
代码实践|通过简单代码来回顾卷积块的历史
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

我试着定期阅读ML和AI的论文,这是保持不掉队的唯一的方法。作为一个计算机科学家,我常常会在看科学性的文字描述或者是数据公式的时候遇到麻烦。我发现通过代码来理解会好很多。所以,在这篇文章中,我会通过Keras实现的方式,带领大家回顾一下最近的一些文章中的重要的卷积块。
当你在GitHub上寻找热门的结构的实现的时候,你可能会惊讶需要多少代码。在代码中包含足够的注释以及使用额外的参数是一个很好的实践,但是同时,也会使代码不能聚焦于核心的结构的实现。为了简化代码,我使用了一些函数的别名:
def conv(x, f, k=3, s=1, p='same', d=1, a='relu'):
return Conv2D(filters=f, kernel_size=k, strides=s,
padding=p, dilation_rate=d, activation=a)(x)
def dense(x, f, a='relu'):
return Dense(f, activation=a)(x)
def maxpool(x, k=2, s=2, p='same'):
return MaxPooling2D(pool_size=k, strides=s, padding=p)(x)
def avgpool(x, k=2, s=2, p='same'):
return AveragePooling2D(pool_size=k, strides=s, padding=p)(x)
def gavgpool(x):
return GlobalAveragePooling2D()(x)
def sepconv(x, f, k=3, s=1, p='same', d=1, a='relu'):
return SeparableConv2D(filters=f, kernel_size=k, strides=s,
padding=p, dilation_rate=d, activation=a)(x)我发现不使用模板代码,代码的可读性增加了不少。当然,需要你理解我的单个单词的表述才可以。我们开始。
Bottleneck 块
卷积层的参数的数量取决于kernel的尺寸,输入的filter的数量和输出filter的数量。你的网络越宽,3x3卷积的代价越大。
def bottleneck(x, f=32, r=4):
x = conv(x, f//r, k=1)
x = conv(x, f//r, k=3)
return conv(x, f, k=1)bottleneck块背后的思想是使用计算量很小的1x1的卷积将通道的数量减少r倍,接下来的3x3的卷积的参数会大大减小,最后,我们再使用另一个1x1的卷积将通道数变回原来的样子。
Inception 模块
Inception模块的思想是并行使用不同类型的操作,然后将结果合并。这样,网络可以学习到不同类型的filter。
def naive_inception_module(x, f=32):
a = conv(x, f, k=1)
b = conv(x, f, k=3)
c = conv(x, f, k=5)
d = maxpool(x, k=3, s=1)
return concatenate([a, b, c, d])这里我们将卷积核尺寸为1,3,5的结果进行了合并,后面接一个MaxPooling层。上面这一小段显示了一个inception的朴素的实现。实际的实现和bottlenecks 的思想结合起来,会稍微更复杂一点。
