
发现一个贼有意思的新项目!
大家好,我是鱼皮。最近看到一个非常有意思的项目亲戚计算器,感觉很不错,今天分享给大家。
注意:下文中的我指原项目作者
原文链接:https://juejin.cn/post/7203734711779196986
《亲戚计算器》大概是我迄今为止写过最复杂的算法了,它可能看起来它好像逻辑简单,仅 1 个方法调用而已,却耗费了我大量的时间!
从一开始灵光乍现,想到实现它的初步思路,到如今开源已 7 年多了。这期间,我一直在不断更新才让它日趋完善,它的工作不仅是对数据的整理,还有我对程序逻辑的梳理和设计思路的推敲。
如果你也对传统文化稍微有点兴趣,不妨耐心的看下去……也许你会发现:原来我们日常习以为常的一个称呼,需要考虑那么多细节。
称谓系统的庞大
中国的亲戚称呼系统复杂在于,它对每种亲戚关系都有特定的称呼,同时对于同种关系不同地方、对于不同性别的人都可能有不同的称呼。
对外国人而言,父母的兄弟姐妹不外乎:uncle、aunt;而对于我们来说,父母的兄弟姐妹有:伯父、叔叔、姑姑、舅舅、姨妈;
不同地方对同个亲戚的称呼都是不一样的,以爸爸为例,别称包含有:爸爸、父亲、老爸、阿爸、老窦、爹地、老汉、老爷子等等;
不同关系链可能具有相同的称呼;比如“舅公”一词,可以是父母亲的舅舅,也可以是老公的舅舅,而这两种关系辈分却不同。究其原因我猜测是,传统上由姻亲产生的亲戚关系,为表达谦卑会自降一辈,随子女称呼配偶的长辈。
一个称呼中可能是多种关系的合称。比如:“父母”、“子女”、“公婆”,他们不是指代一个人物关系,而是几个关系的合称。
在设计这套算法的时候,我希望它能尽量包含各种称呼、各种关系链,因为我之所以做这个项目就是像让它真正集合多种需求,否则如果它不够全面那终究是个代码演示而已。
关系网络的表达
亲戚的关系网络是以血缘和婚姻为纽带联系在一起的,每个节点都是一个人,每个人都有诸如:父、母、兄、弟、姐、妹、子、女、夫、妻这样的基础关系。关系网络中的节点数量随着层级的加深而指数增长!如果是5层关系,大概就有9x9x9x9x9 = 59049种关系了(当然,这其中有小部分是重复的)。如果想要把几万个关系,数十万个称呼全部尽收其中显然是不可能的,没人有那个精力去维护。
如何将亲戚关系网络中每个节点之间的关系用数据结构表现出来是一个难点。它需要保证数据量尽量全、占用体积小、易检索、可扩展等特点,这样才能保证算法检索关系时的完整性和高效性。
网络的寻址问题
既然是计算,那一定不是简单通过父、母、子、女等这些基础关系找对应称呼了。否则这就是简单的字典查询而已,谈不上算法。
如果问的是:“舅妈的儿子的奶奶的外孙”又该如何呢?首先,需要在网络中找到单一称呼,如“舅妈”,而下一步找她的“儿子”,而非你自己的“儿子”。这就要求有类似于指针的功能,关系链每往前走一步,指针就指引着关系的节点,最终需找到答案。
而就像前面说到的一样,某些称谓可能对应多条关系,同时有些关系并不是唯一的。比方说你爸爸的儿子就是你吗?有没有可能是弟弟或者哥哥?而这些是不是同时取决于你的性别呢?
因为如果你是女的,那么你爸爸的儿子必然不是你呀!
这就对算法提出了一个要求,它必须准确的包含多种可能性。
年龄和性别的推测
随着关系链的复杂,最终得到的答案也有多种。那有没有一种可能,在对关系链的描述中是否存在一些词,可以通过逻辑判断知道对方的性别或年纪大小,进而排除一些不可呢?
