
实操教程|人脸识别模型的动手实践!

极市导读
本文将向大家简单介绍活体检测,并动手完成一个活体检测模型的训练,最终实现对摄像头或者视频中的活体进行识别。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
人脸识别已经成为生活中越来越常见的技术,其中最关键的问题就是安全,而活体检测技术又是保证人脸识别安全性的一个重要手段,本文将向大家简单介绍活体检测,并动手完成一个活体检测模型的训练,最终实现对摄像头或者视频中的活体进行识别。
人脸识别的技术关键——活体检测
一般提到人脸识别技术,即指人脸比对或人脸匹配,即将待识别的人脸和系统中已经提前录入的人脸信息(如身份证照片)进行特征的比对,而在使用神经网络提取特征进行比对之前,需要首先对识别到的人脸进行活体检测,以确定摄像头前的人是个活人。因此整个人脸识别过程一般为(并非一定要这样):人脸检测 -> 关键点检测 -> 人脸对齐 -> 活体检测 -> 人脸特征提取 -> 人脸比对。
模型简介
本项目使用基于resnet18的二分类模型对RGB图像进行活体、非活体的分类识别, 网络结构如图所示,有关于resnet的知识可自行查阅。

数据集简介
本项目数据集使用中科院大型人脸活体检测数据库CASIA-SURF,这是一个包含大量不同年龄段人的多模态(RGB, Depth,IR)的数据集,其中包含大量真实活体人脸样本,也包含了对应的攻击样本(数据集已上传至开源数据平台Graviti)。如图所示,图例中的攻击样本是以打印出来的人脸作为攻击样本,或者露出五官中的部分结合打印人脸一起作为攻击样本,当然还有别的攻击样本制作的形式。因此模型训练的目标就是要在遇到这些攻击样本的时候能够正确识别出它不是一个活体。

其中,RGB表示RGB图片,Depth表示深度图,IR表示近红外图。三个模态的数据可以都用来训练,以使模型适应不同图像采集设备的需求。为了简单,本项目仅使用RGB图像训练。数据集目录结构如图所示:

