
码农也来玩奥运开幕式“超级变变变”!相机动捕,实时转换赛事图标,项目开源可试玩

来源:大数据文摘 本文约2600字,建议阅读5分钟 来为奥运“花样”加油。





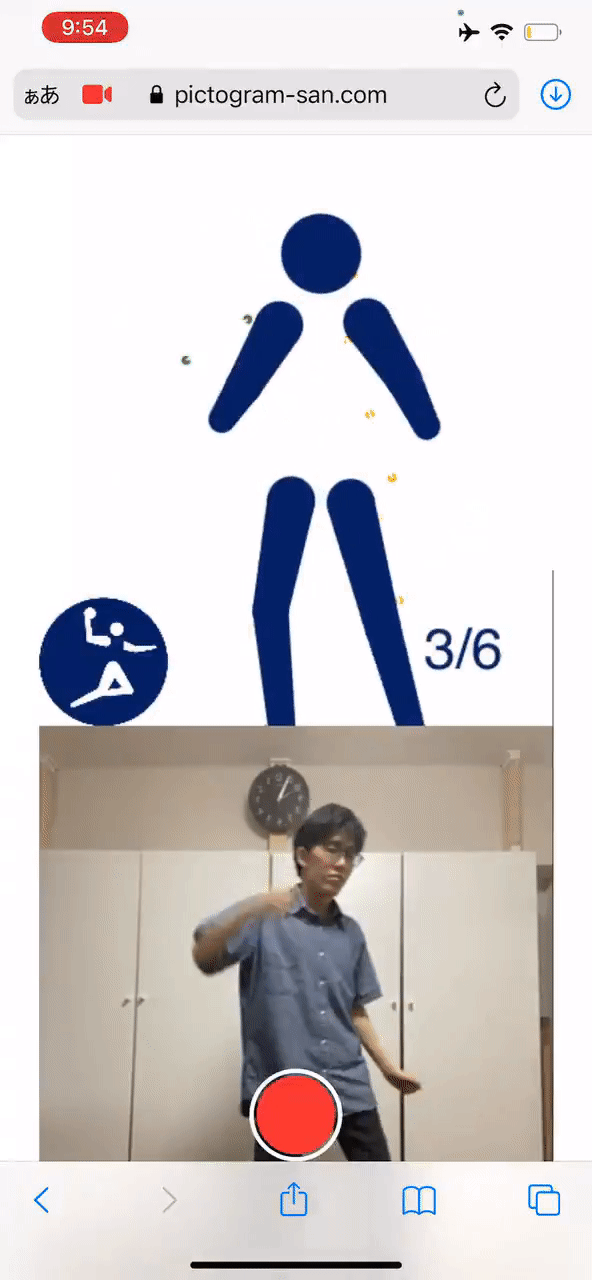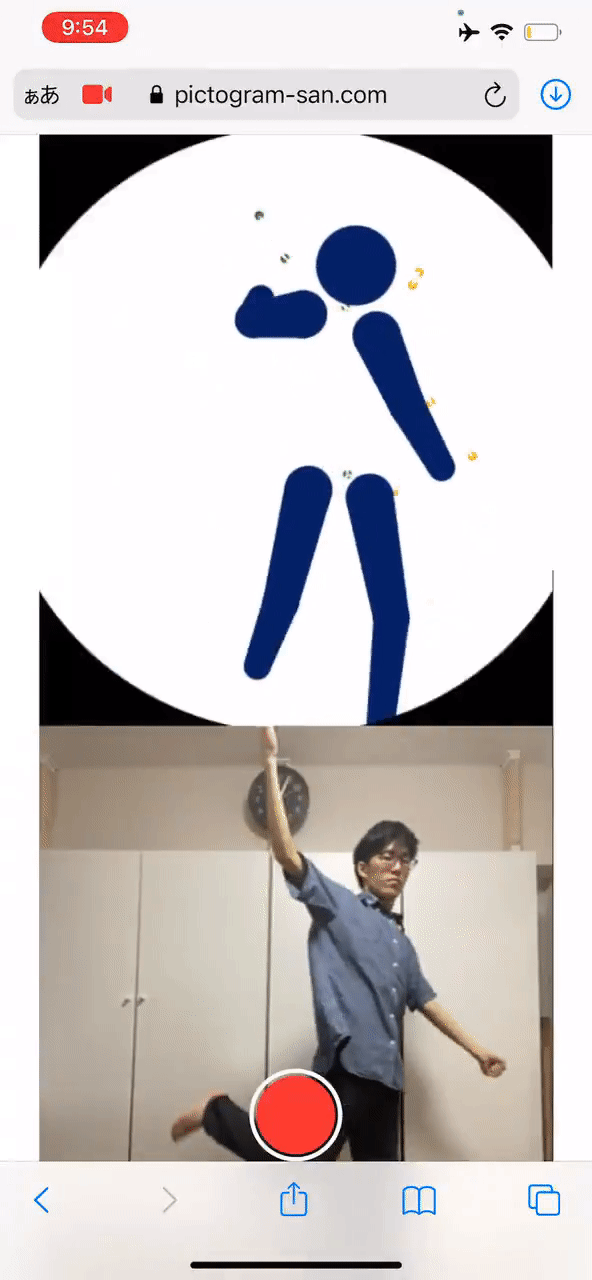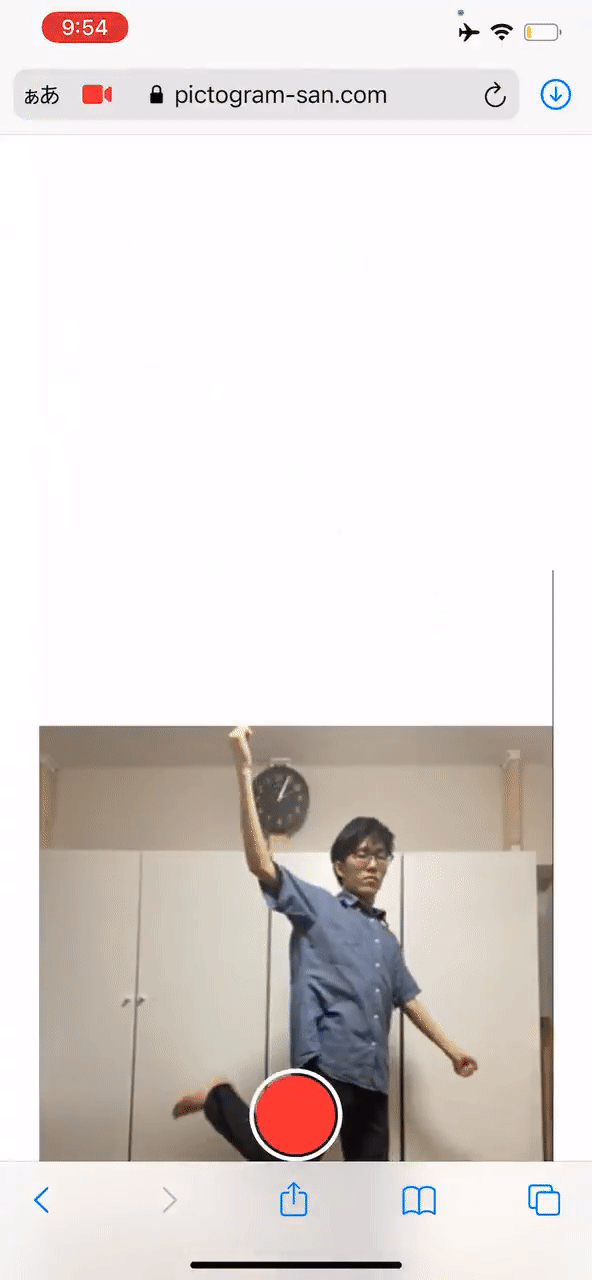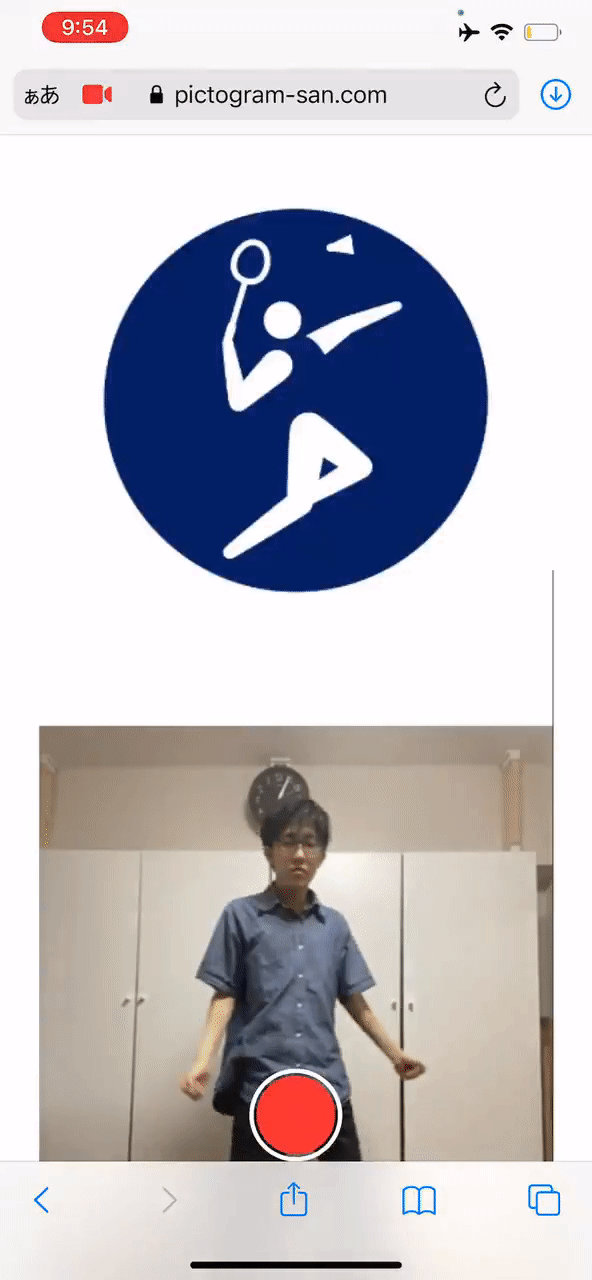
手把手教你把自己变成象形动图

https://github.com/Kazuhito00/Tokyo2020-Pictogram-using-MediaPipe
