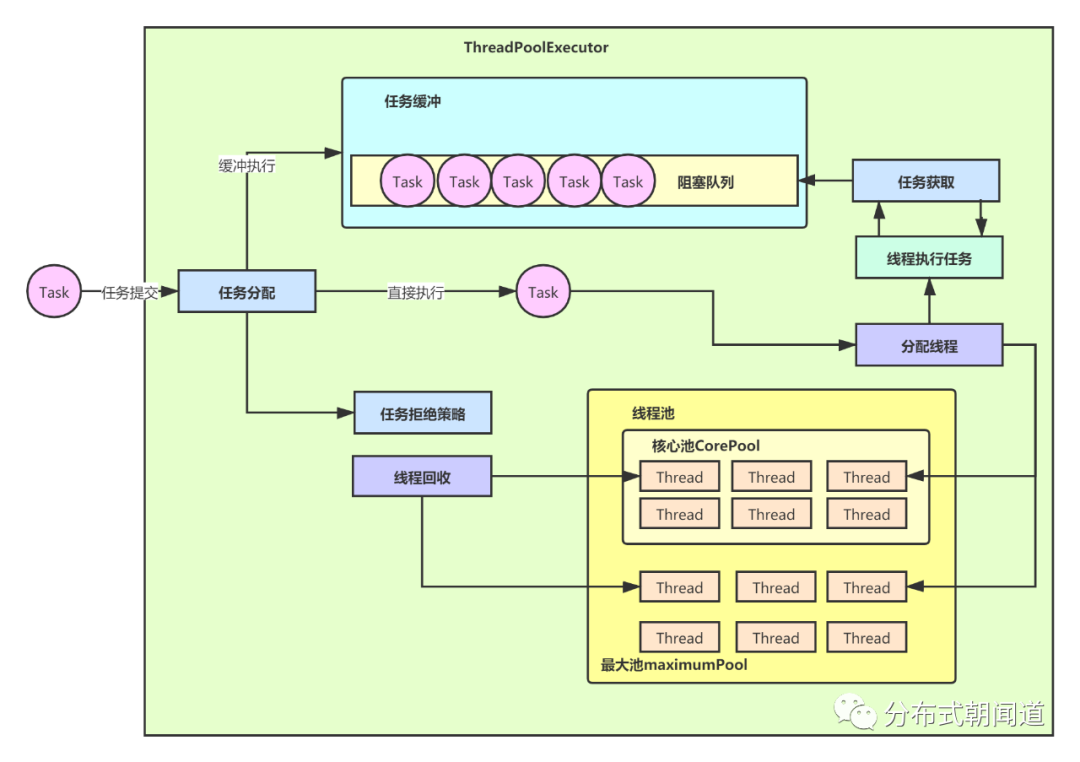
图1
事实上,图1是对线程池原理的一个详细的表达,它体现了线程池的几个核心概念,具体是哪些概念呢,且听我慢慢分析。
也许你还记得我们对Executors创建线程池的代码分析,如果记不清了就返回上文再去理解一下。这里直接说结论,通过方法签名,我们会发现:那几种创建线程池的方式其实都是基于ThreadPoolExecutor类的包装,就以newFixedThreadPool(intnThreads)方法为例,它的签名如图2所示。

图2
好家伙,敢情就是包装了一下ThreadPoolExecutor,提供了定制化的能力啊。
既然是对ThreadPoolExecutor的直接调用,那么我们就趁热打铁,直接看一下ThreadPoolExecutor的构造方法签名,如图3所示。
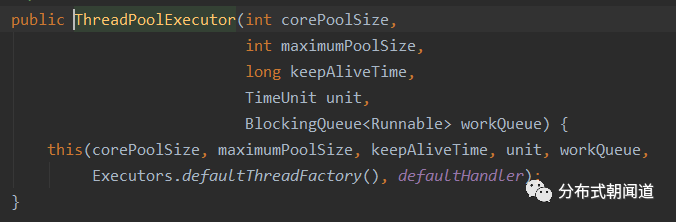
图3
因为注释实在是有点太长了,就只截取代码部分。我们发现,这个构造方法其实是重载了另外一个构造方法,本着追根溯源,挖掘本质的宗旨,我们接着看他调用的这个重载构造方法,如图4所示。
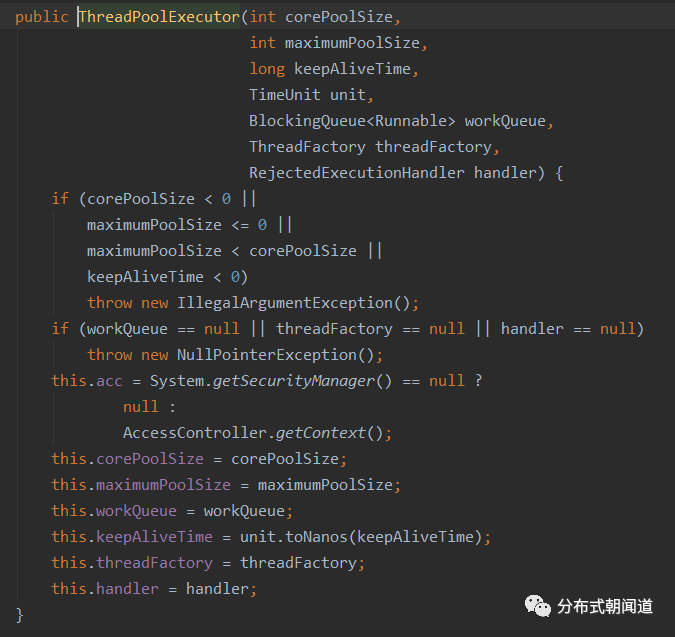
图4
OK,到此就真相大白了,这个构造方法就是最后真正实例化线程池的地方。
ThreadPoolExecutor核心参数分析
通过上面截图中的构造方法,我们发现,主要有7个入参,这7个参数就是线程池构造以及任务执行过程中的核心了。
假如说你去大厂面试,别人问你:兄弟,你用过线程池吗?你自信的回答,当然用过。对面继续问你,那既然你用过,不妨说说线程池构造的核心参数吧。你一脸懵,啥,啥7个参数啊,我记不清了诶。然后只听面试官说,那,回去等通知吧。这就表示,基本上这次面试就此画上了终点。
作为一位有追求的技术人员,我们当然不想出现这种尴尬的场景。因此可以这么说,是否了解线程池ThreadPoolExecutor的核心参数及其意义,是一个后端Java栈开发者是否用过ThreadPoolExecutor的重要依据,这也是面试场景中经常出现的高频问题。为什么这么说呢?你想啊,如果你用一个API实现一个功能,结果你在不知道这个API的参数含义的前提下竟然实现了功能,我只能说,兄弟,你是个人才。
