
推荐中的召回算法—总结串讲
1. 工业界召回的基本思路
大家都知道,推荐系统基本上由召回-粗排-精排组成,其中召回的主要作用是,在海量的候选中找到用户可能感兴趣的内容,由于召回位置靠前且输入空间较大,所以时延要求较高。
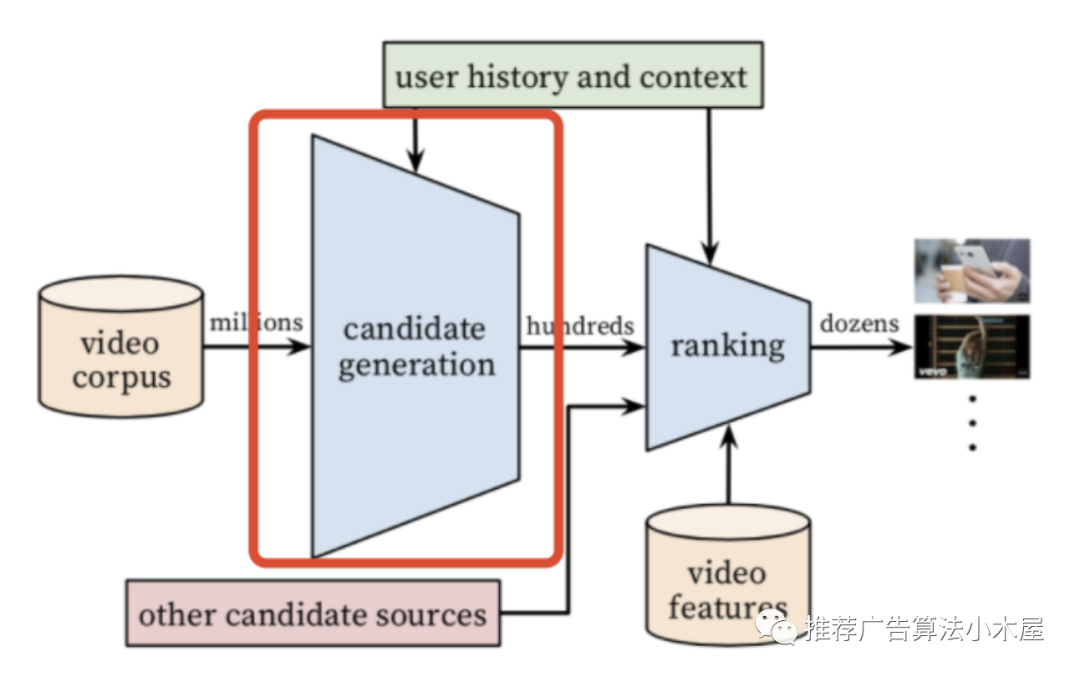
在工业界一般是多路召回并发调用,多路merge之后是小几千或者几百的量级,常见的有以下几大类:
基础属性召回:简单来讲就是人主观觉得有效的策略,比如热门召回、地域召回、家乡召回、标题召回等
产品&运营策略召回:比如节日、活动等定制场景
试探类召回:由于推荐系统容易产生“信息茧房”,瓶颈主要就在召回端,像EE等方式均属于试探类的典型应用
社交类召回:典型例子就是微信视频号,会把你好友点赞的视频推给你
模型类召回:用模型来做召回,一般来讲效果最好迭代时间也较长,本文主要介绍的就是该类召回
下面会罗列工业界常用的召回模型,像NLP+策略、协同过滤等我就懒得赘述了,本文主要介绍基础的向量化召回、行为序列建模召回、图召回和一些自己的感想看法。本来还总结一下工程上的一些东西和实践后的一些结论,但是发现好像都和业务联系太紧密了,为了避免被公司查水表就删了。
介于篇幅和时间所限,我只列举了我所知的在一线大厂有落地的经典算法,各类算法我会提纲挈领地阐述思想,一些具体细节可以看我引用的论文或者博客。(微信论文链接放不了,可以看我知乎的文章版本,里面每个小节都放了链接,知乎直接搜iwtbs)
2. 基础的向量化召回
本质上讲是将召回建模成在向量空间内的近邻搜索问题,将用户和物品均由向量表示,离线构建索引,在serving时模糊近邻查找。
2.1 YoutubeDNN
Deep Neural Networks for YouTube Recommendations是一篇做推荐必读的论文,王喆的两篇文章也让我受益很多
王喆:重读Youtube深度学习推荐系统论文,字字珠玑,惊为神文
王喆:YouTube深度学习推荐系统的十大工程问题
