
终于被我说清楚了!
文章内容比较长,大家可以耐心看下去,一定会有新的发现!

什么 SQL 语句会加行级锁?
InnoDB 引擎是支持行级锁的,而 MyISAM 引擎并不支持行级锁,所以后面的内容都是基于 InnoDB 引擎 的。
普通的 select 语句是不会对记录加锁的,因为它属于快照读,是通过 MVCC(多版本并发控制)实现的。
如果要在查询时对记录加行级锁,可以使用下面这两个方式,这两种查询会加锁的语句称为锁定读。
//对读取的记录加共享锁(S型锁)
select ... lock in share mode;
//对读取的记录加独占锁(X型锁)
select ... for update;
上面这两条语句必须在一个事务中,因为当事务提交了,锁就会被释放,所以在使用这两条语句的时候,要加上 begin 或者 start transaction 开启事务的语句。
除了上面这两条锁定读语句会加行级锁之外,update 和 delete 操作都会加行级锁,且锁的类型都是独占锁。
//对操作的记录加独占锁(X型锁)
updaet table .... where id = 1;
//对操作的记录加独占锁(X型锁)
delete from table where id = 1;
共享锁(S锁)满足读读共享,读写互斥。独占锁(X锁)满足写写互斥、读写互斥。

行级锁有哪些种类?
不同隔离级别下,行级锁的种类是不同的。
在读已提交隔离级别下,行级锁的种类只有记录锁,也就是仅仅把一条记录锁上。
在可重复读隔离级别下,行级锁的种类除了有记录锁,还有间隙锁(目的是为了避免幻读),所以行级锁的种类主要有三类:
Record Lock,记录锁,也就是仅仅把一条记录锁上; Gap Lock,间隙锁,锁定一个范围,但是不包含记录本身; Next-Key Lock:Record Lock + Gap Lock 的组合,锁定一个范围,并且锁定记录本身。
接下来,分别介绍这三种行级锁。
Record Lock
Record Lock 称为记录锁,锁住的是一条记录。而且记录锁是有 S 锁和 X 锁之分的:
当一个事务对一条记录加了 S 型记录锁后,其他事务也可以继续对该记录加 S 型记录锁(S 型与 S 锁兼容),但是不可以对该记录加 X 型记录锁(S 型与 X 锁不兼容); 当一个事务对一条记录加了 X 型记录锁后,其他事务既不可以对该记录加 S 型记录锁(S 型与 X 锁不兼容),也不可以对该记录加 X 型记录锁(X 型与 X 锁不兼容)。
举个例子,当一个事务执行了下面这条语句:
mysql > begin;
mysql > select * from t_test where id = 1 for update;
事务会对表中主键 id = 1 的这条记录加上 X 型的记录锁,这样其他事务就无法对这条记录进行修改和删除了。
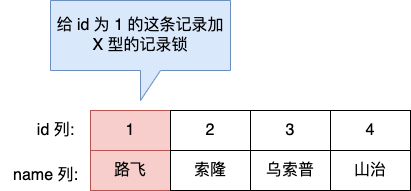
当事务执行 commit 后,事务过程中生成的锁都会被释放。
Gap Lock
Gap Lock 称为间隙锁,只存在于可重复读隔离级别,目的是为了解决可重复读隔离级别下幻读的现象。
假设,表中有一个范围 id 为(3,5)间隙锁,那么其他事务就无法插入 id = 4 这条记录了,这样就有效的防止幻读现象的发生。

间隙锁虽然存在 X 型间隙锁和 S 型间隙锁,但是并没有什么区别,间隙锁之间是兼容的,即两个事务可以同时持有包含共同间隙范围的间隙锁,并不存在互斥关系,因为间隙锁的目的是防止插入幻影记录而提出的。
Next-Key Lock
Next-Key Lock 称为临键锁,是 Record Lock + Gap Lock 的组合,锁定一个范围,并且锁定记录本身。
假设,表中有一个范围 id 为(3,5] 的 next-key lock,那么其他事务即不能插入 id = 4 记录,也不能修改 id = 5 这条记录。
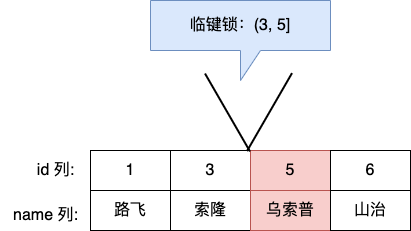
所以,next-key lock 即能保护该记录,又能阻止其他事务将新记录插入到被保护记录前面的间隙中。
next-key lock 是包含间隙锁+记录锁的,如果一个事务获取了 X 型的 next-key lock,那么另外一个事务在获取相同范围的 X 型的 next-key lock 时,是会被阻塞的。
比如,一个事务持有了范围为 (1, 10] 的 X 型的 next-key lock,那么另外一个事务在获取相同范围的 X 型的 next-key lock 时,就会被阻塞。
虽然相同范围的间隙锁是多个事务相互兼容的,但对于记录锁,我们是要考虑 X 型与 S 型关系,X 型的记录锁与 X 型的记录锁是冲突的。
MySQL 是怎么加行级锁的?
行级锁加锁规则比较复杂,不同的场景,加锁的形式是不同的。
加锁的对象是索引,加锁的基本单位是 next-key lock,它是由记录锁和间隙锁组合而成的,next-key lock 是前开后闭区间,而间隙锁是前开后开区间。
但是,next-key lock 在一些场景下会退化成记录锁或间隙锁。
那到底是什么场景呢?
这次会以下面这个表结构来进行实验说明:
CREATE TABLE `user` (
`id` bigint NOT NULL AUTO_INCREMENT,
`name` varchar(30) COLLATE utf8mb4_unicode_ci NOT NULL,
`age` int NOT NULL,
PRIMARY KEY (`id`),
KEY `index_age` (`age`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
其中,id 是主键索引(唯一索引),age 是普通索引(非唯一索引),name 是普通的列。
表中的有这些行记录:
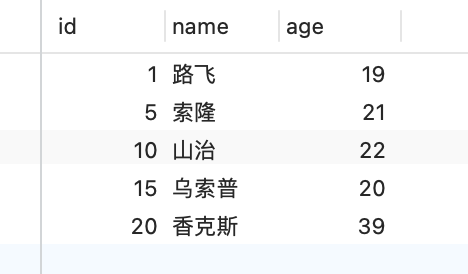
这次实验环境的 MySQL 版本是 8.0.26,隔离级别是「可重复读」。
不同版本的加锁规则可能是不同的,但是大体上是相同的。
唯一索引等值查询
当我们用唯一索引进行等值查询的时候,查询的记录存不存在,加锁的规则也会不同:
当查询的记录是「存在」的,在索引树上定位到这一条记录后,将该记录的索引中的 next-key lock 会退化成「记录锁」。 当查询的记录是「不存在」的,则会在索引树找到第一条大于该查询记录的记录,然后将该记录的索引中的 next-key lock 会退化成「间隙锁」。
接下里用两个案例来说明。
1、记录存在的情况
假设事务 A 执行了这条等值查询语句,查询的记录是「存在」于表中的。
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from user where id = 1 for update;
+----+--------+-----+
| id | name | age |
+----+--------+-----+
| 1 | 路飞 | 19 |
+----+--------+-----+
1 row in set (0.02 sec)
那么,事务 A 会为 id 为 1 的这条记录就会加上 X 型的记录锁。

接下来,如果有其他事务,对 id 为 1 的记录进行更新或者删除操作的话,这些操作都会被阻塞,因为更新或者删除操作也会对记录加 X 型的记录锁,而 X 锁和 X 锁之间是互斥关系。
比如,下面这个例子:
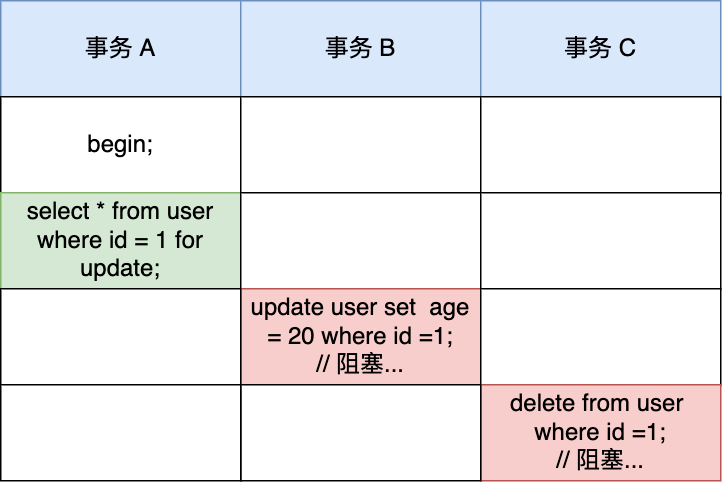
因为事务 A 对 id = 1的记录加了 X 型的记录锁,所以事务 B 在修改 id=1 的记录时会被阻塞,事务 C 在删除 id=1 的记录时也会被阻塞。
有什么命令可以分析加了什么锁?
