
如何完善Redis监控告警?


本文字数:3940字
预计阅读时间:20分钟
一、背景 二、监控指标分类 三、监控指标说明 四、总结
一、背景
Redis监控告警实践是基于开发CacheCloud云平台过程中不断实践和总结出来,随着Redis实例规模不断变大,会遇到各种各样的问题,这就需要一套完善的监控报警机制来帮助我们快速定位问题以及开发运维。
当我们在开发使用Redis的过程中,你是否会遇到这些问题?
问题1:Redis内存何时需要扩容? 问题2:Redis客户端流量和异常如何采集监控? 问题3:Redis实例需要消耗哪些系统资源? 问题4:Redis实例运行状态是否正常? 问题5:Redis集群在机器故障期间是否能保证故障转移成功?
那么将从上面这些问题出发,分享在开发过程中如何完善Redis的监控告警。
二、监控指标分类
Redis是一种基于key-value的Nosql数据库,会将所有数据都存放在内存中,所以想全面监控Redis指标需要考虑到影响它的内外因素,比如像客户端连接数、OPS、是否有热点key或bigkey、CPU竞争、宿主环境磁盘IO压力、集群实例分布等等。那么先从上面几个问题入手,来分析Redis监控指标的几个方面:
1).Redis内部指标 2).客户端采集指标 3).宿主/容器环境指标 4).实例运行状态指标 5).集群拓扑指标
问题1:Redis内存何时需要扩容?
这里首先需要了解Redis内部指标有哪些,通过info all可以获取到关于实例客户端、内存使用、运行数据统计、持久化信息、命令统计、集群信息统计等,下图只展示了部分模块的指标,详细指标说明参见3.1 Redis info指标。
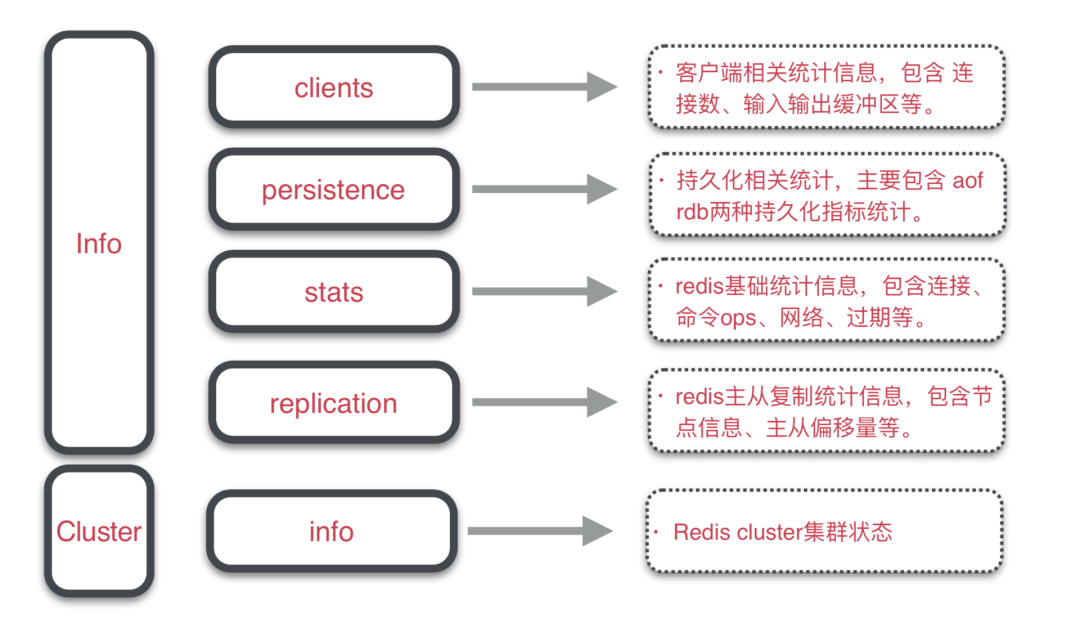
其中当前对Redis内部指标重点监控指标有:
| 序号 | 配置名 | 配置说明 | 关系 | 阈值 |
|---|---|---|---|---|
| 1 | aof_current_size | aof当前尺寸(单位:MB) | 大于 | 6000 |
| 2 | aof_delayed_fsync | 分钟aof阻塞个数 | 大于 | 3 |
| 3 | client_biggest_input _buf | 输入缓冲区最大buffer大小(单位:MB) | 大于 | 10 |
| 4 | client_longest_output_list | 输出缓冲区最大队列长度 | 大于 | 50000 |
| 5 | instantaneous_ops_per_sec | 实时ops | 大于 | 60000 |
| 6 | latest_fork_usec | 上次fork所用时间(单位:微秒) | 大于 | 400000 |
| 7 | mem_fragmentation_ratio | 内存碎片率(检测大于500MB) | 大于 | 1.5 |
| 8 | rdb_last_bgsave_status | 上一次bgsave状态 | 不等于 | ok |