简单总结一下,输入用户属性特征和历史行为序列,经过NN网络做softmax,在当时有价值的一点是最终softmax之前的网络层可以当作是u_vec,且使用了负采样加速训练,线上使用ANN做serving加速。即将group的embedding离线构建好,线上只需要计算user的embeeding并查找就好,充分发挥了NN网络的拟合能力,还不影响速度

2.2 DSSM双塔召回
DSSM论文地址,DSSM全称是Deep Structured Semantic Model ,最开始是解决搜索问题,后来在推荐召回阶段被广泛使用,基本结构就是user和group侧分别用NN网络来拟合,最上层的神经元可认为是user和group的向量表征。CTR召回可以直接用点积+sigmod得到loss,时长模型可以用cos距离+mse计算loss
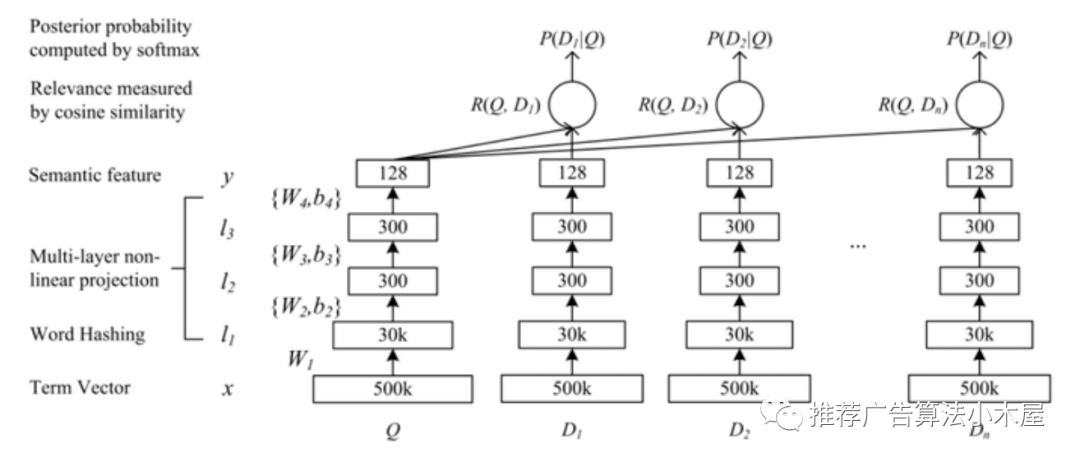
双塔模型结构简单效果好,经过了工业界的考验,也有一些技巧:
双塔模型在工程上一般离线提前构建好group侧的embedding,线上只计算user_emd,然后通过ANN的方式进行快速查找
双塔一般不使用u-g交叉特征,因为一旦使用就很难离线提前构建好group_emd的查找图
ANN的构建方法也会影响双塔结构,比如使用HNSW建图依赖欧氏距离,双塔使用点积作为loss和目标并不一致,可以做归一化
双塔只是一种结构范式,其本身有很多可以根据业务场景创新的点:比如使用短期和长期兴趣构建长短期兴趣建模;通过胶囊网络建模用户多兴趣;使用泛化特征优化用户冷启动。
双塔存在的一个问题是,只有最后的MLP层才能进行ug的交互,比较细粒度的特征可能无法表征。之前在某手实习的时候是采用下层和上层拼接后再点积解决的,前段时间看俊林老师也写了一篇文章介绍他们的做法,简单来讲是通过SENet动态抑制无效特征张俊林:SENet双塔模型:在推荐领域召回粗排的应用及其它
2.3 FM召回
这个我之前写过一篇文章,介绍了FM召回的原理和实践,以及常用的ANN算法,这里就不多介绍了,主体思路依旧是构建向量,然后离线建group_emd,线上计算user_emd再近邻查找。从原理上来讲,我觉得双塔比起FM有更强的泛化拟合能力,且方便怼特征,也一定程度上比FM能更好地缓解bias现象。
