
【前端实战】一文带你层层解锁「文件下载」的奥秘
大家好我是秋风,今天带来的主题是关于文件下载,在我之前曾经发过一篇文件上传的文章(一文了解文件上传全过程(1.8w字深度解析,进阶必备),反响还不错,时隔多日,由于最近有研究一些媒体相关的工作,因此打算对下载做一个整理,因此他的兄弟篇诞生了,带你领略文件下载的奥秘。本文会花费你较长的时间阅读,建议先收藏/点赞,然后查看你感兴趣的部分,平时也可以充当当做字典的效果来查询。
:) 不整不知道,一整,居然整出这么多情况,我只是想简单地做个页面仔。
前言
一图览全文,可以先看看大纲适不适合自己,如果你喜欢则继续往下阅读。
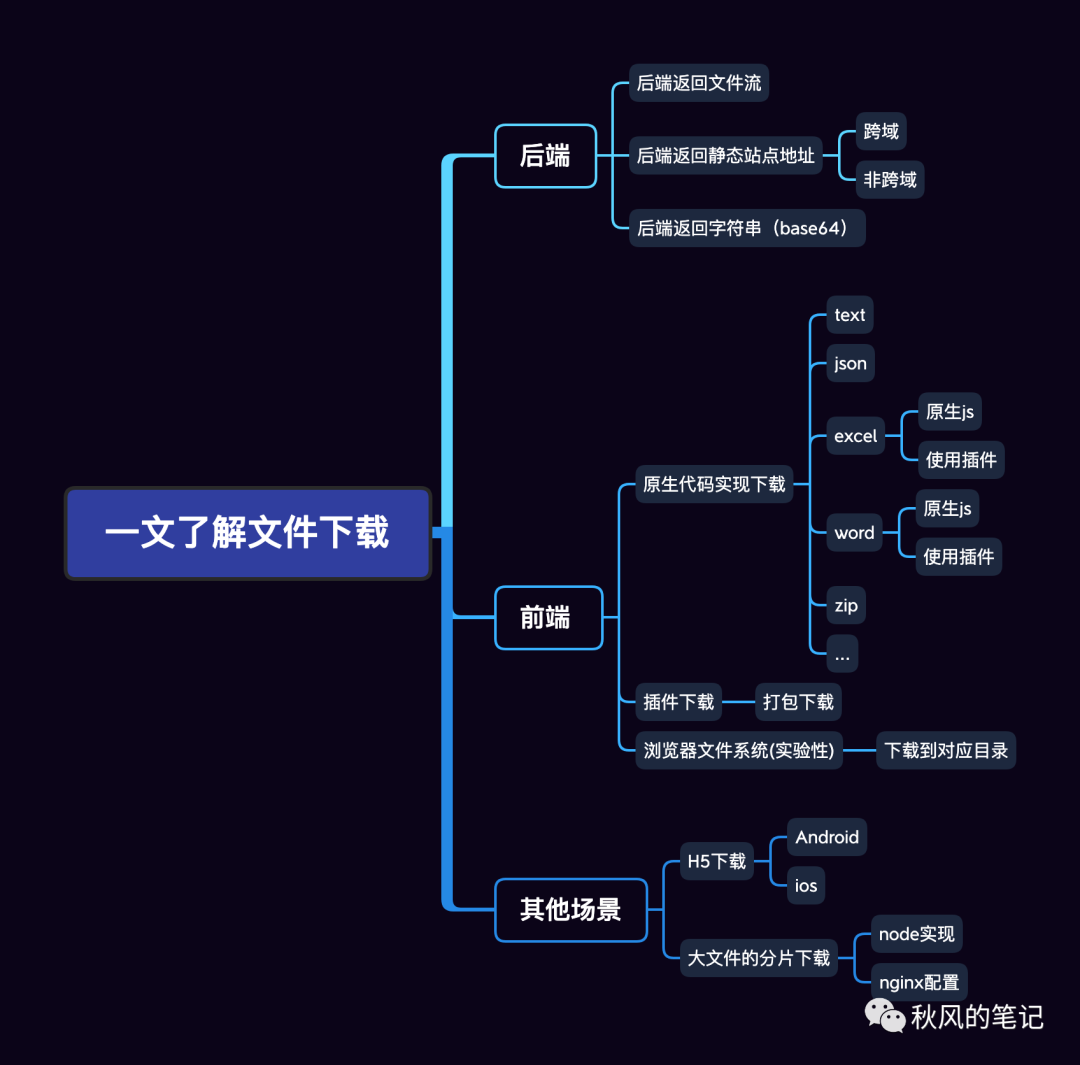
这一节呢,主要介绍一些前置知识,对一些基础知识的介绍,如果你觉得你是这个。⬇️⬇️⬇️,你可以跳过前言。

前端的文件下载主要是通过 ,再加上 download属性,有了它们让我们的下载变得简单。
download此属性指示浏览器下载 URL 而不是导航到它,因此将提示用户将其保存为本地文件。如果属性有一个值,那么此值将在下载保存过程中作为预填充的文件名(如果用户需要,仍然可以更改文件名)。此属性对允许的值没有限制,但是 / 和 \ 会被转换为下划线。大多数文件系统限制了文件名中的标点符号,故此,浏览器将相应地调整建议的文件名。( 摘自 https://developer.mozilla.org/zh-CN/docs/Web/HTML/Element/a)
注意:
此属性仅适用于同源 URL。 尽管 HTTP URL 需要位于同一源中,但是可以使用 blob:URL 和data:URL ,以方便用户下载使用 JavaScript 生成的内容(例如使用在线绘图 Web 应用程序创建的照片)。
因此下载 url 主要有三种方式。(本文大部分以 blob 的方式进行演示)
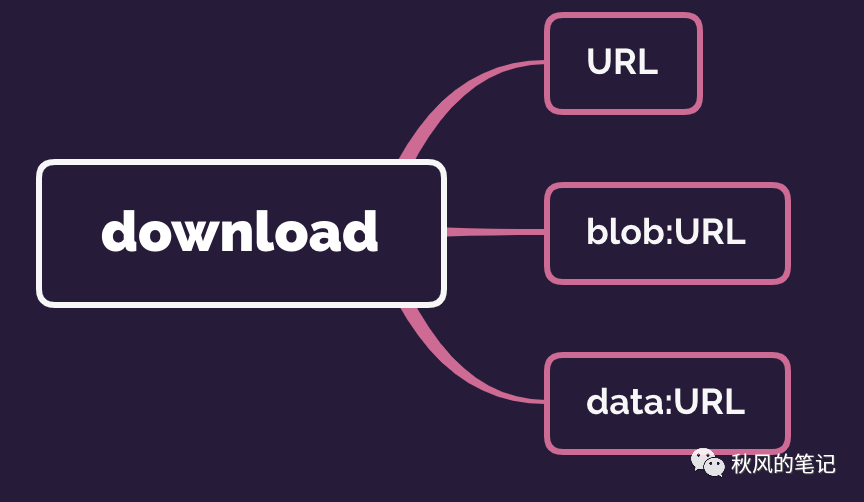
兼容性
可以看到它的兼容性也非常的可观(https://www.caniuse.com/#search=download)