我们可以通过 select * from performance_schema.data_locks\G; 这条语句,查看事务执行 SQL 过程中加了什么锁。
我们以前面的事务 A 作为例子,分析下下它加了什么锁。
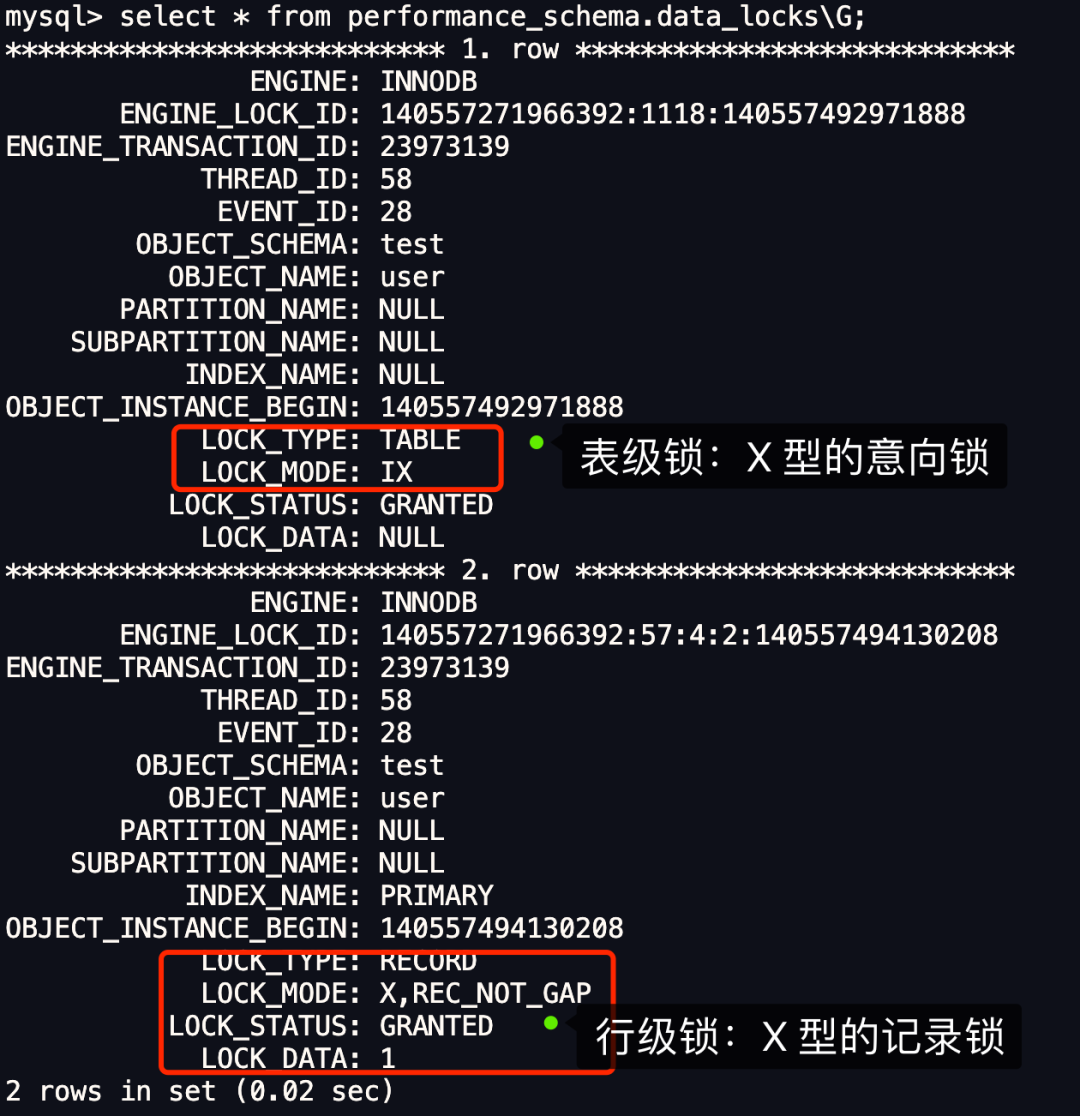
从上图可以看到,共加了两个锁,分别是:
表锁:X 类型的意向锁; 行锁:X 类型的记录锁;
这里我们重点关注行级锁,图中 LOCK_TYPE 中的 RECORD 表示行级锁,而不是记录锁的意思。
通过 LOCK_MODE 可以确认是 next-key 锁,还是间隙锁,还是记录锁:
如果 LOCK_MODE 为 X,说明是 next-key 锁;如果 LOCK_MODE 为 X, REC_NOT_GAP,说明是记录锁;如果 LOCK_MODE 为 X, GAP,说明是间隙锁;
因此,此时事务 A 在 id = 1 记录的主键索引上加的是记录锁,锁住的范围是 id 为 1 的这条记录。这样其他事务就无法对 id 为 1 的这条记录进行更新和删除操作了。
从这里我们也可以得知,加锁的对象是针对索引,因为这里查询语句扫描的 B+ 树是聚簇索引树,即主键索引树,所以是对主键索引加锁。将对应记录的主键索引加 记录锁后,就意味着其他事务无法对该记录进行更新和删除操作了。
2、记录不存在的情况
假设事务 A 执行了这条等值查询语句,查询的记录是「不存在」于表中的。
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from user where id = 2 for update;
Empty set (0.03 sec)
接下来,通过 select * from performance_schema.data_locks\G; 这条语句,查看事务执行 SQL 过程中加了什么锁。
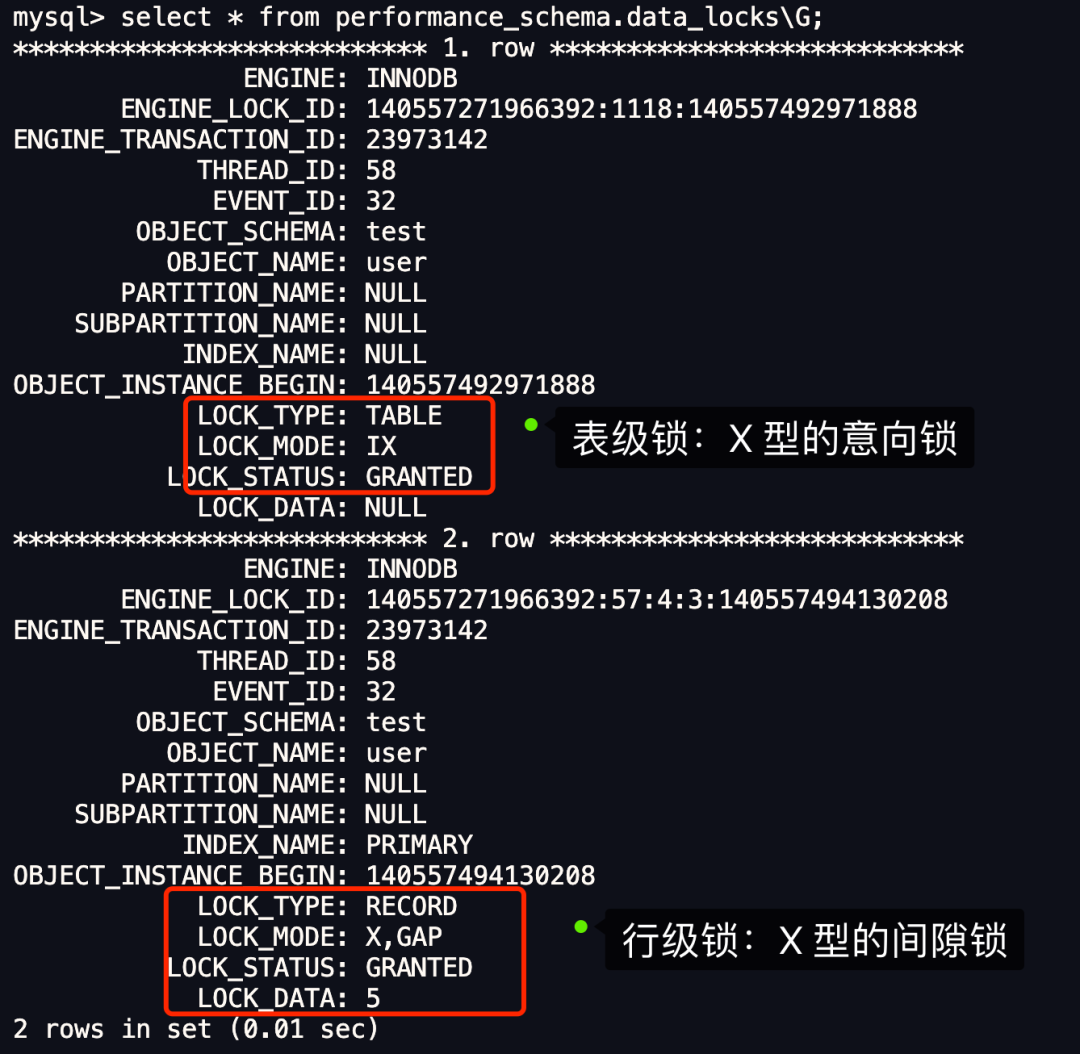
从上图可以看到,共加了两个锁,分别是:
表锁:X 类型的意向锁; 行锁:X 类型的间隙锁;
因此,此时事务 A 在 id = 5 记录的主键索引上加的是间隙锁,锁住的范围是 (1, 5)。
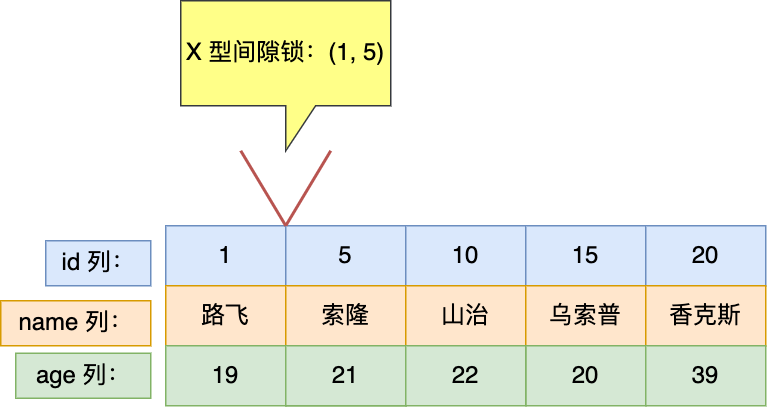
接下来,如果有其他事务插入 id 值为 2、3、4 这一些记录的话,这些插入语句都会发生阻塞。
注意,如果其他事务插入的 id = 1 或者 id = 5 的记录话,并不会发生阻塞,而是报主键冲突的错误,因为表中已经存在 id = 1 和 id = 5 的记录了。
比如,下面这个例子:

因为事务 A 在 id = 5 记录的主键索引上加了范围为 (1, 5) 的 X 型间隙锁,所以事务 B 在插入一条 id 为 3 的记录时会被阻塞住,即无法插入 id = 3 的记录。
间隙锁的范围
(1, 5),是怎么确定的?
根据我的经验,如果 LOCK_MODE 是 next-key 锁或者间隙锁,那么 LOCK_DATA 就表示锁的范围「右边界」,此次的事务 A 的 LOCK_DATA 是 5。
然后锁范围的「左边界」是表中 id 为 5 的上一条记录的 id 值,即 1。
因此,间隙锁的范围(1, 5)。
唯一索引范围查询
范围查询和等值查询的加锁规则是不同的。
当唯一索引进行范围查询时,会对每一个扫描到的索引加 next-key 锁,然后如果遇到下面这些情况,会退化成记录锁或者间隙锁:
情况一:针对「大于等于」的范围查询,因为存在等值查询的条件,那么如果等值查询的记录是存在于表中,那么该记录的索引中的 next-key 锁会退化成记录锁。 情况二:针对「小于或者小于等于」的范围查询,要看条件值的记录是否存在于表中: 当条件值的记录不在表中,那么不管是「小于」还是「小于等于」条件的范围查询,扫描到终止范围查询的记录时,该记录的索引的 next-key 锁会退化成间隙锁,其他扫描到的记录,都是在这些记录的索引上加 next-key 锁。 当条件值的记录在表中,如果是「小于」条件的范围查询,扫描到终止范围查询的记录时,该记录的索引的 next-key 锁会退化成间隙锁,其他扫描到的记录,都是在这些记录的索引上加 next-key 锁;如果「小于等于」条件的范围查询,扫描到终止范围查询的记录时,该记录的索引 next-key 锁不会退化成间隙锁。其他扫描到的记录,都是在这些记录的索引上加 next-key 锁。
