码农也来玩奥运开幕式“超级变变变”!相机动捕,实时转换赛事图标,项目开源可试玩

大数据文摘出品
作者:Caleb
大家都有在看奥运会吗?
根据发稿前的数据统计,目前中国金牌数量24,位列第一,奖牌总数51,仅次于美国的59,位列第二。
在为运动员们加油助威的同时,我们不妨再回顾一下本届奥运会开幕式。
7月23日,东京时间晚上8点,延期一年的东京奥运会终于开幕,本应座无虚席可容纳6.8万人的看台上,因防疫需要几乎空无一人。
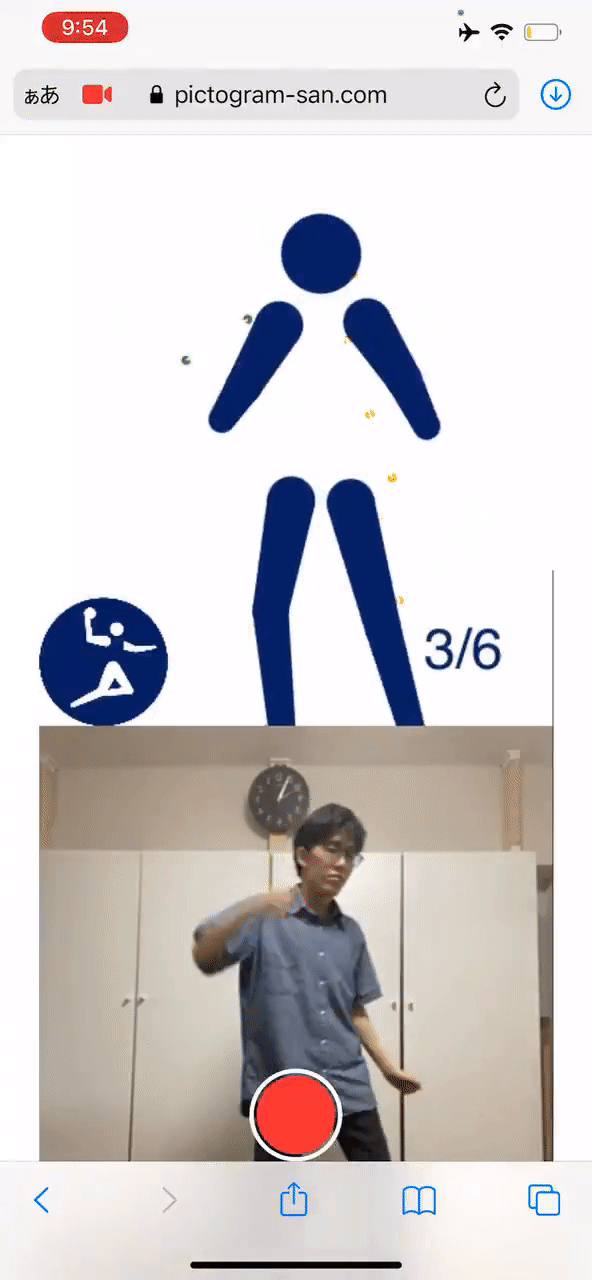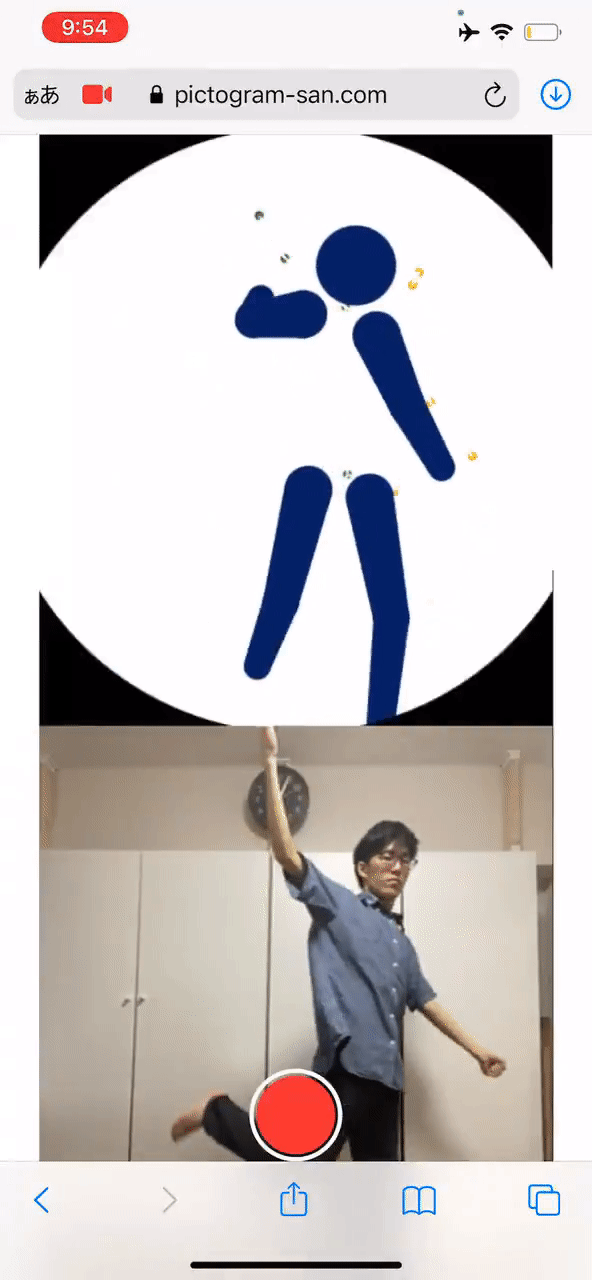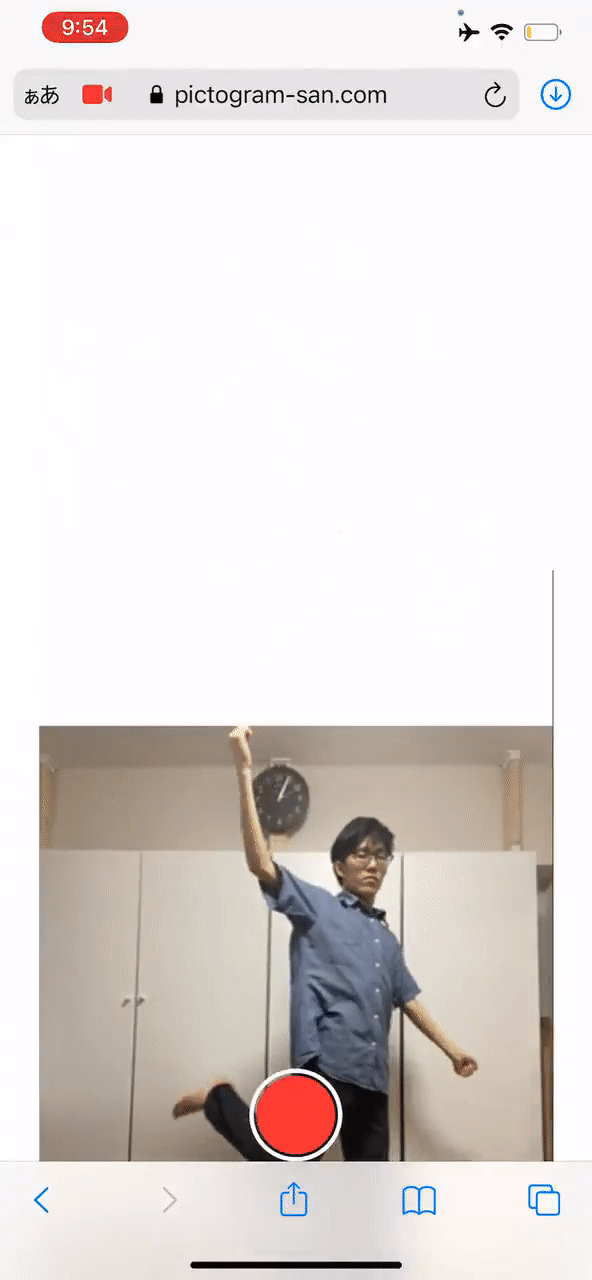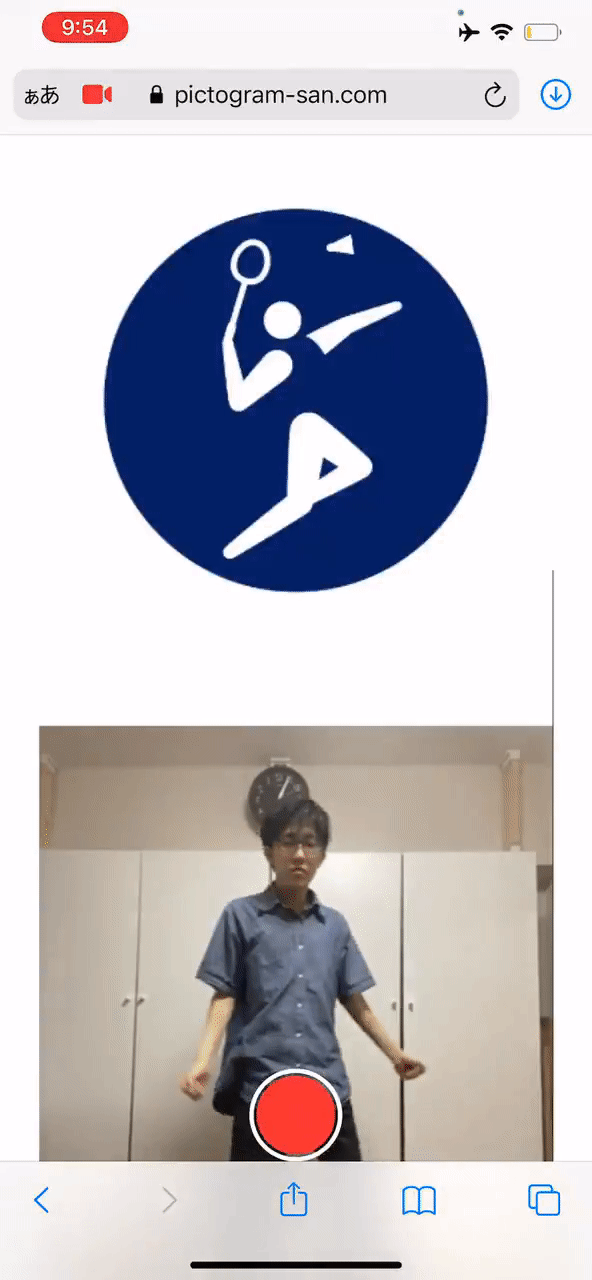
