
HBase详细介绍及原理解析!
最近公司新项目用到HBase,学习了一下,顺便整理了笔记记录一下!
觉得有收获,希望帮忙点赞,转发下哈,谢谢,谢谢
文章很长,所以笔记内容会同步到个人网站:http://hardyfish.top/,方便阅读查看!
 基本介绍
基本介绍 HBase官网:https://hbase.apache.org/
Apache HBase 是 Hadoop中一个支持分布式的、可扩展的大数据存储的数据库。
当需要对大数据进行随机、实时读/写访问时,可以用 Apache HBase。
HBase特点
列式存储:
HBase是面向列族的非关系型数据库,每行数据列都可以不同,并且列可以按照需求进行动态增加。
因此在开始创建HBase表时,可以只创建列族,等需要时再创建相应的列。
数据压缩:
列式存储意味着数据往往类型相同,可以采用某种压缩算法进行统一的压缩存储。
海量存储:
基本操作
HDFS支持的海量存储,存储PB级数据仍能有百毫秒内的响应速度。
Shell操作
进入HBase客户端命令操作界面:
hbase shell
查看帮助命令:
hbase(main):001:0> help
查看当前数据库中有哪些表:
hbase(main):006:0> list
创建一张表:
创建user表, 包含base_info、extra_info两个列族
hbase(main):007:0> create 'user', 'base_info', 'extra_info'
create 'user', {NAME => 'base_info', VERSIONS => '3'},{NAME => 'extra_info'}
添加数据操作:
向user表中插入信息,row key为 rk0001,列族base_info中添加name列标示符,值为zhangsan
hbase(main):008:0> put 'user', 'rk0001', 'base_info:name', 'zhangsan'
向user表中插入信息,row key为rk0001,列族base_info中添加age列标示符,值为20
hbase(main):010:0> put 'user', 'rk0001', 'base_info:age', 20
查询数据:
通过rowkey进行查询:
- 获取user表中row key为rk0001的所有信息
hbase(main):006:0> get 'user', 'rk0001'
查看rowkey下面的某个列族的信息:
- 获取user表中row key为rk0001,base_info列族的所有信息
hbase(main):007:0> get 'user', 'rk0001', 'base_info'
查看rowkey指定列族指定字段的值:
- 获取user表中row key为rk0001,base_info列族的name、age列标示符的信息
hbase(main):008:0> get 'user', 'rk0001', 'base_info:name', 'base_info:age'
查看rowkey指定多个列族的信息
- 获取user表中row key为rk0001,base_info、extra_info列族的信息
hbase(main):010:0> get 'user', 'rk0001', 'base_info', 'extra_info'
hbase(main):011:0> get 'user', 'rk0001', {COLUMN => ['base_info', 'extra_info']}
hbase(main):012:0> get 'user', 'rk0001', {COLUMN => ['base_info:name', 'extra_info:address']}
指定rowkey与列值查询:
- 获取user表中row key为rk0001,cell的值为zhangsan的信息