代码简介
项目环境:python 3.7.4 、pytorch 1.4.0、其余的opencv、numpy啥的看缺啥装啥吧。。。项目代码目录如图所示(代码地址见文末):

其中,alive_detect为自定义的文件夹,里面存放了一些测试视频,人脸检测模型权重等等文件。loss文件夹内存放了一些损失函数的实现 model文件夹内存放了一些模型的实现models文件夹是模型训练过程中权重的保存路径 process文件夹内存放了一些关于数据处理相关的代码metric.py实现了一些指标的计算utils.py实现了一些训练或测试用到的小功能函数train_CyclicLR.py是训练代码,执行这个代码即可启动训练train_Fusion_CyclicLR.py是多模态数据的训练代码。即同时使用上述数据集中的三种模态的数据进行训练face_recognize.py是使用训练好的模型进行活体检测测试的代码项目代码中给出了训练好的模型权重示例,models/baseline_color_32/checkpoint/global_min_acer_model.pth。执行脚本face_recognize.py,即可调用训练好的模型完成活体检测。
训练过程示例
以resnet18模型为例,使用数据集中的RGB图片进行训练,输入模型尺寸大小为32。
开始训练:
cd alive_recognize_project#开启训练#--model baseline , 以resnet18为例,可选其他模型,自行探索#--image_size 32 , 输入活体检测模型的人脸图像大小为32#--cycle_num 5,训练5个cycle周期#--cycle_inter 50, 每个cycle周期内训练50个epoch#--mode train , 开启训练模型python train_CyclicLR.py --model baseline --image_mode color --image_size 32 --cycle_num 5 --cycle_inter 50 --mode train
