
JavaScript Debugger 原理揭秘
代码写完会运行一下看下效果,开发的时候我们更多都是通过 dubugger 来单步或断点运行。我们整天在用 debugger,可是你有想过它的实现原理么。
本文会解答以下问题:
代码运行的底层原理是什么 为什么需要 debugger debugger 实现原理是什么 如何实现 debugger 客户端
代码运行的原理是什么
代码的运行方式可以分为直接执行和解释执行两类。
不知道平时你有没有注意,可执行文件直接 ./xxx 就可以执行,而执行 js 文件需要 node ./xxx,执行 python 文件需要 python ./xxx,这就是编译执行(直接执行)和解释执行的区别。
直接执行
cpu 提供了一套指令集,基于这套指令集就可以控制整个计算机的运转,机器语言的代码就是由这些指令和对应的操作数构成的,这些机器码可以直接跑在计算机上,也就是可直接执行。由它们构成的文件叫做可执行文件。
不同操作系统可执行文件的格式不同,在 windows 上是 pe(Portable Executable) 格式,在 linux、unix 系统上是 elf(Executable Linkable Format) 格式,在 mac 上是 mash-o 格式。它们规定了不同的内容(.text 是代码、.data .bass 等是数据)放在文件中的什么位置。但其中真正可执行的部分还是由 cpu 提供的机器指令构成的。
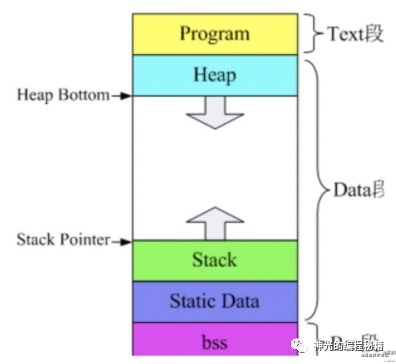
编译型语言会经过编译、汇编、链接的阶段,编译是把源代码转成汇编语言构成的中间代码,汇编是把中间代码变成目标代码,链接会把目标代码组合成可执行文件。这个可执行文件是可以在操作系统上直接执行的。就因为它是由 cpu 的机器指令构成的,可以直接控制 cpu。所以可以直接 ./xxx 就可以执行。

解释执行
编译型语言都是生成可执行文件直接在操作系统上来执行的,不需要安装解释器,而 js、python 等解释型语言的代码需要用解释器来跑。
为什么有了解释器就不需要生成机器码了,cpu 仍然不认识这些代码啊?
那是因为解释器是需要编译成机器码的,cpu 知道怎么执行解释器,而解释器知道怎么执行更上层的脚本代码,就这样,由机器码解释执行解释器,再由解释器解释执行上层代码,这就是脚本语言的原理。 包括 js、python 等都是这样。
但是解释器毕竟多了一层,所以有的时候会把它编译成机器码来直接执行,这就是 JIT 编译器。比如 js 引擎一般就是由 parser、解释器、JIT 编译器、GC 构成,大部分代码是由解释器解释执行的,而热点代码会经过 JIT 编译器编译成由机器码,直接在操作系统上执行以提高性能。
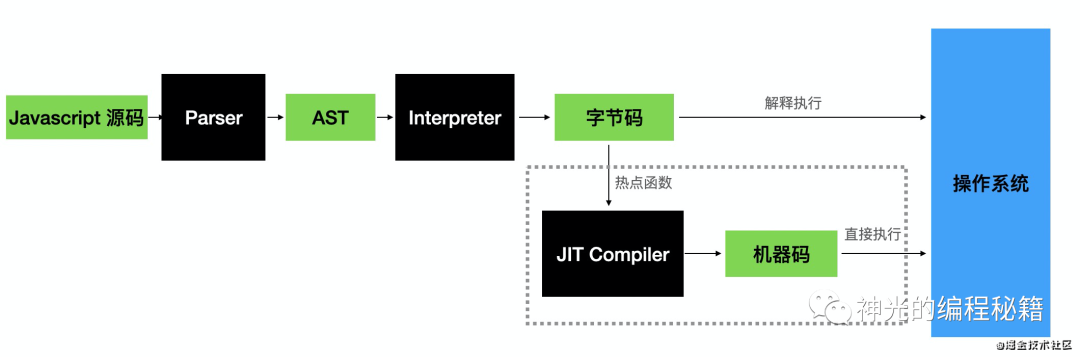
编译成机器码直接执行,或者是从源码解释执行,代码就这两种执行方式。两者各有各的好处,编译型速度快,解释型跨平台。这就是代码运行的原理。
王垠说过,计算机的本质就是解释器。就是说 cpu 用电路解释机器码,解释器用机器码解释更上层的脚本代码,所以计算机的本质是解释器。
为什么需要 debugger
我们知道,图灵完备的语言可以解释任何可计算问题,所以不管是编译型还是解释型都能够描述所有可计算的业务逻辑。
我们利用不同的语言描述业务逻辑,然后运行它看效果,当代码的逻辑比较复杂的时候,难免会出错,我们希望能够一步步运行或是运行到某个点停下来,然后看一下当时的环境中的变量,执行某个脚本。完成这个功能的就是 debugger。
也许还有很多初级程序员只会用 console.log 打日志,但是日志不能完全展现当时的环境,最好的方式还是 debugger。
狼叔说过,是否会用 debugger 是 nodejs 水平的一个明显的区分。
debugger 的原理
我们知道了 debugger 是调试程序必不可少的,那么它是怎么实现的呢?