接下来,通过几个实验,才验证我上面说的结论。
1、针对「大于或者大于等于」的范围查询
实验一:针对「大于」的范围查询的情况。
假设事务 A 执行了这条范围查询语句:
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from user where id > 15 for update;
+----+-----------+-----+
| id | name | age |
+----+-----------+-----+
| 20 | 香克斯 | 39 |
+----+-----------+-----+
1 row in set (0.01 sec)
事务 A 加锁变化过程如下:
最开始要找的第一行是 id = 20,由于查询该记录不是一个等值查询(不是大于等于条件查询),所以对该主键索引加的是范围为 (15, 20] 的 next-key 锁; 由于是范围查找,就会继续往后找存在的记录,虽然我们看见表中最后一条记录是 id = 20 的记录,但是实际在 Innodb 存储引擎中,会用一个特殊的记录来标识最后一条记录,该特殊的记录的名字叫 supremum pseudo-record ,所以扫描第二行的时候,也就扫描到了这个特殊记录的时候,会对该主键索引加的是范围为 (20, +∞] 的 next-key 锁。 停止扫描。
可以得知,事务 A 在主键索引上加了两个 X 型 的 next-key 锁:
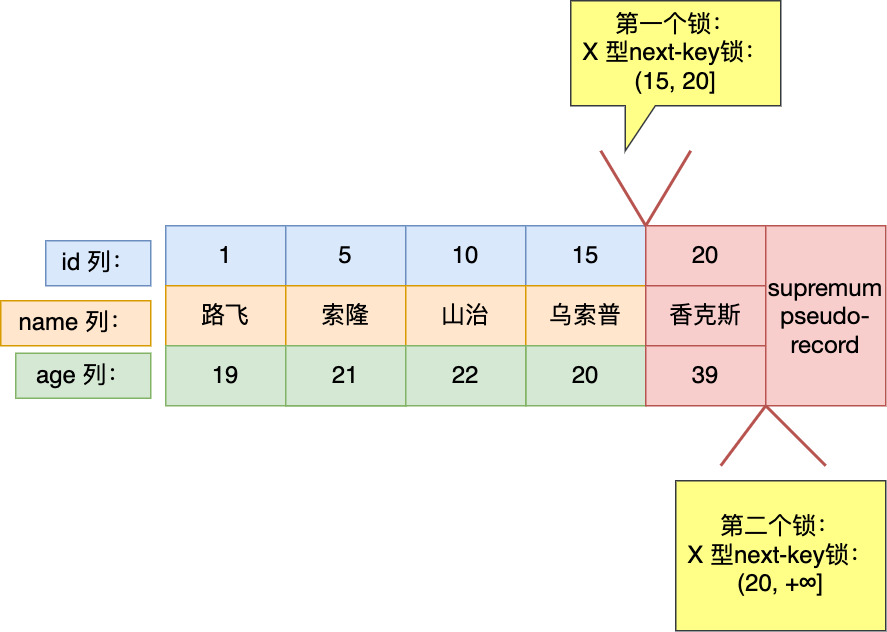
在 id = 20 这条记录的主键索引上,加了范围为 (15, 20] 的 next-key 锁,意味着其他事务即无法更新或者删除 id = 20 的记录,同时无法插入 id 值为 16、17、18、19 的这一些新记录。 在特殊记录( supremum pseudo-record)的主键索引上,加了范围为 (20, +∞] 的 next-key 锁,意味着其他事务无法插入 id 值大于 20 的这一些新记录。
我们也可以通过 select * from performance_schema.data_locks\G; 这条语句来看看事务 A 加了什么锁。
输出结果如下,我这里只截取了行级锁的内容。
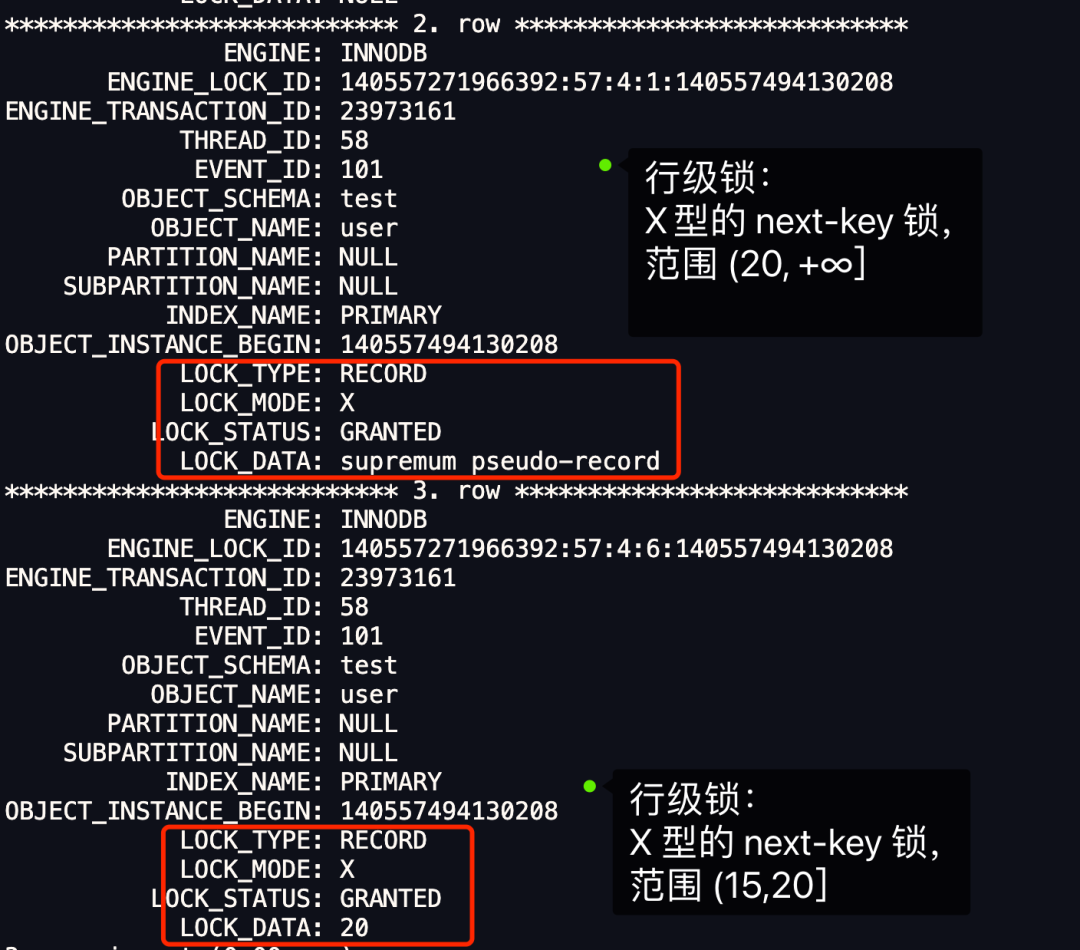
从上图中的分析中,也可以得到事务 A 在主键索引上加了两个 X 型 的next-key 锁:
在 id = 20 这条记录的主键索引上,加了范围为 (15, 20] 的 next-key 锁,意味着其他事务即无法更新或者删除 id = 20 的记录,同时无法插入 id 值为 16、17、18、19 的这一些新记录。 在特殊记录( supremum pseudo-record)的主键索引上,加了范围为 (20, +∞] 的 next-key 锁,意味着其他事务无法插入 id 值大于 20 的这一些新记录。
实验二:针对「大于等于」的范围查询的情况。
假设事务 A 执行了这条范围查询语句:
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from user where id >= 15 for update;
+----+-----------+-----+
| id | name | age |
+----+-----------+-----+
| 15 | 乌索普 | 20 |
| 20 | 香克斯 | 39 |
+----+-----------+-----+
2 rows in set (0.00 sec)
