
搞懂这些SQL优化技巧,面试横着走!

图片来自 Pexels
SQL 优化已经成为衡量程序猿优秀与否的硬性指标,甚至在各大厂招聘岗位职能上都有明码标注,如果是你,在这个问题上能吊打面试官还是会被吊打呢?
有朋友疑问到,SQL 优化真的有这么重要么?如下图所示,SQL 优化在提升系统性能中是:成本最低和优化效果最明显的途径。
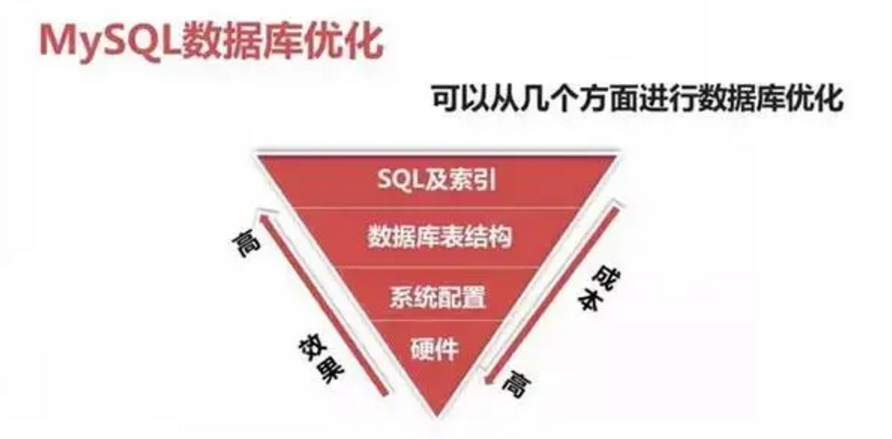
优化成本:硬件>系统配置>数据库表结构>SQL 及索引。
优化效果:硬件<系统配置<数据库表结构
String result = "嗯,不错,";
if ("SQL优化经验足") {
if ("熟悉事务锁") {
if ("并发场景处理666") {
if ("会打王者荣耀") {
result += "明天入职"
}
}
}
} else {
result += "先回去等消息吧";
}
Logger.info("面试官:" + result );
减少数据访问:设置合理的字段类型,启用压缩,通过索引访问等减少磁盘 IO。
返回更少的数据:只返回需要的字段和数据分页处理,减少磁盘 IO 及网络 IO。
减少交互次数:批量 DML 操作,函数存储等减少数据连接次数。
减少服务器 CPU 开销:尽量减少数据库排序操作以及全表查询,减少 CPU 内存占用。
利用更多资源:使用表分区,可以增加并行操作,更大限度利用 CPU 资源。
最大化利用索引。
尽可能避免全表扫描。
减少无效数据的查询。
SELECT 语句,语法顺序如下:
1. SELECT
2. DISTINCT
3. FROM
4. JOIN
5. ON
6. WHERE
7. GROUP BY
8. HAVING
9. ORDER BY
10.LIMIT
SELECT 语句,执行顺序如下:
FROM
<表名> # 选取表,将多个表数据通过笛卡尔积变成一个表。
ON
<筛选条件> # 对笛卡尔积的虚表进行筛选
JOIN <join, left join, right join...>
<join表> # 指定join,用于添加数据到on之后的虚表中,例如left join会将左表的剩余数据添加到虚表中
WHERE
<where条件> # 对上述虚表进行筛选
GROUP BY
<分组条件> # 分组
# 用于having子句进行判断,在书写上这类聚合函数是写在having判断里面的
HAVING
<分组筛选> # 对分组后的结果进行聚合筛选
SELECT
<返回数据列表> # 返回的单列必须在group by子句中,聚合函数除外
DISTINCT
# 数据除重
ORDER BY
<排序条件> # 排序
LIMIT
<行数限制>
以下 SQL 优化策略适用于数据量较大的场景下,如果数据量较小,没必要以此为准,以免画蛇添足。
避免不走索引的场景
SELECT * FROM t WHERE username LIKE '%陈%'
SELECT * FROM t WHERE username LIKE '陈%'
使用 MySQL 内置函数 INSTR(str,substr)来匹配,作用类似于 Java 中的 indexOf(),查询字符串出现的角标位置。
使用 FullText 全文索引,用 match against 检索。
数据量较大的情况,建议引用 ElasticSearch、Solr,亿级数据量检索速度秒级。