3. 行为序列建模召回
3.1 RNN序列召回
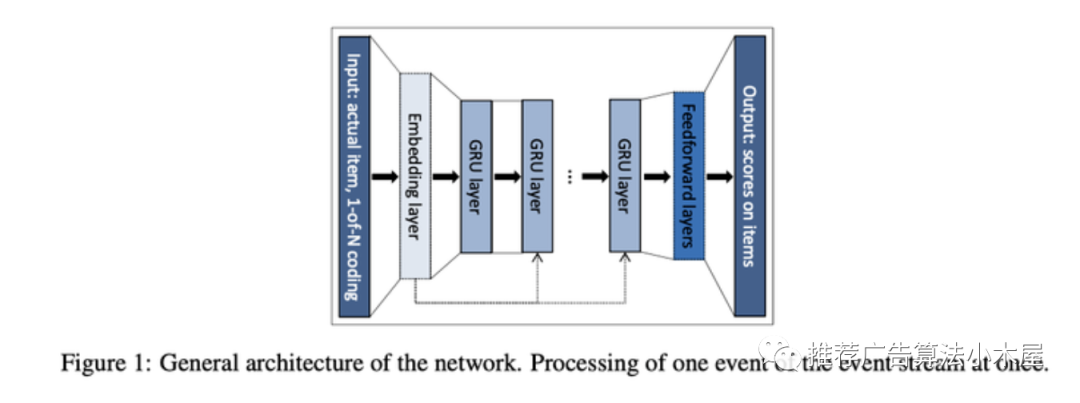
建模用户单一的短期兴趣,最简单的就是直接把rgid做pooling或者attention,这里介绍一个比较经典的序列召回方法GRU4REC。相应的网络结构其实很简单,使用用户session中的点击序列作为模型输入,输出则为用户下次点击的item相应的得分
3.2 MIND多兴趣召回
文章名为Multi-Interest Network with Dynamic routing论文链接,其基本思想是用户兴趣多样,仅用一个向量表征用户兴趣是有偏的,如果能构建多个user_emd某种程度上就能召回出更全的候选,该论文采用胶囊网络来建模用户多种兴趣。
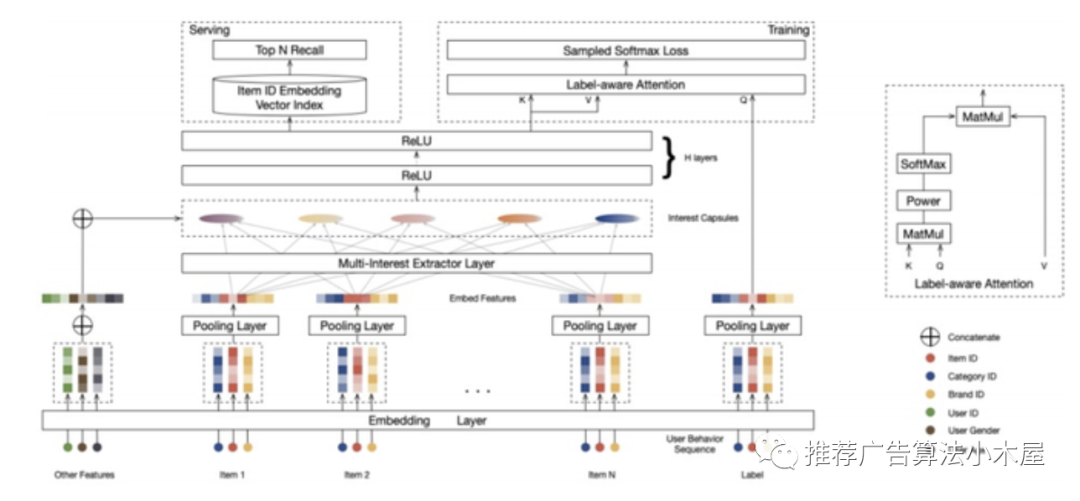
模型结构如上,将历史行为序列输入动态路由网络层输出N个兴趣表征向量,每个兴趣向量分别和用户画像的Embedding concat,输入到relu神经网络,输出多个经过非线性变换的兴趣向量,输出的多个兴趣向量再和 Label Item做个Label-aware Attention,从多个兴趣向量中选择一个,最后通过 Softmax 层构建ug_emd。MIND 模型的线上部署可以分成两部分内容,一部分是生成用户的多兴趣向量,另一部分是通过多个兴趣向量进行向量检索。

实践中要根据业务来评估建模多兴趣的收益,比如阿里的电商业务做多兴趣就非常必要。从模型角度来评估是否有必要,可以离线打印一下各个u_emd的召回内容和向量距离,如果召回内容有显著差距且向量距离大则说明有价值,如果本身距离很近则说明用一个向量表征用户兴趣已经绰绰有余。
3.3 SDM长期兴趣建模
SDM 论文链接并非直接取用户近期行为(长度 50~100)进行建模,而是将用户行为进行session化。定义当前行为的session为用户的短期兴趣,发生在该session之前到一周内的历史行为为长期兴趣。并且把短期兴趣Embedding和长期兴趣Embedding做融合,代表用户兴趣向量。这个insight在电商场景我觉得肯定有价值,因为我购物就是短期和长期并不一致,但是长期兴趣对短期的推荐有很大价值。如果是长短期兴趣差距并不大的场景,比如听音乐我觉得就没什么作用,我自己的音乐品类在数年前和今天差距都变化不大。