为了避免很多代码的重复性,因为我抽离出了几个公共函数。(该部分可跳过,名字都比较可读,之后若是遇到不明白则可以在这里寻找)
export function downloadDirect(url) {
const aTag = document.createElement('a');
aTag.download = url.split('/').pop();
aTag.href = url;
aTag.click()
}
export function downloadByContent(content, filename, type) {
const aTag = document.createElement('a');
aTag.download = filename;
const blob = new Blob([content], { type });
const blobUrl = URL.createObjectURL(blob);
aTag.href = blobUrl;
aTag.click();
URL.revokeObjectURL(blob);
}
export function downloadByDataURL(content, filename, type) {
const aTag = document.createElement('a');
aTag.download = filename;
const dataUrl = `data:${type};base64,${window.btoa(unescape(encodeURIComponent(content)))}`;
aTag.href = dataUrl;
aTag.click();
}
export function downloadByBlob(blob, filename) {
const aTag = document.createElement('a');
aTag.download = filename;
const blobUrl = URL.createObjectURL(blob);
aTag.href = blobUrl;
aTag.click();
URL.revokeObjectURL(blob);
}
export function base64ToBlob(base64, type) {
const byteCharacters = atob(base64);
const byteNumbers = new Array(byteCharacters.length);
for (let i = 0; i < byteCharacters.length; i++) {
byteNumbers[i] = byteCharacters.charCodeAt(i);
}
const buffer = Uint8Array.from(byteNumbers);
const blob = new Blob([buffer], { type });
return blob;
}
🚅🚅🚅🚅🚅🚅🚅🚅🚅🚅🚅🚅🚅🚅🚅🚅🚅🚅🚅🚅🚅🚅🚅🚅🚅🚅🚅🚅🚅
(手动给不看以上内容的大佬画分割线)
🇨🇳
所有示例Github地址: https://github.com/hua1995116/node-demo/tree/master/file-download
在线Demo: https://qiufeng.blue/demo/file-download/index.html
后端
本文后端所有示例均以 koa / 原生 js 实现。
后端返回文件流
这种情况非常简单,我们只需要直接将后端返回的文件流以新的窗口打开,即可直接下载了。
// 前端代码
<button id="oBtnDownload">点击下载button>
<script>
oBtnDownload.onclick = function(){
window.open('http://localhost:8888/api/download?filename=1597375650384.jpg', '_blank')
}
script>
// 后端代码
router.get('/api/download', async (ctx) => {
const { filename } = ctx.query;
const fStats = fs.statSync(path.join(__dirname, './static/', filename));
ctx.set({
'Content-Type': 'application/octet-stream',
'Content-Disposition': `attachment; filename=${filename}`,
'Content-Length': fStats.size
});
ctx.body = fs.readFileSync(path.join(__dirname, './static/', filename));
})
能够让浏览器自动下载文件,主要有两种情况:
一种为使用了Content-Disposition属性。
我们来看看该字段的描述。
在常规的HTTP应答中,
Content-Disposition响应头指示回复的内容该以何种形式展示,是以内联的形式(即网页或者页面的一部分),还是以附件的形式下载并保存到本地 --- 来源 MDN(https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers/Content-Disposition)
再来看看它的语法
Content-Disposition: inline
Content-Disposition: attachment
Content-Disposition: attachment; filename="filename.jpg"
很简单,只要设置成最后一种形态我就能成功让文件从后端进行下载了。
另一种为浏览器无法识别的类型
例如输入 http://localhost:8888/static/demo.sh,浏览器无法识别该类型,就会自动下载。
不知道小伙伴们有没有遇到过这样的一个情况,我们输入一个正确的静态 js 地址,没有配置Content-Disposition,但是却会被意外的下载。
例如像以下的情况。
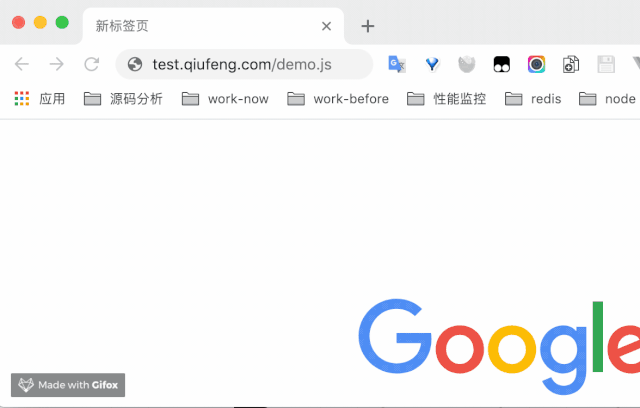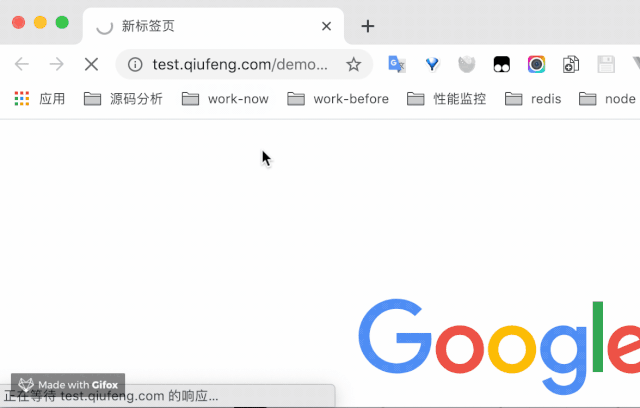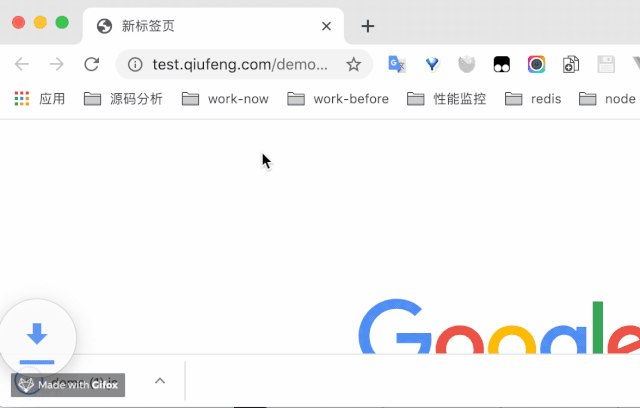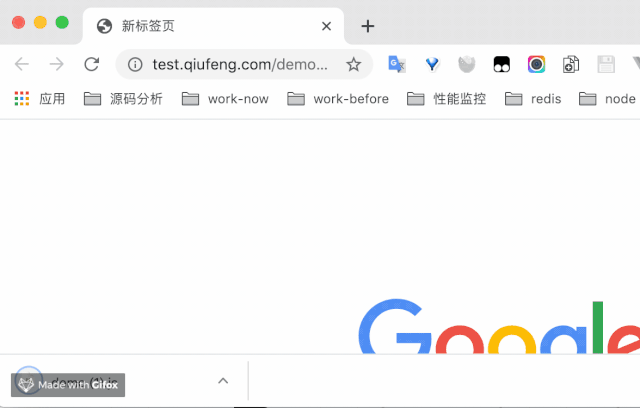