| 9 | total_net_output_bytes | 分钟网络输出流量(单位:MB) | 大于 | 5000 |
| 10 | total_net_input_bytes | 分钟网络输入流量(单位:MB) | 大于 | 1200 |
| 11 | sync_partial_err | 分钟部分复制失败次数 | 大于 | 0 |
| 12 | sync_partial_ok | 分钟部分复制成功次数 | 大于 | 0 |
| 13 | sync_full | 分钟全量复制执行次数 | 大于 | 0 |
| 14 | rejected_connections | 分钟拒绝连接数 | 大于 | 400000 |
| 15 | master_slave_offset_diff | 主从节点偏移量差(单位:字节) | 大于 | 20000000 |
| 16 | cluster_state | 集群状态 | 不等于 | ok |
| 17 | cluster_slots_ok | 集群成功分配槽个数 | 不等于 | 16384 |
| 18 | used_memory_precent | 内存使用率 | 大于 | 80% |
那么对于Redis内存何时需要扩容,需要看那些指标呢?
此时先检查info memory指标,其中maxmemory指的是当前Redis最大使用内存,一旦使用内存used_memory>maxmemory限制达到的时候,Redis会根据配置的maxmemory-policy策略来对键进行回收,如果策略配置不对可能会导致客户端调用出现OOM的报错.
因此我们对Redis实例的内存使用率监控阈值默认设置在80%,超过阈值则会邮件提醒管理员,以保证提前发现应用对内存需求增长的需求。这里展示了线上的某一个实例当前内存使用情况和内存回收策略:
1).当前实例内存使用情况
127.0.0.1:6470> info memory
# Memory
used_memory:6441145376
used_memory_human:6.00G
used_memory_rss:6622314496
used_memory_rss_human:6.17G
used_memory_peak:6442453200
used_memory_peak_human:6.00G
used_memory_peak_perc:99.98%
maxmemory:6442450944
maxmemory_human:6.00G
...
2).淘汰策略: 在有过期键的集合中尝试回收最少使用的键(LRU)
config get maxmemory-policy
1) "maxmemory-policy"
2) "volatile-lru"
3).统计当前实例过期的key数量和驱逐的key的数量
127.0.0.1:6470> info stats
# Stats
...
expired_keys:19125
evicted_keys:1120问题2:Redis客户端流量和异常如何采集监控?
