
数据特征分析技能——统计分析
统计指标对定量数据进行统计描述,常从集中趋势和离中趋势两个方面进行分析
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
% matplotlib inline1
2
3
4
集中趋势度量
指一组数据向某一中心靠拢的倾向,核心在于寻找数据的代表值或中心值
取得集中趋势代表值的方法有两种:数值平均数和位置平均数
- 数值平均数
- 算数平均数
- 调和平均数
- 几何平均数
- 位置平均数
- 众数
- 中位数
数值平均数
算数平均数
关注数值,鲁棒性弱(稳定性较弱,易受到异常值影响)
data = pd.DataFrame({'value':np.random.randint(100,120,100),
'f':np.random.rand(100)})
data['f'] = data['f'] / data['f'].sum() # f为权重,这里将f列设置成总和为1的权重占比
print(data.head())
print('-----------------')
# 算数平均值
mean = data['value'].mean()
print('算数平均数为:%.2f'%mean)
mean_w = (data['value'] * data['f']).sum() / data['f'].sum()
print('加权算数平均值为:%.2f'%mean_w)
# 加权算数平均值 = (x1f1 + x2f2 + ... + xnfn) / (f1 + f2 + ... + fn)1
2
3
4
5
6
7
8
9
10
11
12
13
f value
0 0.014970 118
1 0.007184 116
2 0.007459 101
3 0.005892 110
4 0.016599 119
-----------------
算数平均数为:110.09
加权算数平均值为:110.69
1
2
3
4
5
6
7
8
9
几何平均数
计算几何平均数要求各观察值之间存在连乘积关系,它的主要用途是
1. 对比率、指数等进行平均
2. 计算平均发展速度
- 样本数据非负,主要用于对数正态分布
3. 复利下的平均年利率
4. 连续作业的车间求产品的平均合格率
几何平均数
# 一位投资者持有股票,1996年,1997年,1998年,1999年收益率分别为
# 4.5%, 2.0%, 3.5%, 5.4%,
# 求此4年内平均收益率
from scipy.stats import gmean
data_g = gmean(data['value'])
data_g1
2
3
4
5
6
109.96165465844449
1
位置平均数
中位数:
- 关注顺序,鲁棒性强众数:
- 关注频次
# 中位数
med = data['value'].median()
print('中位数为%i' % med)
# 中位数指将总体各单位标志按照大小顺序排列后,中间位置的数字
# 众数
m = data['value'].mode()
print('众数为',m.tolist())
# 众数是一组数据中出现次数最多的数,这里可能返回多个值
# 密度曲线
data['value'].plot(kind='kde',style='--k',grid=True,figsize=(10,6))
# 简单算术平均
plt.axvline(mean,hold=None,color='r',linestyle='--',alpha=0.8)
plt.text(mean+5,0.005,'简单算术平均值:%.2f' % mean,color='r',fontsize=15)
# 加权平均数
plt.axvline(mean_w,hold=None,color='b',linestyle='--',alpha=0.8)
plt.text(mean+5,0.01,'加权平均值:%.2f' % mean_w,color='b',fontsize=15)
# 几何平均数
plt.axvline(data_g,hold=None,color='g',linestyle='--',alpha=0.8)
plt.text(mean+5,0.015,'几何平均值:%.2f' % data_g,color='g',fontsize=15)
# 中位数
plt.axvline(med,hold=None,color='y',linestyle='--',alpha=0.8)
plt.text(mean+5,0.020,'几何平均值:%.2f' % med,color='y',fontsize=15)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
中位数为110
众数为 [108]
1
2

离中趋势度
是指一组数据中个数据值以不同程度偏离其中心(平均数)的趋势,又称标志变动度
# 创建数据,销售数据
data = pd.DataFrame({'A_sale':np.random.rand(30)*1000,
'B_sale':np.random.rand(30)*1000},
index = pd.period_range('20170601','20170630'))
print(data.head())1
2
3
4
5
A_sale B_sale
2017-06-01 574.693080 970.059264