这很可能是由于你的 nginx 少了这一行配置.
include mime.types;
导致默认走了 application/octet-stream,浏览器无法识别就下载了文件。
后端返回静态站点地址
通过静态站点下载,这里要分为两种情况,一种为可能该服务自带静态目录,即为同源情况,第二种情况为适用了第三方静态存储平台,例如阿里云、腾讯云之类的进行托管,即非同源(当然也有些平台直接会返回)。
同源
同源情况下是非常简单,先上代码,直接调用一下函数就能轻松实现下载。
import {downloadDirect} from '../js/utils.js';
axios.get('http://localhost:8888/api/downloadUrl').then(res => {
if(res.data.code === 0) {
downloadDirect(res.data.data.url);
}
})
非同源
我们也可以从 MDN 上看到,虽然 download 限制了非同源的情况,但是!!但是!!但是可以使用 blob: URL 和 data: URL ,因此我们只要将文件内容进行下载转化成 blob 就可以了。
整个过程如下

<button id="oBtnDownload">点击下载button>
<script type="module">
import {downloadByBlob} from '../js/utils.js';
function download(url) {
axios({
method: 'get',
url,
responseType: 'blob'
}).then(res => {
downloadByBlob(res.data, url.split('/').pop());
})
}
oBtnDownload.onclick = function(){
axios.get('http://localhost:8888/api/downloadUrl').then(res => {
if(res.data.code === 0) {
download(res.data.data.url);
}
})
}
script>
现在非同源的也可以愉快地下载啦。
后端返回字符串(base64)
有时候我们也会遇到一些新手后端返回字符串的情况,这种情况很少见,但是来了我们也不慌,顺便可以向后端小哥秀一波操作,不管啥数据,咱都能给你下载下来。
ps: 前提是安全无污染的资源 :) , 正经文章的招牌闪闪发光。
这种情况下,我需要模拟下后端小哥的骚操作,因此有后端代码。

核心过程

// node 端
router.get('/api/base64', async (ctx) => {
const { filename } = ctx.query;
const content = fs.readFileSync(path.join(__dirname, './static/', filename));
const fStats = fs.statSync(path.join(__dirname, './static/', filename));
console.log(fStats);
ctx.body = {
code: 0,
data: {
base64: content.toString('base64'),
filename,
type: mime.getType(filename)
}
}
})
// 前端
<button id="oBtnDownload">点击下载button>
<script type="module">
import {base64ToBlob, downloadByBlob} from '../js/utils.js';
function download({ base64, filename, type }) {
const blob = base64ToBlob(blob, type);
downloadByBlob(blob, filename);
}
oBtnDownload.onclick = function(){
axios.get('http://localhost:8888/api/base64?filename=1597375650384.jpg').then(res => {
if(res.data.code === 0) {
download(res.data.data);
}
})
}
script>
思路其实还是利用了我们上面说的 标签。但是在这个步骤前,多了一个步骤就是,需要将我们的 base64 字符串转化为二进制流,这个东西,在我的前一篇文件上传中也常常提到,毕竟文件就是以二进制流的形式存在。不过也很简单,js 拥有内置函数 atob。极大地提高了我们转换的效率。
纯前端
上面介绍借助后端来完成文件下载的相关方法,接下来我们来介绍介绍纯前端来完成文件下载的一些方法。
方法一: blob: URL