这里需要定制统一客户端SDK,通过SDK埋点采集用户Redis调用统计和异常信息,方便从客户端视角定位问题,形成Redis发现问题并响应解决的持续运维流。
1).从客户端视角主要指标说明如下:
客户端命令调用统计: 基础字段:收集时间(collectTime)、客户端IP(client)、应用(appId); 命令字段:命令(command)、调用量(count)、 输入/输出流量(input/output)、累计毫秒耗时(costtime); 客户端异常信息统计: 异常分析可参考:3.2 客户端异常说明 连接事件: 连接失败次数(connectFailedCount)、连接失败毫秒耗时(connectFiledTime); 命令调用: 超时次数(latencyCount)、超时毫秒耗时(latencyTime)、超时命令明文(latencyCommands);
2).客户端上报数据采集过程:
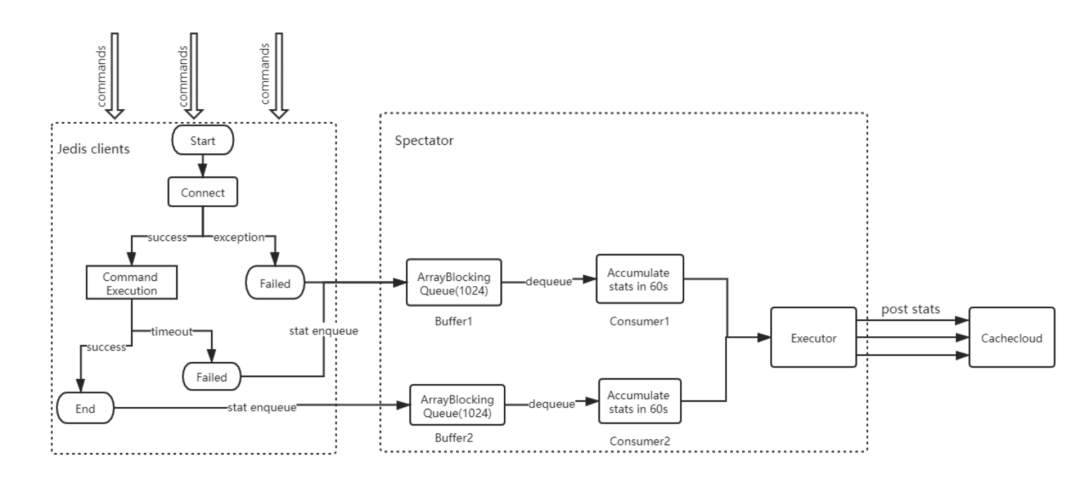
2.1.指标采集暂存到队列,队列大小限制为1024; 2.2.单线程从队列取数据进行消费,累加一分钟内的指标; 2.3.单独线程池负责发送HTTP请求,上报指标到服务端; 2.4.通过收集到数据绘制实例图表曲线和数据表格汇总;
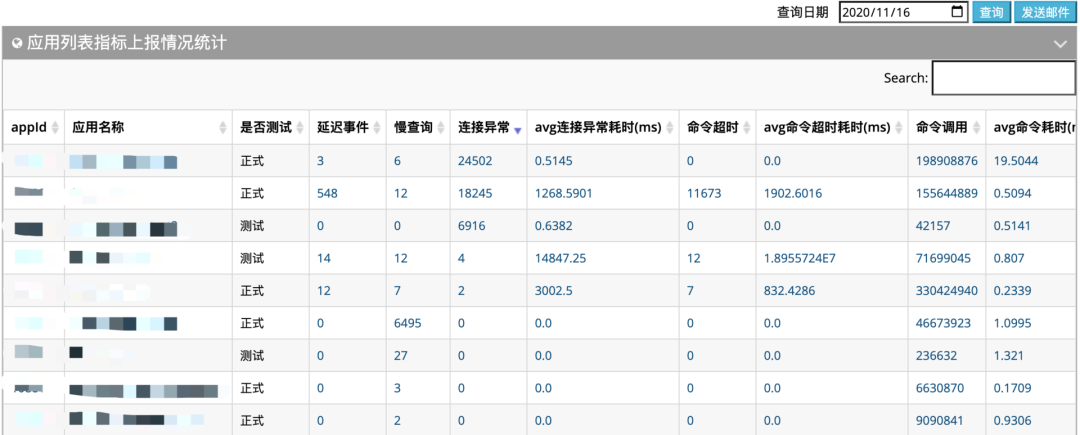
如下图统计了所有应用客户端指标数据(按天汇总),这样就能快速发现到系统中存在的调用异常的应用,通过收集到数据快速发现问题。
问题3:Redis实例需要消耗哪些系统资源?