hbase(main):013:0> get 'user', 'rk0001', {FILTER => "ValueFilter(=, 'binary:zhangsan')"}
指定rowkey与列值模糊查询:
- 获取user表中row key为rk0001,列标示符中含有a的信息
hbase(main):015:0> get 'user', 'rk0001', {FILTER => "(QualifierFilter(=,'substring:a'))"}
插入一批数据:
hbase(main):016:0> put 'user', 'rk0002', 'base_info:name', 'fanbingbing'
hbase(main):017:0> put 'user', 'rk0002', 'base_info:gender', 'female'
hbase(main):018:0> put 'user', 'rk0002', 'base_info:birthday', '2000-06-06'
hbase(main):019:0> put 'user', 'rk0002', 'extra_info:address', 'Shanghai'
查询所有数据:
- 查询user表中的所有信息
hbase(main):020:0> scan 'user'
列族查询:
- 查询user表中列族为 base_info 的信息
Scan:
设置是否开启Raw模式,开启Raw模式会返回包括已添加删除标记但是未实际删除的数据。
VERSIONS指定查询的最大版本数。
hbase(main):021:0> scan 'user', {COLUMNS => 'base_info'}
hbase(main):022:0> scan 'user', {COLUMNS => 'base_info', RAW => true, VERSIONS => 5}
多列族查询:
- 查询user表中列族为info和data的信息。
hbase(main):023:0> scan 'user', {COLUMNS => ['base_info', 'extra_info']}
hbase(main):024:0> scan 'user', {COLUMNS => ['base_info:name', 'extra_info:address']}
指定列族与某个列名查询:
- 查询user表中列族为base_info、列标示符为name的信息。
hbase(main):025:0> scan 'user', {COLUMNS => 'base_info:name'}
指定列族与列名以及限定版本查询:
- 查询user表中列族为base_info、列标示符为name的信息,并且版本最新的5个
hbase(main):026:0> scan 'user', {COLUMNS => 'base_info:name', VERSIONS => 5}
指定多个列族与按照数据值模糊查询:
- 查询user表中列族为 base_info 和 extra_info且列标示符中含有a字符的信息
hbase(main):027:0> scan 'user', {COLUMNS => ['base_info', 'extra_info'], FILTER => "(QualifierFilter(=,'substring:a'))"}
rowkey的范围值查询:
- 查询user表中列族为info,rk范围是[rk0001, rk0003)的数据
hbase(main):028:0> scan 'user', {COLUMNS => 'base_info', STARTROW => 'rk0001', ENDROW => 'rk0003'}
指定rowkey模糊查询:
- 查询user表中row key以rk字符开头的
hbase(main):029:0> scan 'user',{FILTER=>"PrefixFilter('rk')"}
更新数据值:
- 把user表中rowkey为rk0001的base_info列族下的列name修改为zhangsansan