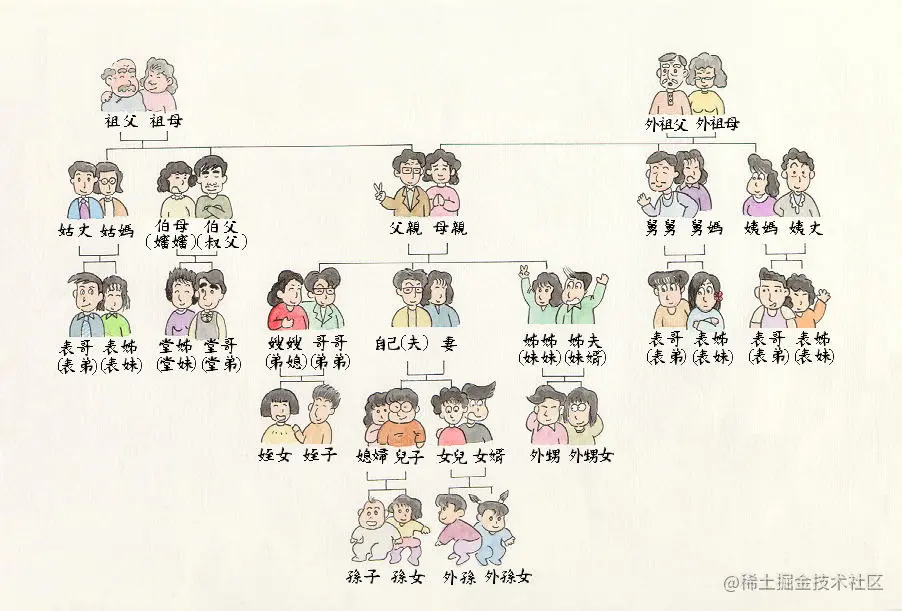
例如“爱人的婆婆的儿子”,单从“爱人”二字我们并不能推测自己的性别,而后的“婆婆”确是只有女性才有的亲戚,“爱人的婆婆”就足以推断自己是男的,那么“爱人的婆婆的儿子”必然包含自己。
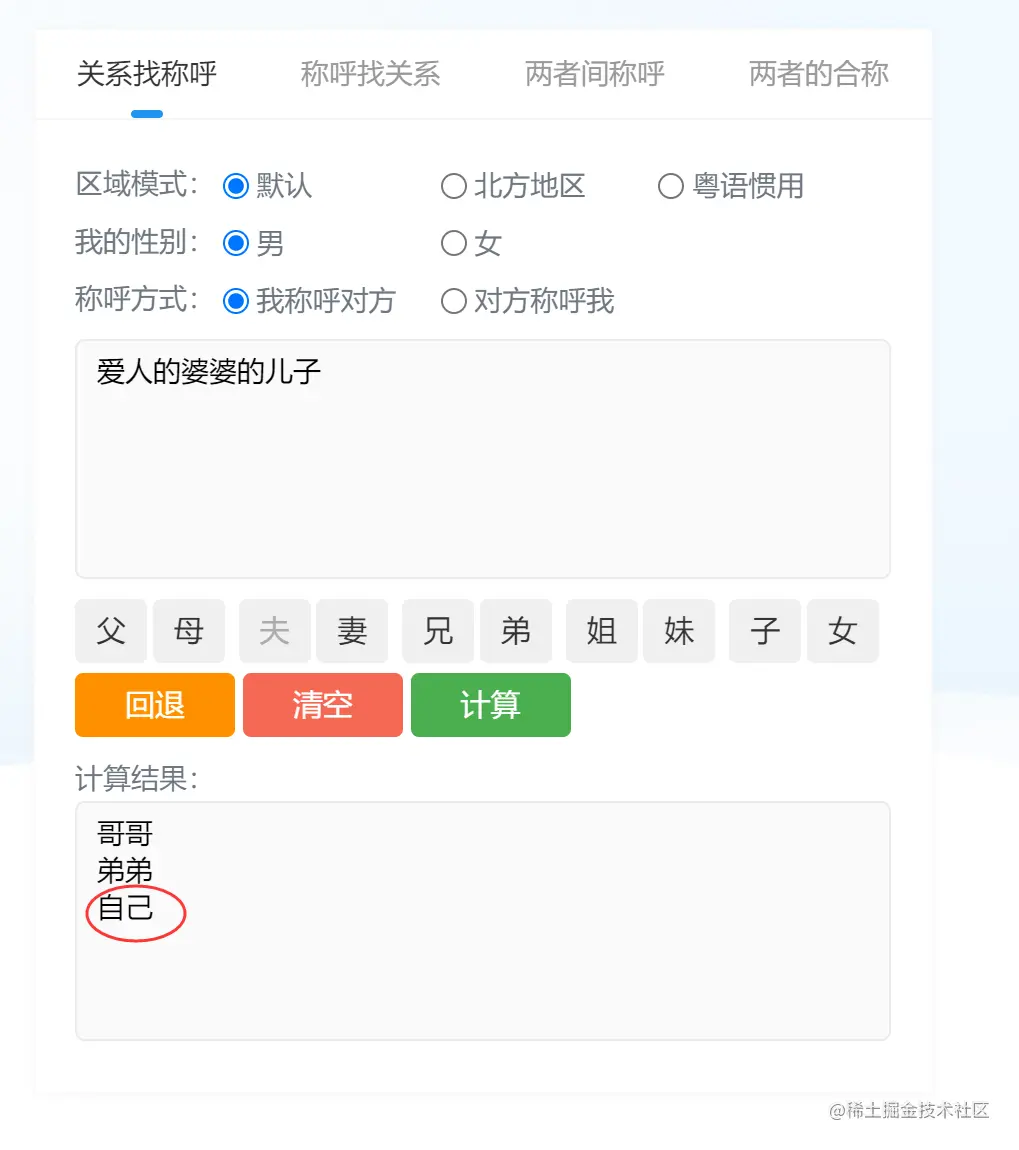
相反,“爱人的婆婆的女儿”一定不是自己,只能是自己的姊妹。
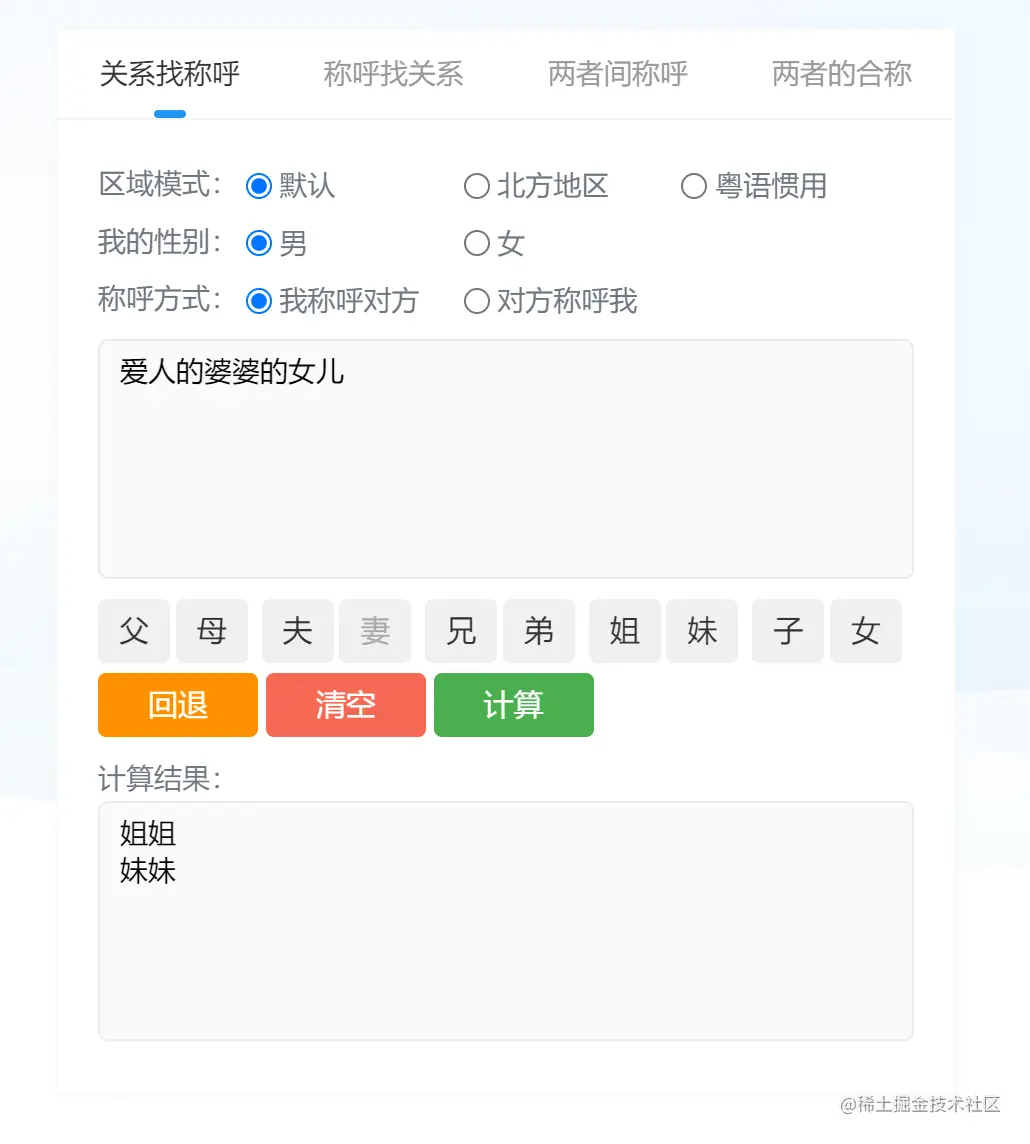
再比如:自己哥哥的表哥也是你的表哥,你弟弟的表哥还是你表哥吗?因为你无法判断你弟弟和他的表哥谁大,自然无法判断对方是你的表哥还是表弟。既然都有可能存在,就需要保留可能性进一步计算。这就涉及到了在关系链的计算中不仅仅需要考虑隐藏的性别线索,还有年龄线索。
身份角度的切换
单从亲戚和自己的关系链条中开始算亲戚的称呼,仅仅是单向的推算,只需要一个个关系往下算就好。如果想知道对方称呼为我什么,这就需要站在对方的角度,重新逆向的调理出我和他之间的关系了。比如我的“外孙”应该叫我什么?