方法二: data: URL

由于 data:URL 会有长度的限制,因此下面的所有例子都会采用 blob 的方式来进行演示。
json/text
下载text和json非常的简单,可以直接构造一个 Blob。
Blob(blobParts[, options])
返回一个新创建的 Blob 对象,其内容由参数中给定的数组串联组成。
// html
<textarea name="" id="text" cols="30" rows="10">textarea>
<button id="textBtn">下载文本button>
<p>p>
<textarea name="" id="json" cols="30" rows="10" disabled>
{
"name": "秋风的笔记"
}
textarea>
<button id="jsonBtn">下载JSONbutton>
//js
import {downloadByContent, downloadByDataURL} from '../js/utils.js';
textBtn.onclick = () => {
const value = text.value;
downloadByContent(value, 'hello.txt', 'text/plain');
// downloadByDataURL(value, 'hello.txt', 'text/plain');
}
jsonBtn.onclick = () => {
const value = json.value;
downloadByContent(value, 'hello.json', 'application/json');
// downloadByDataURL(value, 'hello.json', 'application/json');
}
效果图
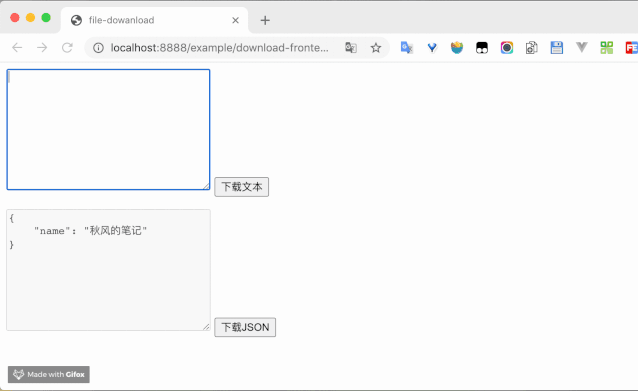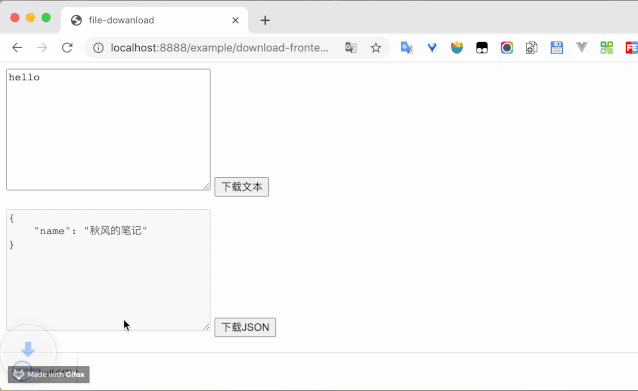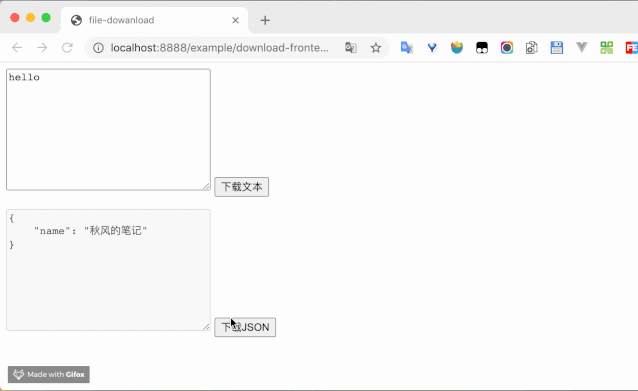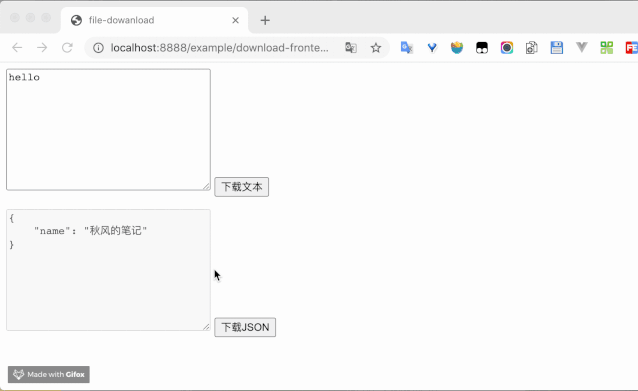
注释代码为 data:URL 的展示部分,由于是第一个例子,因此我讲展示代码,后面都省略了,但是你也可以通过调用 downloadByDataURL 方法,找不到该方法的定义请滑到文章开头哦~
excel
excel 可以说是我们部分前端打交道很深的一个场景,什么数据中台,天天需要导出各种报表。以前都是前端请求后端,来获取一个 excel 文件地址。现在让我们来展示下纯前端是如何实现下载excel。
简单excel
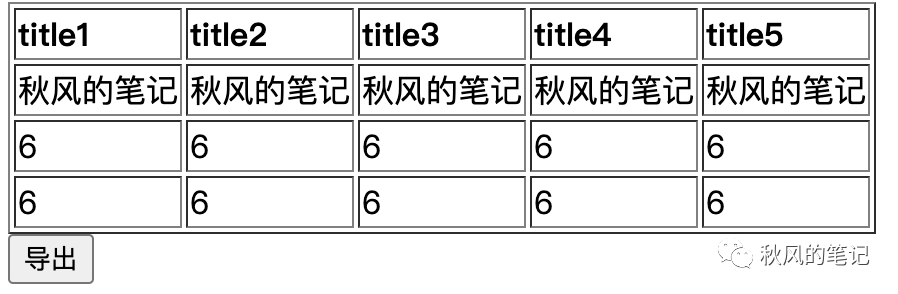
表格长这个模样,比较简陋的形式
const template = '
+'xmlns:x="urn:schemas-microsoft-com:office:excel" '
+'xmlns="http://www.w3.org/TR/REC-html40">'
+''
+''
+'{table}<\/body>'
+'<\/html>';
const context = template.replace('{table}', document.getElementById('excel').innerHTML);
downloadByContent(context, 'qiufengblue.xls', 'application/vnd.ms-excel');
但是编写并不复杂,依旧是和我们之前一样,通过构造出 excel 的格式,转化成 blob 来进行下载。
最终导出的效果

element-ui 导出表格
没错,这个就是 element-ui 官方table 的例子。
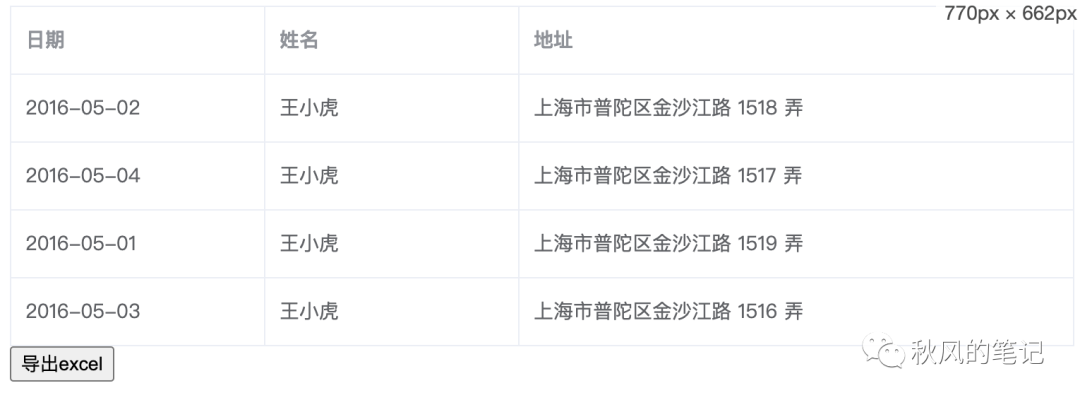
导出效果如下,可以说非常完美。
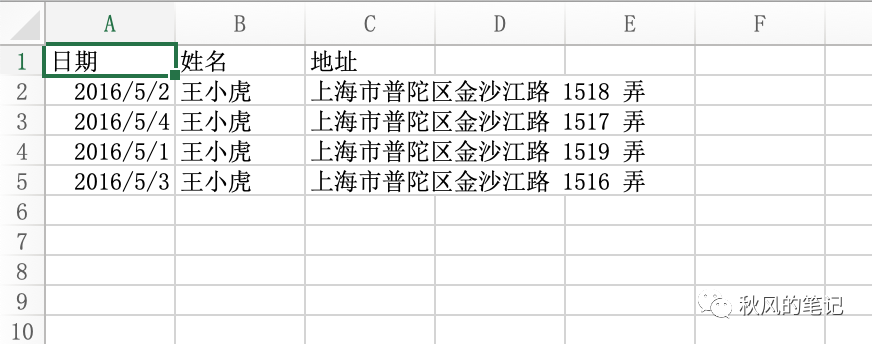
这里我们用到了一个插件 https://github.com/SheetJS/sheetjs
使用起来非常简单。
<template>
<el-table id="ele" border :data="tableData" style="width: 100%">
<el-table-column prop="date" label="日期" width="180">
el-table-column>
<el-table-column prop="name" label="姓名" width="180">
el-table-column>
<el-table-column prop="address" label="地址">
el-table-column>
el-table>
<button @click="exportExcel">导出excelbutton>
template>
<script>
...
methods: {
exportExcel() {
let wb = XLSX.utils.table_to_book(document.getElementById('ele'));
XLSX.writeFile(wb, 'qiufeng.blue.xlsx');
}
}
...
script>