在开幕仪式上,最让人惊喜的节目之一便是将日本老牌节目《超级变变变》的风格搬运到了各个项目图标中,表演者们相互配合,用道具搭配肢体动作,展现了乒乓球、射击、铁人三项等50个图标。

其实,在1964年的东京奥运会上,日本人就首次发明了体育项目图标,随后这也逐渐成为奥运会的传统之一,得以延续。

借着奥运热潮,不少象形文字项目也受到了关注。
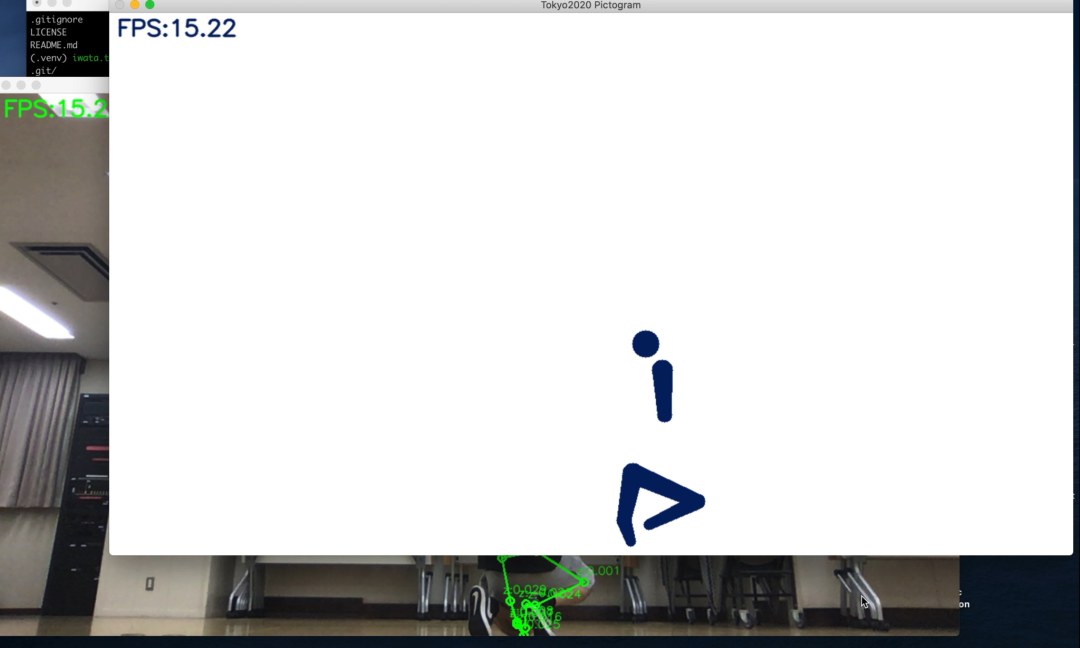
比如,日本一位叫做高桥的嵌入式工程师就亲自开发了一个软件,通过相机捕捉动作和姿势,然后把它们变成奥运风格的象形动图,就像这样:
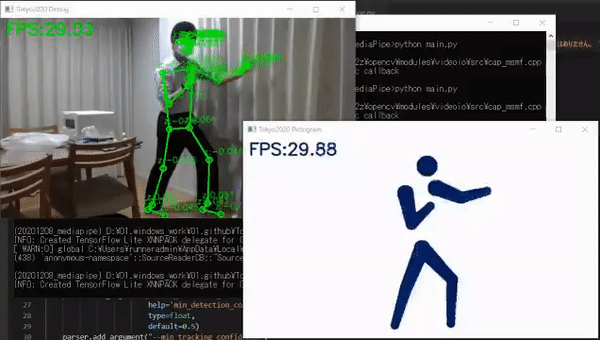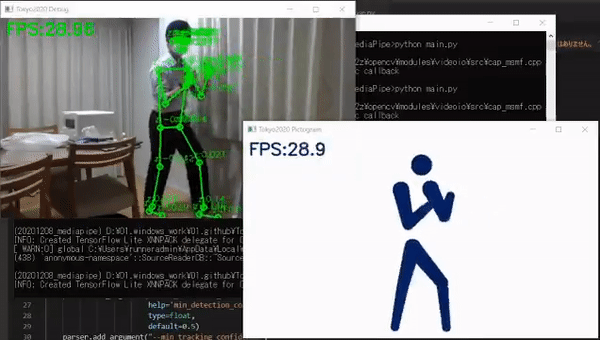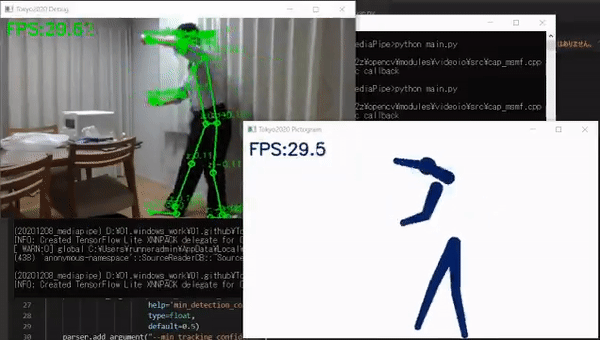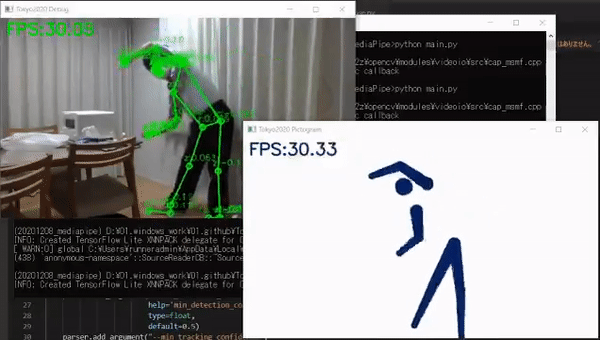
最终识别效果如下图所示,文摘菌只能说,都是“动作不够,机器来凑”啊。

手把手教你把自己变成象形动图
目前,该项目已经在GitHub上开源了。

GitHub链接:
git clone https://github.com/Kazuhito00/Tokyo2020-Pictogram-using-MediaPipe.gitcd Tokyo2020-Pictogram-using-MediaPipe
然后,需要创建一个Python虚拟环境,并安装所需要的库。
python -m venv .venvsource .venv/bin/activatepip install mediapipe opencv-python
准备工作做完之后,可能会遇到在本地代码无效的情况,可以对VideoCapture的宽度和高度适当做出调整。
- parser.add_argument("--width", help='cap width', type=int, default=640)- parser.add_argument("--height", help='cap height', type=int, default=360)+ parser.add_argument("--width", help='cap width', type=int, default=960)+ parser.add_argument("--height", help='cap height', type=int, default=540)
随后就可以运行该项目了。
python main.py这时候你就会发现,相机识别出来的图变成了这个样子:
最后,高桥也大方地给出了试玩地址,感兴趣的同学可别错过了:

试玩地址:
https://pictogram-san.com/
象形动图升级:霹雳舞也能玩出花!