hbase(main):030:0> put 'user', 'rk0001', 'base_info:name', 'zhangsansan'
指定rowkey以及列名进行删除:
- 删除user表row key为rk0001,列标示符为 base_info:name 的数据
hbase(main):032:0> delete 'user', 'rk0001', 'base_info:name'
指定rowkey,列名以及字段值进行删除:
- 删除user表row key为rk0001,列标示符为base_info:name,timestamp为1392383705316的数据
hbase(main):033:0> delete 'user', 'rk0001', 'base_info:age', 1564745324798
删除 base_info 列族
hbase(main):034:0> alter 'user', NAME => 'base_info', METHOD => 'delete'
hbase(main):035:0> alter 'user', 'delete' => 'base_info'
删除user表数据:
hbase(main):036:0> truncate 'user'
删除user表:
数据模型
#先disable 再drop
hbase(main):036:0> disable 'user'
hbase(main):037:0> drop 'user'
#如果不进行disable,直接drop会报错
ERROR: Table user is enabled. Disable it first.
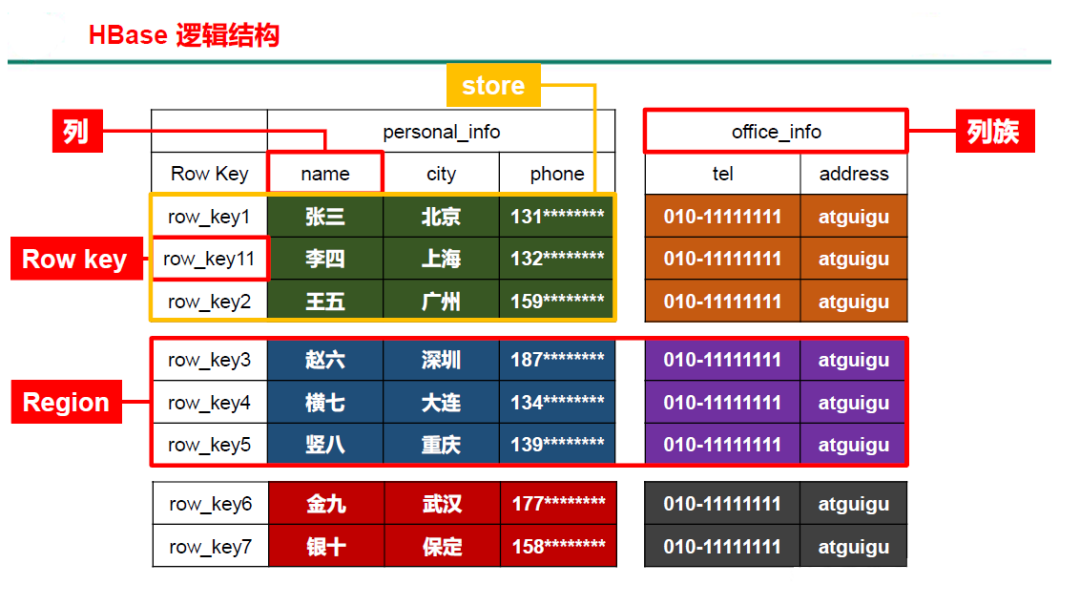
逻辑结构:
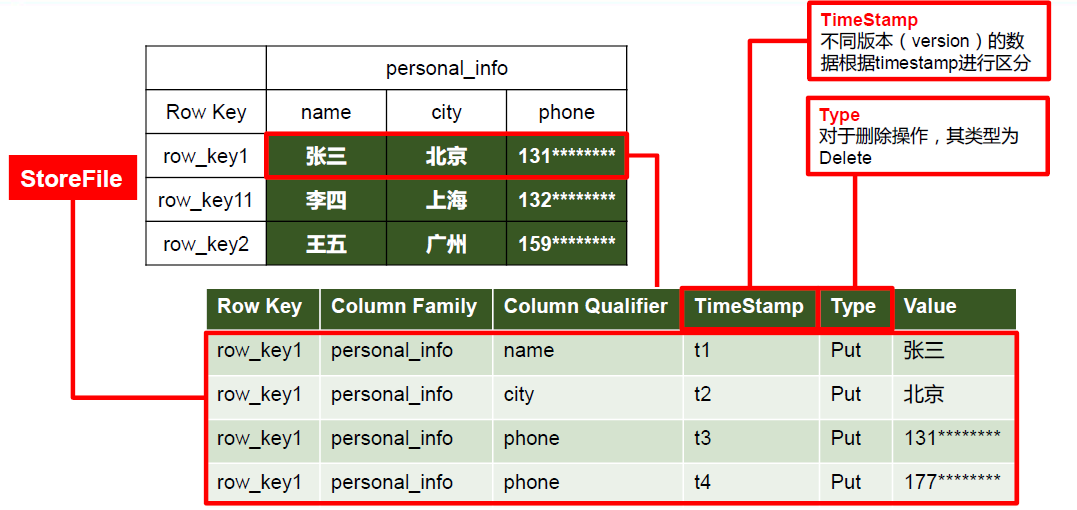
物理架构:

基本原理
Rowkey(行键):
- Table 的主键,Table 中的记录按照 Rowkey 的字典序进行排序。
Column Family(列族):
- 表中的每个列,都归属与某个列族。
- 列族是表的 Schema 的一部分,必须在使用表之前定义。
Timestamp(时间戳):
- 每次数据操作对应的时间戳,可以看作是数据的 Version 版本号。
Column(列):
- 列族下面的具体列。
- 属于某一个 ColumnFamily,类似于 MySQL 当中创建的具体的列。
Cell(单元格):
由
{rowkey, column, version}唯一确定的单元。
Cell 中的数据没有类型,全部是以字节数组进行存储。
如何支持海量数据的随机存取
1、利用了HDFS的分布式存储和Hadoop的分布式计算能力:
- 将数据存储在HDFS上,并利用Hadoop的MapReduce框架进行分布式计算,从而实现了高可扩展性和高并发性。
2、将数据按照行和列族的方式存储在HDFS上:
- 这种数据存储方式使得HBase能够实现高速的随机读写功能。
3、利用了LSM(Log-Structured Merge-Tree)算法:
- 该算法通过内存和顺序写磁盘的方式,使得随机写入成为可能,同时还能保证读取效率。
4、支持数据的自动分片和负载均衡:
- 可以支持PB级别的数据存储和处理,从而满足大规模数据的实时处理需求。
整体结构
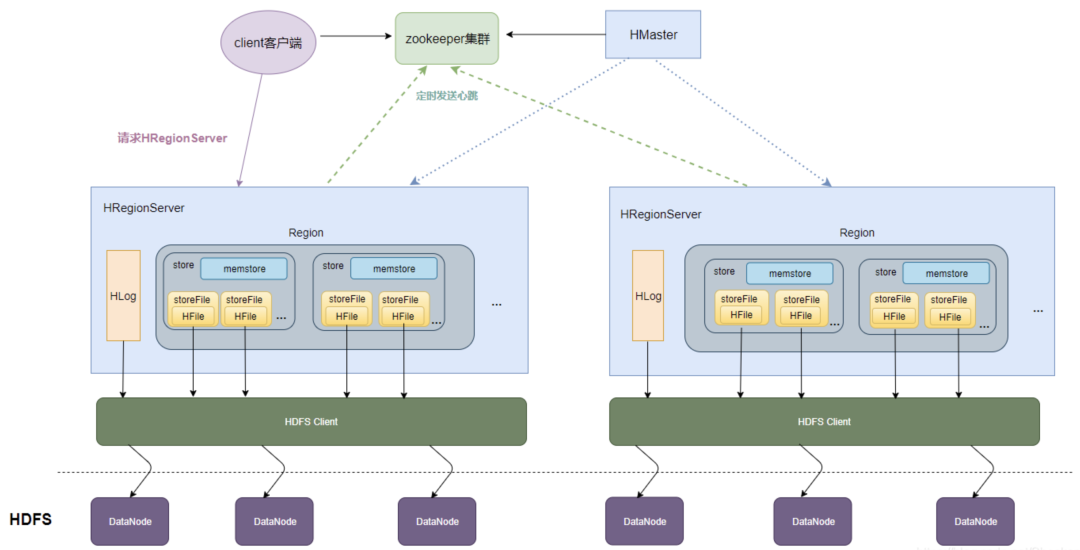
HMaster:
- HBase集群的主节点,负责监控RegionServer,处理Region分配和负载均衡。
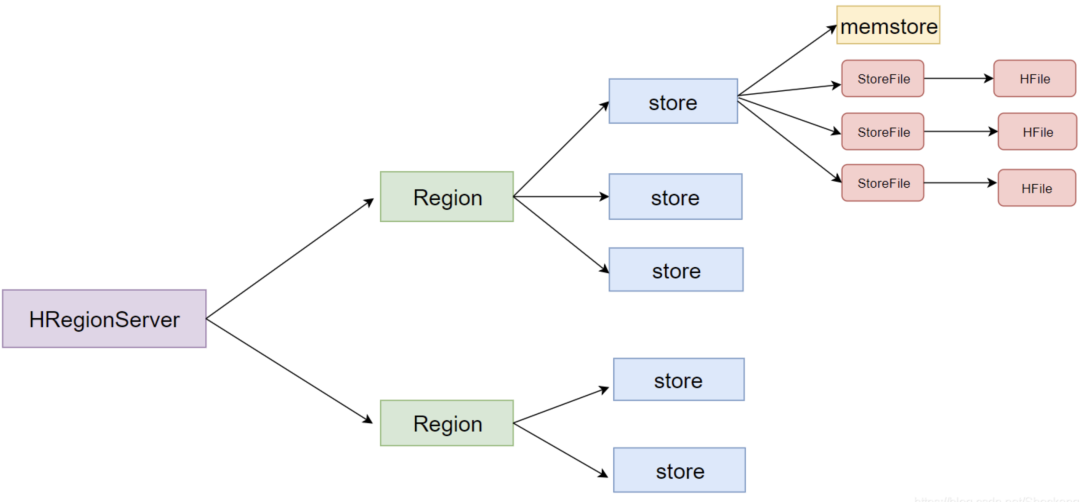
HRegionServer:
- 管理 Region,处理对所分配Region的IO请求,Region是表的分片,由多个Store组成。
Zookeeper:
- 维护HBase的运行状态信息,如Region分布信息等。
- HMaster和RegionServer都依赖Zookeeper。