可执行文件的 debugger
其实 cpu、操作系统在设计的时候就支持了 debugger 的能力(可见 debugger 的重要性),cpu 里面有 4 个寄存器可以做硬中断,操作系统提供了系统调用来做软中断。这是编译型语言的 debugger 实现的基础。
中断
cpu 只会不断的执行下一条指令,但程序运行过程中难免要处理一些外部的消息,比如 io、网络、异常等等,所以设计了中断的机制,cpu 每执行完一条指令,就会去看下中断标记,是否需要中断了。就像 event loop 每次 loop 完都要检查下是否需要渲染一样。
INT 指令
cpu 支持 INT 指令来触发中断,中断有编号,不同的编号有不同的处理程序,记录编号和中断处理程序的表叫做中断向量表。其中 INT 3 (3 号中断)可以触发 debugger,这是一种约定。
那么可执行文件是怎么利用这个 3 号中断来 debugger 的呢?其实就是运行时替换执行的内容,debugger 程序会在需要设置断点的位置把指令内容换成 INT 3,也就是 0xCC,这就断住了。就可以获取这时候的环境数据来做调试。
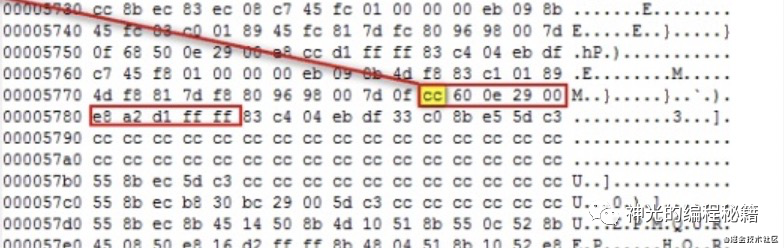
通过机器码替换成 0xcc (INT 3)是把程序断住了,可是怎么恢复执行呢?其实也比较简单,把当时替换的机器码记录下来,需要释放断点的时候再换回去就行了。
这就是可执行文件的 debugger 的原理了,最终还是靠 cpu 支持的中断机制来实现的。
中断寄存器
上面说的 debugger 实现方式是修改内存中的机器码的方式,但有的时候修改不了代码,比如 ROM,这种情况就要通过 cpu 提供的 4 个中断寄存器(DR0 - DR3)来做了。这种叫做硬中断。
总之,INT 3 的软中断,还有中断寄存器的硬中断,是可执行文件实现 debugger 的两种方式。
解释型语言的 debugger
编译型语言因为直接在操作系统之上执行,所以要利用 cpu 和操作系统的中断机制和系统调用来实现 debugger。但是解释型语言是自己实现代码的解释执行的,所以不需要那一套,但是实现思路还是一样的,就是插入一段代码来断住,支持环境数据的查看和代码的执行,当释放断点的时候就继续往下执行。
比如 javascript 中支持 debugger 语句,当解释器执行到这一条语句的时候就会断住。
解释型语言的 debugger 相对简单一些,不需要了解 cpu 的 INT 3 中断。
debugger 客户端
上面我们了解了直接执行和解释执行的代码的 debugger 分别是怎么实现的。我们知道了代码是怎么断住的,那么断住之后呢?怎么把环境数据暴露出去,怎么执行外部代码?