回到论文本身,Session 定义主要包括:系统后台标识相同的 Session Id 的;两次行为在10分钟以内的;长度在50以内的。大致上本文和爱彼迎、DSIN等的划分思路基本差不多,有一些阈值需要根据业务进行分析调整。
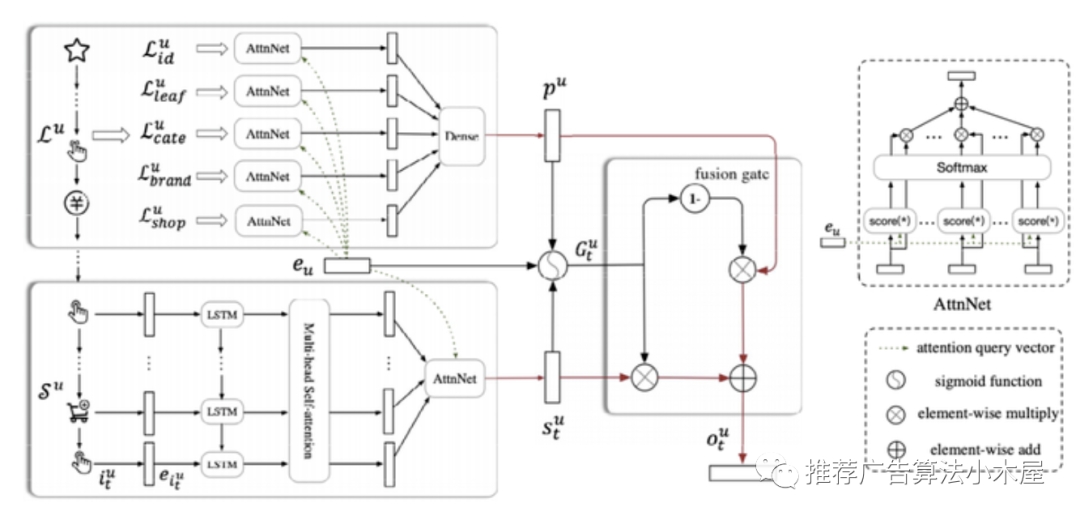
对用户长短期数据,分不同方式处理:
对于长期行为序列:使用item_id,cate_id,cate_level1_id,shop_id,brand_id 等行为序列。以用户画像embedding 作为 query 向量分别做 user attention。
对于短期行为序列,借鉴 GRU4REC。具体做法:拿最近一个Session的行为序列,同时考虑到即使用户行为在一个session内仍然会表现出用户的多兴趣倾向。使用multi-head attention将RNN表达的用户动态兴趣投影到不同兴趣空间,然后通过一个矩阵进行聚合,最后做个User Attention。
代码复现可以参考一袋米抗三楼:SDM(Sequential Deep Matching Model)的复现之路
4. 图召回
4.1 通用Graph Embedding模型
如果对DeepWalk等基础图嵌入算法没有了解,建议先阅读相关资料。这里推荐浅梦的github,https://github.com/shenweichen/GraphEmbedding。
以DeepWalk为例,利用用户的行为数据构造出item的有向图。再通过随机游走的方式生成item序列,然后把item序列当成句子,以word2vec的方式进行训练,最终生成每个item的embedding。至于具体用物品图、还是用户-物品图、随机采样还是概率采样等都可以根据业务实验效果来定。

4.2 EGES
Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba,在EGES中为了解决冷启动问题引入了side information的概念。将商品的商店、价格、类型等特征放入到模型里面训练。因此输入不仅是item的embedding, 还包括item对应的商店,价格,分类的embedding。
由于对于不同的商品,每个side information对商品的影响程度是不一样的。因此为不同的商品的side information赋予了不一样的权重,整体结构如下图所示。
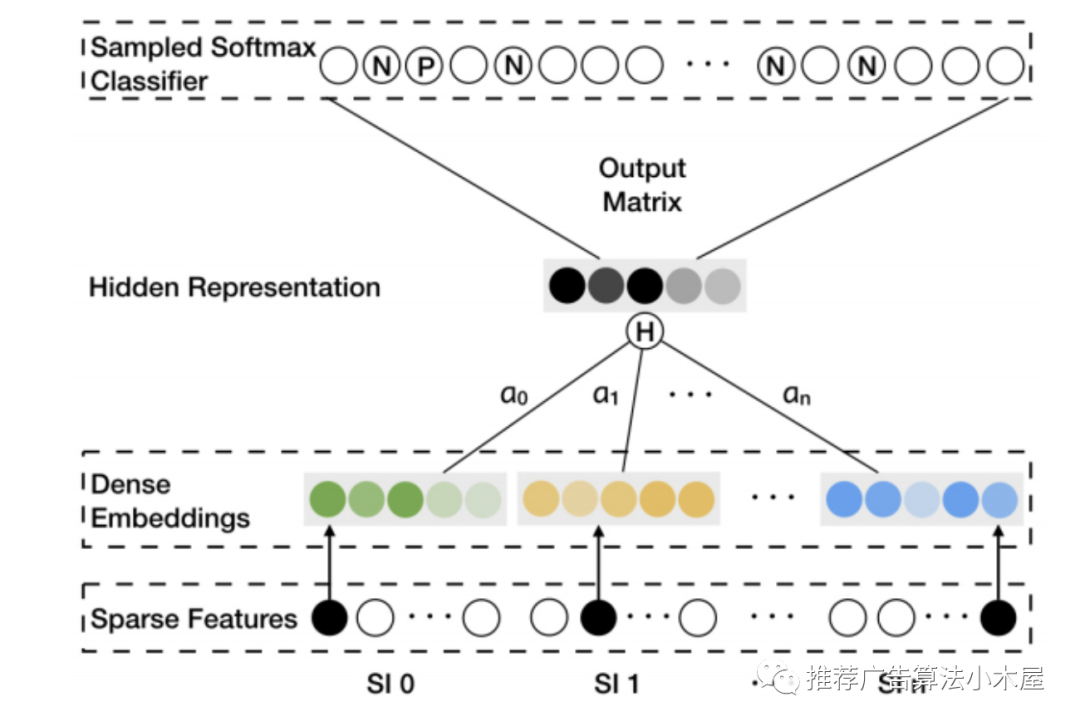
其中SI 0表示商品,SI 1到SI n表示商品的各个side information。a0,a1到an表示embedding做averge pooling时候的的权重因子,相关实现可参考wangzhegeek/EGES
4.3 图卷积网络
与DeepWalk等不同在于使用了卷积的方式,而这里卷积算子和CV中有所不同,但本质也是学习某个节点周边其他节点信息。GCN是谱图卷积的一阶局部近似,是一个多层的图卷积神经网络,每一个卷积层仅处理一阶邻域信息,通过叠加若干卷积层可以实现多阶邻域的信息传递。
但是GCN要求在一个确定的图中去学习顶点的embedding,无法直接泛化到在训练过程没有出现过的顶点,GraphSAGE则是一种能够利用顶点的属性信息高效产生未知顶点embedding的一种归纳式学习的框架,其核心思想是通过学习一个对邻居顶点进行聚合表示的函数来产生目标顶点的embedding向量。GraphSage论文链接

步骤主要是:1. 对图中每个顶点邻居顶点进行采样 ;2. 根据聚合函数聚合邻居顶点蕴含的信息 ;3. 得到图中各顶点的向量表示供下游任务使用。
PinSage底层算法就是 GraphSAGE,只不过为了将其落地做了一系列的改进,我自己没有深入研究过,感兴趣的可以自己看论文Graph Convolutional Neural Networks for Web-Scale Recommender Systems
4.4 知识图谱召回
