
175篇论文告诉你深度学习er能从NeurIPS 2020论文学到什么?
新智元推荐
新智元推荐
来源:AMiner科技
作者:戚路北
【新智元导读】在Medium上,一位名为Prabhu Prakash Kagitha的博主,根据NeurIPS 2020上的论文发表了一篇题为“NeurIPS 2020 Papers: Takeaways for a Deep Learning Engineer”的文章,阅读了NeurIPS 2020中的175篇论文的摘要,汇总了与深度学习有关的见解。
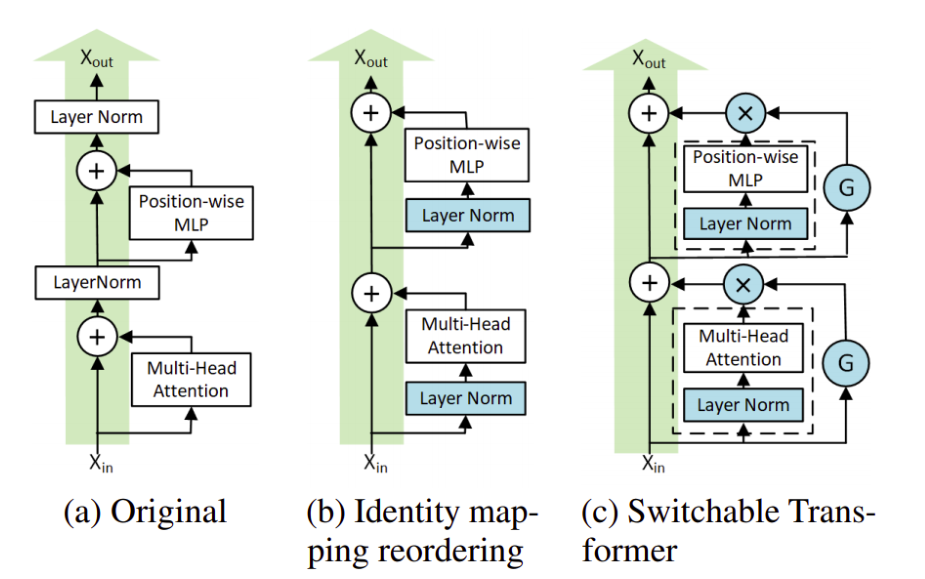
1、加速基于Transformer的语言模型的逐层下降训练
与标准翻译器相比,可切换翻译器(ST)的预训练速度快2.5倍。
配备可切换门(G在fg。下面),一些层是根据伯努利分布抽样0或1随机跳过的,每个抽样的时间效率为25%。
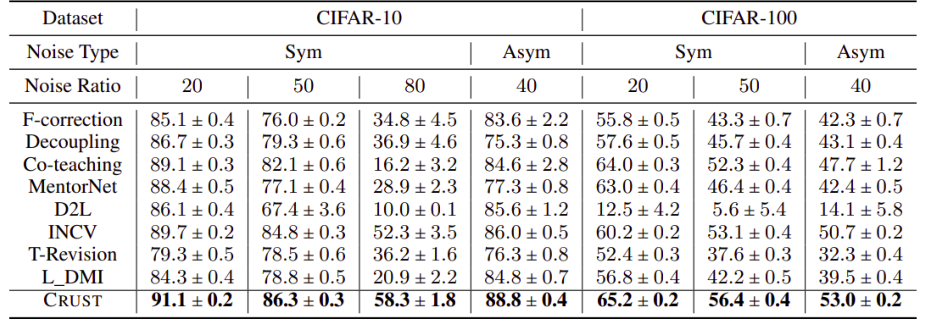
2、用于神经网络抗噪声标签的Robust训练的核心集
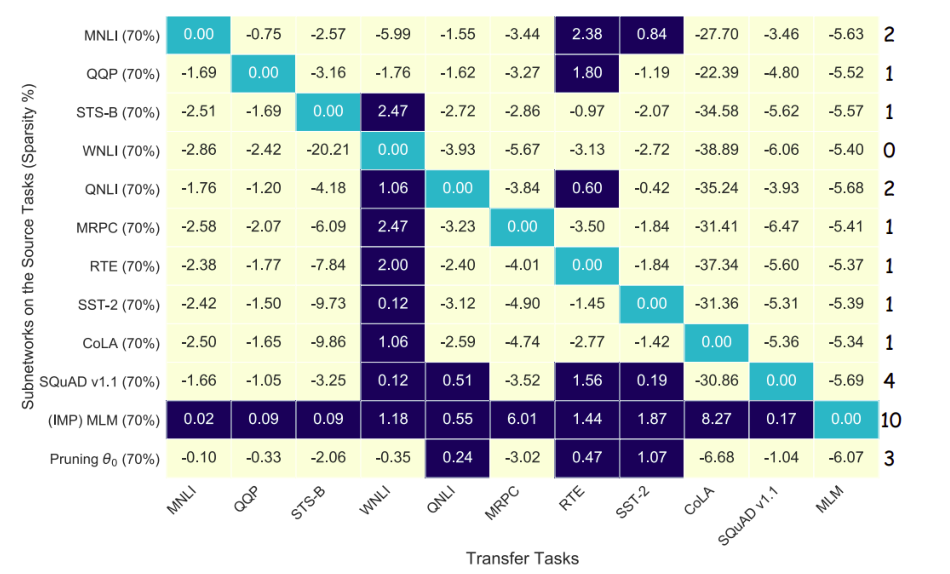
3、基于预训练BERT网络模型的彩票假设


4、MPNet:语言理解预先训练的掩蔽和排列

5、使用边缘排名下的区域识别错误标记的数据
6、重新思考标签对于改善课堂不平衡学习的价值
7、Big Bird:长序列翻译
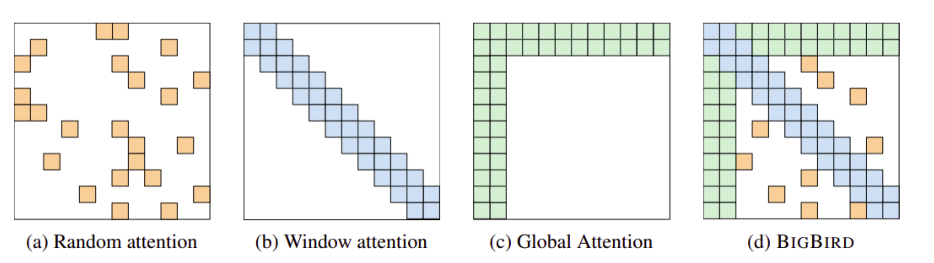
 不同类型的注意在稀疏注意(a)随机注意(b)窗口邻域注意(c)添加CLS令牌后的全局注意。(图片摘自本论文的pdf版本。)
不同类型的注意在稀疏注意(a)随机注意(b)窗口邻域注意(c)添加CLS令牌后的全局注意。(图片摘自本论文的pdf版本。)8、通过权重共享来改进自动增重
9、集中注意力的快速翻译
10、自我关注的深度限制和效率

评论