事务 A 加锁变化过程如下:
最开始要找的第一行是 id = 15,由于查询该记录是一个等值查询(等于 15),所以该主键索引的 next-key 锁会退化成记录锁,也就是仅锁住 id = 15 这一行记录。 由于是范围查找,就会继续往后找存在的记录,扫描到的第二行是 id = 20,于是对该主键索引加的是范围为 (15, 20] 的 next-key 锁; 接着扫描到第三行的时候,扫描到了特殊记录( supremum pseudo-record),于是对该主键索引加的是范围为 (20, +∞] 的 next-key 锁。 停止扫描。
可以得知,事务 A 在主键索引上加了三个 X 型 的锁,分别是:

在 id = 15 这条记录的主键索引上,加了记录锁,范围是 id = 15 这一行记录;意味着其他事务无法更新或者删除 id = 15 的这一条记录; 在 id = 20 这条记录的主键索引上,加了 next-key 锁,范围是 (15, 20] 。意味着其他事务即无法更新或者删除 id = 20 的记录,同时无法插入 id 值为 16、17、18、19 的这一些新记录。 在特殊记录( supremum pseudo-record)的主键索引上,加了 next-key 锁,范围是 (20, +∞] 。意味着其他事务无法插入 id 值大于 20 的这一些新记录。
我们也可以通过 select * from performance_schema.data_locks\G; 这条语句来看看事务 A 加了什么锁。
输出结果如下,我这里只截取了行级锁的内容。

通过前面这个实验,我们证明了:
针对「大于等于」条件的唯一索引范围查询的情况下, 如果条件值的记录存在于表中,那么由于查询该条件值的记录是包含一个等值查询的操作,所以该记录的索引中的 next-key 锁会退化成记录锁。
2、针对「小于或者小于等于」的范围查询
实验一:针对「小于」的范围查询时,查询条件值的记录「不存在」表中的情况。
假设事务 A 执行了这条范围查询语句,注意查询条件值的记录(id 为 6)并不存在于表中。
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from user where id < 6 for update;
+----+--------+-----+
| id | name | age |
+----+--------+-----+
| 1 | 路飞 | 19 |
| 5 | 索隆 | 21 |
+----+--------+-----+
3 rows in set (0.00 sec)
事务 A 加锁变化过程如下:
最开始要找的第一行是 id = 1,于是对该主键索引加的是范围为 (-∞, 1] 的 next-key 锁; 由于是范围查找,就会继续往后找存在的记录,扫描到的第二行是 id = 5,所以对该主键索引加的是范围为 (1, 5] 的 next-key 锁; 由于扫描到的第二行记录(id = 5),满足 id < 6 条件,而且也没有达到终止扫描的条件,接着会继续扫描。 扫描到的第三行是 id = 10,该记录不满足 id < 6 条件的记录,所以 id = 10 这一行记录的锁会退化成间隙锁,于是对该主键索引加的是范围为 (5, 10) 的间隙锁。 由于扫描到的第三行记录(id = 10),不满足 id < 6 条件,达到了终止扫描的条件,于是停止扫描。
从上面的分析中,可以得知事务 A 在主键索引上加了三个 X 型的锁:

在 id = 1 这条记录的主键索引上,加了范围为 (-∞, 1] 的 next-key 锁,意味着其他事务即无法更新或者删除 id = 1 的这一条记录,同时也无法插入 id 小于 1 的这一些新记录。 在 id = 5 这条记录的主键索引上,加了范围为 (1, 5] 的 next-key 锁,意味着其他事务即无法更新或者删除 id = 5 的这一条记录,同时也无法插入 id 值为 2、3、4 的这一些新记录。 在 id = 10 这条记录的主键索引上,加了范围为 (5, 10) 的间隙锁,意味着其他事务无法插入 id 值为 6、7、8、9 的这一些新记录。