HRegion:
- HBase表的分片,由一个或者多个Store组成,存储实际的表数据。
Store:
- Store以Column Family为单位存储数据,主要组成是MemStore和StoreFile(HFile)。
- 1个Column Family的数据存放在一个Store中,一个Region包含多个Store。
MemStore:
内存存储,用于临时存放写数据,达到阈值后刷入StoreFile。
- 数据会先写入到 MemStore 进行缓冲,然后再把数据刷到磁盘。
通过内存,也加快了读写速度。
StoreFile(HFile):
- 磁盘上面真正存放数据的文件。
HDFS:
- 用来持久化存储HFiles。
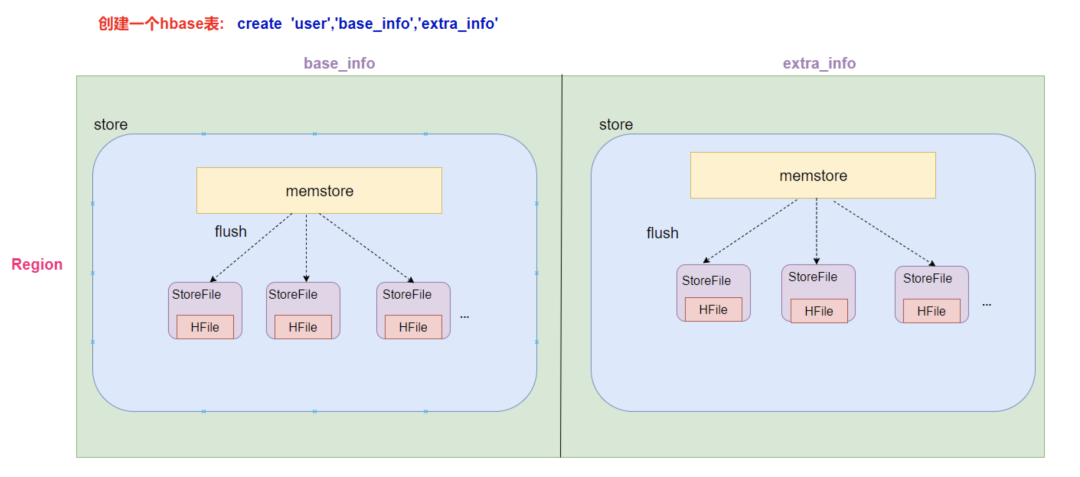
一个列族就划分成一个 Store,如果一个表中只有 1 个列族,那么每一个 Region 中只有一个 Store。
一个 Store 里面只有一个 MemStore。
一个 Store 里面有很多个 StoreFile, 最后数据是以很多个 HFile 文件保存在 HDFS 上。
- StoreFile是HFile的抽象对象。
- 每次 MemStore 刷写数据到磁盘,就生成对应的一个新的 HFile 文件出来。
负载均衡
HBase 官方目前支持两种负载均衡策略:
- SimpleLoadBalancer 策略和 StochasticLoadBalancer 策略。
SimpleLoadBalancer 策略:
这种策略能够保证每个 RegionServer 的 Region 个数基本相等。
假设集群中一共有 n 个 RegionServer,m 个 Region ,那么集群的平均负载就是 average = m/n。
- 这种策略能够保证所有 RegionServer 上的 Region 个数都在
[floor(average),ceil(average)]之间。
因此, SimpleLoadBalancer 策略中负载就是 Region 个数,集群负载迁移计划就是 Region 从个数较多的 RegionServer 上迁移到个数较少的 RegionServer 上。
虽然集群中每个 RegionServer 的 Region 个数都基本相同,但如果某台 RegionServer 上的 Region 全部都是热点数据,导致 90 %的读写请求还是落在了这台 RegionServer 上,这样没有达到负载均衡的目的。
StochasticLoadBalancer 策略:
它对于负载的定义不再是 Region 个数这么简单,而是由多种独立负载加权计算的复合值,这些独立负载包括:
- Region 个数,Region 负载,读请求数,写请求数,Storefile 大小,MemStore 大小,数据本地率,移动代价。
这些独立负载经过加权计算会得到一个代价值,系统使用这个代价值来评估当前 Region 分布是否均衡,越均衡代价值越低。
- HBase 通过不断随机挑选迭代来找到一组 Region 迁移计划,使得代价值最小。
Flush机制
MemStore的大小超过某个值的时候,会Flush到磁盘,默认为128M。
MemStore中的数据时间超过1小时,会Flush到磁盘。
HRegionServer的全局MemStore的大小超过某大小会触发Flush到磁盘,默认是堆大小的40%。
Compact机制
HBase需要在必要的时候将小的Store File合并成相对较大的Store File,这个过程为Compaction。
- 为了防止小文件过多,以保证查询效率。
在HBase中主要存在两种类型的Compaction合并。
Minor Compaction 小合并:
- 在将Store中多个HFile合并为一个HFile。
- 这个过程中,达到TTL(记录保留时间)会被移除,删除和更新的数据仅仅只是做了标记,并没有物理移除。
- 这种合并的触发频率很高。