这么有意思的项目仅限于此未免有些可惜了。
于是,一位叫做岩田智哉的同学就对高桥的程序进行了进一步的改进和完善,比如说,用来跳霹雳舞。
由于身体机能的下降,岩田放弃了在转动摄像机时实时制作象形图,转而尝试通过让程序读取视频,来制作象形图。
考虑到这点后,他做出了如下修改,把程序改成了由命令行参数传递的视频文件的象形图,同时还删除了反转视频的逻辑。
- parser.add_argument("--device", type=int, default=0)+ parser.add_argument('--file', type=str, required=True, help="video file path")parser.add_argument("--width", help='cap width', type=int, default=960)parser.add_argument("--height", help='cap height', type=int, default=540)@@ -43,7 +43,7 @@ def main():# 引数解析 #################################################################args = get_args()- cap_device = args.device+ cap_file = args.filecap_width = args.widthcap_height = args.height@@ -55,7 +55,7 @@ def main():rev_color = args.rev_color# カメラ準備 ###############################################################- cap = cv.VideoCapture(cap_device)+ cap = cv.VideoCapture(cap_file)cap.set(cv.CAP_PROP_FRAME_WIDTH, cap_width)cap.set(cv.CAP_PROP_FRAME_HEIGHT, cap_height)@@ -86,7 +86,7 @@ def main():ret, image = cap.read()if not ret:break- image = cv.flip(image, 1) # ミラー表示+ #image = cv.flip(image, 1) # ミラー表示debug_image01 = copy.deepcopy(image)debug_image02 = np.zeros((image.shape[0], image.shape[1], 3), np.uint8)cv.rectangle(debug_image02, (0, 0), (image.shape[1], image.shape[0]),
然后就能得到这样的视频识别效果:

想看动图?满足你:

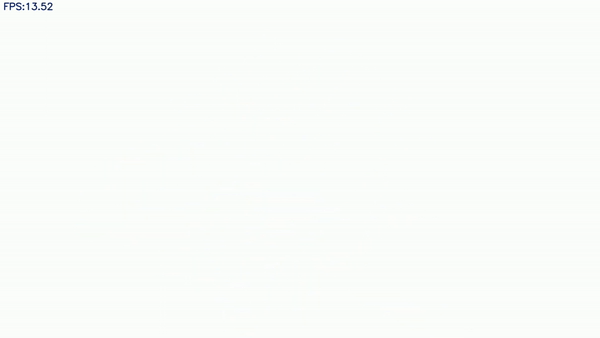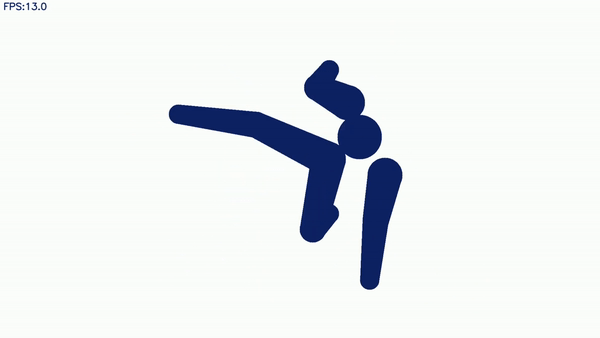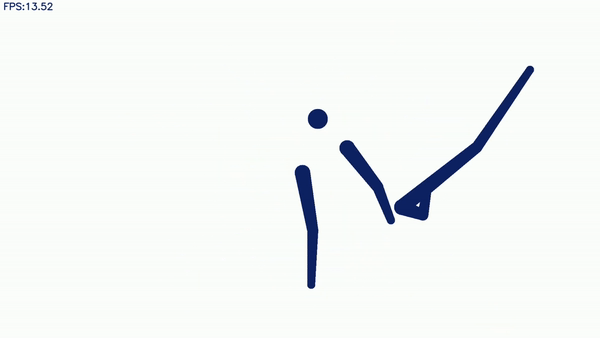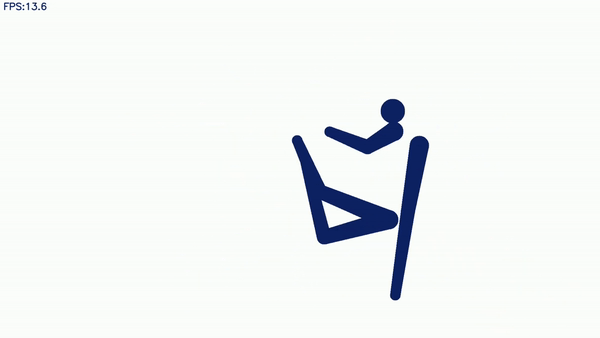
怎么样,是不是觉得竟然还有一丝酷炫?