我们也可以通过 select * from performance_schema.data_locks\G; 这条语句来看看事务 A 加了什么锁。
输出结果如下,我这里只截取了行级锁的内容。
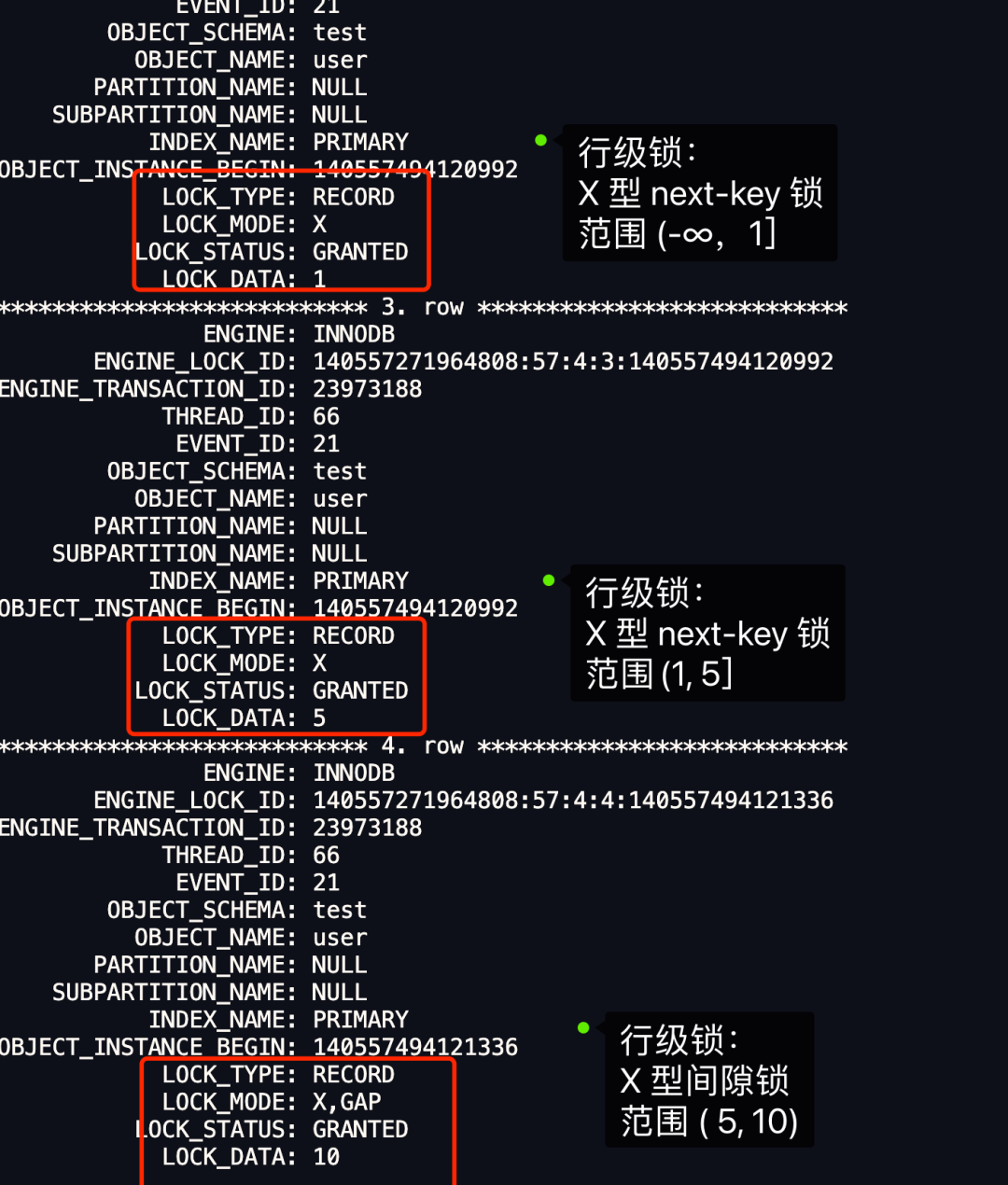
从上图中的分析中,也可以得知事务 A 在主键索引加的三个锁,就是我们前面分析出那三个锁。
虽然这次范围查询的条件是「小于」,但是查询条件值的记录不存在于表中( id 为 6 的记录不在表中),所以如果事务 A 的范围查询的条件改成 <= 6 的话,加的锁还是和范围查询条件为 < 6 是一样的。 大家自己也验证下这个结论。
因此,针对「小于或者小于等于」的唯一索引范围查询,如果条件值的记录不在表中,那么不管是「小于」还是「小于等于」的范围查询,扫描到终止范围查询的记录时,该记录中索引的 next-key 锁会退化成间隙锁,其他扫描的记录,则是在这些记录的索引上加 next-key 锁。
实验二:针对「小于等于」的范围查询时,查询条件值的记录「存在」表中的情况。
假设事务 A 执行了这条范围查询语句,注意查询条件值的记录(id 为 5)存在于表中。
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from user where id <= 5 for update;
+----+--------+-----+
| id | name | age |
+----+--------+-----+
| 1 | 路飞 | 19 |
| 5 | 索隆 | 21 |
+----+--------+-----+
2 rows in set (0.00 sec)
事务 A 加锁变化过程如下:
最开始要找的第一行是 id = 1,于是对该记录加的是范围为 (-∞, 1] 的 next-key 锁; 由于是范围查找,就会继续往后找存在的记录,扫描到的第二行是 id = 5,于是对该记录加的是范围为 (1, 5] 的 next-key 锁。 由于主键索引具有唯一性,不会存在两个 id = 5 的记录,所以不会再继续扫描,于是停止扫描。
从上面的分析中,可以得到事务 A 在主键索引上加了 2 个 X 型的锁:
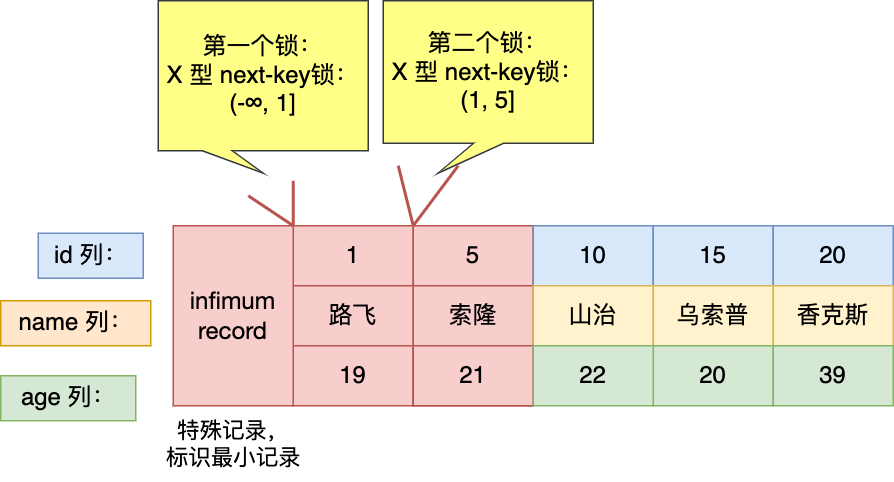
在 id = 1 这条记录的主键索引上,加了范围为 (-∞, 1] 的 next-key 锁。意味着其他事务即无法更新或者删除 id = 1 的这一条记录,同时也无法插入 id 小于 1 的这一些新记录。 在 id = 5 这条记录的主键索引上,加了范围为 (1, 5] 的 next-key 锁。意味着其他事务即无法更新或者删除 id = 5 的这一条记录,同时也无法插入 id 值为 2、3、4 的这一些新记录。
我们也可以通过 select * from performance_schema.data_locks\G; 这条语句来看看事务 A 加了什么锁。
输出结果如下,我这里只截取了行级锁的内容。
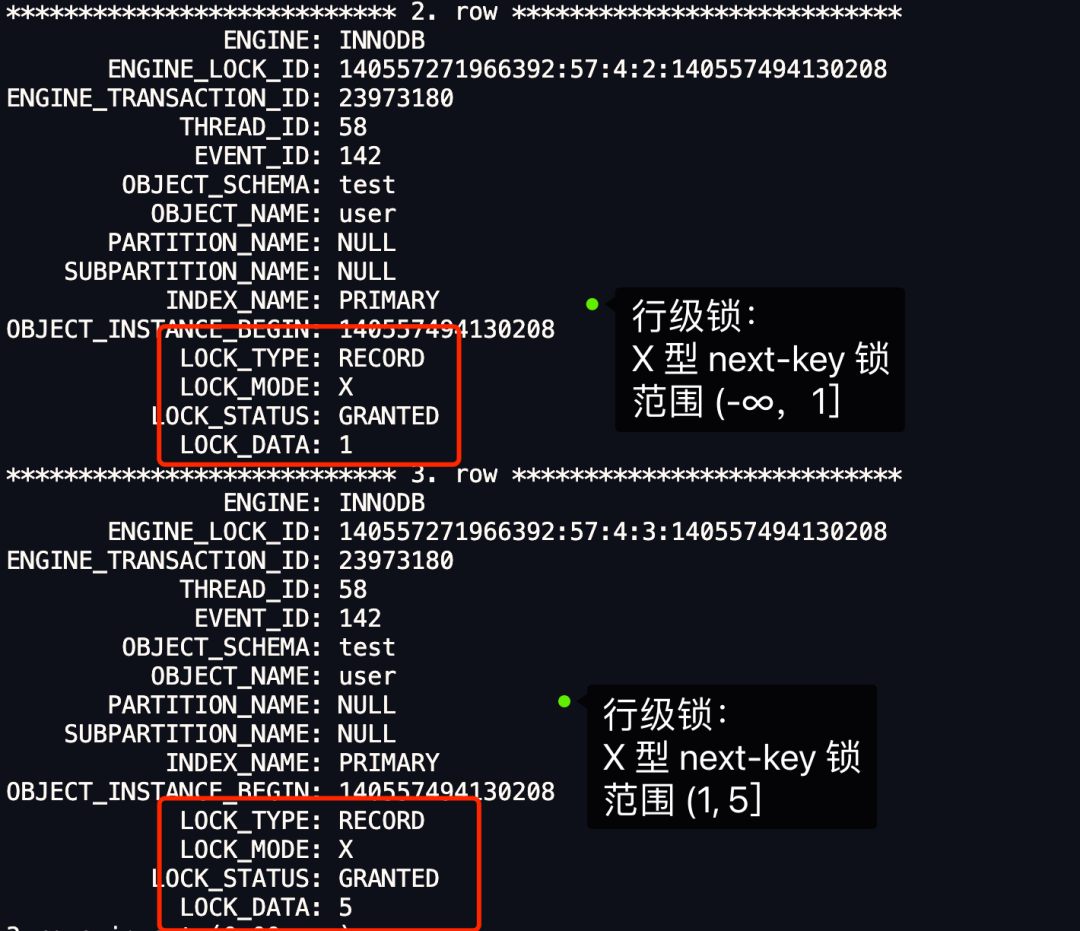
从上图中的分析中,可以得到事务 A 在主键索引上加了两个 X 型 next-key 锁,分别是:
在 id = 1 这条记录的主键索引上,加了范围为 (-∞, 1] 的 next-key 锁; 在 id = 5 这条记录的主键索引上,加了范围为(1, 5 ] 的 next-key 锁。
实验三:再来看针对「小于」的范围查询时,查询条件值的记录「存在」表中的情况。
如果事务 A 的查询语句是小于的范围查询,且查询条件值的记录(id 为 5)存在于表中。
select * from user where id < 5 for update;
事务 A 加锁变化过程如下:
