
GTA 5 + AI = ?
点击上方“视学算法”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者 | 琰琰






实现方法
实现方法
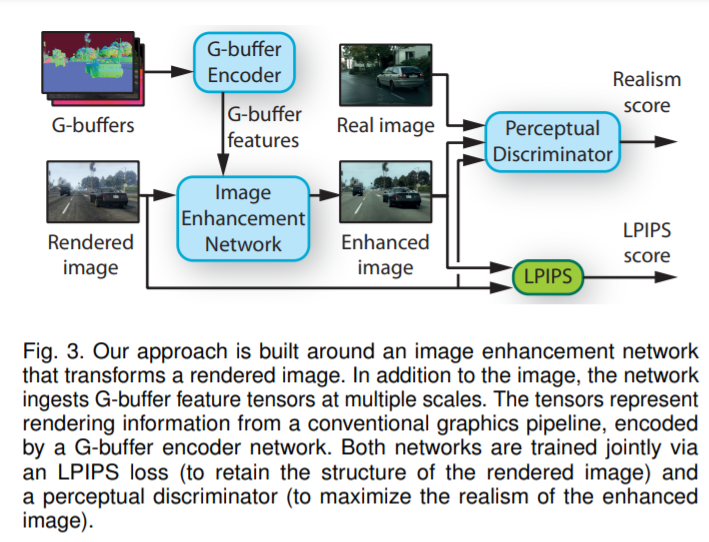

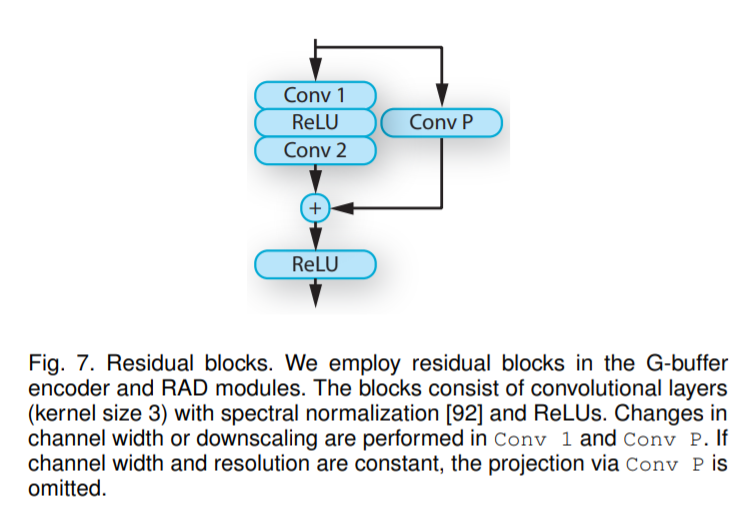
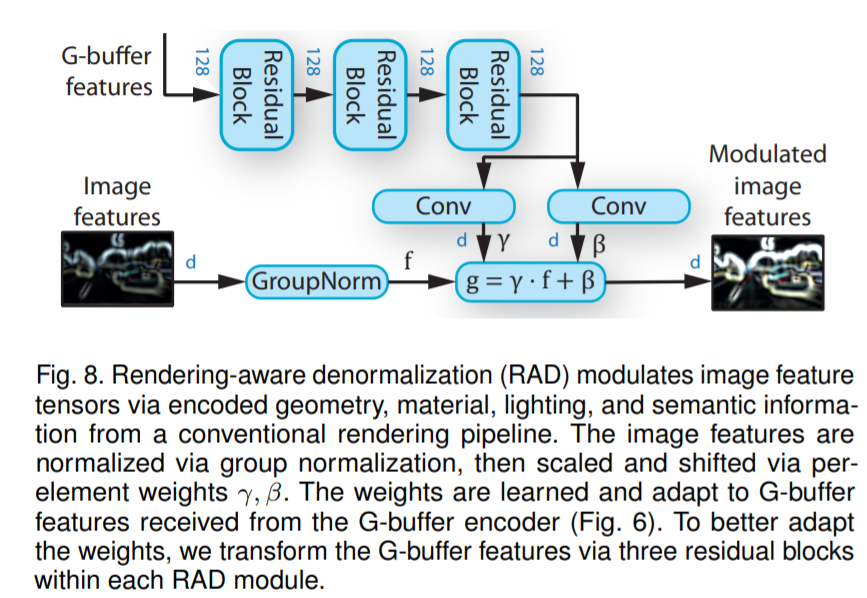
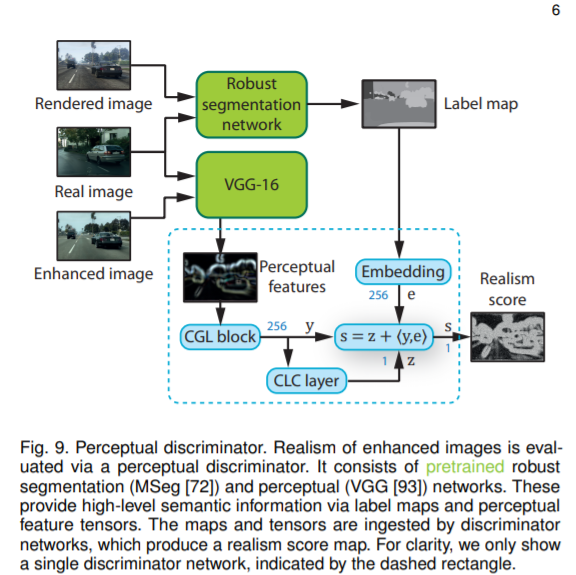
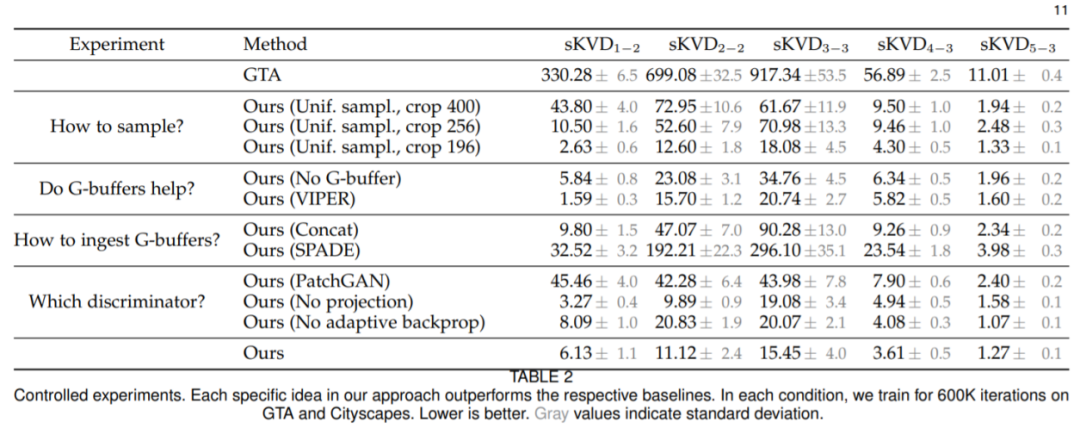
实验评估
实验评估



https://www.theverge.com/2021/5/12/22432945/intel-gta-v-realistic-machine-learning-cityscapes-dataset
https://www.engadget.com/gta-v-ai-photorealism-135046313.html

点个在看 paper不断!
评论