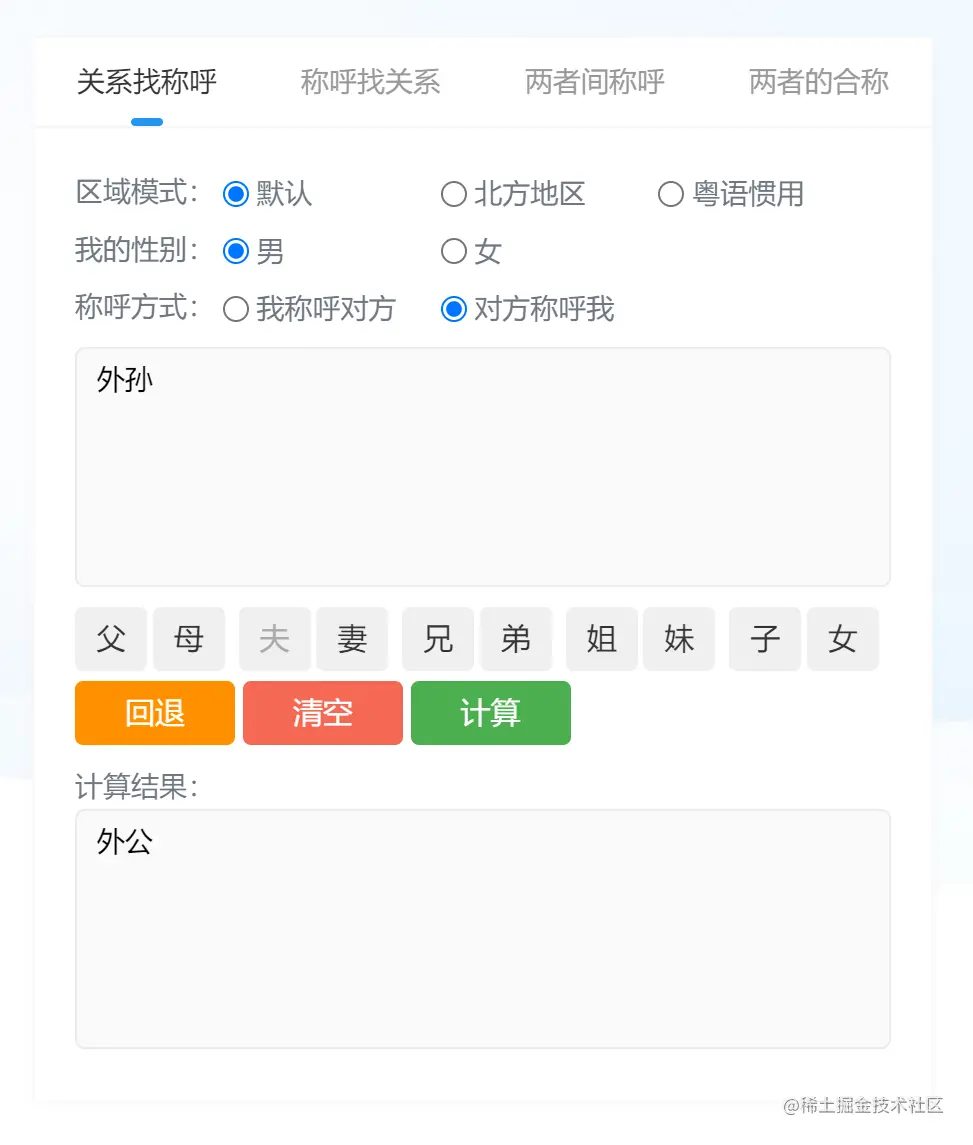
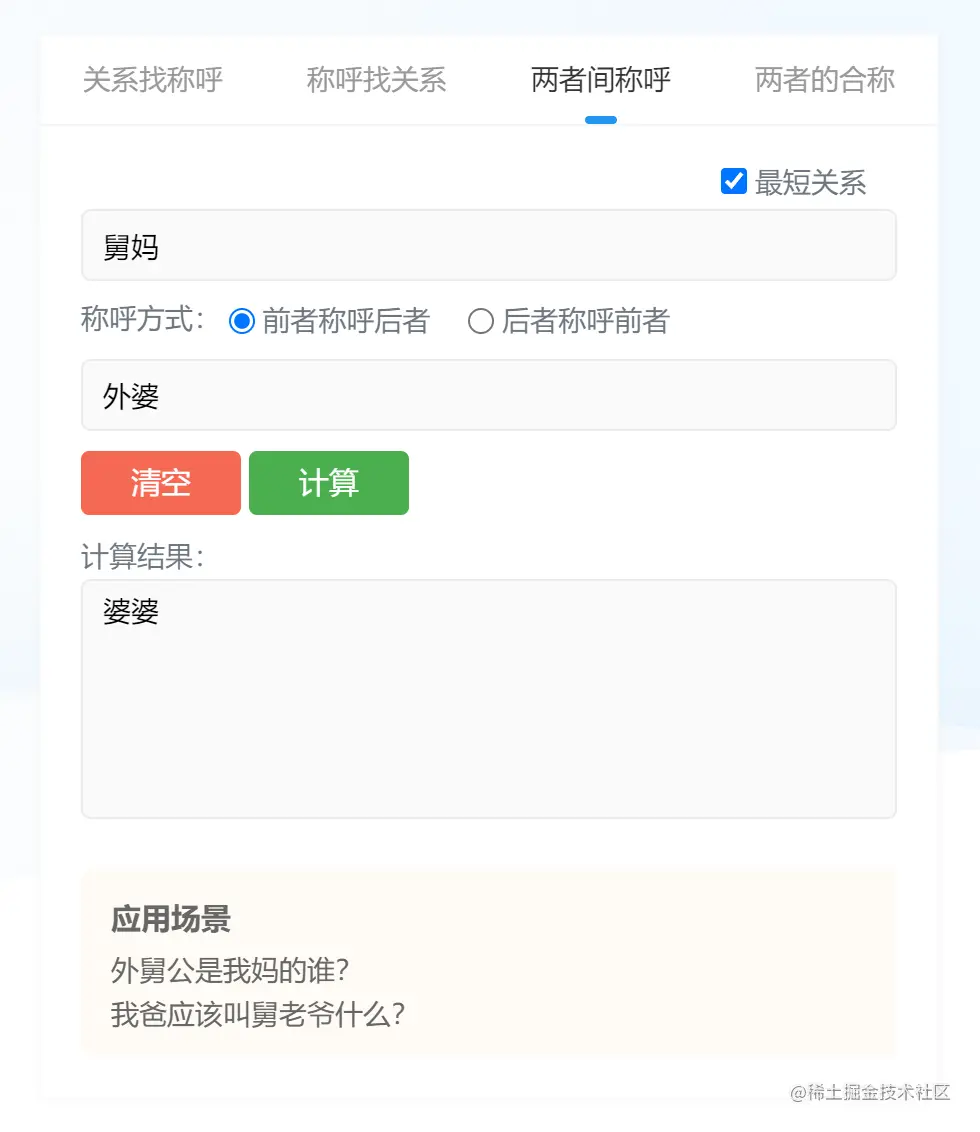
另一方面,如果把我置身于第三者,想知道我的两个亲戚他们之间如何称呼,就必须要同时站在两个亲戚的角度,看待他们彼此之间的关系了。比如:我的“舅妈”该叫我的“外婆”什么呢?