Redis实例是以进程为单位运行在宿主环境上,系统资源消耗和实例的稳定运行有着重要的联系,例如进程间存在cpu竞争、磁盘IO压力大或是网卡阻塞都会影响Redis性能,所以需要对宿主环境资源做好资源监控:
| 序号 | 指标类型 | 级别 | 说明 |
|---|---|---|---|
| 1 | cpu限制时长 | 容器 | 容器cpu限制时长top10监控 |
| 2 | cpu使用率 | 容器 | 容器cpu使用率top10监控 |
| 3 | RSS内存 | 容器 | 容器内存阈值的85%,防止出现oomkiier |
| 4 | 磁盘IO | 宿主机 | 诊断磁盘读写压力 |
| 5 | 网络流量 | 宿主机 | 诊断网络流量是否异常 |
| 6 | 磁盘空间 | 宿主机 | 诊断磁盘空间否充足 |
| 7 | 宿主机器运行时间 | 宿主机 | 诊断宿主机器是否故障 |
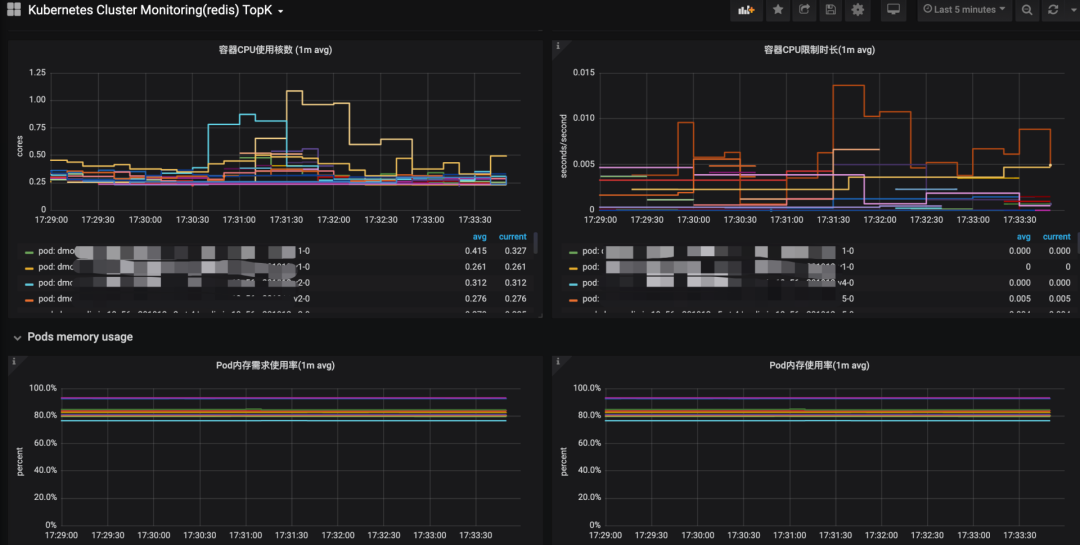
下图通过grafana展示了关于容器和宿主环境监控指标曲线,通过对关键指标使用率监控能够快速找到可能发生问题容器和宿主信息。
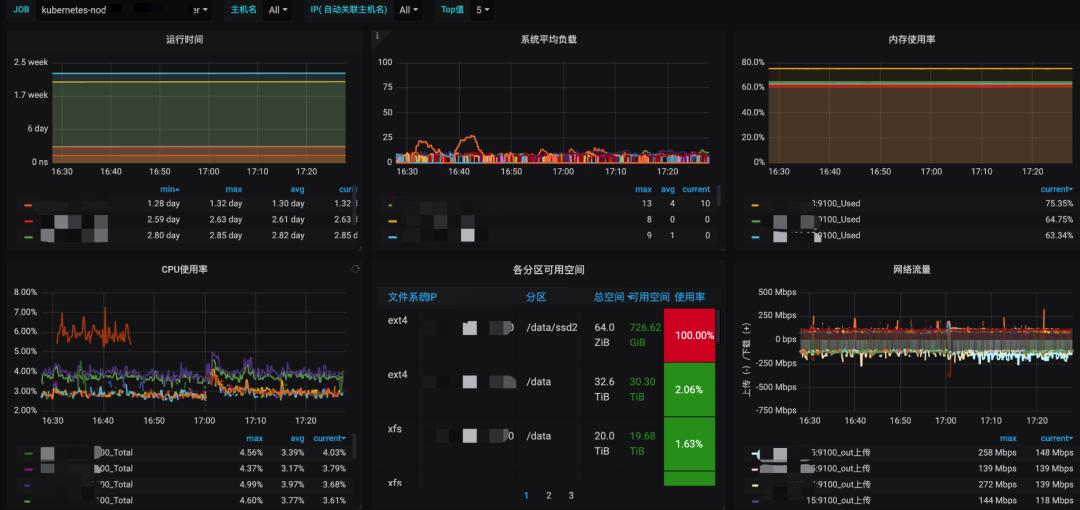
问题4:Redis实例运行状态是否正常?