$ git clone https://github.com/Kazuhito00/Tokyo2020-Pictogram-using-MediaPipe.git$ cd Tokyo2020-Pictogram-using-MediaPipe
$ python -m venv .venv$ source .venv/bin/activate$ pip install mediapipe opencv-python
- parser.add_argument("--width", help='cap width', type=int, default=640)- parser.add_argument("--height", help='cap height', type=int, default=360)+ parser.add_argument("--width", help='cap width', type=int, default=960)+ parser.add_argument("--height", help='cap height', type=int, default=540)
$ python main.py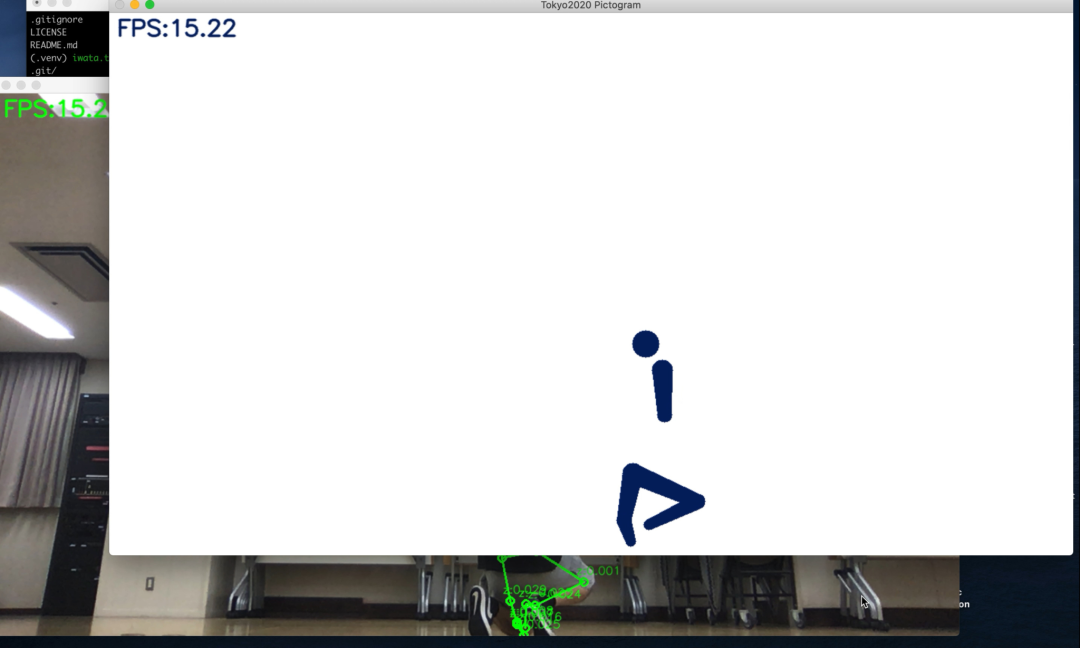

https://pictogram-san.com/
象形动图升级:霹雳舞也能玩出花!