Major Compaction 大合并:
合并Store中所有的HFile为一个HFile。
这个过程有删除标记的数据会被真正移除,同时超过单元格maxVersion的版本记录也会被删除。
合并频率比较低,默认7天执行一次,并且性能消耗非常大,建议生产关闭(设置为0),在应用空闲时间手动触发。
- 一般可以是手动控制进行合并,防止出现在业务高峰期。
Region拆分机制
Region 中存储的是大量的 Rowkey 数据,当 Region 中的数据条数过多的时候,直接影响查询效率。
- 当 Region 过大的时候,HBase 会拆分 Region。
HBase 的 Region Split 策略一共有以下几种。
ConstantSizeRegionSplitPolicy:
0.94版本前默认切分策略。
当Region大小大于某个阈值之后就会触发切分,一个Region等分为2个Region。
- 在生产线上这种切分策略有相当大的弊端:切分策略对于大表和小表没有明显的区分。
阈值设置较大对大表比较友好,但是小表就有可能不会触发分裂,极端情况下可能就1个。
如果设置较小则对小表友好,但一个大表就会在整个集群产生大量的Region,这对于集群的管理、资源使用、Failover不好。
IncreasingToUpperBoundRegionSplitPolicy:
0.94版本~2.0版本默认切分策略。
总体看和ConstantSizeRegionSplitPolicy思路相同,一个Region大小大于设置阈值就会触发切分。
- 但这个阈值并不是一个固定的值。
- 而是会在一定条件下不断调整,调整规则和Region所属表在当前RegionServer上的Region个数有关系。
Region Split的计算公式是:
RegionCount^3 * 128M * 2,当Region达到该size的时候进行split。
例如:
第一次split:
1^3 * 256 = 256MB
第二次split:
2^3 * 256 = 2048MB
第三次split:
3^3 * 256 = 6912MB
第四次split:
4^3 * 256 = 16384MB > 10GB,取较小的值10GB
后面每次split的size都是10GB了。
SteppingSplitPolicy:
2.0版本默认切分策略。
依然和待分裂Region所属表在当前RegionServer上的Region个数有关系。
如果Region个数等于1,切分阈值为
flush size * 2,否则为MaxRegionFileSize。
这种切分策略对于大集群中的大表。
小表会比 IncreasingToUpperBoundRegionSplitPolicy 更加友好,小表不会再产生大量的小Region,而是适可而止。
KeyPrefixRegionSplitPolicy:
根据RowKey的前缀对数据进行分组,这里是指定RowKey的前多少位作为前缀,比如RowKey都是16位的,指定前5位是前缀。
那么前5位相同的RowKey在进行region split的时候会分到相同的Region中。
DelimitedKeyPrefixRegionSplitPolicy:
保证相同前缀的数据在同一个Region中,例如RowKey的格式为:
userid_eventtype_eventid,指定的delimiter为_。
则split的的时候会确保userid相同的数据在同一个Region中。
DisabledRegionSplitPolicy:
不启用自动拆分,需要指定手动拆分。
预分区
当一个table刚被创建的时候,HBase默认的分配一个Region给table。
这时所有的读写请求都会访问到同一个RegionServer的同一个Region中。
这个时候就达不到负载均衡的效果了,集群中的其他RegionServer就可能会处于比较空闲的状态。
解决办法:
- 可以用预分区(
pre-splitting),在创建table的时候就配置好,生成多个Region。
如何预分区?