这就需要 debugger 客户端了。
比如 v8 引擎会把设置断点、获取环境信息、执行脚本的能力通过 socket 暴露出去,socket 传递的信息格式就是 v8 debug protocol 。
比如:
设置断点:
{
"seq":117,
"type":"request",
"command":"setbreakpoint",
"arguments":{
"type":"function",
"target":"f"
}
去掉断点:
{
"seq":117,
"type":"request",
"command":"clearbreakpoint",
"arguments": {
"type":"function",
"breakpoint":1
}
}
继续:
{
"seq":117,
"type":"request",
"command":"continue"
}
执行代码:
{
"seq":117,
"type":"request",
"command":"evaluate",
"arguments":{
"expression":"1+2"
}
}
感兴趣的同学可以去 v8 debug protocol 的文档中去查看全部的协议。
基于这些协议就可以控制 v8 的 debugger 了,所有的能够实现 debugger 的都是对接了这个协议,比如 chrome devtools、vscode debugger 还有其他各种 ide 的 debugger。
nodejs 代码的调试
nodejs 可以通过添加 --inspect 的 option 来做调试(也可以是 --inspect-brk,这个会在首行就断住)。
它会起一个 debugger 的 websocket 服务端,我们可以用 vscode 来调试 nodejs 代码,也可以用 chrome devtools 来调试(见 nodejs debugger 文档)。
➜ node --inspect test.js
Debugger listening on ws://127.0.0.1:9229/db309268-623a-4abe-b19a-c4407ed8998d
For help see https://nodejs.org/en/docs/inspector
原理就是实现了 v8 debug protocol。
我们如果自己做调试工具、做 ide,那就要对接这个协议。
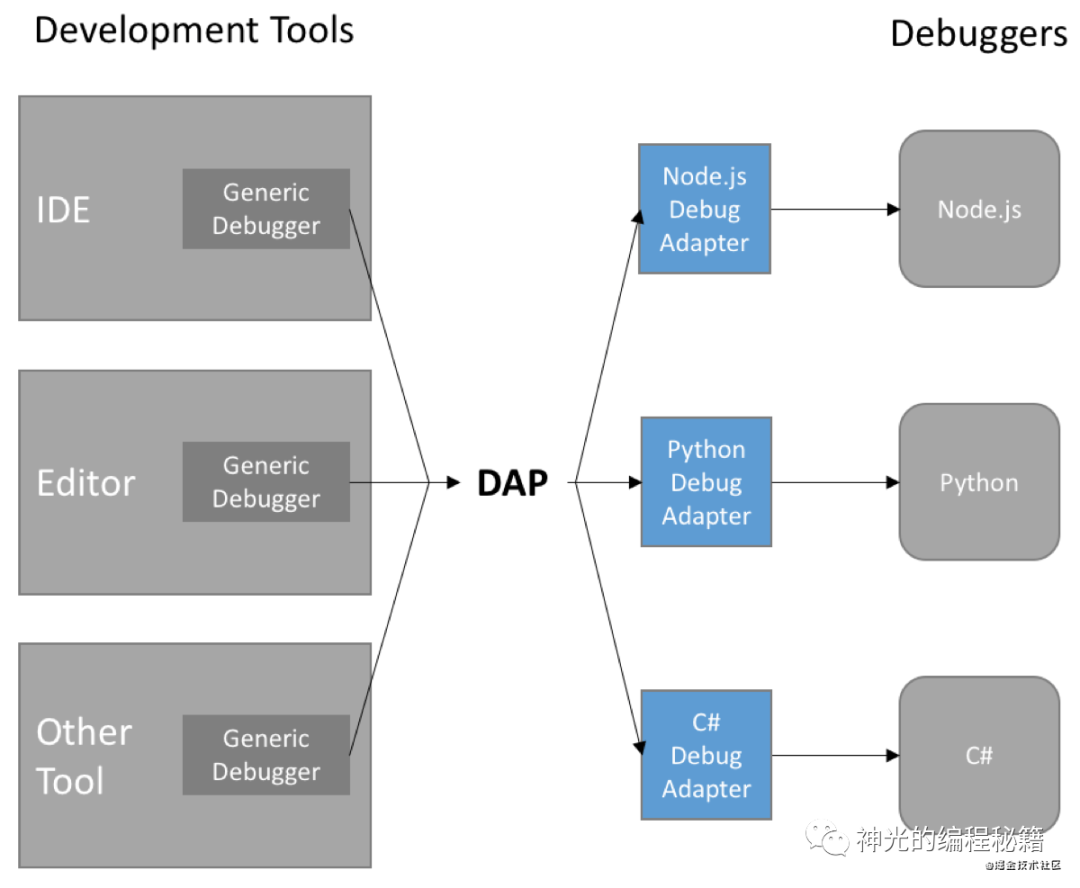
debugger adaptor protocol
上面介绍的 v8 debug protocol 可以实现 js 代码的调试,那么 python、c# 等肯定也有自己的调试协议,如果要实现 ide,都要对接一遍太过麻烦。所以后来出现了一个中间层协议,DAP(debugger adaptor protocol)。
debugger adaptor protocol, 顾名思义,就是适配的,一端适配各种 debugger 协议,一端提供给客户端统一的协议。这是适配器模式的一个很好的应用。
总结
本文我们学习了 debugger 的实现原理和暴露出的调试协议。
首先我们了解了代码两种运行方式:直接执行和解释执行,然后分析了下为什么需要 debugger。
之后探索了直接执行的代码通过 INT 3 的中断的方式来实现 debugger 和解释型语言自己实现的 debugger。
然后 debugger 的能力会通过 socket 暴露给客户端,提供调试协议,比如 v8 debug protocol,各种客户端包括 chrome devtools、ide 等都实现了这个协议。
但是每种语言都要实现一次的话太过麻烦,所以后来出现了一个适配层协议,屏蔽了不同协议的区别,提供统一的协议接口给客户端用。
希望这篇文章能够让你理解 debugger 的原理,如果要实现调试工具也知道怎么该怎么去对接协议。能够知道 chrome devtools、vscode 为啥都可以调试 nodejs 代码。
爱心三连击
1.看到这里了就点个在看支持下吧,你的在看是我创作的动力。
2.关注公众号脑洞前端,获取更多前端硬核文章!加个星标,不错过每一条成长的机会。
3.如果你觉得本文的内容对你有帮助,就帮我转发一下吧。