最开始要找的第一行是 id = 1,于是对该记录加的是范围为 (-∞, 1] 的 next-key 锁; 由于是范围查找,就会继续往后找存在的记录,扫描到的第二行是 id = 5,该记录是第一条不满足 id < 5 条件的记录,于是**该记录的锁会退化为间隙锁,锁范围是 (1,5)**。 由于找到了第一条不满足 id < 5 条件的记录,于是停止扫描。
可以得知,此时事务 A 在主键索引上加了两种 X 型锁:
.png)
在 id = 1 这条记录的主键索引上,加了范围为 (-∞, 1] 的 next-key 锁,意味着其他事务即无法更新或者删除 id = 1 的这一条记录,同时也无法插入 id 小于 1 的这一些新记录。
在 id = 5 这条记录的主键索引上,加了范围为 (1,5) 的间隙锁,意味着其他事务无法插入 id 值为 2、3、4 的这一些新记录。
我们也可以通过 select * from performance_schema.data_locks\G; 这条语句来看看事务 A 加了什么锁。
输出结果如下,我这里只截取了行级锁的内容。
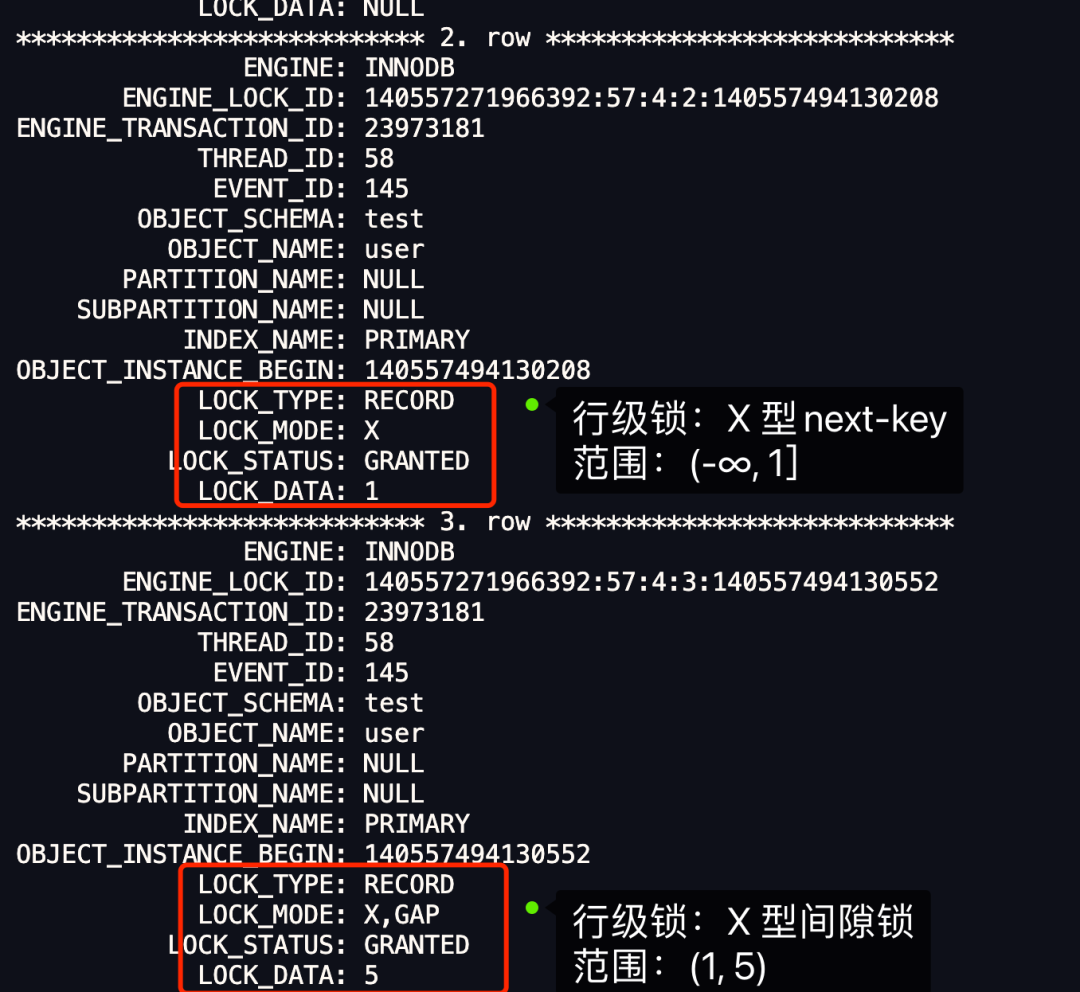
从上图中的分析中,可以得到事务 A 在主键索引上加了 X 型的范围为 (-∞, 1] 的 next-key 锁,和 X 型的范围为 (1, 5) 的间隙锁。
因此,通过前面这三个实验,可以得知。
在针对「小于或者小于等于」的唯一索引(主键索引)范围查询时,存在这两种情况会将索引的 next-key 锁会退化成间隙锁的:
当条件值的记录「不在」表中时,那么不管是「小于」还是「小于等于」条件的范围查询,扫描到终止范围查询的记录时,该记录的主键索引中的 next-key 锁会退化成间隙锁,其他扫描到的记录,都是在这些记录的主键索引上加 next-key 锁。 当条件值的记录「在」表中时: 如果是「小于」条件的范围查询,扫描到终止范围查询的记录时,该记录的主键索引中的 next-key 锁会退化成间隙锁,其他扫描到的记录,都是在这些记录的主键索引上,加 next-key 锁。 如果是「小于等于」条件的范围查询,扫描到终止范围查询的记录时,该记录的主键索引中的 next-key 锁「不会」退化成间隙锁,其他扫描到的记录,都是在这些记录的主键索引上加 next-key 锁。
非唯一索引等值查询
当我们用非唯一索引进行等值查询的时候,因为存在两个索引,一个是主键索引,一个是非唯一索引(二级索引),所以在加锁时,同时会对这两个索引都加锁,但是对主键索引加锁的时候,只有满足查询条件的记录才会对它们的主键索引加锁。
针对非唯一索引等值查询时,查询的记录存不存在,加锁的规则也会不同:
当查询的记录「存在」时,由于不是唯一索引,所以肯定存在索引值相同的记录,于是非唯一索引等值查询的过程是一个扫描的过程,直到扫描到第一个不符合条件的二级索引记录就停止扫描,然后在扫描的过程中,对扫描到的二级索引记录加的是 next-key 锁,而对于第一个不符合条件的二级索引记录,该二级索引的 next-key 锁会退化成间隙锁。同时,在符合查询条件的记录的主键索引上加记录锁。 当查询的记录「不存在」时,扫描到第一条不符合条件的二级索引记录,该二级索引的 next-key 锁会退化成间隙锁。因为不存在满足查询条件的记录,所以不会对主键索引加锁。
接下里用两个实验来说明。
1、记录存在的情况
实验一:针对非唯一索引等值查询时,查询的值存在的情况。
假设事务 A 对非唯一索引(age)进行了等值查询,且表中存在 age = 22 的记录。
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from user where age = 22 for update;
+----+--------+-----+
| id | name | age |
+----+--------+-----+
| 10 | 山治 | 22 |
+----+--------+-----+
1 row in set (0.00 sec)