- 每一个Region维护着startRow与endRowKey。
- 如果加入的数据符合某个Region维护的RowKey范围,则该数据交给这个Region维护。
手动指定预分区:
create 'person','info1','info2',SPLITS => ['1000','2000','3000','4000']
Region定位
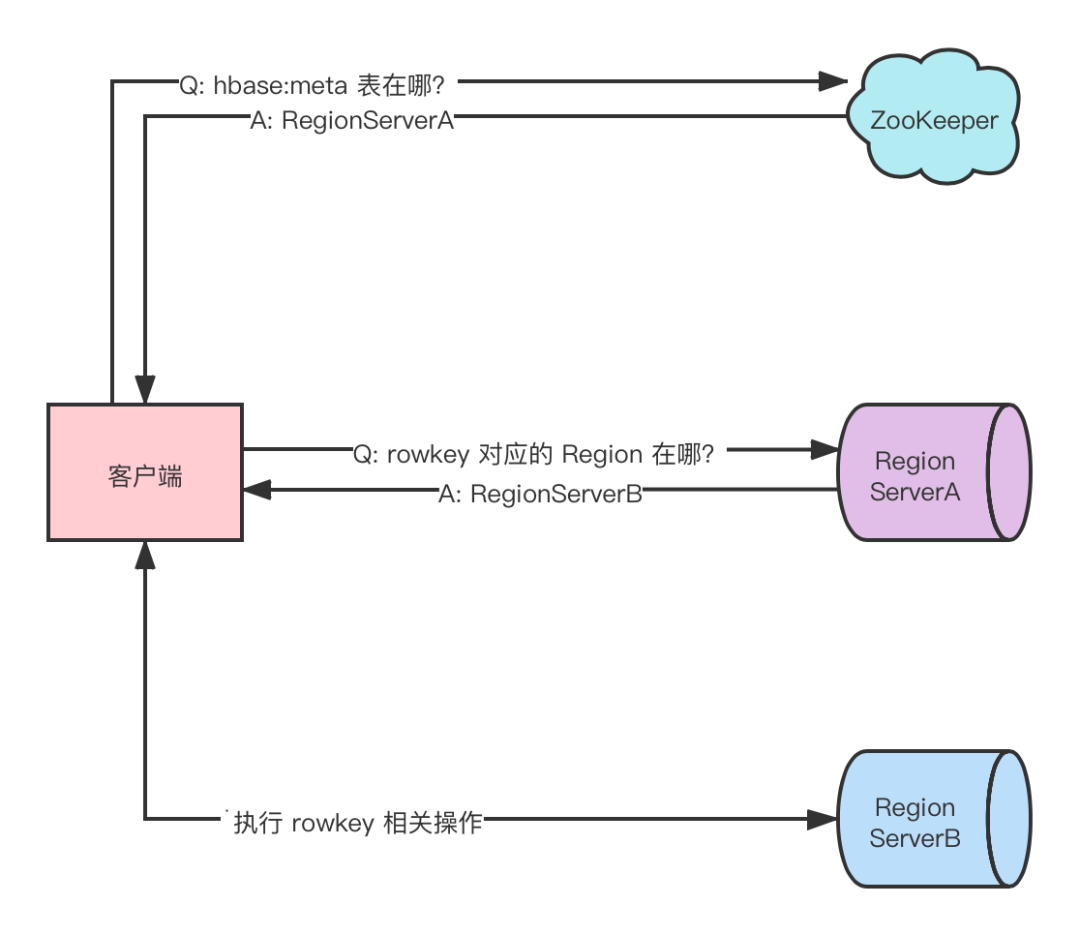
HBase 支持 put , get , delete 和 scan 等基础操作,所有这些操作的基础是 region 定位。
region 定位基本步骤:
客户端与 ZooKeeper 交互,查找
hbase:meta系统表所在的 Regionserver。
hbase:meta表维护了每个用户表中 rowkey 区间与 Region 存放位置的映射关系,具体如下:
rowkey : table name,start key,region id。
value : RegionServer 对象(保存了 RegionServer 位置信息等)。
客户端与
hbase:meta系统表所在 RegionServer 交互,获取 rowkey 所在的 RegionServer。
客户端与 rowkey 所在的 RegionServer 交互,执行该 rowkey 相关操作。
需要注意:
客户端首次执行读写操作时才需要定位
hbase:meta表的位置。
之后会将其缓存到本地,除非因 region 移动导致缓存失效,客户端才会重新读取
hbase:meta表位置,并更新缓存。
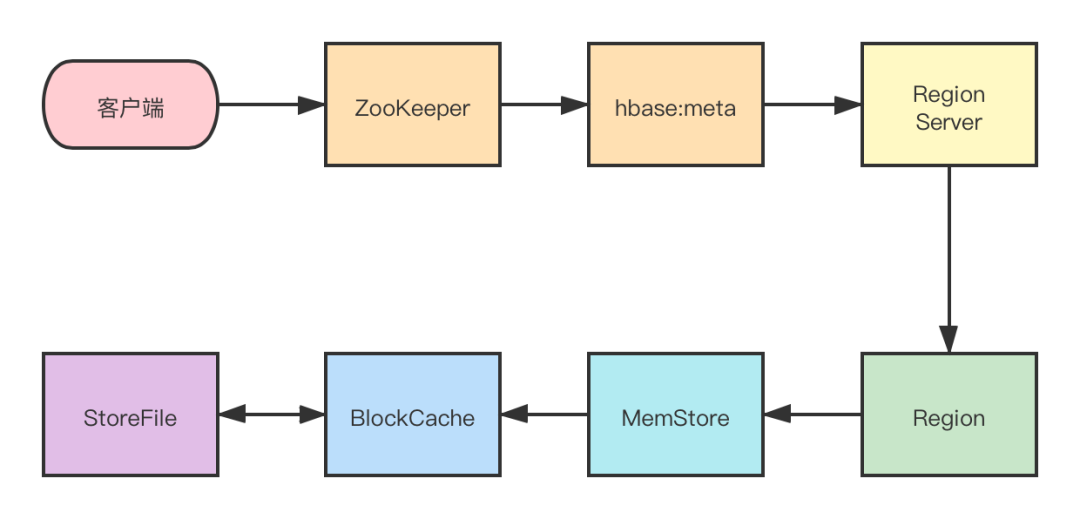
读写流程
读操作:
首先从 ZooKeeper 找到 meta 表的 region 位置,然后读取
