
AlphaCode到底强在哪儿?清华博士后十分钟视频详细解析

来源:机器之心 本文约2300字,建议阅读5分钟
AlphaCode 到底是怎么练成的?
春节期间,DeepMind 的编程版 AlphaGo——AlphaCode 一度火到刷屏。它可以编写与普通程序员水平相媲美的计算机程序,在 Codeforces 网站的 10 项挑战中总体排名前 54.3%,击败了 46% 的参赛者。
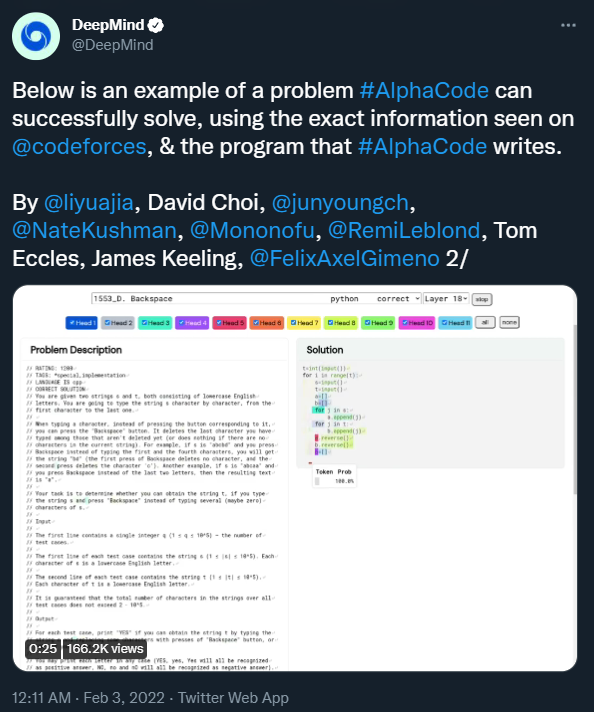
原视频地址:https://www.youtube.com/watch?v=YjsoN5aJChA

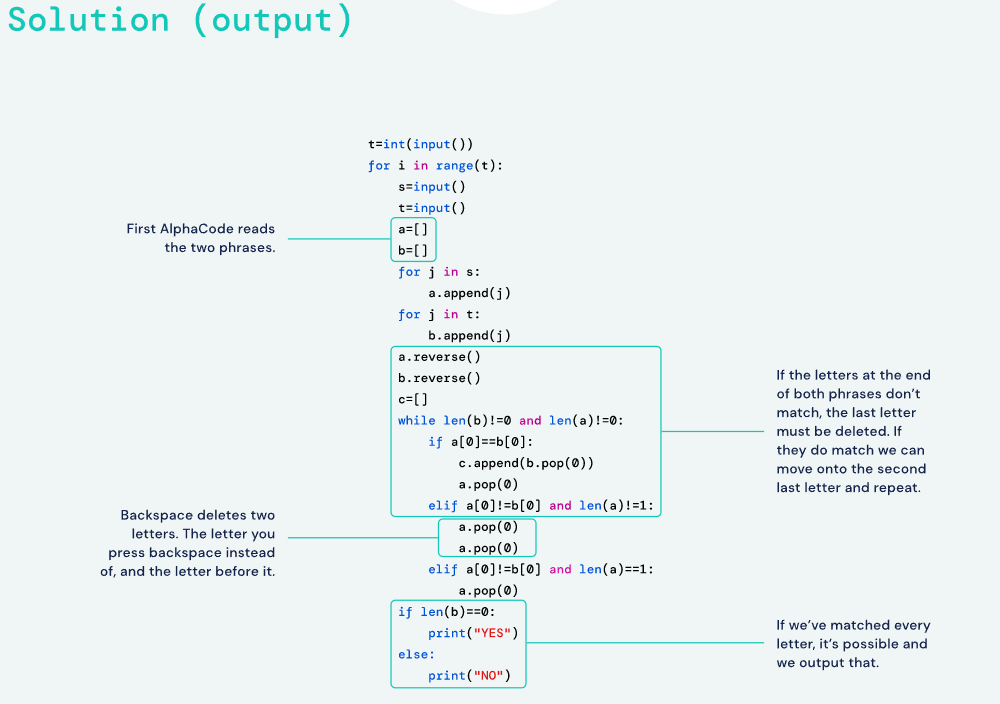
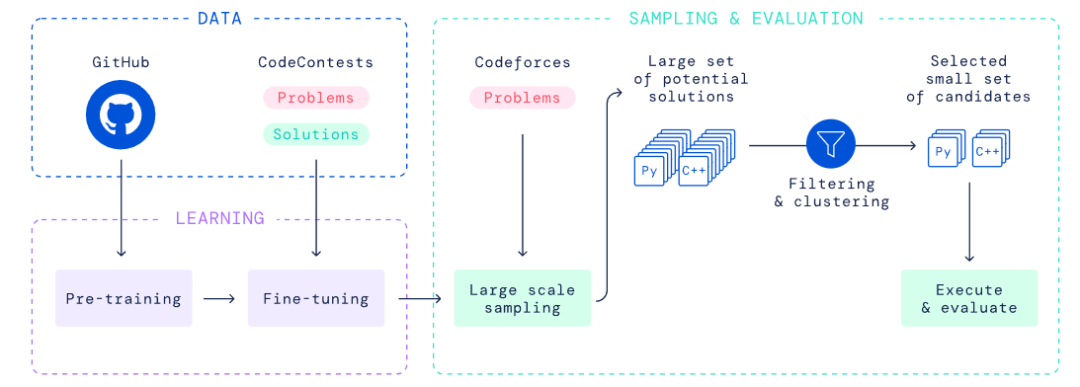
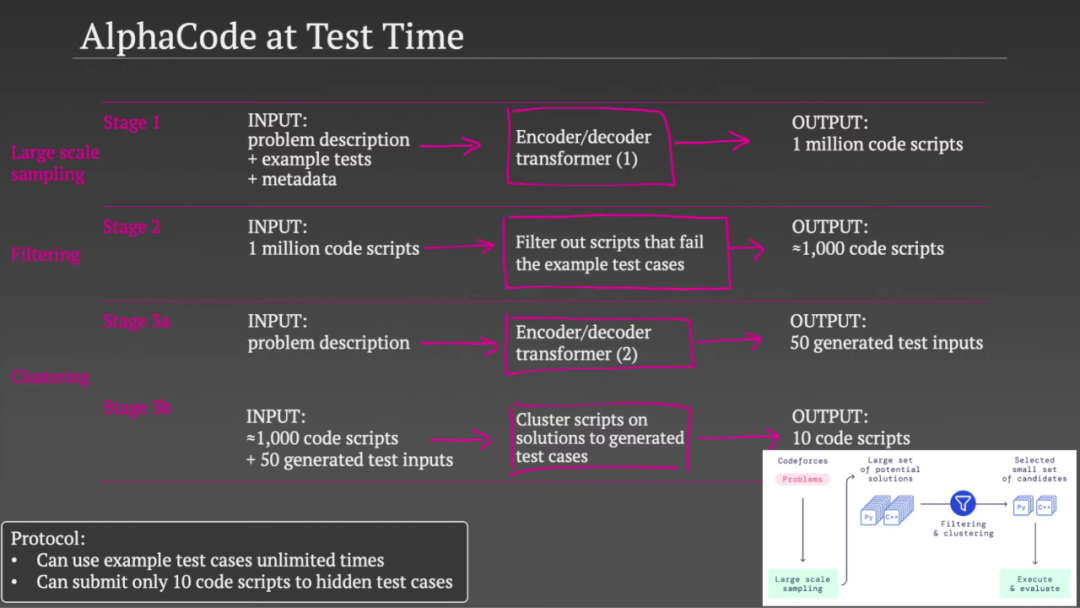