事务 A 加锁变化过程如下:
由于不是唯一索引,所以肯定存在值相同的记录,于是非唯一索引等值查询的过程是一个扫描的过程,最开始要找的第一行是 age = 22,于是对该二级索引记录加上范围为 (21, 22] 的 next-key 锁。同时,因为 age = 22 符合查询条件,于是对 age = 22 的记录的主键索引加上记录锁,即对 id = 10 这一行加记录锁。 接着继续扫描,扫描到的第二行是 age = 39,该记录是第一个不符合条件的二级索引记录,所以该二级索引的 next-key 锁会退化成间隙锁,范围是 (22, 39)。 停止查询。
可以看到,事务 A 对主键索引和二级索引都加了 X 型的锁:

主键索引: 在 id = 10 这条记录的主键索引上,加了记录锁,意味着其他事务无法更新或者删除 id = 10 的这一行记录。 二级索引(非唯一索引): 在 age = 22 这条记录的二级索引上,加了范围为 (21, 22] 的 next-key 锁,意味着其他事务无法更新或者删除 age = 22 的这一些新记录,不过对于插入 age = 22 记录的语句,在一些情况是可以成功插入的,而一些情况则无法成功插入,具体哪些情况,会在后面说。 在 age = 39 这条记录的二级索引上,加了范围 (22, 39) 的间隙锁。意味着其他事务无法插入 age 值为 23、24、..... 、38 的这一些新记录。不过对于插入 age = 39 记录的语句,在一些情况是可以成功插入的,而一些情况则无法成功插入,具体哪些情况,会在后面说。
我们也可以通过 select * from performance_schema.data_locks\G; 这条语句来看看事务 A 加了什么锁。
输出结果如下,我这里只截取了行级锁的内容。
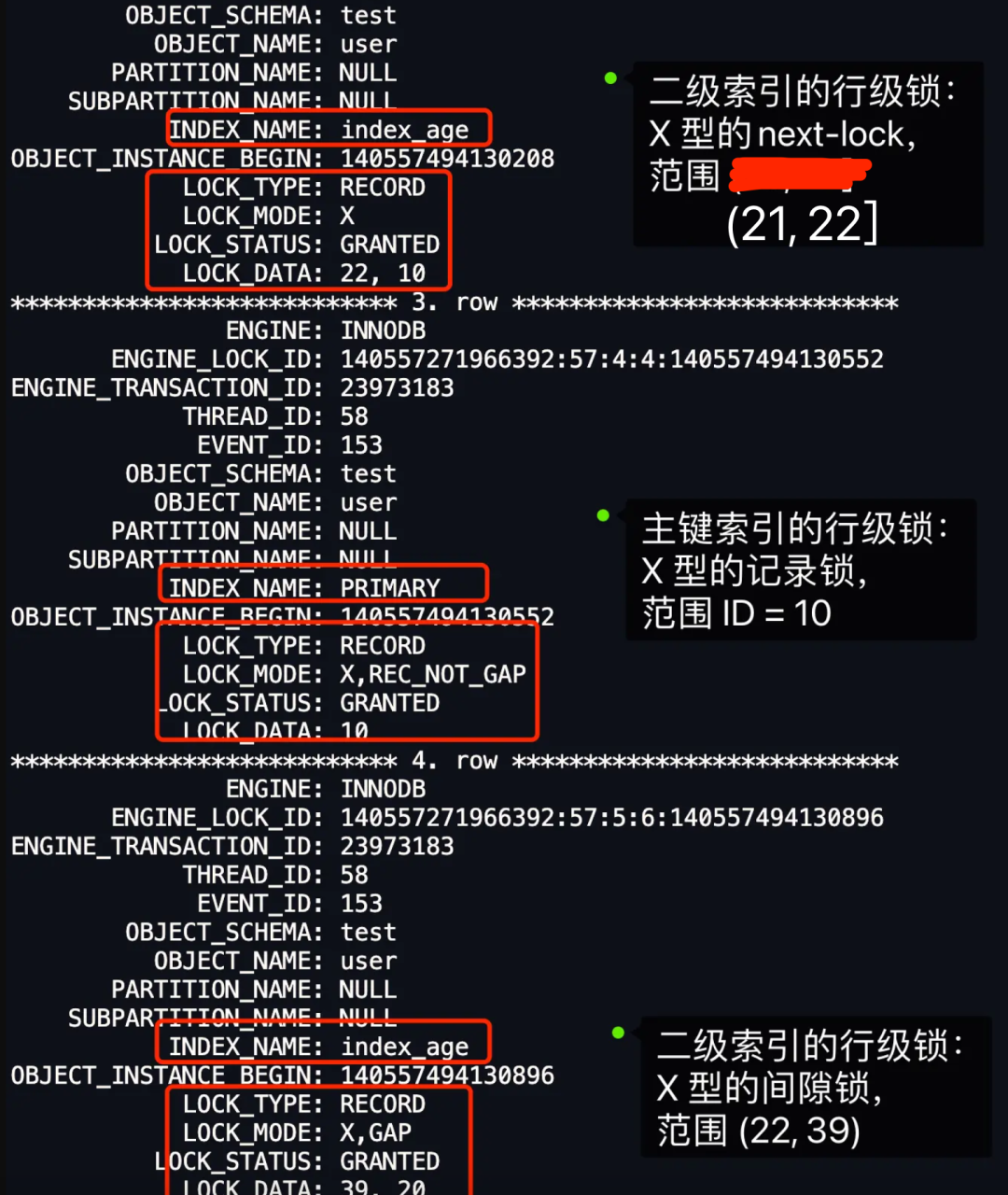
从上图的分析,可以看到,事务 A 不仅对二级索引(INDEX_NAME: index_age )加了范围为 (21, 22] 的 X 型 next-key 锁和范围为 (22, 39) 的 X 型间隙锁,而且还对主键索引(INDEX_NAME: PRIMARY )加了X 型的记录锁,范围是 id = 10 这一行记录。
2、记录不存在的情况
实验二:针对非唯一索引等值查询时,查询的值不存在的情况。
假设事务 A 对非唯一索引(age)进行了等值查询,且表中不存在 age = 25 的记录。
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from user where age = 25 for update;
Empty set (0.00 sec)
事务 A 加锁变化过程如下:
定位到第一条不符合查询条件的二级索引记录,即扫描到 age = 39,于是该二级索引的 next-key 锁会退化成间隙锁,范围是 (22, 39)。 停止查询
事务 A 在 age = 39 记录的二级索引上,加了 X 型的间隙锁,范围是 (22, 39)。意味着其他事务无法插入 age 值为 23、24、25、26、....、38 这些新记录。不过对于插入 age = 39 记录的语句,在一些情况是可以成功插入的,而一些情况则无法成功插入,具体哪些情况,会在后面说。

我们也可以通过 select * from performance_schema.data_locks\G; 这条语句来看看事务 A 加了什么锁。
输出结果如下,我这里只截取了行级锁的内容。

从上图的分析,可以看到,事务 A 在 age = 39 记录的二级索引上(INDEX_NAME: index_age ),加了范围为 (22, 39) 的 X 型间隙锁。
此时,如果有其他事务插入了 age 值为 23、24、25、26、....、38 这些新记录,那么这些插入语句都会发生阻塞。不过对于插入 age = 39 记录的语句,在一些情况是可以成功插入的,而一些情况则无法成功插入,具体哪些情况,接下来我们就说!