废话不多说,既然核心参数这么重要,我们就来看看他们的含义以及意义何在。
我们还是以图1作为理解的辅助依据结合构造方法的参数进行理解。
首先是corePoolSize,即核心线程的个数。注意看图中右下角浅黄色的“核心池CorePool”,它里面放的就是核心线程。核心线程其实就是预先分配的线程,当线程池创建,就实现分配指定数量的核心线程,一旦有任务提交过来,核心线程立即就能接管开始执行,就好比你去食堂打饭,去了不用排队直接点菜取参,不用等待。它的意义在于解决了创建线程的开销,做到了“任务来则线程可用,无需等待,即来即走”。如下图中的核心池Pool中的线程池的数量,代表的含义就是这里的corePoolSize,如图5所示。
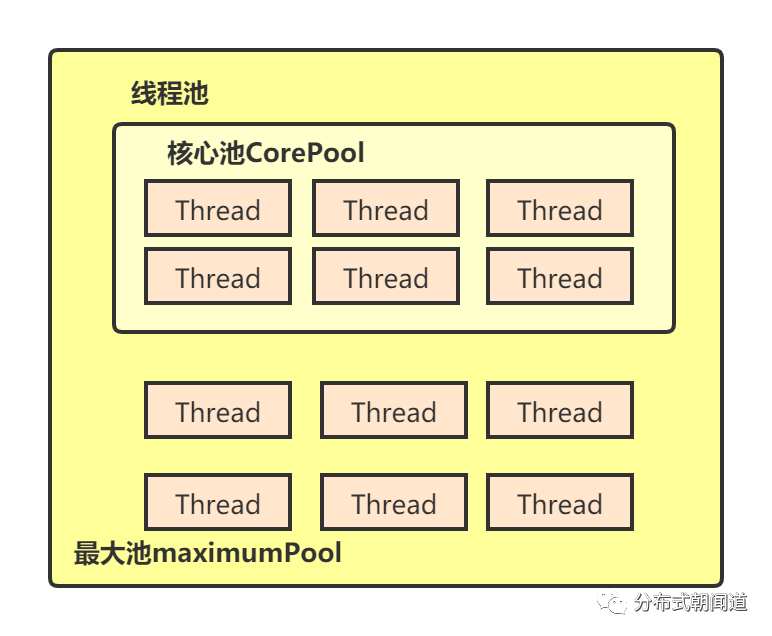
图5
然后是maximumPoolSize,即线程池最大的线程数量。也就是上图中的“最大池maximumPool”的容量,它的作用在于说,当核心线程数被任务占满,并且线程池中的任务缓冲队列也满了的时候,为了让新提交的任务仍旧可以在一定程度上执行,不至于立马就拒绝任务,因此设置了这个参数,保证线程池可以通过创建新工作线程的方式来接受并执行任务。
欸,不是已经有corePoolSize参数了么,为啥还要来一个maximumPoolSize呢?这其实就是线程池设计的精妙之处了。
你想啊,如果没有设置maximumPoolSize,而是只设置了一个corePoolSize,当然没什么大问题,但是如果说本身系统平时的任务不多,每秒执行10个以内的任务,这属于典型的低并发场景吧。然后PPT架构师考虑了一下说,“如果每个月初月末流量突增,会达到每秒100以上的并发。让我们把corePoolSize设置成原先的10倍吧!”。果然不愧是架构师,他的说法不能说完全是错的,但是仔细想想,这不合理啊。