年龄排序的问题
前面说到的都是对不同关系链中的可能性推敲,那如果相同的关系如何判断年龄呢?如果你有3个舅舅呢?虽然不管哪个舅舅,他们对于你的关系都一样,他们的老婆你都得叫声“舅妈”。但他们毕竟有年龄区别,自然就有长幼的排序了。有了排序,就又引发了对他们之间关系的思考。
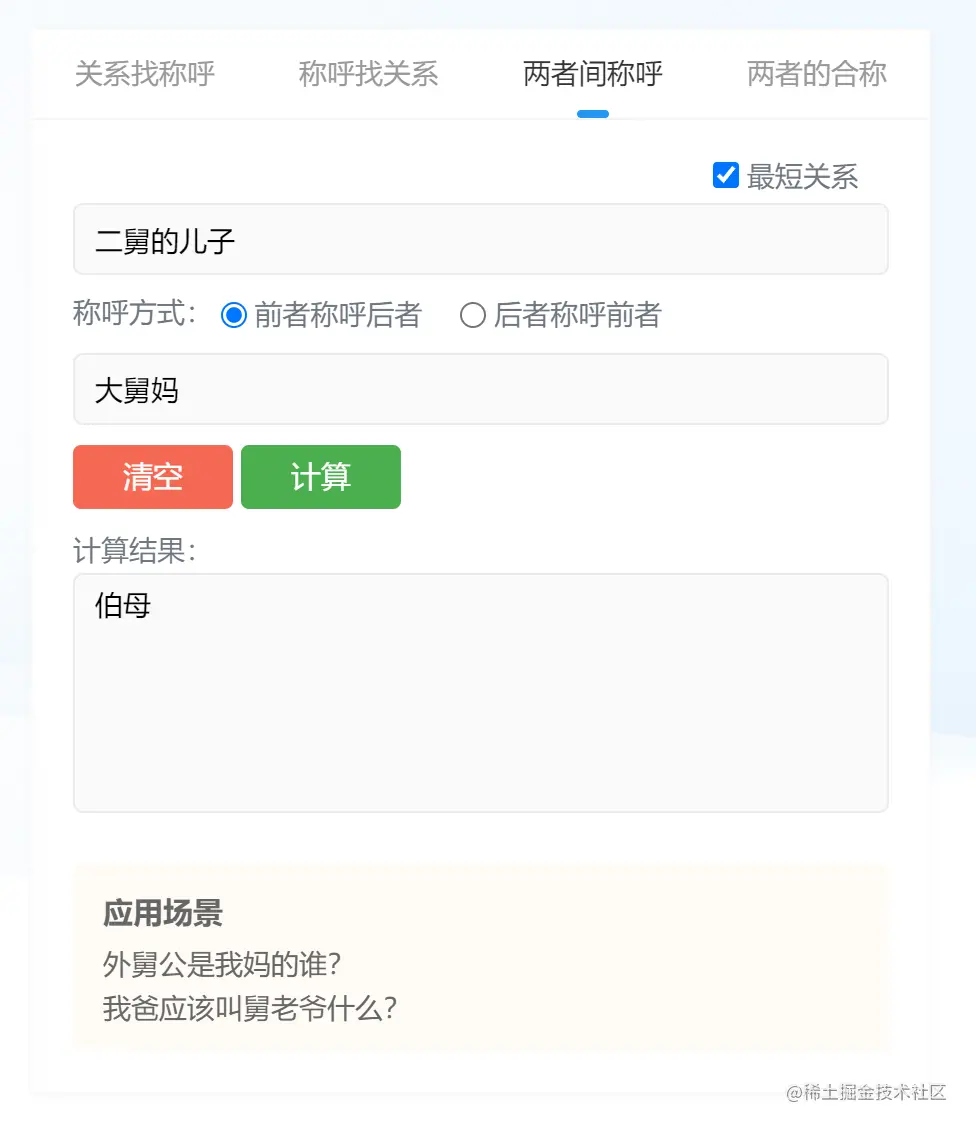