当表数据量较少(几千条儿那种),别整花里胡哨的,直接用 like '%xx%'。
如下:
SELECT * FROM t WHERE id IN (2,3)如下:
SELECT * FROM t WHERE id BETWEEN 2 AND 3如下:
-- 不走索引
select * from A where A.id in (select id from B);
-- 走索引
select * from A where exists (select * from B where B.id = A.id);如下:
SELECT * FROM t WHERE id = 1 OR id = 3
如下:
SELECT * FROM t WHERE id = 1
UNION
SELECT * FROM t WHERE id = 3如下:
SELECT * FROM t WHERE score IS NULL
如下:
SELECT * FROM t WHERE score = 0-- 全表扫描
SELECT * FROM T WHERE score/10 = 9
-- 走索引
SELECT * FROM T WHERE score = 10*9
如下:
SELECT username, age, sex FROM T WHERE 1=1⑦查询条件不能用 <> 或者 !=
如下:复合(联合)索引包含 key_part1,key_part2,key_part3 三列,但 SQL 语句没有包含索引前置列"key_part1",按照 MySQL 联合索引的最左匹配原则,不会走联合索引。
select col1 from table where key_part2=1 and key_part3=2
如下 SQL 语句由于索引对列类型为 varchar,但给定的值为数值,涉及隐式类型转换,造成不能正确走索引。
select col1 from table where col_varchar=123;
如下:
-- 不走age索引
SELECT * FROM t order by age;
-- 走age索引
SELECT * FROM t where age > 0 order by age;
第一步:根据 where 条件和统计信息生成执行计划,得到数据。
第二步:将得到的数据排序。当执行处理数据(order by)时,数据库会先查看第一步的执行计划,看 order by 的字段是否在执行计划中利用了索引。如果是,则可以利用索引顺序而直接取得已经排好序的数据。如果不是,则重新进行排序操作。
第三步:返回排序后的数据。
USE INDEX 在你查询语句中表名的后面,添加 USE INDEX 来提供希望 MySQL 去参考的索引列表,就可以让 MySQL 不再考虑其他可用的索引。
例子: SELECT col1 FROM table USE INDEX (mod_time, name)...
IGNORE INDEX 如果只是单纯的想让 MySQL 忽略一个或者多个索引,可以使用 IGNORE INDEX 作为 Hint。
例子: SELECT col1 FROM table IGNORE INDEX (priority) ...
FORCE INDEX 为强制 MySQL 使用一个特定的索引,可在查询中使用FORCE INDEX 作为 Hint。
例子: SELECT col1 FROM table FORCE INDEX (mod_time) ...