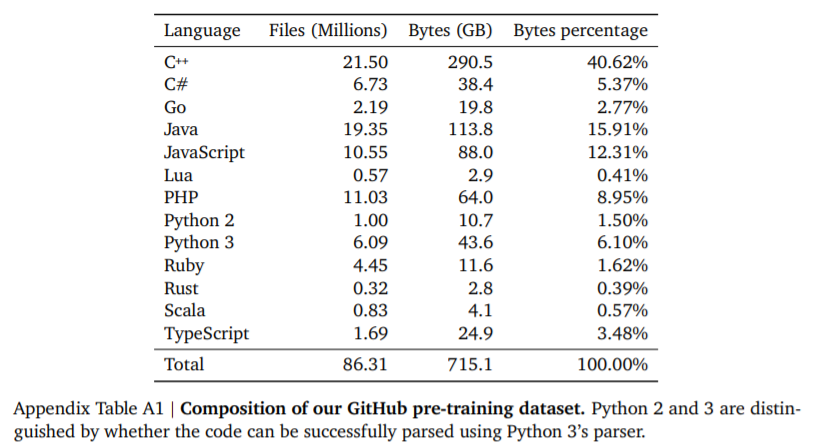
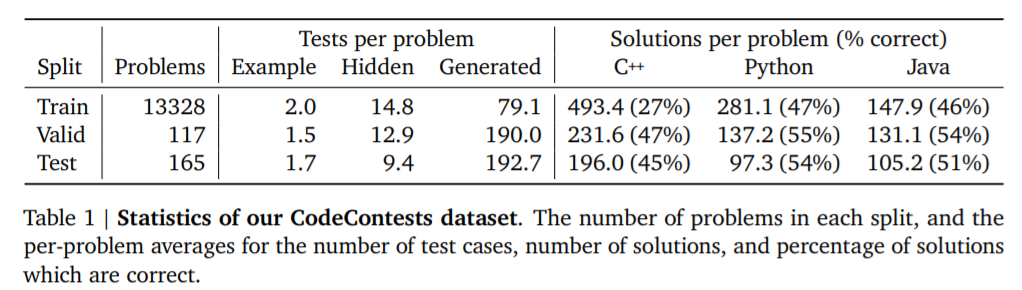
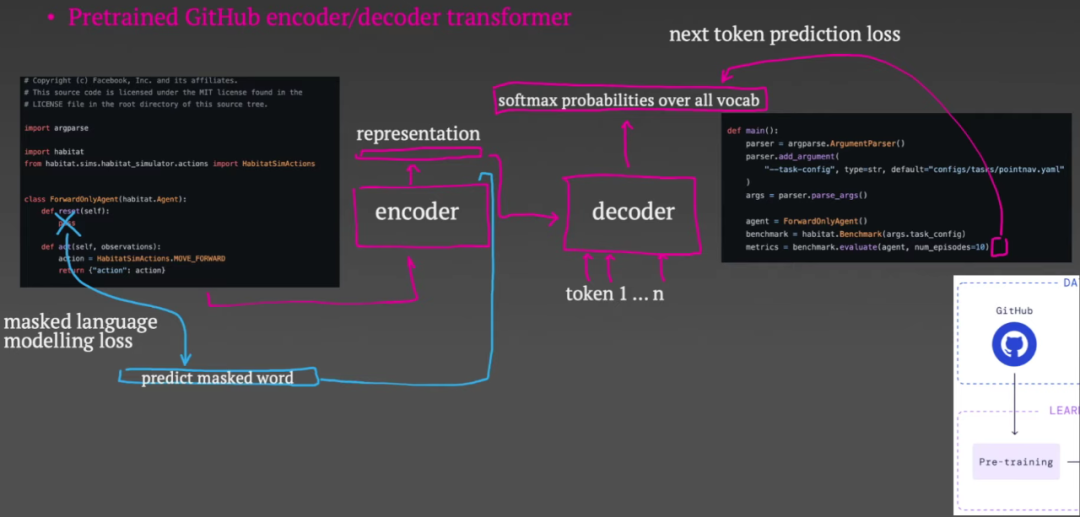
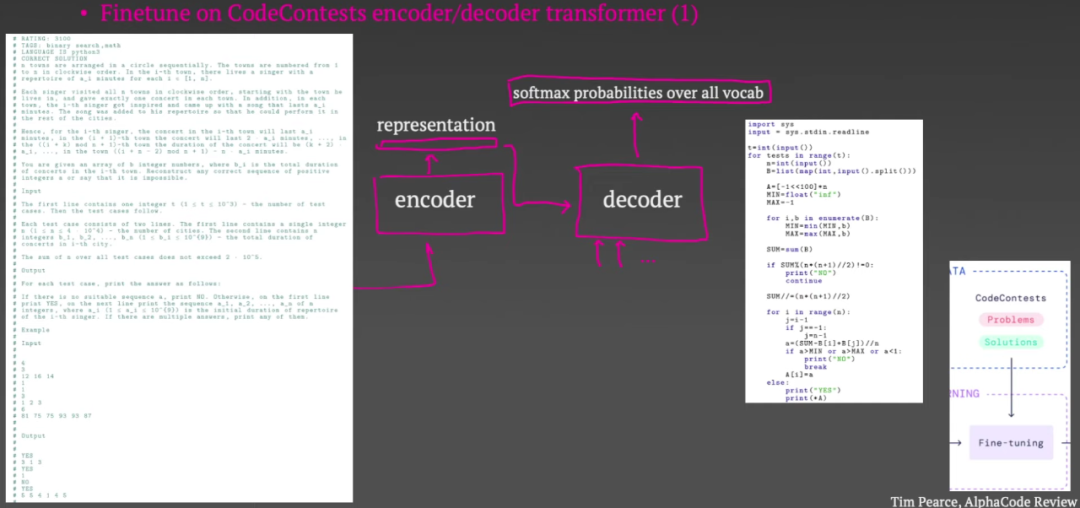
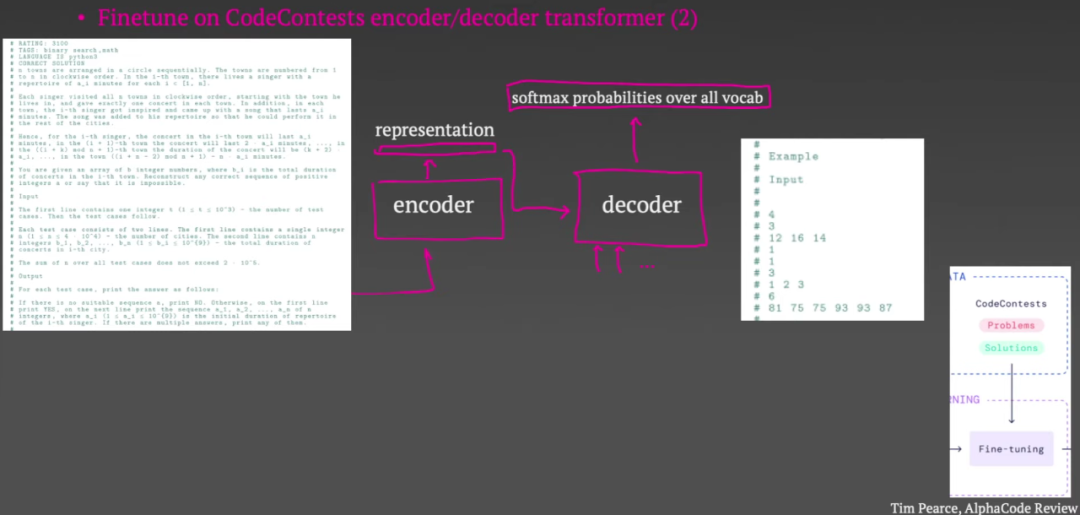