你想啊,单纯为了应对短暂的高峰流量,就把常规状态下的线程翻了10倍,实际上大部分情况下就没有那么多的任务可以执行,一下子创建了大量的工作线程并保持常态,这是典型的资源浪费啊。
于是就有了maximumPoolSize,它本质上其实是一种“伸缩思想”在线程池中的体现,原理如图6所示。

图6
从图7中我们可以看到,正是因为maximumPoolSize参数,让线程池具备了可以根据任务量灵活的调节自身的资源分配情况的能力。上图中最大可以创建16个线程,已经创建了8个(实线圆形),还剩8个可以创建(虚线圆形)。
再看keepAliveTime参数,顾名思义,就是存活时间。那具体是谁的存活时间呢?其实就是超过核心线程池(线程总数小于等于maximumPoolSize)并且处于空闲状态的那些线程的存活时间。这部分线程给他们分配了一个keepAliveTime参数,意义在于说,让它们别急着回收,先等会儿,看有没有任务来了,如果有就去执行任务,否则就等达到了keepAliveTime之后,对工作线程进行回收。如下图7所示。

图7
我们举个理想情况下的例子,假设corePoolSize是10,maximumPoolSize是20,此时线程池中共有15个线程,并且keepAliveTime设置为60s。结果最近60s内都没一个任务被提交到线程池,那超出来的5个线程(一年级的算数题,15-10=5)就会被回收。
和keepAliveTime有关联的参数是unit,它代表了keepAliveTime的时间单位(TimeUnit类型),可以是天、时、分、秒、毫秒、微妙、纳秒。一般而言,我们给线程池的keepAliveTime指定的时间单位是秒或者分,原因在于从经验判断,对于任务执行而言,毫秒、微秒、纳秒单位过小,小时又过大了。
接着看workQueue参数,它表示用于保存提交的待执行状态的任务的阻塞队列。队列种类有很多种,包括基于数据的有界队列ArrayBlockingQueue、基于链表的无界队列LinkedBlockingQueue、有且只有一个元素的同步队列SynchronousQueue以及优先级队列PriorityBlockingQueue等等。