2017-06-02 278.487440 683.602258
2017-06-03 830.472896 293.102768
2017-06-04 505.211093 268.009253
2017-06-05 316.383594 134.011541
1
2
3
4
5
6
极差与分位差
极差:
- 没有考虑中间值的变动情况,测定离中趋势时不准确分位差:
- 从一组数据踢出部分极端值后的从新计算类似极差的指标,常用的有四分位差,八分位差
a_r = data['A_sale'].max() - data['A_sale'].min()
b_r = data['B_sale'].max() - data['B_sale'].min()
print('A产品销售额极差为:%.2f,B产品销售额极差为:%.2f'%(a_r,b_r))1
2
3
A产品销售额极差为:920.98,B产品销售额极差为:914.30
1
sta = data['A_sale'].describe()
stb = data['B_sale'].describe()
#print(sta)
a_iqr = sta.loc['75%'] - sta.loc['25%']
b_iqr = stb.loc['75%'] - stb.loc['25%']
print('A销售额的分位差为:%.2f, B销售额的分位差为:%.2f' % (a_iqr,b_iqr))1
2
3
4
5
6
A销售额的分位差为:481.57, B销售额的分位差为:508.45
1
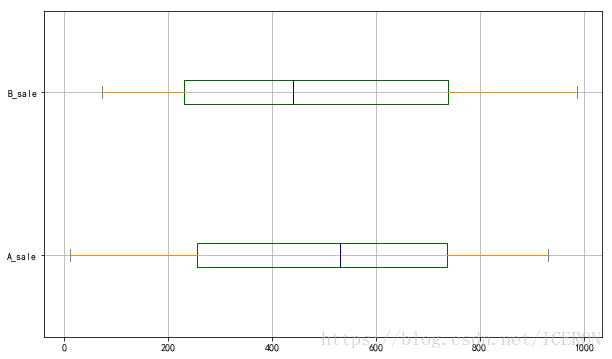
# 绘制箱型图
color = dict(boxes='DarkGreen', whiskers='DarkOrange', medians='DarkBlue', caps='Gray')
data.plot.box(vert=False,grid = True,color = color,figsize = (10,6))
# 箱型图1
2
3
4
5
方差与标准差
平均差:平均差是总体所有单位与其算术平均数的离差绝对值的算术平均数,1范数,异常值影响
M D = ∑ N ‖ x − x ¯ ‖ N 方差:差的平方的均值,2范数,异常值影响
总体方差
样本方差
标准差:方差的算数平方根(应用最广)
平均差 VS 方差:对异常值的敏感程度不同
离散系数(常用的是标准差系数:数据标准差和算数平均数的比)
a_std = sta.loc['std']
b_std = stb.loc['std']
a_var = data['A_sale'].var()
b_var = data['B_sale'].var()
print('A销售额的标准差为:%.2f, B销售额的标准差为:%.2f' % (a_std,b_std))
print('A销售额的方差为:%.2f, B销售额的方差为:%.2f' % (a_var,b_var))
# 方差 → 各组中数值与算数平均数离差平方的算术平均数
# 标准差 → 方差的平方根
# 标准差是最常用的离中趋势指标 → 标准差越大,离中趋势越明显1
2
3
4
5
6
7
8
9
A销售额的标准差为:292.12, B销售额的标准差为:293.35
A销售额的方差为:85331.19, B销售额的方差为:86052.83
1
2
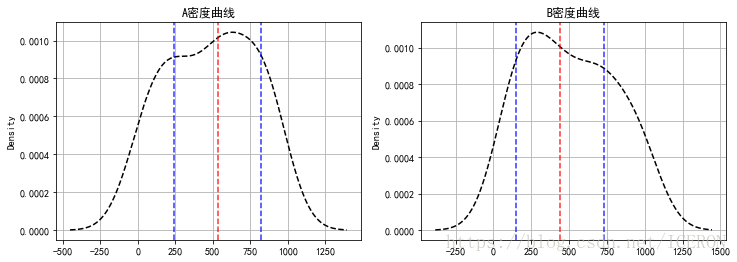
fig = plt.figure(figsize = (12,4))
ax1 = fig.add_subplot(1,2,1)
data['A_sale'].plot(kind = 'kde',style = 'k--',grid = True,title = 'A密度曲线')
plt.axvline(sta.loc['50%'],hold=None,color='r',linestyle="--",alpha=0.8)
plt.axvline(sta.loc['50%'] - a_std,hold=None,color='b',linestyle="--",alpha=0.8)
plt.axvline(sta.loc['50%'] + a_std,hold=None,color='b',linestyle="--",alpha=0.8)
# A密度曲线,1个标准差
ax2 = fig.add_subplot(1,2,2)
data['B_sale'].plot(kind = 'kde',style = 'k--',grid = True,title = 'B密度曲线')
plt.axvline(stb.loc['50%'],hold=None,color='r',linestyle="--",alpha=0.8)
plt.axvline(stb.loc['50%'] - b_std,hold=None,color='b',linestyle="--",alpha=0.8)
plt.axvline(stb.loc['50%'] + b_std,hold=None,color='b',linestyle="--",alpha=0.8)
# B密度曲线,1个标准差1
2
3
4
5
6
7
8
9
10
11
12
13
14
推荐阅读
《数据科学与人工智能》公众号推荐朋友们学习和使用Python语言,需要加入Python语言群的,请扫码加我个人微信,备注【姓名-Python群】,我诚邀你入群,大家学习和分享。