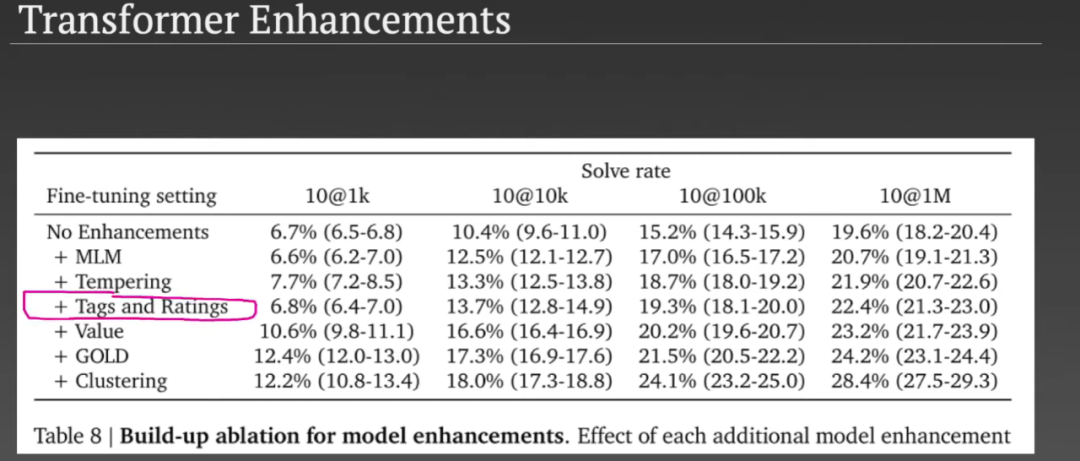
参考链接:
https://www.youtube.com/watch?v=YjsoN5aJChA
https://storage.googleapis.com/deepmind-media/AlphaCode/competition_level_code_generation_with_alphacode.pdf
评论