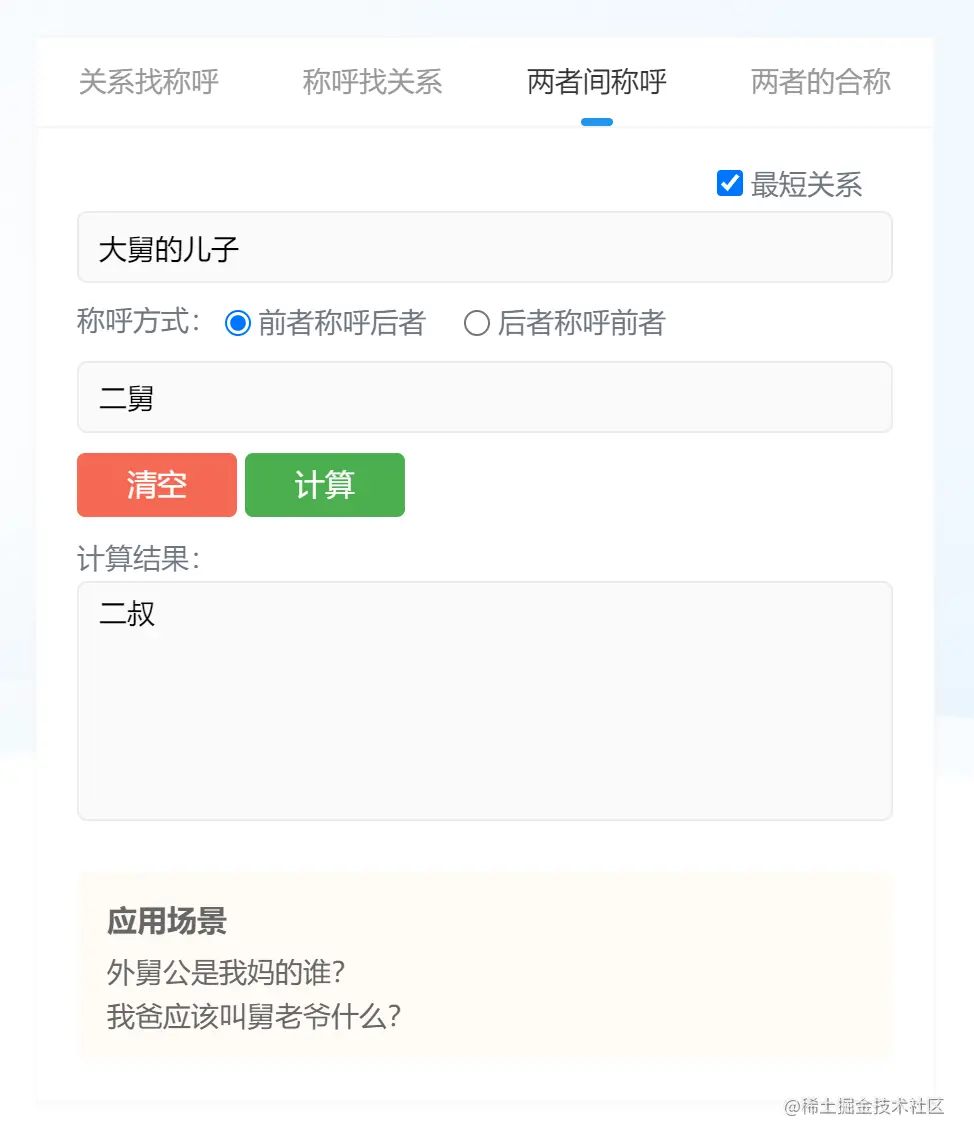
还是举例说明下:“舅舅”和“舅妈”是什么关系?相信大部分第一反应就是夫妻关系呗!其实不尽然,毕竟有些人不会只有一个舅舅吧?那“大舅妈”和“二舅”就不是夫妻关系了,他们是叔嫂关系呀。“二舅”得管“大舅妈”叫“嫂子”,“大舅妈”得管“二舅”叫“小叔子”。