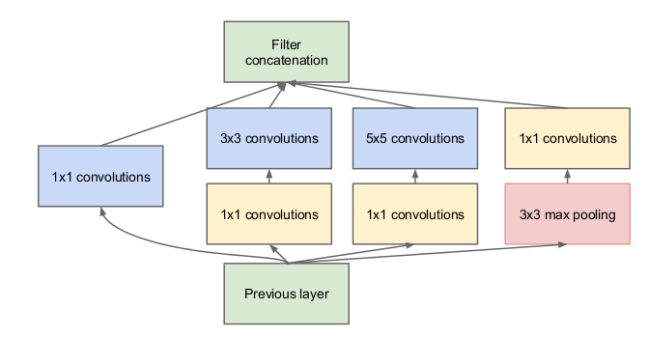
Inception 模块
def inception_module(x, f=32, r=4):
a = conv(x, f, k=1)
b = conv(x, f//3, k=1)
b = conv(b, f, k=3)
c = conv(x, f//r, k=1)
c = conv(c, f, k=5)
d = maxpool(x, k=3, s=1)
d = conv(d, f, k=1)
return concatenate([a, b, c, d])Residual 块
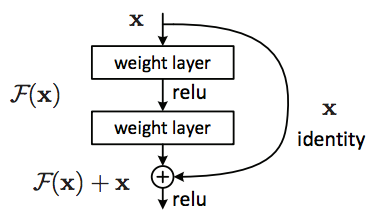
ResNet是微软的研究人员发明的一种结构,可以让网络变得很深,要多深都可以,同时仍然可以提高模型的准确率。现在你也许已经对很深的网络司空见惯了,但是在ResNet之前却不行。
def residual_block(x, f=32, r=4):
m = conv(x, f//r, k=1)
m = conv(m, f//r, k=3)
m = conv(m, f, k=1)
return add([x, m])它的思想是在输出的卷积块上加上一个初始的激活。那样的话,网络可以决定在学习的过程中,输出使用多少新的卷积。注意,inception模块在拼接输出的时候也拼接了加到上面的残差块。
ResNeXt 块
看名字就知道,ResNeXt 和ResNet和接近。作者给卷积块引入了一个新的名词基数,就像是另外的一个维度,就像宽度(通道数)和深度(层数)一样。
基数指的是卷积块中并行出现的路径的数量。听起来很像inception块中4个不同的并行的操作。但是,这里使用的是完全相同的操作,4个基数指的是使用4次相同的操作。
但是既然做的是同样的事情,为什么要并行起来做呢?问得好,这个概念要追溯到最早的AlexNet中的分组卷积,原先AlexNet是为了将运算分开利用不同的GPU,而ResNeXt主要是为了提高参数的使用效率。
def resnext_block(x, f=32, r=2, c=4):
l = []
for i in range(c):
m = conv(x, f//(c*r), k=1)
m = conv(m, f//(c*r), k=3)
m = conv(m, f, k=1)
l.append(m)
m = add(l)
return add([x, m])思想就是对于所有的输入通道,将它们分成组。卷积只在组中进行,不会跨组。可以发现,每个组会学到不同的特征,提高了权值的效率。
想象一下,一个bottleneck块首先使用压缩率为4,将256通道降维到64通道,最后输出的时候,再从64通道回到256通道。如果我们引入了基数为32,压缩率为2,我们并行使用32个1x1卷积层,每个组得到4 (256 / (32*2))个输出通道。最后一步将32个并行路径的结果加起来,得到一个输出,然后再加上初始的输入,得到残差连接。
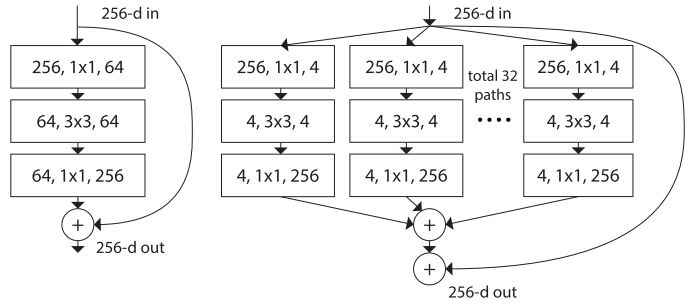
Left: ResNet Block — Right: RexNeXt Block of roughly the same parameter complexity
这需要好好消化一下。使用上面的图看看能不能得到一个可视化的表示,了解一下发生了什么,或者拷贝上面的几行代码,自己用Keras建一个小网络试试。这么复杂的描述,只用了9行简单的代码就实现了,是不是很酷?