word
讲完了 excel我们再来讲讲 word 这可是 office 三剑客另外一大利器。这里我们依旧是利用上述的 blob 的方法进行下载。
简单示例

代码展示
exportWord.onclick = () => {
const template = '
+'xmlns:x="urn:schemas-microsoft-com:office:word" '
+'xmlns="http://www.w3.org/TR/REC-html40">'
+''
+''
+'{table}<\/body>'
+'<\/html>';
const context = template.replace('{table}', document.getElementById('word').innerHTML);
downloadByContent(context, 'qiufeng.blue.doc', 'application/msword');
}
效果展示
使用 docx.js插件
如果你想有更高级的用法,可以使用 docx.js这个库。当然用上述方法也是可以高级定制的。
代码
<button type="button" onclick="generate()">下载wordbutton>
<script>
async function generate() {
const res = await axios({
method: 'get',
url: 'http://localhost:8888/static/1597375650384.jpg',
responseType: 'blob'
})
const doc = new docx.Document();
const image1 = docx.Media.addImage(doc, res.data, 300, 400)
doc.addSection({
properties: {},
children: [
new docx.Paragraph({
children: [
new docx.TextRun("欢迎关注[秋风的笔记]公众号").break(),
new docx.TextRun("").break(),
new docx.TextRun("定期发送优质文章").break(),
new docx.TextRun("").break(),
new docx.TextRun("美团点评2020校招-内推").break(),
],
}),
new docx.Paragraph(image1),
],
});
docx.Packer.toBlob(doc).then(blob => {
console.log(blob);
saveAs(blob, "qiufeng.blue.docx");
console.log("Document created successfully");
});
}
script>
效果(没有打广告...随便找了张图,强行不承认系列)