Redis实例大多是运行在容器里的,一旦容器挂起或实例长时间阻塞就会影响服务调用,所以需要对容器或实例的运行状态做好近实时监控。
| 序号 | 指标类型 | 含义 | 监控周期 |
|---|---|---|---|
| 1 | Redis实例状态 | 0:心跳停止 1:运行中 2:下线 3:永久下线 | 每1分钟 |
| 2 | Pod状态 | 0:下线 1:上线 | 回调接口通知 |
Redis实例状态: 通过后台定时任务探测所有在线运行的实例,检测发现响应异常实例会以邮件形式通知管理员; Pod状态: 下线:通过回调接口以邮件形式通知系统哪些Pod不可用; 上线:通过回调接口以邮件形式通知恢复&自动拉起实例列表;
问题5:Redis集群故障期间是否能保证故障转移成功?
在平时使用Redis集群(例如RedisSentinel/RedisCluster)过程中,机器可能会出现宕机、重启等情况,如果集群中部分实例分布在故障机器上就会导致实例无法服务,一旦集群实例拓扑分布异常就会导致集群故障转移失败,从而影响整体集群可用性。
| 序号 | 类型 | 含义 |
|---|---|---|
| 1 | Redis Sentinel集群 | 诊断集群拓扑是否异常 |
| 2 | Redis Cluster集群 | 诊断集群拓扑是否异常 |
Redis Sentinel集群拓扑诊断: sentinel节点至少分布在3个及以上物理机; 主从节点不能分布在同一台物理机; 主节点需要有至少一个从节点; Redis Cluster集群拓扑诊断: 集群节点至少分布在3台物理机器上; 集群中某一台容器的宿主机发生故障,是否能满足故障转移; 主节点需要有从节点;
下图为检测部分应用的拓扑诊断情况:
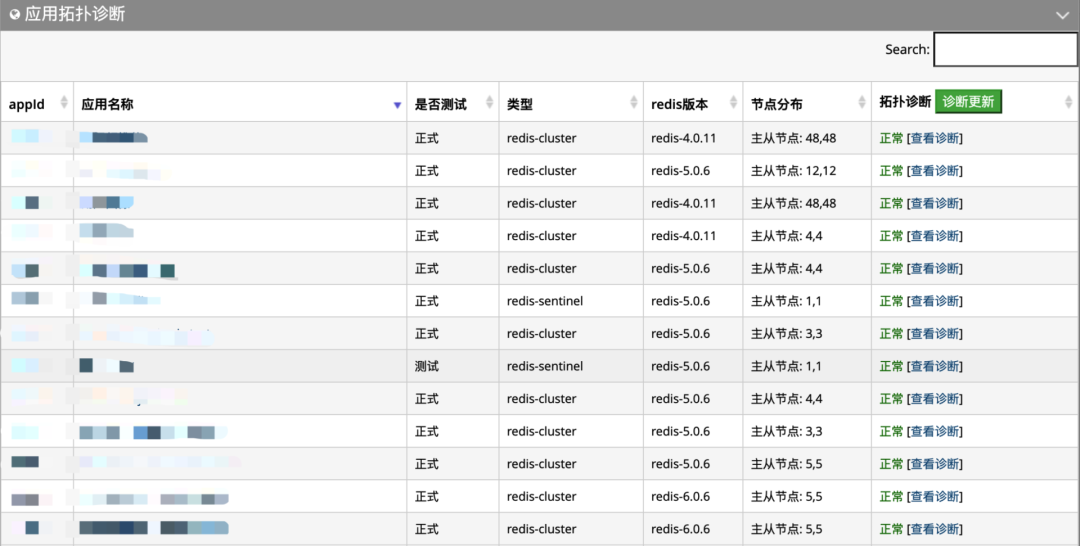
三、监控指标说明
上一节讲述了Redis监控指标的几个方面,下面来详细分析指标报警可能产生的原因:
3.1 Redis info指标说明
info all命令包含Redis最全的系统状态信息,表格列出了涉及到所有模块,下面分析其中部分模块的指标。
| 序号 | 模块 | 含义 |
|---|---|---|
| 1 | Clients | 客户端信息 |
| 2 | Cluster | 集群信息 |
| 3 | Commandstats | 命令统计信息 |
| 4 | CPU | CPU消耗信息 |
| 5 | Keyspace | 数据库键统计信息 |
| 6 | Memory | 内存信息 |
| 7 | Persistence | 持久化信息 |
| 8 | Replication | 复制信息 |
| 9 | Server | 服务器信息 |
| 10 | Memory | 统计信息 |
1).info client模块:
info client模块的统计信息,它包含了连接数、阻塞命令连接数、输入输出缓冲区等相关统计。
127.0.0.1:6399> info clients
# Clients
connected_clients:300
client_longest_output_list:0
client_biggest_input_buf:0
blocked_clients:0
connected_clients: 统计当前客户端连接数,报警阈值>2000个连接;1).客户端可能存在连接泄漏问题; 2).客户端实例数增加或客户端连接池设置过大; 3).创建集群实例非单例; client_longest_output_list:当前所有输出缓冲区中队列对象个数的最大值,报警阈值>500;client_biggest_input_buf:输入缓冲区最大buffer大小(单位:MB),报警阈值>10;影响报警的因素: 1).可能存在bigkey读写,阻塞缓冲区; 2).有频繁批量读写操作:hgetall/hkeys、zrange、lrange 、smembers、mget等; 3).开启monitor直连线上环境,阻塞服务端输入输出缓冲区;