利用知识图谱作为辅助信息生成推荐可以缓解冷启动和泛化不足的问题,而且可以对推荐的结果进行解释,尤其是一些泛化内容仅仅通过自身数据是学不到的。由于知识图谱我没有深入做过,也就没什么经验和感悟可谈了,这里仅列一篇2020年关于知识图谱+推荐综述。
BELIEVE:一文概览知识图谱在推荐系统的发展现状
5. 深度检索召回模型
不再是离线训练并构建group_emd线上计算user_emd然后ANN的方式,而是端到端地做召回。
5.1 阿里TDM
Learning Tree-based Deep Model for Recommender Systems
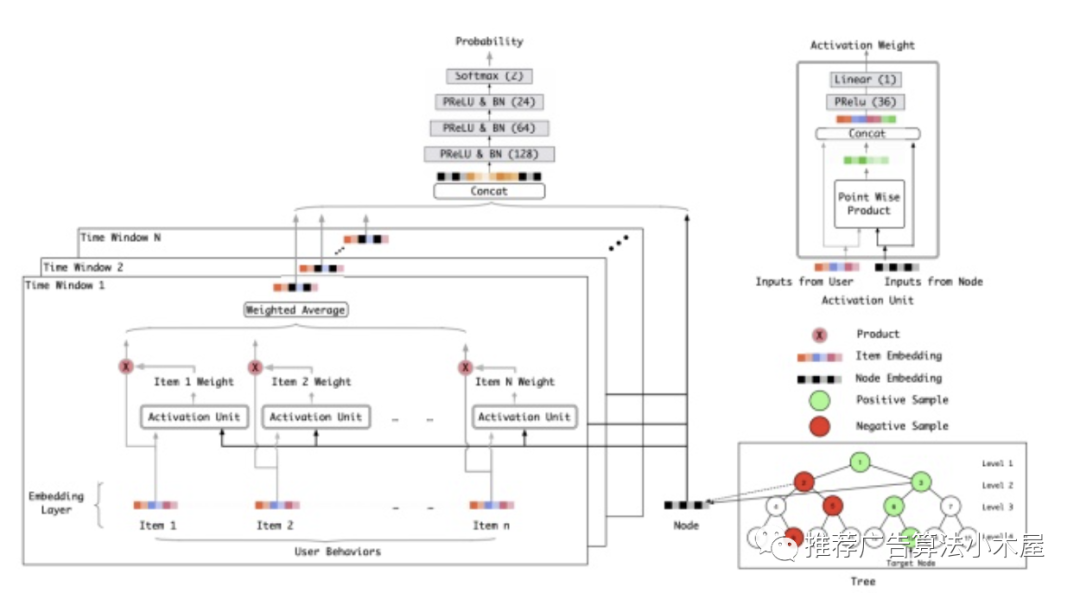
内积表征偏好的方式表达能力有限,阿里提出了基于树的检索算法 TDM, 将索引建模成一棵树结构,候选集的每个 Item 为树中的叶子结点,并将模型的参数学习和树结构的参数学习结合起来训练。
索引的构建方式就是绿色方框中的树形结构,评分规则就是红框中的复杂DNN网络(用于输出用户对树节点的偏好程度,其中叶子节点表征每一个商品,非叶子节点是对商品的一种抽象化表征,可以不具有具体的物理意义),检索算法是beam search算法。
5.2 字节Deep Retrieval
Deep Retrieval: An End-to-End Learnable Structure Model for Large-Scale Recommendations
TDM树结构的部分叶子结点可以会因为稀疏数据而导致学习不充分,候选集只属于一个叶子节点也不符合常理。
字节提出了一种端到端的模型训练框架“深度检索” DR,该模型使用 D*K 维的矩阵来作为索引结构。每个 Item 都需要走 D 步,每一步有 K 种选择。走到最后会有 K^D 可能的路径,每一条路径可以代表一个包含多个 Item。每个 Item 可以被这样编码一次或多次,所以 Item 也可以属于多条路径。Item 和 Embedding 之间是多对多的编码范式,故其可以表达更复杂的关系,最终实验证明,DR 模型时间复杂度接近线性,同时可以取得与暴力枚举相当的结果。

6. 召回的一些常见问题
简单列举几个别人问过我的问题,只谈谈自己的看法
6.1 多路召回如何判断各路权重?