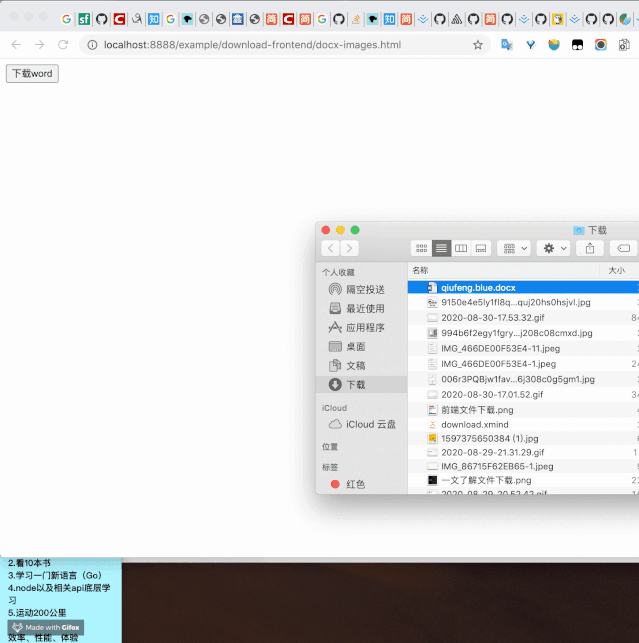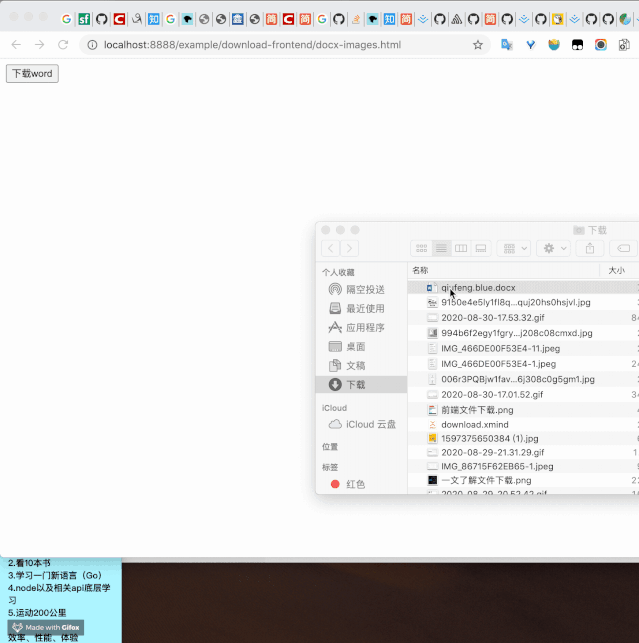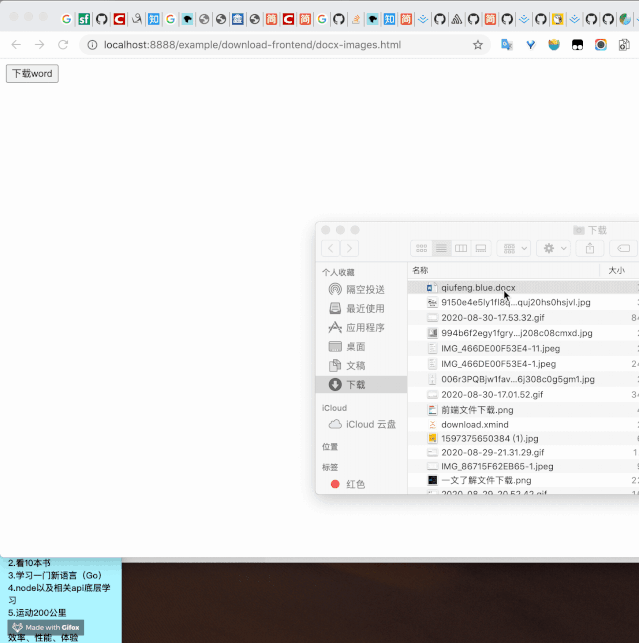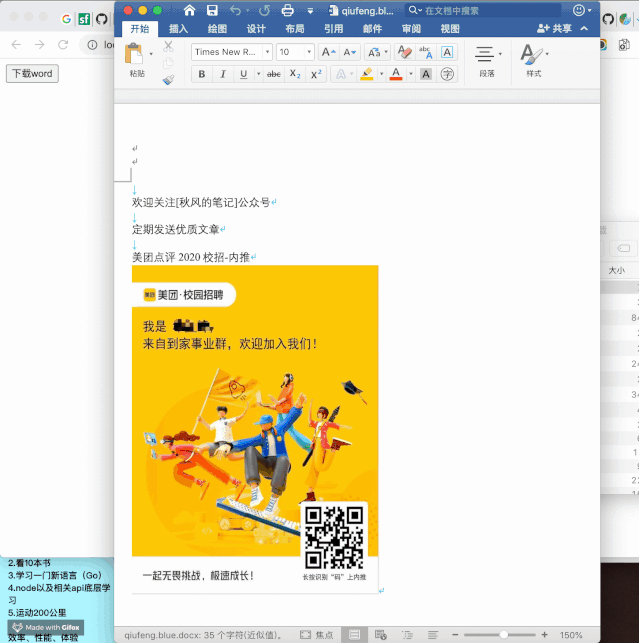
zip下载
前端压缩还是非常有用的,在一定的场景下,可以节省流量。而这个场景比较使用于,例如前端打包图片下载、前端打包下载图标。
一开始我以为我 https://tinypng.com/ 就是用了这个,结果我发现我错了...仔细一想,因为它压缩好的图片是存在后端的,如果使用前端打包的话,反而要去请求所有压缩的图片从而来获取图片流。如果用后端压缩话,可以有效节省流量。嗯。。。失败例子告终。
后来又以为https://www.iconfont.cn/打包下载图标的时候,使用了这个方案....发现....我又错了...但是我们分析一下.
它官网都是 svg 渲染的图标,对于 svg 下载的时候,完全可以使用前端打包下载。但是,它还支持 font 以及 jpg 格式,所以为了统一,采用了后端下载,能够理解。那我们就来实现这个它未完成的功能,当然我们还需要用到一个插件,就是 jszip。
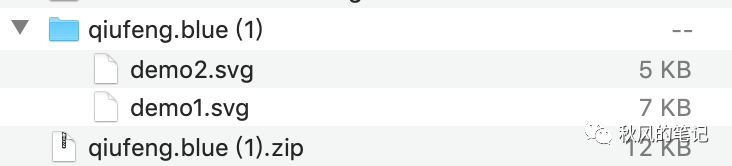
这里我从以上找了两个 svg 的图标。
实现代码
download.onclick = () => {
const zip = new JSZip();
const svgList = [{
id: 'demo1',
}, {
id: 'demo2',
}]
svgList.map(item => {
zip.file(item.id + '.svg', document.getElementById(item.id).outerHTML);
})
zip.generateAsync({
type: 'blob'
}).then(function(content) {
// 下载的文件名
var filename = 'svg' + '.zip';
// 创建隐藏的可下载链接
var eleLink = document.createElement('a');
eleLink.download = filename;
// 下载内容转变成blob地址
eleLink.href = URL.createObjectURL(content);
// 触发点击
eleLink.click();
// 然后移除
});
}

查看文件夹目录,已经将 SVG 打包下载完毕。
浏览器文件系统(实验性)

