
【Web技术】705- 完善的前端异常监控解决方案

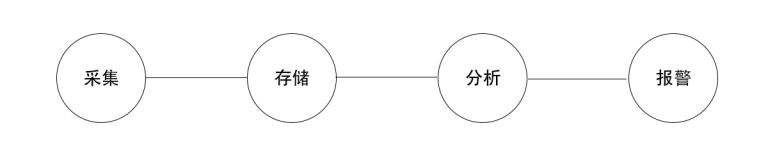
1 前端异常
1.1 前端异常分类

1.2 异常错误原因分类
2) 事件绑定顺序错误 3) 调用栈时序错误 4) 错误的操作js对象 | ||
2) 将undefined视作数组进行遍历 3) 将字符串形式的数字直接用于加运算 4) 函数参数未传 | ||
2) 服务端未返回数据但仍200,前端按正常进行数据遍历 3) 提交数据时网络中断 4) 服务端500错误时前端未做任何错误处理 | ||
2) 磁盘塞满 3) 壳不支持API 4) 不兼容 |
2 异常采集
2.1 采集内容
2.2 异常捕获
window.addEventListener(‘error’) / window.addEventListener(“unhandledrejection”) / document.addEventListener(‘click’) 等 框架级别的全局监听,例如aixos中使用interceptor进行拦截,vue、react都有自己的错误采集接口 通过对全局函数进行封装包裹,实现在在调用该函数时自动捕获异常 对实例方法重写(Patch),在原有功能基础上包裹一层,例如对console.error进行重写,在使用方法不变的情况下也可以异常捕获
try…catch 专门写一个函数来收集异常信息,在异常发生时,调用该函数 专门写一个函数来包裹其他函数,得到一个新函数,该新函数运行结果和原函数一模一样,只是在发生异常时可以捕获异常
2.3 跨域脚本异常
将js内联到HTML中 将js文件与HTML放在同域下
为页面上script标签添加crossorigin属性 被引入脚本所在服务端响应头中,增加 Access-Control-Allow-Origin 来支持跨域资源共享
2.4 异常录制
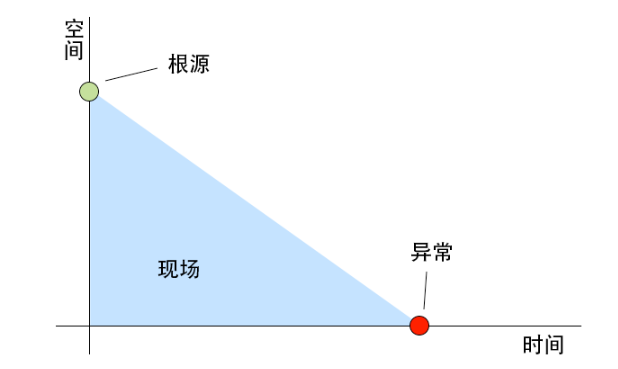
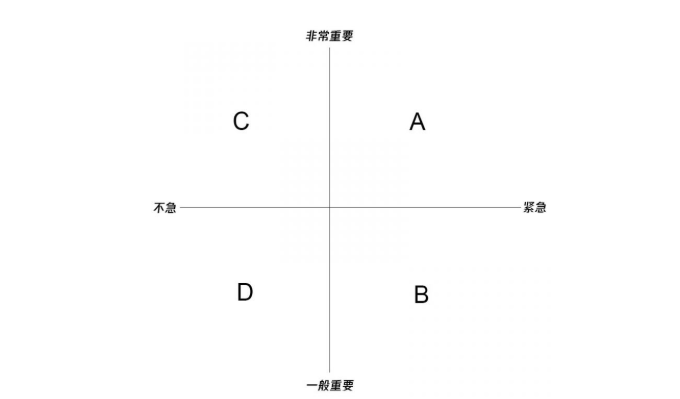
2.5 异常级别
3 整理与上报方案
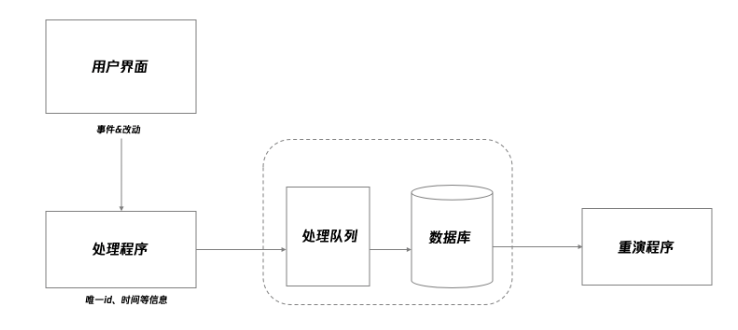
3.1 前端存储日志
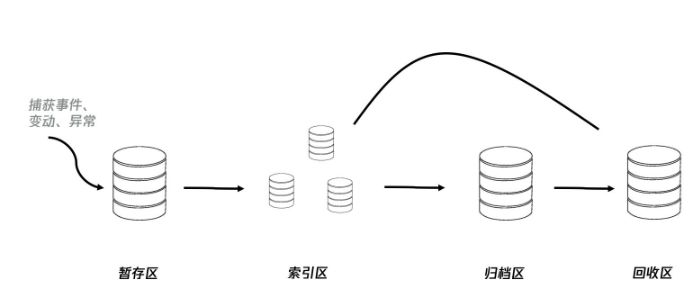
3.2 前端整理日志