一般来说权重靠人拍,定好了weight和count后上线测一测,然后靠诸如独占等评估指标,以及AB/生态等多种考量调整,但是整体上还是人拍。
很早期的推荐以基础属性召回为主,召回路太多调weight和截断count很麻烦,而当向量化召回逐渐成熟后,一般主召回都会用向量化模型来做,这也是向量化召回对比策略召回的一个优势。
6.2 如何衡量召回的好坏?
不像精排可以拿AUC等指标来精准衡量模型的优劣,召回一般来讲AUC只供参考,因为召回训练时要负采样(不知道原因的可看这篇文章)
这些负例未必就是真负的,且负例难度低通常AUC都很高,召回本身也不是准就ok的,要同时考虑独占比、资源和时延、画风生态等。
整个召回系统,可以构建无偏集离线计算准确度、覆盖度、多样性、业务目标等几个点来大致评估,更关键的还是线上看AB和AA的效果,要和业务对齐目标。
6.3 召回merge时要注意什么?
一般来讲召回进粗排前会指定条数,但是在merge时可能因为各种原因导致总数不够,所以要有兜底策略。
merge时不可能按照第一路召回+500条,再继续第二路召回+300条,一定是第一路取N个再第二路取M个这种,merge时可以用一些算法动态计算N/M力求最优。
多路召回经常有很多相同的候选,所以要进行召回间消重,同时要注意展现消重、各种过滤也是在召回做的,毕竟等排序再做就太der了。
6.4 召回评估看命中率对么?
这个问题换句话说是,召回和精排强耦合好吗?个人觉得召回承担了explore的责任,命中率不错肯定是好的,但是如果太高了则说明召回和精排耦合程度太高,如果下游策略发生改动则可能出现无合适候选的情况。同理,召回在迭代时也要推动精排的优化,不然排出率就很低。
6.5 召回和精排模型的区别?
精排候选比较少,可以使用大量特征和复杂模型,尤其是交叉特征;而召回一般不用交叉特征,一方面减小复杂度,另一方面user和group可以独立发展,这样离线才能构建group候选图,以线上更快地检索。
6.6 冷启动做高热召回好吗?
其实在深入做冷启之前我一直以为高热时最make sense的方法,但是在深入了解冷启业务后会发现其实高热并不一定适合所有的业务,举例像快手最开始做下沉用户,那么画风整体上是很差的,训练数据都是靠下沉用户积累的,如果新用户是下沉当然高热很ok,但是在泛化阶段想吸引年轻用户推高热其实是劝退的。至于怎么更好地解决这个难点,因为涉及工作徐姐这里就不谈了。
6.7 想做推荐算法岗,是做召回还是排序?
最近有挺多学弟妹问我这个问题。首先不同公司有不同的风格,比如像手百会单拆一个召回组,专做召回做得比较深入;而像头条主要own业务,全链路都可以涉及但是有所侧重。所以在纠结这个问题的时候可以先打听清楚部门的组成,看是只允许做召回还是侧重召回。
第二点是召回和排序的对比。个人体会召回跟业务联系比较紧密,召回是整个推荐系统的天花板,会让你对业务有更深入的认知,也会涉及策略和模型但是不如排序那么复杂;排序会更模型一些,学术界每年有大量的论文可以参考,做模型研究未来面试时也有很多可以讲的点,但是在各公司推荐越来越成熟的今天,要靠魔改结构拿收益越来越难。
一言以蔽之,其实不用太纠结进去做召回还是排序,无论做哪个到后面你都会发现数据+特征+架构才是王道,同时也要时刻关注组内其他链路环节的进展,才能更好的把控全局和提高自己。