- parser.add_argument("--device", type=int, default=0)+ parser.add_argument('--file', type=str, required=True, help="video file path")parser.add_argument("--width", help='cap width', type=int, default=960)parser.add_argument("--height", help='cap height', type=int, default=540)@@ -43,7 +43,7 @@ def main():# 引数解析 #################################################################args = get_args()- cap_device = args.device+ cap_file = args.filecap_width = args.widthcap_height = args.height@@ -55,7 +55,7 @@ def main():rev_color = args.rev_color# カメラ準備 ###############################################################- cap = cv.VideoCapture(cap_device)+ cap = cv.VideoCapture(cap_file)cap.set(cv.CAP_PROP_FRAME_WIDTH, cap_width)cap.set(cv.CAP_PROP_FRAME_HEIGHT, cap_height)@@ -86,7 +86,7 @@ def main():ret, image = cap.read()if not ret:break- image = cv.flip(image, 1) # ミラー表示+ #image = cv.flip(image, 1) # ミラー表示debug_image01 = copy.deepcopy(image)debug_image02 = np.zeros((image.shape[0], image.shape[1], 3), np.uint8)cv.rectangle(debug_image02, (0, 0), (image.shape[1], image.shape[0]),


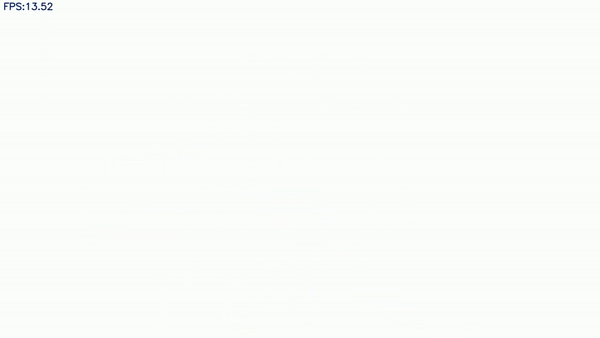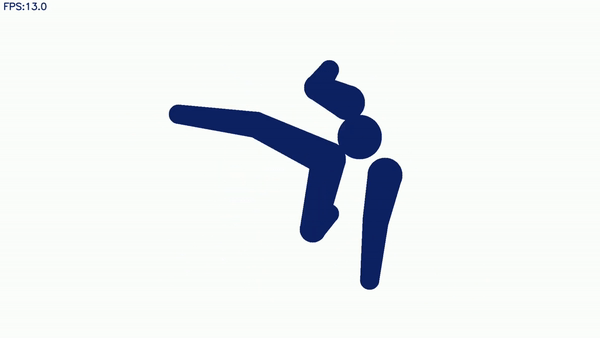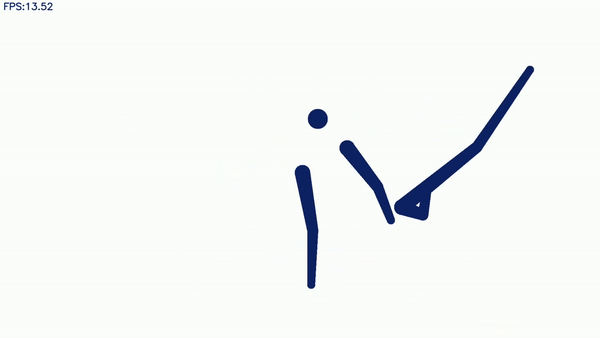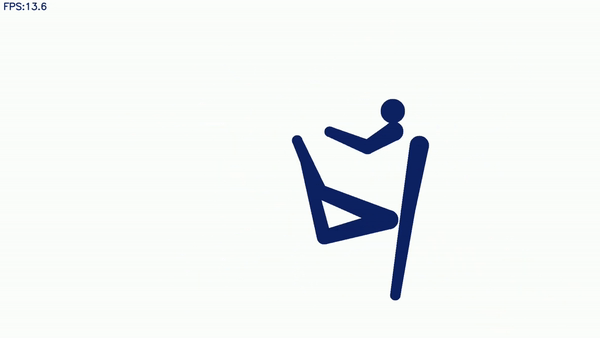
#!/usr/bin/env python# -*- coding: utf-8 -*-import copy+from datetime import datetimeimport mathimport argparsecolor = (100, 33, 3)bg_color = (255, 255, 255)+ is_first = True+ output_video = Nonewhile True:display_fps = cvFpsCalc.get()ret, image = cap.read()if not ret:break+#image = cv.flip(image, 1) # ミラー表示debug_image01 = copy.deepcopy(image)debug_image02 = np.zeros((image.shape[0], image.shape[1], 3), np.uint8)cv.imshow('Tokyo2020 Debug', debug_image01)cv.imshow('Tokyo2020 Pictogram', debug_image02)+ if is_first:+ fmt = cv.VideoWriter_fourcc('m', 'p', '4', 'v')+ fps = cap.get(cv.CAP_PROP_FPS)+ now = datetime.now().strftime('%Y-%m-%d-%H%M%S')+ output_video = cv.VideoWriter(f'{now}-pictgram-output.mp4', fmt, fps, (debug_image02.shape[1], debug_image02.shape[0]))+ is_first = False++ output_video.write(debug_image02)+cap.release()+ if output_video:+ output_video.release()cv.destroyAllWindows()
基于机器学习技术的手势识别算法MediaPipe


编辑:于腾凯
校对:汪雨晴
评论