在我电脑上都有这么一个浏览器,用来学习和调试 chrome 的最新新特性, 如果你的电脑没有,建议你安装一个。
玩这个特性需要打开 chrome 的实验特性 chrome://flags => #native-file-system-api => enable, 因为实验特性都会伴随一些安全或者影响原本的渲染的行为,因此我再次强烈建议,下载一个金丝雀版本的 chrome 来进行玩耍。
<textarea name="" id="textarea" cols="30" rows="10">textarea>
<p><button id="btn">下载button>p>
<script>
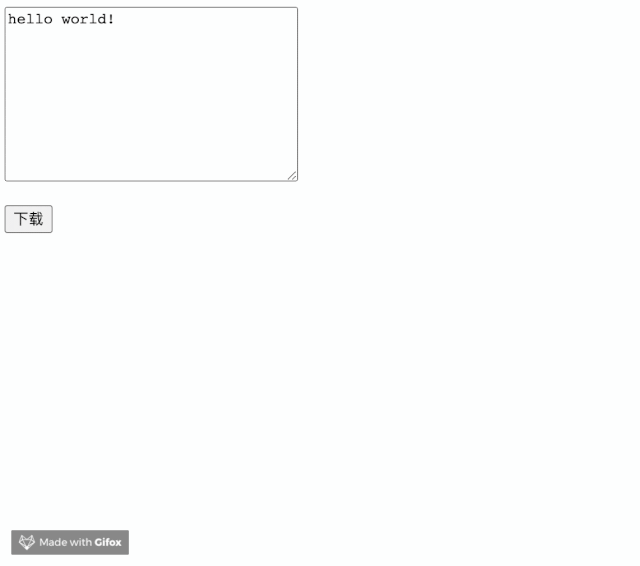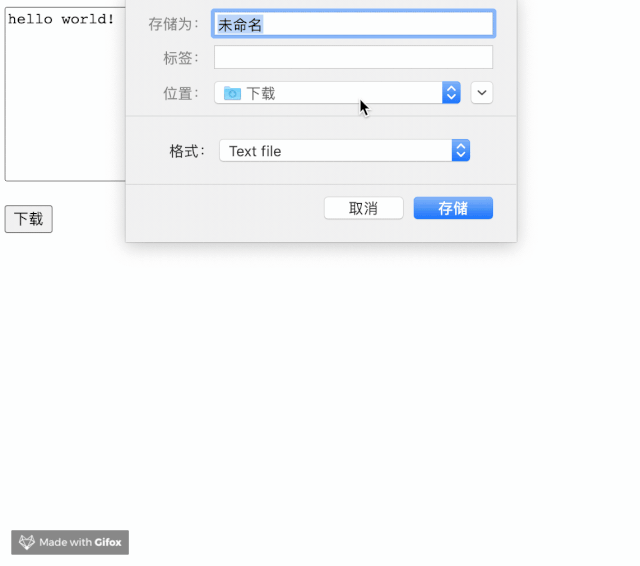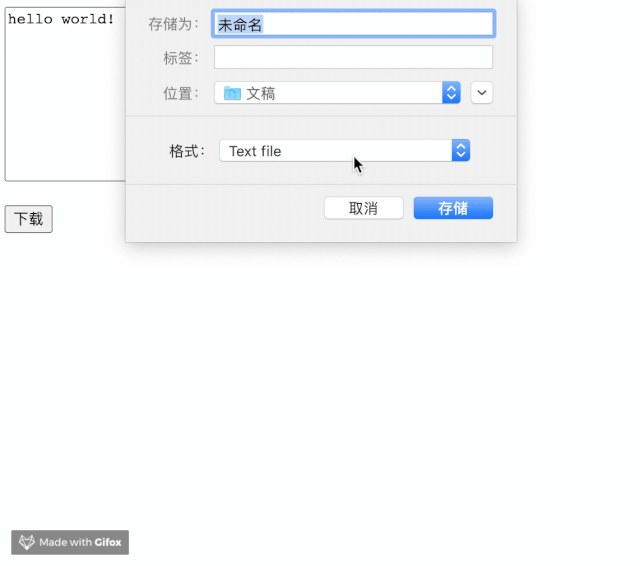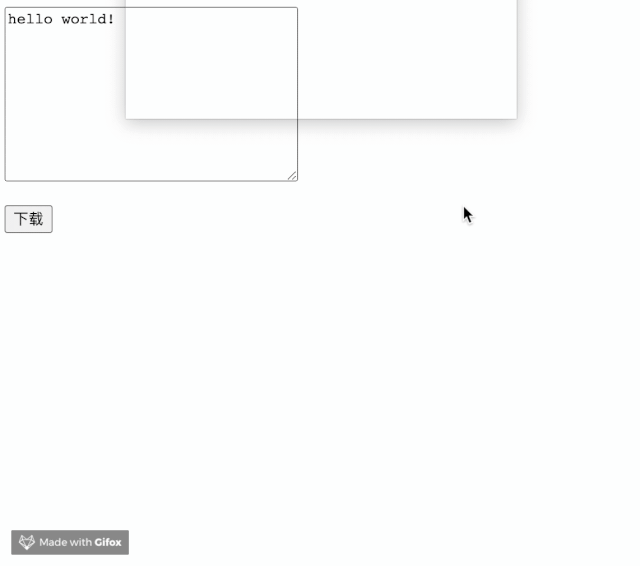
btn.onclick = async () => {
const handler = await window.chooseFileSystemEntries({
type: 'save-file',
accepts: [{
description: 'Text file',
extensions: ['txt'],
mimeTypes: ['text/plain'],
}],
});
const writer = await handler.createWritable();
await writer.write(textarea.value);
await writer.close();
}
script>
实现起来非常简单。却飞一般的感觉。
其他场景
H5文件下载
一般在 h5 下载比较多的是 pdf 或者是 apk 的下载。
Android
在安卓浏览器中,浏览器直接下载文件。
ios
由于ios的限制,无法进行下载,因此,可以使用复制 url ,来代替下载。
import {downloadDirect} from '../js/utils.js';
const btn = document.querySelector('#download-ios');
if (/(iPhone|iPad|iPod|iOS)/i.test(navigator.userAgent)) {
const clipboard = new ClipboardJS(btn);
clipboard.on('success', function () {
alert('已复制链接,打开浏览器粘贴链接下载');
});
clipboard.on('error', function (e) {
alert('系统版本过低,复制链接失败');
});
} else {
btn.onclick = () => {
downloadDirect(btn.dataset.clipboardText)
}
}
更多
对于 apk 等下载包可以使用这个包(本人暂时没有试验,接触不多,回头熟悉了再回来补充。)
https://github.com/jawidx/web-launch-app
大文件的分片下载
最近在开发媒体流相关的工作的时候,发现在加载 mp4 文件的时候,发现了一个比较有意思的现象,视频流并不需要将整个 mp4 下载完才进行播放,并且伴随了很多状态码为 206 的请求,乍一看有点像流媒体(HLS等)的韵味。
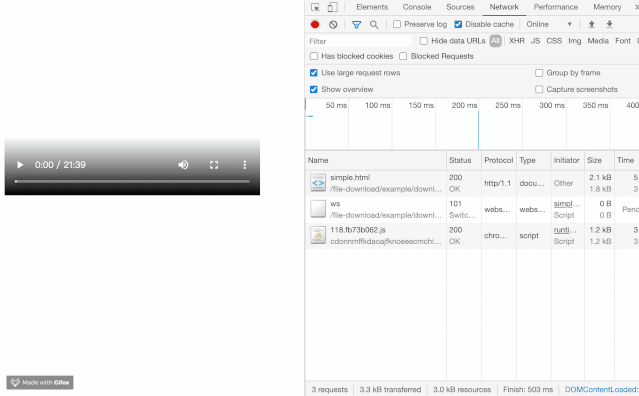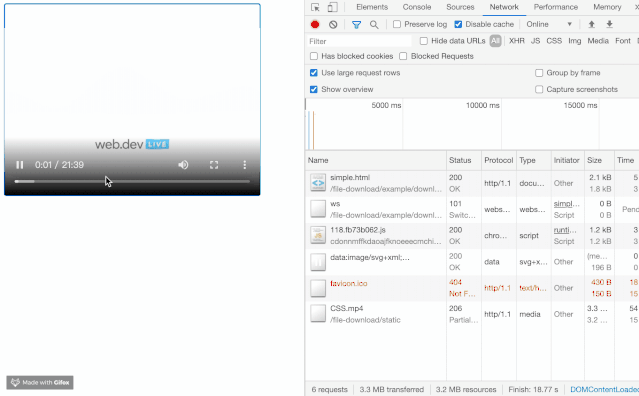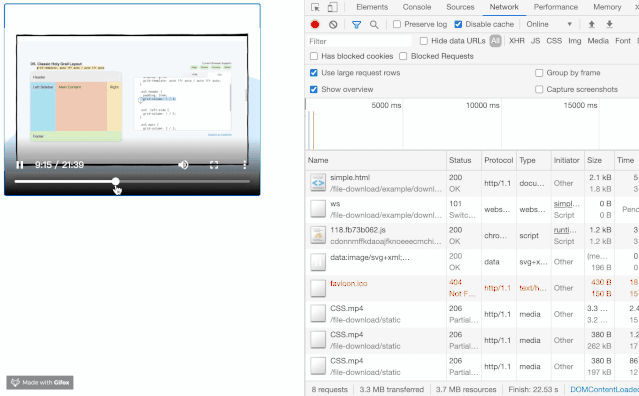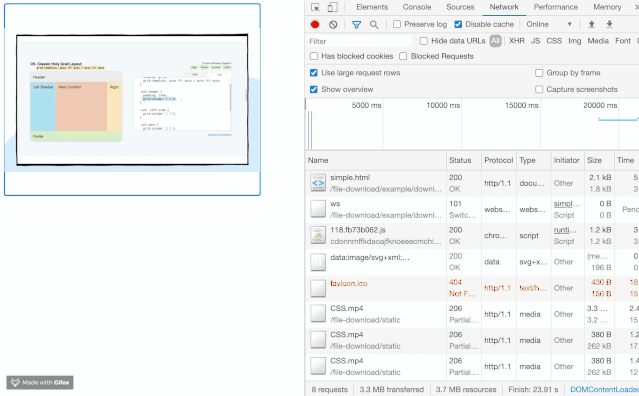
觉得这个现象非常的有意思,他能够分片地加载资源,这对于体验或者是流量的节省都是非常大的帮助。最终发现它带了一个名为 Range 的头。我们来看看 MDN 的解释。
The
Range是一个请求首部,告知服务器返回文件的哪一部分。在一个Range首部中,可以一次性请求多个部分,服务器会以 multipart 文件的形式将其返回。如果服务器返回的是范围响应,需要使用206Partial Content状态码。 摘自 MDN
语法
Range: =-
Range: =-
Range: =-, -
Range: =-, -, -
Node实现
既然我们知道了它的原理,就来自己实现一下。
router.get('/api/rangeFile', async(ctx) => {
const { filename } = ctx.query;
const { size } = fs.statSync(path.join(__dirname, './static/', filename));
const range = ctx.headers['range'];
if (!range) {
ctx.set('Accept-Ranges', 'bytes');
ctx.body = fs.readFileSync(path.join(__dirname, './static/', filename));
return;
}
const { start, end } = getRange(range);
if (start >= size || end >= size) {
ctx.response.status = 416;
ctx.set('Content-Range', `bytes */${size}`);
ctx.body = '';
return;
}
ctx.response.status = 206;
ctx.set('Accept-Ranges', 'bytes');
ctx.set('Content-Range', `bytes ${start}-${end ? end : size - 1}/${size}`);
ctx.body = fs.createReadStream(path.join(__dirname, './static/', filename), { start, end });
})
Nginx实现
发现 nginx 不需要写任何代码就默认支持了 range 头,想着我一定知道它到底是支持,还是加入了什么模块,或者是我默认开启了什么配置,找了半天没有找到什么额外的配置。