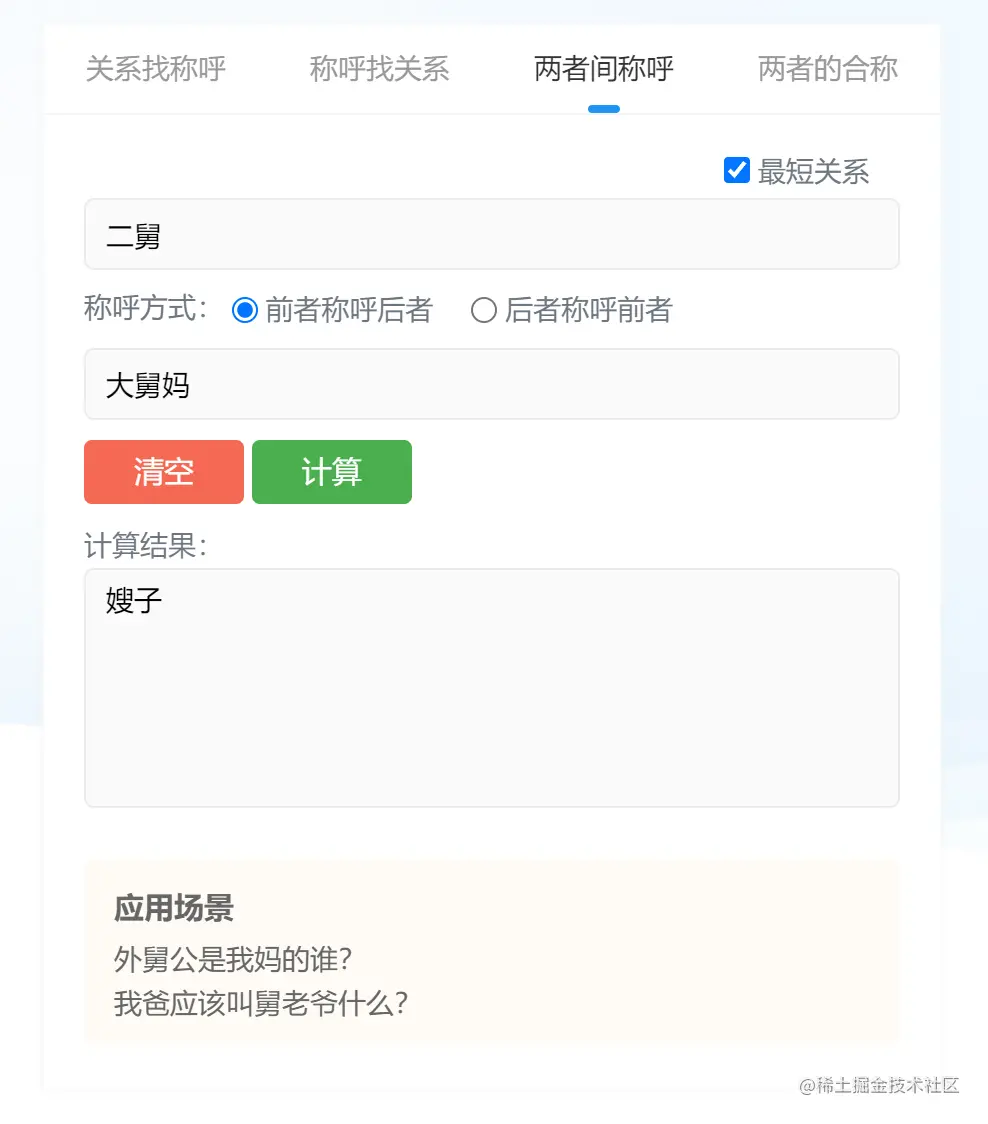
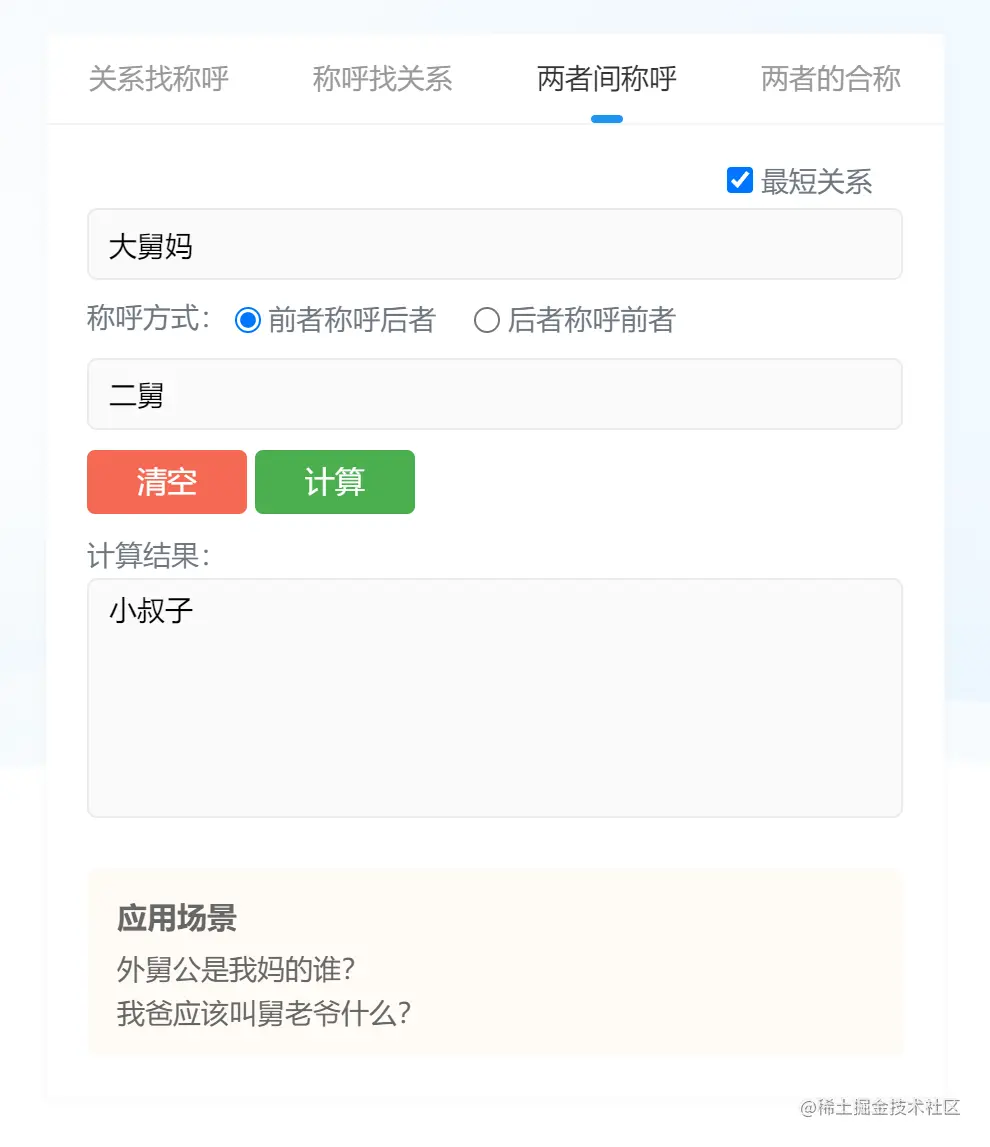
再进一步说,“二舅的儿子”得叫“大舅妈”为“伯母”,“大舅的儿子”得叫“二舅”为“二叔”。这些由父辈的排序问题影响自己称谓的不同,而是我这套算法需要考虑的内容。
怎么样?是不是没有想象中的那么简单?