影响报警的因素:
2).info persistence模块:
info Persistence模块的统计信息,它包含了RDB和AOF两种持久化的一些统计。
127.0.0.1:6399> info persistence
# Persistence
loading:0
rdb_changes_since_last_save:589319695
rdb_bgsave_in_progress:0
rdb_last_save_time:1576117607
rdb_last_bgsave_status:ok
rdb_last_bgsave_time_sec:2
rdb_current_bgsave_time_sec:-1
rdb_last_cow_size:2129920
aof_enabled:1
aof_rewrite_in_progress:0
aof_rewrite_scheduled:0
aof_last_rewrite_time_sec:30
aof_current_rewrite_time_sec:-1
aof_last_bgrewrite_status:ok
aof_last_write_status:ok
aof_last_cow_size:20979712
aof_current_size:1654862653
aof_base_size:1584570244
aof_pending_rewrite:0
aof_buffer_length:0
aof_rewrite_buffer_length:0
aof_pending_bio_fsync:0
aof_delayed_fsync:15
aof_current_size:aof当前尺寸(单位:MB),报警阈值>6000MB;aof_delayed_fsync:分钟aof阻塞个数,报警阈值每分钟阻塞大于3次;影响报警的因素: 磁盘有坏道或机器磁盘性能问题,读写速度跟不上; 如果是共享容器,需要检查宿主环境下其他进程的写盘情况; 宿主环境上有较密集实例进行AOF/RDB写盘操作; rdb_last_bgsave_status:上一次bgsave状态;影响报警的因素: 可能由于磁盘空间不足导致写rdb失败;
3).info stats
info Stats模块的统计信息,它是Redis的基础统计信息,包含了:连接、命令、网络、过期、同步很多统计。
127.0.0.1:6399> info stats
# Stats
total_connections_received:5261797
total_commands_processed:9448523137
instantaneous_ops_per_sec:1560
total_net_input_bytes:1307208851742
total_net_output_bytes:5338907609106
instantaneous_input_kbps:68.02
instantaneous_output_kbps:137.20
rejected_connections:0
sync_full:3
sync_partial_ok:1
sync_partial_err:3
expired_keys:7984396
expired_stale_perc:0.10
expired_time_cap_reached_count:0
evicted_keys:0
keyspace_hits:3477205762
keyspace_misses:5308763830
pubsub_channels:0
pubsub_patterns:0
latest_fork_usec:114520
migrate_cached_sockets:0
slave_expires_tracked_keys:0
...