最后,岩田表示,既然都做到这一步了,我们就顺理成章地再添加逻辑,把这个栩栩如生的视频保存为一个单独的mp4文件。
第一次加载作为命令行参数传递的视频文件时,需要创建一个文件名为<UTC时间戳>-pictgram-output.mp4的视频文件,并在每次循环后添加一个进程来导出象形图象即可。
#!/usr/bin/env python# -*- coding: utf-8 -*-import copy+from datetime import datetimeimport mathimport argparsecolor = (100, 33, 3)bg_color = (255, 255, 255)+ is_first = True+ output_video = Nonewhile True:display_fps = cvFpsCalc.get()ret, image = cap.read()if not ret:break+#image = cv.flip(image, 1) # ミラー表示debug_image01 = copy.deepcopy(image)debug_image02 = np.zeros((image.shape[0], image.shape[1], 3), np.uint8)cv.imshow('Tokyo2020 Debug', debug_image01)cv.imshow('Tokyo2020 Pictogram', debug_image02)+ if is_first:+ fmt = cv.VideoWriter_fourcc('m', 'p', '4', 'v')+ fps = cap.get(cv.CAP_PROP_FPS)+ now = datetime.now().strftime('%Y-%m-%d-%H%M%S')+ output_video = cv.VideoWriter(f'{now}-pictgram-output.mp4', fmt, fps, (debug_image02.shape[1], debug_image02.shape[0]))+ is_first = False++ output_video.write(debug_image02)+cap.release()+ if output_video:+ output_video.release()cv.destroyAllWindows()
基于机器学习技术的手势识别算法MediaPipe
MediaPipe是一种基于机器学习技术的手势识别算法,其特点是准确率高,支持五指和手势追踪,可根据一帧图像推断出单手21个立体节点。
与目前市面上较先进的手势识别技术相比,MediaPipe不需要依赖台式机,在手机上就能进行实时追踪,还支持同时追踪多只手,识别遮挡等。

MediaPipe框架有3个模型组成,包括:手掌识别模型BlazePalm(用于识别手的整体框架和方向)、Landmark模型(识别立体手部节点)、手势识别模型(将识别到的节点分类成一系列手势)。
其中,BlazePalm是一个可识别单帧图像的模型,主要为Landmark模型提供准确剪裁的手掌图像,在经过训练后手掌识别准确率可达95.7%。这大大降低了对旋转、转化和缩放等数据增强方式的依赖,让算法将更多计算能力用在提高预测准确性上。
此外,BlazePalm可识别多种不同手掌大小,还能识别手部遮挡,并且能通过对手臂、躯干或个人特征等的识别来准确定位手部。
Landmark模型在BlazePalm基础上识别到的21个立体节点坐标,这些节点之间的位置遮挡也可被识别。
通过手势识别模型,从Landmark提取的数据来推断每根手指伸直或弯曲等动作,接着将这些动作与预设的手势匹配,以预测基础的静态手势。预设手势包括美国、欧洲、中国通用手势,以及竖大拇指、握拳、OK、“蜘蛛侠”等。