顺便说一下,如果基数的数量和通道的数量相同的话,我们会得到一个叫做深度可分离卷积的东西。这个东西自从Xception 结构之后,就开始火了起来。
Dense 块
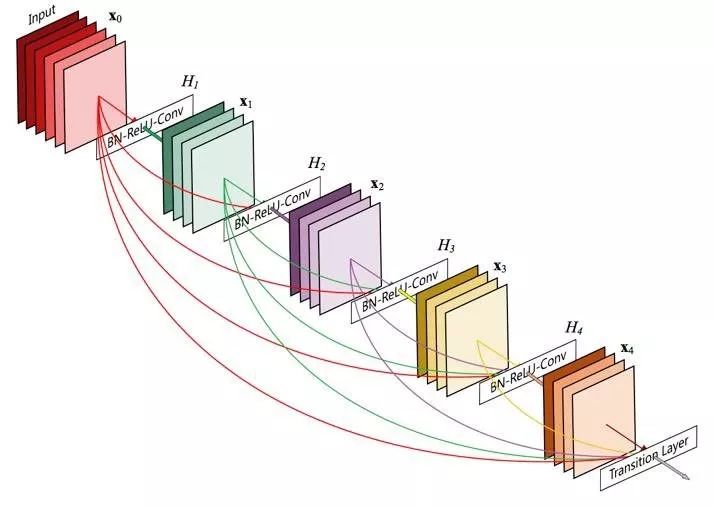
dense块是残差块的一种极端的版本,每一个卷积层都会得到该模块中之前的所有卷积层的输出。第一,我们将输入的激活加到一个列表中,然后进入一个循环,遍历这模块的深度。每个卷积的输出都会加到这个列表中,所以下面的循环会得到越来越多的输入特征图,直到到达预定的深度。
def dense_block(x, f=32, d=5):
l = x
for i in range(d):
x = conv(l, f)
l = concatenate([l, x])
return l研究了几个月得到了一个和DensNet一样好的结构,实际的构建模块就是这么简单,太帅了。
Squeeze-and-Excitation 块
SENet短期内曾是ImageNet中最先进的。它基于ResNext构建,聚焦于对通道之间的信息进行建模。在常规的卷积中,每个通道在内积操作中对于加法操作具有相同的权重。
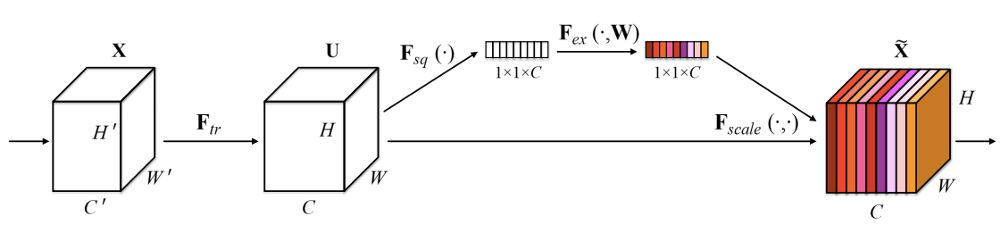
SENet引入了一个非常简单的模块,可以在任意的网络结构中加入。它构建了一个小的神经网络,可以学习到对于输入来说,每个filter的权重是多少。可以看到,这不是一个卷积模块,但是可以加入到任意的卷积块中,而且有可能提高性能。
def se_block(x, f, rate=16):
m = gavgpool(x)
m = dense(m, f // rate)
m = dense(m, f, a='sigmoid')
return multiply([x, m])每个通道被压缩成一个数值,然后输入到一个两层的的神经网络中。依赖于通道的分布,这个网络可以学到基于他们的重要性的权重。最后,这些权重和卷积的激活相乘。
SENets引入了一个很小的计算量,同时提升了卷积模型的性能。在我看来,这个模块并没有得到它应有的关注。
NASNet Normal Cell
到了这里,开始有点难看了。我们要离开那个简单有效的设计空间了,进入一个设计神经网络的算法的世界。NASNet从如何设计的看上去不可思议,但是实际结构相当的复杂。反正我就是知道在ImageNet上,表现非常好。
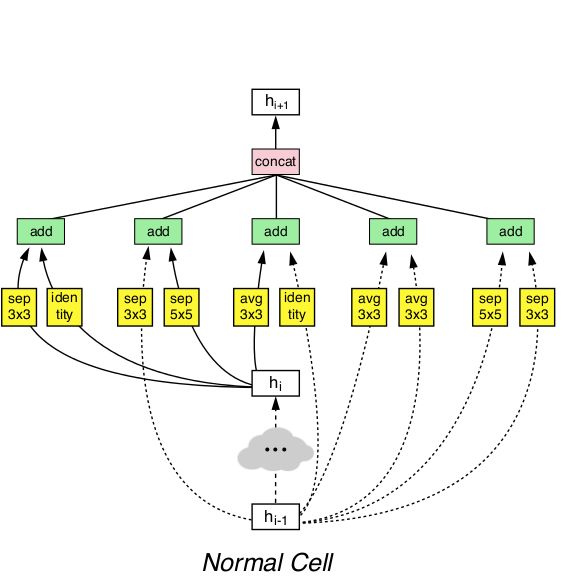
作者手动定义了一个搜索空间,使用不同可能的设置搜索不同类型的卷积核池化层,还定义了这些层是如何设计成并行的,如何相加的,如何拼接的。一旦定义好了,就开始进行强化学习,基于循环神经网络,如果设计出的网络在CIFAR-10上表现的很好的话,就得到奖励。
最后得到的结构不仅仅是在CIFAR-10上表现的好,在ImageNet上也取得了业界领先。NASNet由基础的Normal Cell和Reduction Cell相互重复而成。
def normal_cell(x1, x2, f=32):
a1 = sepconv(x1, f, k=3)
a2 = sepconv(x1, f, k=5)