例如:
SELECT * FROM students FORCE INDEX (idx_class_id) WHERE class_id = 1 ORDER BY id DESC;
SELECT 语句其他优化
②避免出现不确定结果的函数
③多表关联查询时,小表在前,大表在后
增删改 DML 语句优化
方法一:
insert into T values(1,2);
insert into T values(1,3);
insert into T values(1,4);方法二:
Insert into T values(1,2),(1,3),(1,4); 减少 SQL 语句解析的操作,MySQL 没有类似 Oracle 的 share pool,采用方法二,只需要解析一次就能进行数据的插入操作。
在特定场景可以减少对 DB 连接次数。
SQL 语句较短,可以减少网络传输的 IO。
事务占用的 undo 数据块。
事务在 redo log 中记录的数据块。
释放事务施加的,减少锁争用影响性能。特别是在需要使用 delete 删除大量数据的时候,必须分解删除量并定期 commit。
③避免重复查询更新的数据
简单方法实现:
Update t1 set time=now() where col1=1;
Select time from t1 where id =1;
使用变量,可以重写为以下方式:
Update t1 set time=now () where col1=1 and @now: = now ();
Select @now;
写入操作优先于读取操作。
对某张数据表的写入操作某一时刻只能发生一次,写入请求按照它们到达的次序来处理。
对某张数据表的多个读取操作可以同时地进行。
LOW_PRIORITY 关键字应用于 DELETE、INSERT、LOAD DATA、REPLACE 和 UPDATE。
HIGH_PRIORITY 关键字应用于 SELECT 和 INSERT 语句。
DELAYED 关键字应用于 INSERT 和 REPLACE 语句。
查询条件优化
例如:
SELECT col1, col2, COUNT(*) FROM table GROUP BY col1, col2 ORDER BY NULL ;SELECT col1 FROM customerinfo WHERE CustomerID NOT in (SELECT CustomerID FROM salesinfo )
尤其是当 salesinfo 表中对 CustomerID 建有索引的话,性能将会更好,查询如下:
SELECT col1 FROM customerinfo
LEFT JOIN salesinfoON customerinfo.CustomerID=salesinfo.CustomerID
WHERE salesinfo.CustomerID IS NULL高效:
SELECT COL1, COL2, COL3 FROM TABLE WHERE COL1 = 10
UNION ALL
SELECT COL1, COL2, COL3 FROM TABLE WHERE COL3= 'TEST';低效:
SELECT COL1, COL2, COL3 FROM TABLE WHERE COL1 = 10
UNION
SELECT COL1, COL2, COL3 FROM TABLE WHERE COL3= 'TEST';
简单的 SQL 容易使用到 MySQL 的 QUERY CACHE。
减少锁表时间特别是使用 MyISAM 存储引擎的表。
可以使用多核 CPU。
案例 1:
select * from t where thread_id = 10000 and deleted = 0
order by gmt_create asc limit 0, 15;
select t.* from (select id from t where thread_id = 10000 and deleted = 0
order by gmt_create asc limit 0, 15) a, t
where a.id = t.id;
建表优化
②尽量使用数字型字段(如性别,男:1 女:2),若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。
这是因为引擎在处理查询和连接时会 逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。
③查询数据量大的表 会造成查询缓慢。主要的原因是扫描行数过多。这个时候可以通过程序,分段分页进行查询,循环遍历,将结果合并处理进行展示。
SELECT * FROM (SELECT ROW_NUMBER() OVER(ORDER BY ID ASC) AS rowid,*
FROM infoTab)t WHERE t.rowid > 100000 AND t.rowid <= 100050
作者:_陈哈哈
编辑:陶家龙
出处:https://sohu.gg/FGG98i
更多精彩: Java实战项目视频,给需要的读者,收藏!
SpringBoot 如何上传大文件?
微信支付的软件架构到底有多牛?
Java常用的几个Json库,性能强势对比!
求求你们了,别再写满屏的 if/ else 了!
基于Spring+SpringMVC+Mybatis的分布式敏捷开发系统架构(附源码)
关注公众号,查看更多优质文章
最近,整理一份Java资料《Java从0到1》,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。 获取方式:关注公众号并回复 Java 领取,更多Java内容陆续奉上。
明天见(。・ω・。)ノ♡
更多精彩: Java实战项目视频,给需要的读者,收藏! SpringBoot 如何上传大文件? 微信支付的软件架构到底有多牛? Java常用的几个Json库,性能强势对比! 求求你们了,别再写满屏的 if/ else 了! 基于Spring+SpringMVC+Mybatis的分布式敏捷开发系统架构(附源码) 关注公众号,查看更多优质文章 最近,整理一份Java资料《Java从0到1》,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。 获取方式:关注公众号并回复 Java 领取,更多Java内容陆续奉上。