项目线上访问地址:https://passer-by.com/relationship/
项目源码:https://github.com/mumuy/relationship
算法实现原理介绍
常见问题
市面上同类型的算法基本以 “称谓-直接关系-称谓” 的方式实现,如:
"爸爸": {
"爸爸": "爷爷",
"妈妈": "奶奶",
"哥哥": "伯父",
"弟弟": "叔叔",
"姐姐": "姑妈",
"妹妹": "姑妈",
"丈夫": "未知",
"妻子": "妈妈",
"儿子": {"older": "哥哥", 'middle': "我", "younger": "弟弟"},
"女儿": {"older": "姐姐", 'middle': "我", "younger": "妹妹"}
}
这样的结构主要有以下问题:
无法跨代直接查询,如:如何知道“舅妈的婆婆”是谁? 无法逆向查询称谓,如:“表哥的妈妈”的妈妈是“舅妈”、“姨妈”还是“姑妈”? 数据结构过于臃肿, 如:某个节点下可能会出现多个“未知” 无法兼容多种称呼,如:各地称呼不尽相同,“爸爸”也可以叫“父亲”、“爹地” 无法进行关系拓扑,如:“舅妈”和我什么关系?
本算法的原理
采用 “关系链-称谓集合” 哈希对的方式建立数据库,映射亲戚网络中的每个节点和自己的关系
数据结构
'h':['老公','丈夫','先生','官人','男人','汉子','夫','夫君','相公','夫婿','爱人','老伴'],
'h,f':['公公','翁亲','老公公'],
每个称谓都可以找到相应的关系链,每个关系链同时有对应的称谓集合,这里需要引入自己“发明”的特殊语法标记
语法说明
【关系】f:父,m:母,h:夫,w:妻,s:子,d:女,xb:兄弟,ob:兄,lb:弟,xs:姐妹,os:姐,ls:妹
【修饰符】 1:男性,0:女性,&o:年长,&l:年幼,#:隔断,[a|b]:并列
例如:
"f"对应着爸爸,那么:"f,m"对应着奶奶,"f,f"对应着爷爷;
这样在查询关系的时候,只需要对关系链进行计算就好了,而不是对称谓进行字典查找
算法思路
当用户输入“舅妈的婆婆”,可以分解出两个对象“舅妈”和“婆婆”(前者的婆婆)
从“关系链-称谓集合”映射关系可知,这两个对象的关系链分别是:"m,xb,w"和"h,m",合并后的关系即:"m,xb,w,h,m"
此时关系链会出现冗余,需要进一步处理:
"w,h"表示“老婆的老公”,即自己,可直接将关系链简化成:"m,xb,m"
同理,"xb,m"表示“兄弟的妈妈”,即自己的妈妈,可将关系链再次简化为:"m,m"
当无法进一步简化时,就得到了“最简关系链”,将其带入亲戚关系数据库查询,便可知"m,m"即为自己的“外婆”
这样就将复杂的关系链转换成直接关系了,除此之外还可根据“关系链-称谓集合”反向通过称呼找到关系;
实现细节
如何实现关系链的简化?
关系链为字符串,用正则表达式即可按情形匹配,同时做到“替换”的操作。由于所有非直接的关系,都是存在关系链表达的冗余。虽然冗余可能多层且复杂,只需要考虑两层关系中的去冗余,反复处理即可。
某些多层关系可能未必对应一种关系,如何解决关系的不唯一?
“爸爸的儿子”不一定是自己,也可能是自己的兄弟。在语法中引入了“隔断”和“并列”语法,可以借助正则表达式将此类不唯一的关系拆分为多组,每次再单独带入递归求最简解即可。
每个节点离自己远一层关系,节点数据便翻倍,如何解决数据量过大的问题?
中国的亲戚关系存在一定规律,旁系分支大体由 分支节点 及其 子代关系 ,我们只需记录 分支节点 和 子代关系 即可。如:“舅表哥”和“堂哥”两者在和自己的关系链上存在一定相似,没必要记录两者所有关系。只需知道“舅表哥”是“舅舅”的后代,而“堂哥”是“叔伯”的后代,那么“舅表哥”和“堂哥”的所有后代及姻亲数据可以只存3部分。即:
舅表哥关系数据 = 舅舅(分支节点) + 哥哥关系数据(子代关系);
堂哥关系数据 = 叔伯(分支节点) + 哥哥关系数据(子代关系);
这样的关系有很多,如:“舅表”、“姑表”、“从堂”、“姑表叔表”等等,对关系数据进行拆分复用,即可以达到压缩数据量。同时在脚本运行中对 分支节点 和 子代关系 进行拼接即可组合出数据库。
你还知道哪些可以计算出亲戚关系的好方法,欢迎在评论区留言~
最后,欢迎学编程的朋友们加入鱼皮的 编程知识星球 ,鱼皮会 1 对 1 解决你的问题,直播带你做出项目、为你定制学习计划和求职指导,还能获取海量编程学习资源,和上万名学编程的同学共享知识、交流进步。求职季一起加油!
往期推荐