total_net_output_bytes:分钟网络输出流量(单位:MB),报警阈值>2500;total_net_input_bytes:分钟网络输入流量(单位:MB),报警阈值>1200;影响报警的因素: 客户端整体调用量OPS较高; 可能存在大对象频繁的读写操作; 实例可能存在较大流量热点key; latest_fork_usec:上次fork所用时间(单位:微秒),报警阈值>600000;影响报警的因素: Redis内存分片较大,需要控制分片内存的大小; 物理内存不足导致fork失败; 宿主环境thp关闭,拷贝内存页时间较长; sync_full:分钟全量复制执行次数,报警阈值>0次;sync_partial_ok:分钟部分复制成功次数,,报警阈值>0次;影响报警的因素: 主动发起主从failover,从节点发起全量复制(采用psync2协议可保证增量复制); 添加从节点会发起全量复制; 网络问题导致复制积压缓冲区不足;
4).info replication
info Replication模块的统计信息,它包含了Redis主从复制的一些统计。
127.0.0.1:6399> info replication
# Replication
role:master
connected_slaves:1
slave0:ip=x.x.x.x,port=6387,state=online,offset=4764522381799,lag=1
master_replid:ac5d8f6938d752f8f6d453a9841b2a4ed261bcfb
master_replid2:82ab36d6a6f7059757b96c83337f4a6132597e1a
master_repl_offset:4764522381799
second_repl_offset:3823758361609
repl_backlog_active:1
repl_backlog_size:10000000
repl_backlog_first_byte_offset:4764512381800
repl_backlog_histlen:10000000
repl_backlog_size:缓冲区最大长度,报警阈值>10MB;master_slave_offset_diff:主从节点偏移量差(单位:字节),报警阈值>10MB;影响报警的因素: 机器网络出现延迟; 主节点写操作过于频繁;
5).info cpu模块:
127.0.0.1:6399> info cpu
# CPU
used_cpu_sys:156315.03
used_cpu_user:78421.15
used_cpu_sys_children:5608.28
used_cpu_user_children:19055.72
used_cpu_sys:Redis主进程在内核态所占用的CPU时长累加;used_cpu_user:Redis主进程在用户态所占用的CPU时长累加;used_cpu_sys_children:子进程在内核态所占用的CPU时长累加;used_cpu_user_children:子进程在用户态所占用的CPU时长累加;
如果主进程在内核态单位时间内累计CPU时长较长,说明主进程很繁忙,客户端就有可能出现阻塞或响应慢的情况。
3.2 客户端异常指标说明
目前客户端的sdk主要用的是Jedis客户端,这里主要说明关于Jedis客户端异常信息:
异常信息1:JedisConnectionException: Could not get a resource from the pool` (1) 连接池存在泄露,直到耗尽连接; (2) 业务调用量增长很快,连接池最大连接数设置过小; (3) 有慢查询或者Redis发生阻塞; 异常信息2:java.net.SocketTimeoutException: Read timed out (1) 读写超时设置的过短; (2) 有慢查询或者Redis发生阻塞; (3) 网络不稳定; 异常信息3:JedisDataException: ERR max number of clients reached 客户端连接数超过了Redis实例配置的最大maxclients(默认值10000); 异常信息4:JedisDataException: LOADING Redis is loading the dataset in memory 客户端调用Redis时,如果Redis正在加载持久化文件,无法进行正常的读写; 异常信息5:JedisDataException: NOAUTH Authentication required 客户端调用Redis时,未传入密码;
四、总结
对于任何服务,系统监控告警对服务质量起着至关重要的作用,关于Redis监控报警总结如下:
对于客户端:
SDK集成和使用简单; SDK数据采集上报无感知; SDK可用性&稳定性保障; 对于服务端:
内部监控:Redis内部指标/客户端指标告警快速定位&解决; 外部监控:宿主环境资源/集群拓扑诊断快速迁移&修复; 资源使用:合理分配容器实例数量以及资源使用率; 故障恢复:能对出现故障的实例/容器有快速恢复能力;