将所有日志记录按时序存放在归档区,并将新入库的日志加入索引 BatchIndexes:批量上报索引(包含性能等其他日志),可一次批量上报100条 MomentIndexes:即时上报索引,一次全部上报 FeedbackIndexes:用户反馈索引,一次上报一条 BlockIndexes:区块上报索引,按异常/错误(traceId,requestId)分块,一次上报一块 上报完成后,被上报过的日志对应的索引删除 3天以上日志进入回收区 7天以上的日志从回收区清除
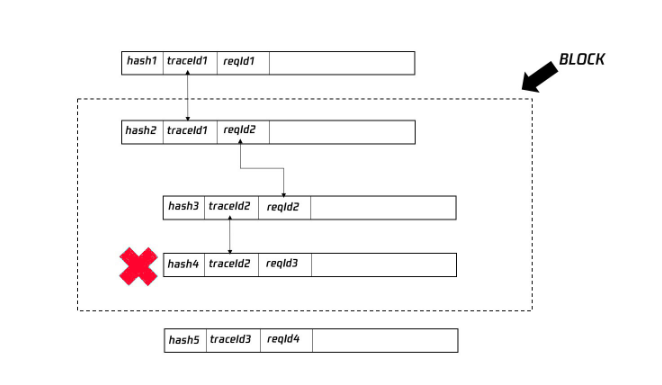
3.3 上报日志
a. 即时上报
b. 批量上报
c. 区块上报
d. 用户主动提交
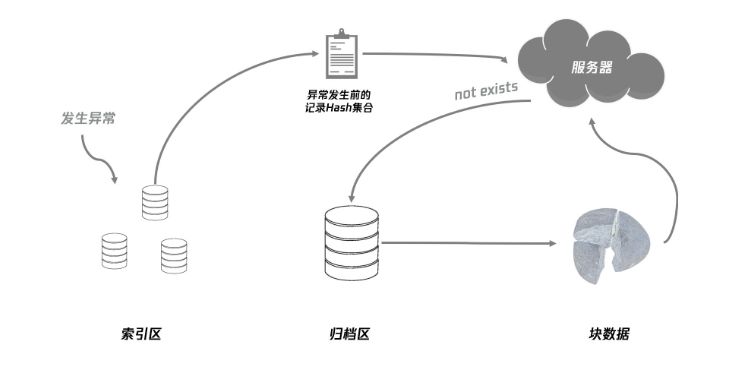
3.4 压缩上报数据
4 日志接收与存储
4.1 接入层与消息队列
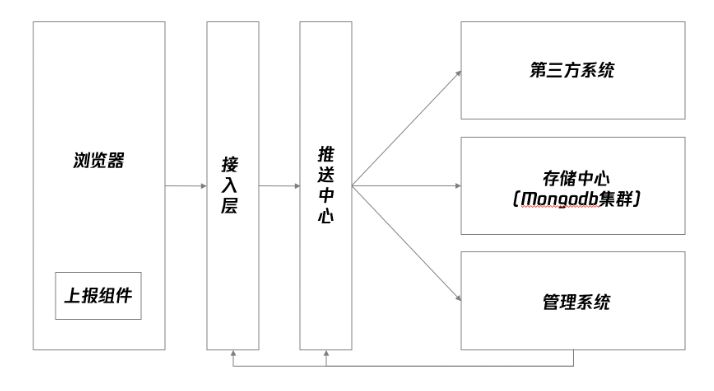
4.2 日志存储系统
4.3 搜索
5 日志统计与分析
5.1 用户纬度
5.2 时间维度
5.3 性能维度
5.4 运行环境维度
5.5 细粒度代码追踪
5.6 场景回溯
6 监控与通知
6.1 自定义触发条件的告警
日志内含有什么内容时 日志统计达到什么度、量时 向符合什么条件的用户告警
6.2 推送渠道
6.3 推送频率
6.4 自动报表
6.5 自动产生bug工单
7 修复异常
7.1 sourcemap
7.2 从告警到预警
7.3 智能修复
8 异常测试
8.1 主动异常测试
8.2 随机异常测试
9 部署
9.1 多客户端
9.2 集成便捷性
9.3 管理系统的可扩展
9.4 日志系统权限
10 其他
10.1 性能监控
运行时性能:文件级、模块级、函数级、算法级 网络请求速率 系统性能
10.2 API Monitor
稳定性监控 数据格式和类型 报错监控 数据准确性监控
10.3 数据脱敏
独立部署,不和其他应用共享监控系统 不采集具体数据,只采集用户操作数据,在重现时,通过日志信息可以取出数据api结果来展示 日志加密,做到软硬件层面的加密防护 必要时,可采集具体数据的ID用于调试,场景重现时,用mock数据替代,mock数据可由后端采用假的数据源生成 对敏感数据进行混淆
结语
1. JavaScript 重温系列(22篇全) 2. ECMAScript 重温系列(10篇全) 3. JavaScript设计模式 重温系列(9篇全) 4. 正则 / 框架 / 算法等 重温系列(16篇全) 5. Webpack4 入门(上)|| Webpack4 入门(下) 6. MobX 入门(上) || MobX 入门(下) 7. 70+篇原创系列汇总 回复“加群”与大佬们一起交流学习~
点击“阅读原文”查看70+篇原创文章
点这,与大家一起分享本文吧~

评论