a = add([a1, a2])
b1 = avgpool(x1, k=3, s=1)
b2 = avgpool(x1, k=3, s=1)
b = add([b1, b2])
c2 = avgpool(x2, k=3, s=1)
c = add([x1, c2])
d1 = sepconv(x2, f, k=5)
d2 = sepconv(x1, f, k=3)
d = add([d1, d2])
e2 = sepconv(x2, f, k=3)
e = add([x2, e2])
return concatenate([a, b, c, d, e])上面是如何使用Keras来实现Normal Cell。除了这些层的组合之外,并没有什么新的东西,效果非常好。
Inverted Residual 块
到目前为止,你听说过了 bottleneck block 和 可分离卷积,现在让我们把这两个东西放到一起,如果你跑一些测试,你会注意到可分离卷积已经减少了参数的数量,再用 bottleneck block压缩的话,可能会伤害到性能。
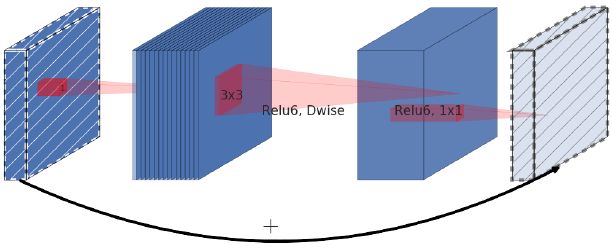
作者实际上做了件和bottleneck residual block相反的事情,使用1x1的卷积核来增加通道的数量,因为接下来的可分离卷积已经很大程度上减小了参数的数量,然后在和初始激活相加之前把通道数降下来。
def inv_residual_block(x, f=32, r=4):
m = conv(x, f*r, k=1)
m = sepconv(m, f, a='linear')
return add([m, x]最后一个困惑是,可分离卷积后面并没有接一个激活函数,而是直接和输入相加。这个block加到结构里之后,非常的有效。
AmoebaNet Normal Cell
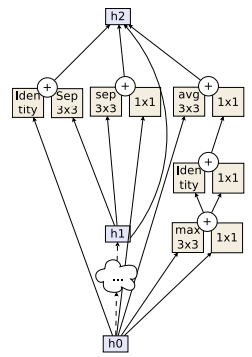
使用AmoebaNet ,我们达到了当前在ImageNet上的业界最佳,也可能是图像识别领域的业界最佳。和NASNet相似,这是由一个算法设计的,使用了相同的搜索空间。只是将强化学习算法换成了常常用来进化的遗传算法。这篇文章中,我们不进行详细的介绍。结果就是,通过进化,作者可以找到一个比NASNet更好的方法,同时计算量也更小。在ImageNet上Top-5的准确率达到了 97.87%,这是单个模型第一次有这样的结果。
看看代码,这个block中并没有加入什么你没见过的新东西,为什么不基于上面的图,自己试试实现一下新的Normal Cell,看看自己是不是能跟得上?
总结
我希望这个文章可以给你一个关于重要的卷积block的扎实的理解,实现这些block也许你想的要容易的多。去看看对应的论文,可以得到一个更加详细的理解。你会注意到,一旦你抓住了论文的核心思想,其余的理解起来就容易了。另外还要注意的是,在实际的实现中,常常会加入Batch Normalization,使用的激活函数也会有差别。
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~