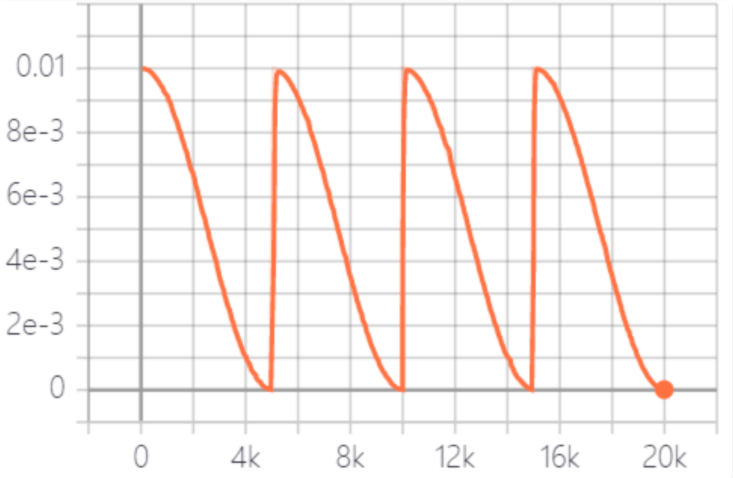
对cycle_num和cycle_inter参数的说明,本项目学习率衰减策略采用周期性余弦衰减,cycle_num表示周期数,cycle_inter表示一个周期内训练的epoch数,即每经过cycle_inter个epoch,学习率从初始值下降到最低值,如下图所示。
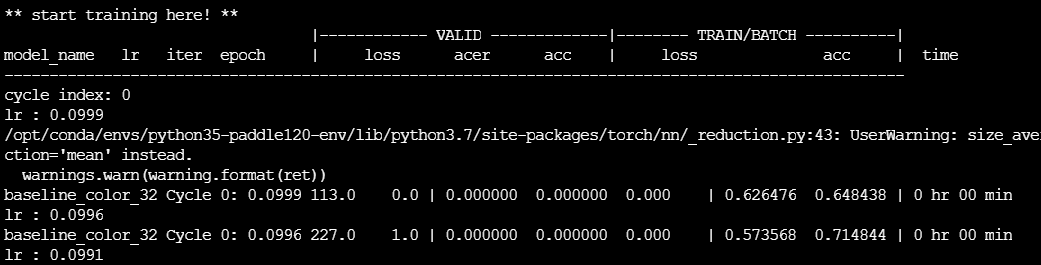
然后就开始训练了,期间会打印出一些训练过程中的loss、acc、acer等信息,如需要别的日志信息可自行修改。
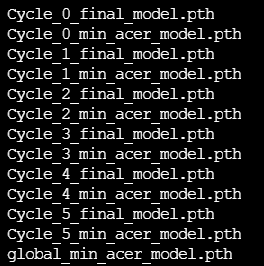
训练完成后的模型保存在路径models/baseline_color_32/checkpoint下,默认保存每个周期内最低acer模型、最后一个epoch训练结束的模型和全局最低acer模型,如下图所示。
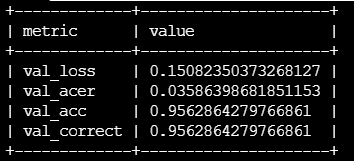
在验证集上测试模型
python train_CyclicLR.py --mode infer_test --model baseline --image_mode color --image_size 32 --batch_size 8
验证集上结果,ACER=0.0358
模型效果测试
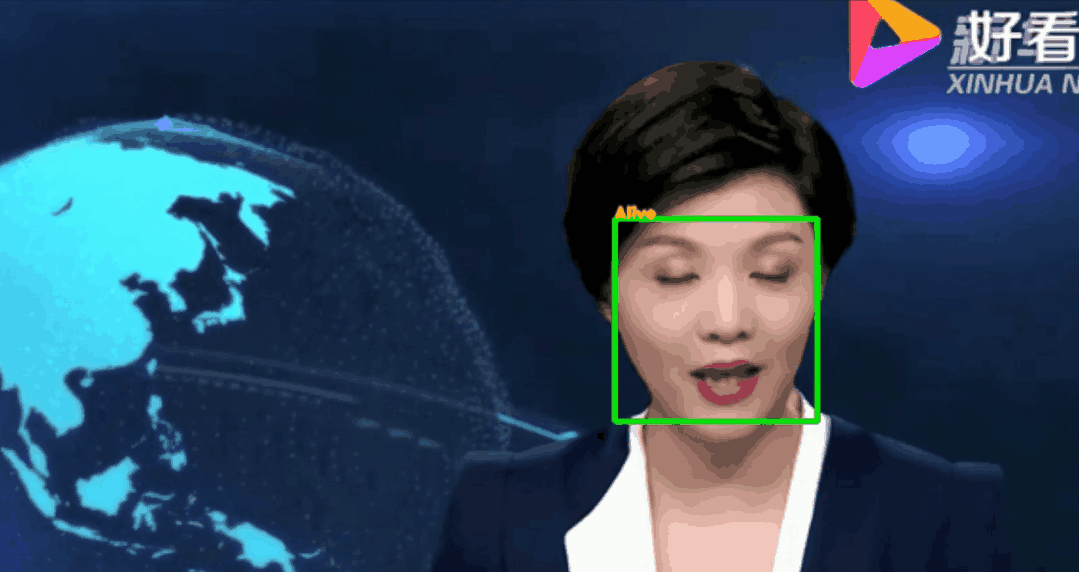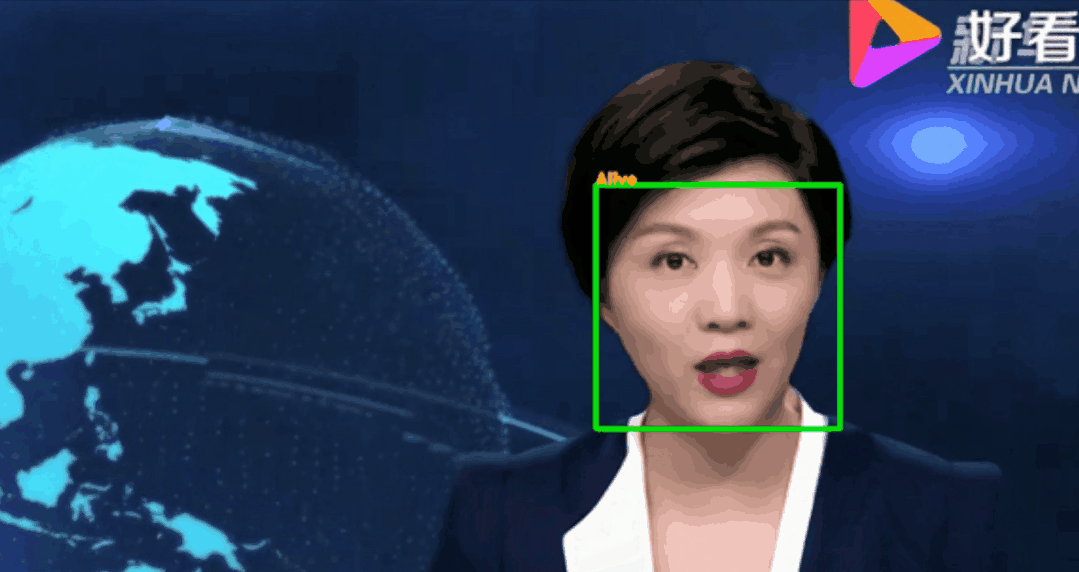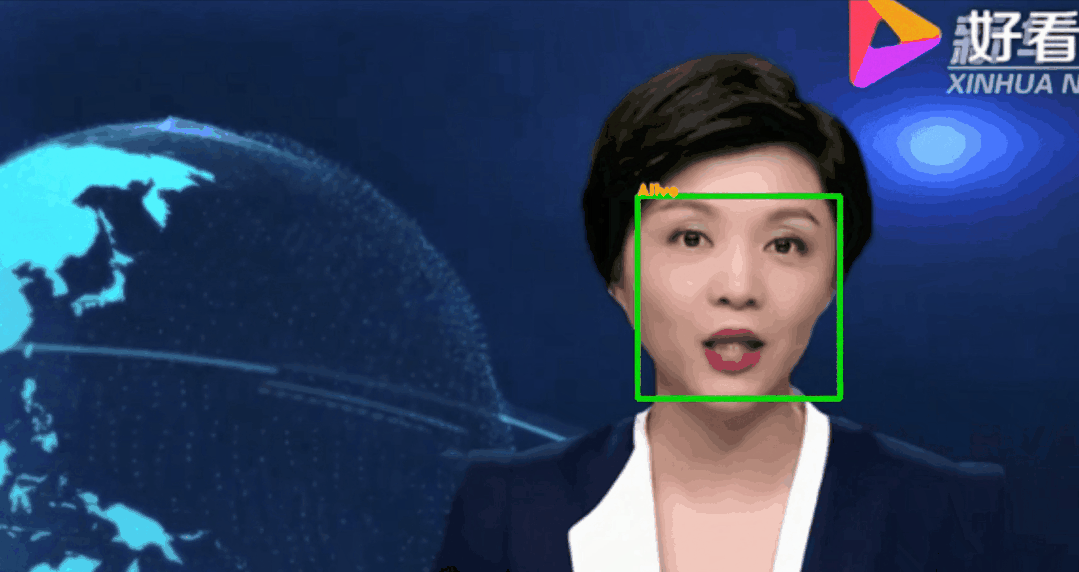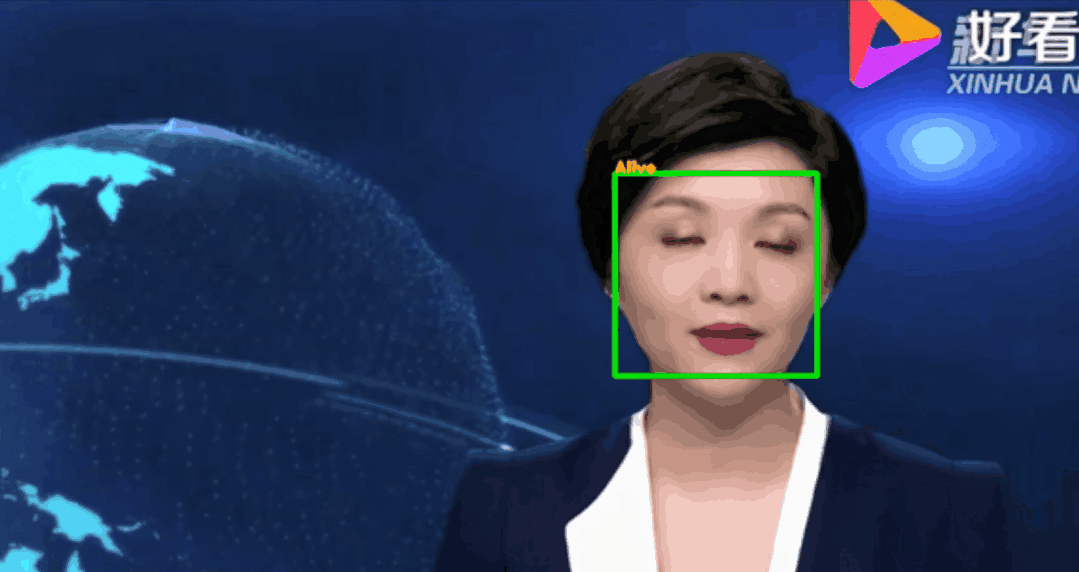
调用训练好的模型,对视频中的人脸进行活体检测。(也可以检测摄像头前的自己,本项目以视频文件为例)测试脚本face_recognize.py参数:--alive_detect_model:活体检测模型权重--key_point_detect_model:关键点检测模型,路径为alive_detect/shape_predictor_68_face_landmarks.dat--detect_vidio:待检测的视频片段存放路径--detect_res:视频片段的检测结果存放路径
测试代码示例:
python face_recognize.py --alive_detect_model models/baseline_color_32/checkpoint/global_min_acer_model.pth --key_point_detect_model alive_detect/shape_predictor_68_face_landmarks.dat --detect_vidio alive_detect/video_demo.mov --detect_res alive_detect/res_video_demo.avi
注:--detect_res保存的视频文件默认avi格式,若需要保存其他格式可以自行修改代码。测试结果示例
扩展
关于模型训练,可继续调参以期在验证集获得更好的效果。 关于数据集,可以使用全部三种模态的数据,使用FaceBagNet模型进行多模态人脸活体检测模型的训练。已经给出相关代码,可自行查看。
数据集获取:https://gas.graviti.cn/dataset/datawhale/CASIA-SURF
代码地址:https://github.com/ZJUTSong/Alive_Detect

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