它本质上就是说通过一个队列,让等待执行的任务先进行排队,给线程池提供了一个缓冲的空间,能够让线程池在一定的程度内一直接受任务,而不是直接就拒绝任务的提交。提高了线程池的任务容纳能力,而且队列天然有解耦的作用,它把任务提交和执行进行了解耦,这是什么?我想你肯定猜到了,这就是生产者-消费者模型啊!原理如图8所示。
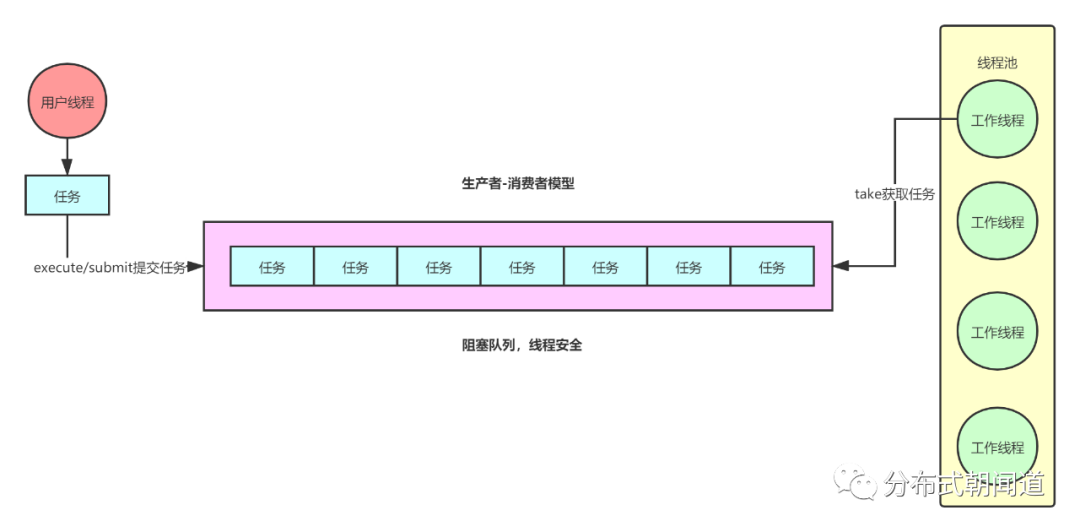
图8
我们接着看一下后续的参数。首先是ThreadFactory参数,即创建线程的工厂,它的作用是当需要增加工作线程时,不需要通过new Thread的方式创建,而是通过ThreadFactory接口的实现类的newThread方法来创建。接口声明如图9所示:
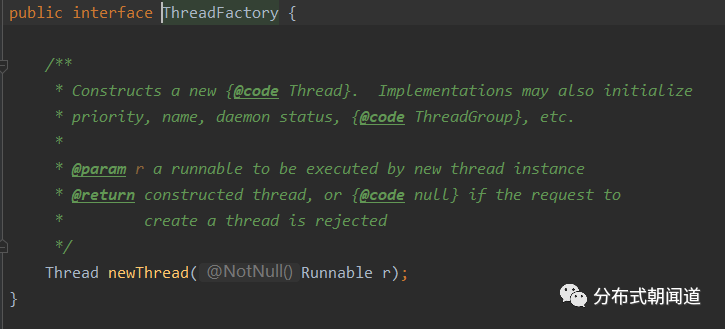
图9
最后看一下RejectedExecutionHandler这个参数,它也是一个接口,翻译过来就是拒绝策略。方法签名如图10所示:

图10
它的作用是当任务队列满了,并且工作线程数量也达到了最大线程数,如果这个时候继续往线程池提交任务,那么就会触发拒绝策略。如图11所示:
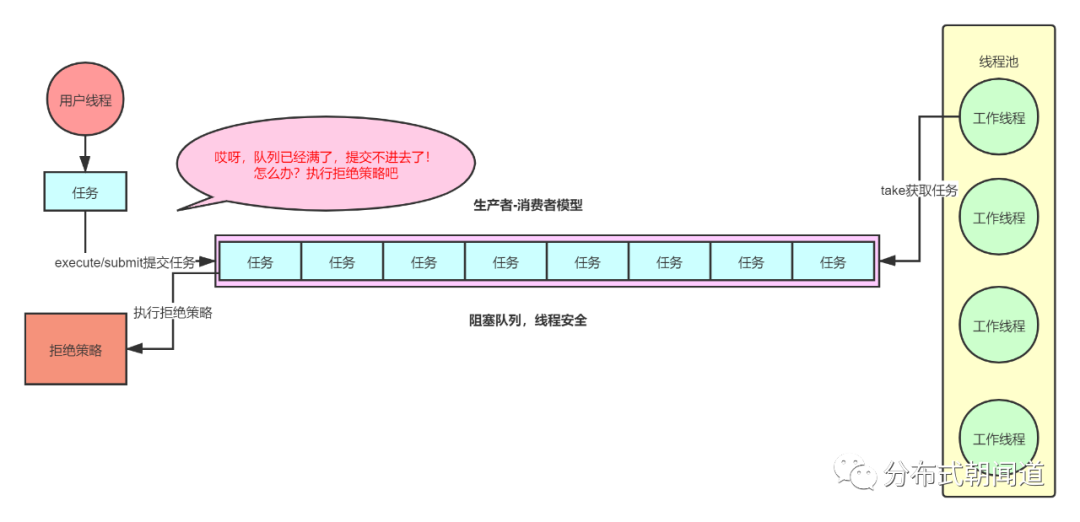
图11
图12中,队列已经满了,并且工作线程数也达到了maximumPoolSize,此时就只能执行拒绝策略了。由于RejectedExecutionHandler是一个接口,因此允许我们自定义具体的拒绝策略。但实际上,Java作为一款十分成熟的工业级开发语言,它肯定不会傻乎乎的就丢一个接口给开发者用,事实上JDK已经提供了四种默认的拒绝策略,我们可以根据实际需要去选择对应场景的拒绝策略。我们用一个脑图简单说明一下这四种拒绝策略的特点,如图12所示。

图12
到此为止呢,我们就对线程池的最完整的核心变量进行了细致的讲解,并配以画图进行解释,希望你能够反复研读,最后理解并记在心中。接下来我们将对线程池提交任务进行源码级别的讲解,而本文所讲解的这部分知识对后续深入源码解析线程池的核心原理有着至关重要的作用,因此希望你牢牢掌握。