hbase:meta表中的数据,hbase:meta表中存储了用户表的 region 信息。
根据要查询的 namespace 、表名和 rowkey 信息,找到写入数据对应的 Region 信息。
找到这个 Region 对应的 RegionServer ,然后发送请求。
查找对应的 Region。
先从 MemStore 查找数据,如果没有,再从 BlockCache 上读取。
- HBase 上 RegionServer 的内存分为两个部分:
- 一部分作为 MemStore,主要用来写。
- 另外一部分作为 BlockCache,主要用于读数据。
如果 BlockCache 中也没有找到,再到 StoreFile(HFile) 上进行读取。
- 从 StoreFile 中读取到数据之后,不是直接把结果数据返回给客户端,而是把数据先写入到 BlockCache 中,目的是为了加快后续的查询,然后在返回结果给客户端。
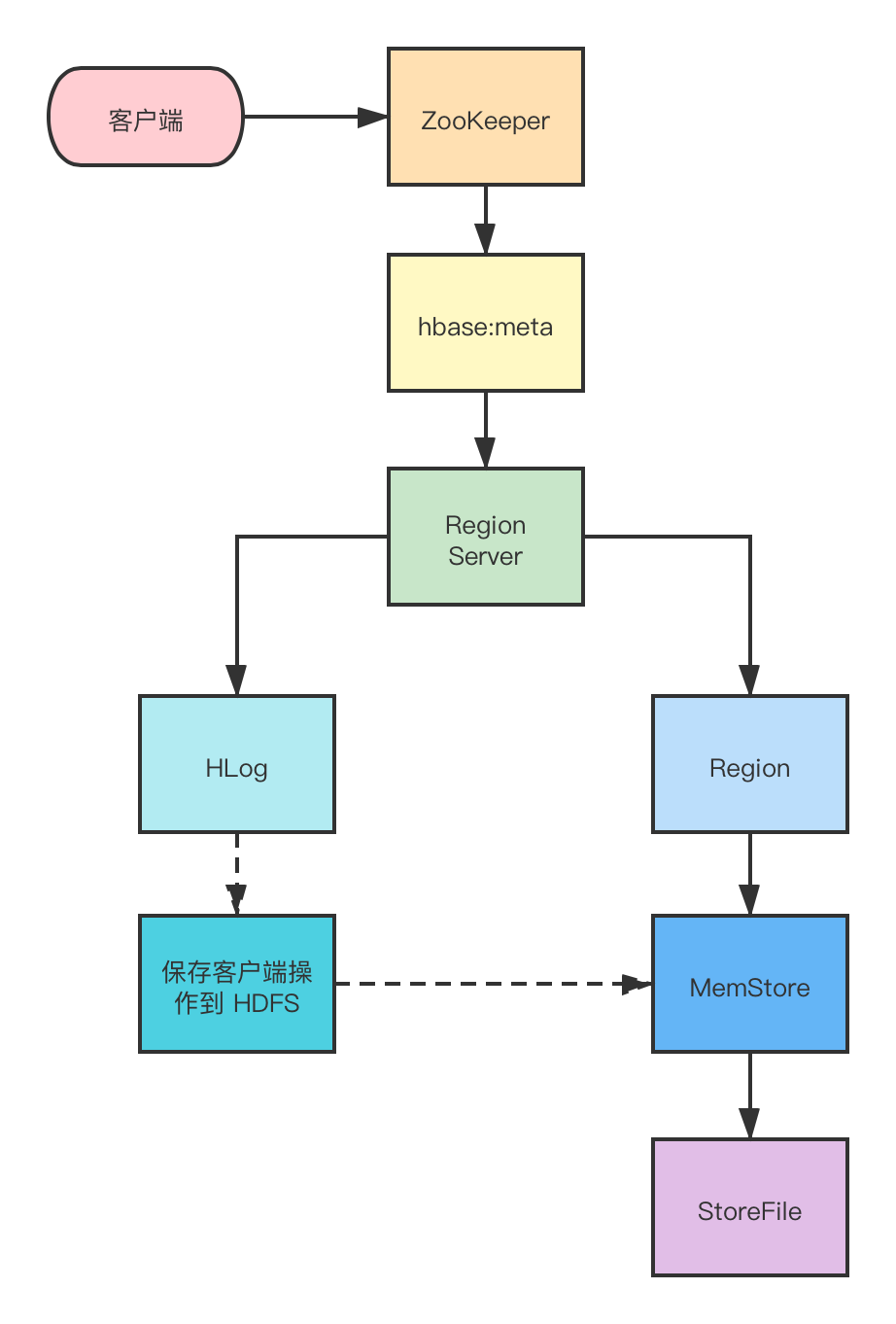
写操作:
首先从 ZooKeeper 找到
hbase:meta表的 Region 位置,然后读取hbase:meta表中的数据,hbase:meta表中存储了用户表的 Region 信息。
根据 namespace 、表名和 rowkey 信息找到写入数据对应的 Region 信息。
找到这个 Region 对应的 RegionServer ,然后发送请求。
把数据分别写到 HLog (WriteAheadLog)和 MemStore 各一份。
MemStore 达到阈值后把数据刷到磁盘,生成 StoreFile 文件。
删除 HLog 中的历史数据。
BulkLoad机制
用户数据位于 HDFS 中,业务需要定期将这部分海量数据导入 HBase 系统,以执行随机查询更新操作。
这种场景如果调用写入 API 进行处理,极有可能会给 RegionServer 带来较大的写人压力。