当有一个事务持有间隙锁 (22, 39) 时,到底是什么情况下,可以让其他事务的插入 age = 39 记录的语句成功?又是什么情况下,插入 age = 39 记录时的语句会被阻塞?
我们先要清楚,什么情况下插入语句会发生阻塞。
插入语句在插入一条记录之前,需要先定位到该记录在 B+树 的位置,如果插入的位置的下一条记录的索引上有间隙锁,才会发生阻塞。
在分析二级索引的间隙锁是否可以成功插入记录时,我们要先要知道二级索引树是如何存放记录的?
二级索引树是按照二级索引值(age列)按顺序存放的,在相同的二级索引值情况下, 再按主键 id 的顺序存放。知道了这个前提,我们才能知道执行插入语句的时候,插入的位置的下一条记录是谁。
事务 A 是在 age = 39 记录的二级索引上,加了 X 型的间隙锁,范围是 (22, 39)。插入 age = 39 记录的成功和失败的情况分别如下:
当其他事务插入一条 age = 39,id = 3 的记录的时候,在二级索引树上定位到插入的位置,而该位置的下一条是 id = 20、age = 39 的记录,正好该记录的二级索引上有间隙锁,所以这条插入语句会被阻塞,无法插入成功。
当其他事务插入一条 age = 39,id = 21 的记录的时候,在二级索引树上定位到插入的位置,而该位置的下一条记录不存在,也就没有间隙锁了,所以这条插入语句可以插入成功。
所以,插入 age = 39 记录的语句是否可以插入成功,关键是要看插入 age = 39 记录的时候,插入的位置的下一条记录是否有间隙锁,如果有间隙锁,就会发生阻塞,如果没有间隙锁,则可以插入成功。
非唯一索引范围查询
非唯一索引和主键索引的范围查询的加锁也有所不同,不同之处在于非唯一索引范围查询,索引的 next-key lock 不会有退化为间隙锁和记录锁的情况,也就是非唯一索引进行范围查询时,对二级索引记录加锁都是加 next-key 锁。
就带大家简单分析一下,事务 A 的这条范围查询语句:
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from user where age >= 22 for update;
+----+-----------+-----+
| id | name | age |
+----+-----------+-----+
| 10 | 山治 | 22 |
| 20 | 香克斯 | 39 |
+----+-----------+-----+
2 rows in set (0.01 sec)
事务 A 的加锁变化:
最开始要找的第一行是 age = 22,虽然范围查询语句包含等值查询,但是这里不是唯一索引范围查询,所以是不会发生退化锁的现象,因此对该二级索引记录加 next-key 锁,范围是 (21, 22]。同时,对 age = 22 这条记录的主键索引加记录锁,即对 id = 10 这一行记录的主键索引加记录锁。 由于是范围查询,接着继续扫描已经存在的二级索引记录。扫面的第二行是 age = 39 的二级索引记录,于是对该二级索引记录加 next-key 锁,范围是 (22, 39],同时,对 age = 39 这条记录的主键索引加记录锁,即对 id = 20 这一行记录的主键索引加记录锁。 虽然我们看见表中最后一条二级索引记录是 age = 39 的记录,但是实际在 Innodb 存储引擎中,会用一个特殊的记录来标识最后一条记录,该特殊的记录的名字叫 supremum pseudo-record ,所以扫描第二行的时候,也就扫描到了这个特殊记录的时候,会对该二级索引记录加的是范围为 (39, +∞] 的 next-key 锁。 停止查询
可以看到,事务 A 对主键索引和二级索引都加了 X 型的锁:

主键索引(id 列): 在 id = 10 这条记录的主键索引上,加了记录锁,意味着其他事务无法更新或者删除 id = 10 的这一行记录。 在 id = 20 这条记录的主键索引上,加了记录锁,意味着其他事务无法更新或者删除 id = 20 的这一行记录。 二级索引(age 列): 在 age = 22 这条记录的二级索引上,加了范围为 (21, 22] 的 next-key 锁,意味着其他事务无法更新或者删除 age = 22 的这一些新记录,不过对于插入 age = 22 记录的语句,在一些情况是可以成功插入的,而一些情况则无法成功插入,具体哪些情况,我们前面也讲了。 在 age = 39 这条记录的二级索引上,加了范围为 (22, 39] 的 next-key 锁,意味着其他事务无法更新或者删除 age = 39 的这一些记录,也无法插入 age 值为 23、24、25、...、38 的这一些新记录。不过对于插入 age = 22 记录的语句是,在一些情况是可以成功插入的,而一些情况则无法成功插入,具体哪些情况,我们前面也讲了。 在特殊的记录(supremum pseudo-record)的二级索引上,加了范围为 (39, +∞] 的 next-key 锁,意味着其他事务无法插入 age 值大于 39 的这些新记录。
没有加索引的查询
前面的案例,我们的查询语句都有使用索引查询,也就是查询记录的时候,是通过索引扫描的方式查询的,然后对扫描出来的记录进行加锁。
如果锁定读查询语句,没有使用索引列作为查询条件,或者查询语句没有走索引查询,导致扫描是全表扫描。那么,每一条记录的索引上都会加 next-key 锁,这样就相当于锁住的全表,这时如果其他事务对该表进行增、删、改操作的时候,都会被阻塞。
不只是锁定读查询语句不加索引才会导致这种情况,update 和 delete 语句如果查询条件不加索引,那么由于扫描的方式是全表扫描,于是就会对每一条记录的索引上都会加 next-key 锁,这样就相当于锁住的全表。
因此,在线上在执行 update、delete、select ... for update 等具有加锁性质的语句,一定要检查语句是否走了索引,如果是全表扫描的话,会对每一个索引加 next-key 锁,相当于把整个表锁住了,这是挺严重的问题。
总结
这次我以 MySQL 8.0.26 版本,在可重复读隔离级别之下,做了几个实验,让大家了解了唯一索引和非唯一索引的行级锁的加锁规则。
我这里总结下, MySQL 行级锁的加锁规则。
唯一索引等值查询:
当查询的记录是「存在」的,在索引树上定位到这一条记录后,将该记录的索引中的 next-key lock 会退化成「记录锁」。 当查询的记录是「不存在」的,则会在索引树找到第一条大于该查询记录的记录,然后将该记录的索引中的 next-key lock 会退化成「间隙锁」。
非唯一索引等值查询:
当查询的记录「存在」时,由于不是唯一索引,所以肯定存在索引值相同的记录,于是非唯一索引等值查询的过程是一个扫描的过程,直到扫描到第一个不符合条件的二级索引记录就停止扫描,然后在扫描的过程中,对扫描到的二级索引记录加的是 next-key 锁,而对于第一个不符合条件的二级索引记录,该二级索引的 next-key 锁会退化成间隙锁。同时,在符合查询条件的记录的主键索引上加记录锁。 当查询的记录「不存在」时,扫描到第一条不符合条件的二级索引记录,该二级索引的 next-key 锁会退化成间隙锁。因为不存在满足查询条件的记录,所以不会对主键索引加锁。
非唯一索引和主键索引的范围查询的加锁规则不同之处在于:
唯一索引在满足一些条件的时候,索引的 next-key lock 退化为间隙锁或者记录锁。 非唯一索引范围查询,索引的 next-key lock 不会退化为间隙锁和记录锁。
还有一件很重要的事情,在线上在执行 update、delete、select ... for update 等具有加锁性质的语句,一定要检查语句是否走了索引,如果是全表扫描的话,会对每一个索引加 next-key 锁,相当于把整个表锁住了,这是挺严重的问题。
就说到这啦, 我们下次见啦!