正当我准备放弃的时候,灵光一现,去看看源码吧,说不定会有发现,去查了 nginx 源码相关的内容,用了惯用的反推方式,才发现原来是max_ranges这个字段。
https://github.com/nginx/nginx/blob/release-1.13.6/src/http/modules/ngx_http_range_filter_module.c#L166
这也怪我一开始文档阅读不够仔细,浪费了大量的时间。
:) 其实我对 nginx 源码也不熟悉,这里可以用个小技巧,直接在源码库 搜索 206 然后 发现了一个宏命令
#define NGX_HTTP_PARTIAL_CONTENT 206
然后顺藤摸瓜,直接找到这个宏命令NGX_HTTP_PARTIAL_CONTENT用到的地方,这样一步一步就慢慢能找到我们想要的。
默认 nginx 是自动开启 range 头的, 如果不需要配置,则配置 max_range: 0;
Nginx 配置文档 http://nginx.org/en/docs/http/ngx_http_core_module.html#max_ranges
总结
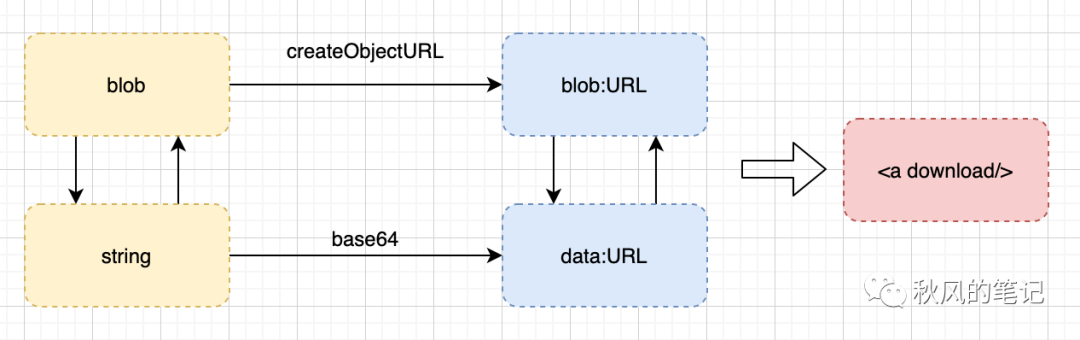
我们可以来总结一下,其实全文主要讲了(xbb)两个核心的知识,一个是 blob 一个a 标签,另外还要注意对于大文件,服务器的优化策略,可以通过 Range 来分片加载。
参考资料
https://github.com/dolanmiu/docx
https://github.com/SheetJS/sheetjs
https://juejin.im/post/6844903763359039501
欢迎关注「前端杂货铺」,一个有温度且致力于前端分享的杂货铺
关注回复「加群」,可加入杂货铺一起交流学习成长