引起 RegionServer 频繁 flush,进而不断 compact、split,影响集群稳定性。
引起 RegionServer 频繁GC,影响集群稳定性。
消耗大量 CPU 资源、带宽资源、内存资源以及 IO 资源,与其他业务产生资源竞争。
在某些场景下,比如平均 KV 大小比较大的场景,会耗尽 RegionServer 的处理线程, 导致集群阻塞。
所以HBase提供了另一种将数据写入HBase集群的方法:BulkLoad。
常见问题
BulkLoad 首先使用 MapReduce 将待写入集群数据转换为 HFile 文件,再直接将这些 HFile 文件加载到在线集群中。
BulkLoad 没有将写请求发送给 RegionServer 处理,可以有效避免上述一系列问题。
热点问题
什么是热点?
检索 HBase 的记录首先要通过Row Key来定位数据行。
当大量的 Client 访问 HBase 集群的一个或少数几个节点,造成少数 Region Server 的读/写请求过多、负载过大,而其他Region Server 负载却很小,就造成了 热点 现象。
解决方案:
预分区:
- 目的让表的数据可以均衡的分散在集群中,而不是默认只有一个Region分布在集群的一个节点上。
加盐:
- 在Rowkey的前面增加随机数,具体就是给Rowkey分配一个随机前缀以使得它和之前的Rowkey的开头不同。
哈希:
- 哈希会使同一行永远用一个前缀加盐。
- 也可以使负载分散到整个集群,但是读是可以预测的。
- 使用确定的哈希可以让客户端重构完整的Rowkey,可以使用get操作准确获取某一个行数据。
反转:
- 反转固定长度或者数字格式的Rowkey。
- 这样可以使得Rowkey中经常改变的部分放在前面。
觉得有收获,希望帮忙点赞,转发下哈,谢谢,谢谢