
SQL去重的三种方法汇总
点击上方蓝色字体,选择“标星公众号”
优质文章,第一时间送达
在使用SQL提数的时候,常会遇到表内有重复值的时候,比如我们想得到 uv (独立访客),就需要做去重。
在 MySQL 中通常是使用 distinct 或 group by子句,但在支持窗口函数的 sql(如Hive SQL、Oracle等等) 中还可以使用 row_number 窗口函数进行去重。
举个栗子,现有这样一张表 task:
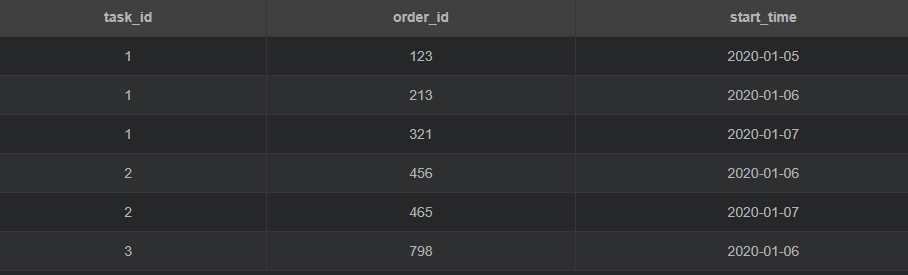
备注:
task_id: 任务id;order_id: 订单id;start_time: 开始时间
注意:一个任务对应多条订单
我们需要求出任务的总数量,因为 task_id 并非唯一的,所以需要去重:
distinct
-- 列出 task_id 的所有唯一值(去重后的记录)
-- select distinct task_id
-- from Task;
-- 任务总数
select count(distinct task_id) task_num
from Task;
distinct 通常效率较低。它不适合用来展示去重后具体的值,一般与 count 配合用来计算条数。
distinct 使用中,放在 select 后边,对后面所有的字段的值统一进行去重。比如distinct后面有两个字段,那么 1,1 和 1,2 这两条记录不是重复值 。
group by
-- 列出 task_id 的所有唯一值(去重后的记录,null也是值)
-- select task_id
-- from Task
-- group by task_id;
-- 任务总数
select count(task_id) task_num
from (select task_id
from Task
group by task_id) tmp;
row_number
row_number 是窗口函数,语法如下:
row_number() over (partition by <用于分组的字段名> order by <用于组内排序的字段名>)
其中 partition by 部分可省略。
-- 在支持窗口函数的 sql 中使用
select count(case when rn=1 then task_id else null end) task_num
from (select task_id
, row_number() over (partition by task_id order by start_time) rn
from Task) tmp;
此外,再借助一个表 test 来理理 distinct 和 group by 在去重中的使用:

-- 下方的分号;用来分隔行
select distinct user_id
from Test; -- 返回 1; 2
select distinct user_id, user_type
from Test; -- 返回1, 1; 1, 2; 2, 1
select user_id
from Test
group by user_id; -- 返回1; 2
select user_id, user_type
from Test
group by user_id, user_type; -- 返回1, 1; 1, 2; 2, 1
select user_id, user_type
from Test
group by user_id;
-- Hive、Oracle等会报错,mysql可以这样写。
-- 返回1, 1 或 1, 2 ; 2, 1(共两行)。只会对group by后面的字段去重,就是说最后返回的记录数等于上一段sql的记录数,即2条
-- 没有放在group by 后面但是在select中放了的字段,只会返回一条记录(好像通常是第一条,应该是没有规律的)
来源:blog.csdn.net/xienan_ds_zj/
article/details/103869048
评论