
面试官发问:什么是高并发下的请求合并?

从一道面试题说起
前段时间一个在深圳的,两年经验的小伙伴出去面试了一圈,收割了几个大厂 offer 的同时,还总结了一下面试的过程中遇到的面试题,面试题有很多,文末的时候我会分享给大家。
这次的文章主要分享他面试过程中遇到的一个场景题:
他说对于这个场景题,面试的时候没有什么思路。
说真的,请求合并我知道,高并发无非就是快速的请求合并。
但是在我有限的认知里面,如果类似于秒杀的高并发扣库存这个场景,用请求合并的方式来做,我个人感觉是有点怪怪的不够传统。
在传统的,或者说是业界常用的秒杀解决方案中,从前端到后台,你也找不到请求合并的字样。
我理解请求合并更加适用的场景是查询类的,或者说是数值增加类的需求,对于库存扣减这种,你稍不留神,就会出现超卖的情况。
当然也有可能是我理解错题意了,看到高并发扣库存就想到秒杀场景了。
但是不重要,我们也不能直接和面试官硬刚。

我会重新给个我觉得合理的场景,告诉大家我理解的请求合并和高并发下的请求合并是什么玩意。
请求合并
现在我们抛开秒杀这个场景。
换一个更加合适,大家可能更容易理解的场景来聊聊什么是请求合并。
就是热点账户。
什么是热点账户呢?
在第三方支付系统或者银行这类交易机构中,每产生一笔转入或者转出的交易,就需要对交易涉及的账户进行记账操作。
记账一般来说涉及到两个部分。
交易系统记录这一笔交易的信息。 账户系统需要增加或减少对应的账户余额。
如果对于某个账户操作非常的频繁,那么当我们对账户余额进行操作的时候,就会涉及到并发处理的问题。
并发了怎么办?
是的,我们可以对账户进行加锁处理。这样一来,这个账户就涉及到频繁的加锁解锁操作。
这样我们可以保证数据不出问题,但是随之带来的问题是随着并发的提高,账户系统性能下降。
这个账户,就是热点账户,就是性能瓶颈点。
热点账户是业界的一个非常常见的问题。
我所了解到的常规解决方案大概可以分为三种:
异步缓冲记账。 设立影子账户。 多笔合一记账。
本小节主要是介绍“多笔合一记账”解决方案,从而引出请求合并的概率。
对于另外两个解决方案,就先简单的说一下。
首先异步缓冲记账。
我先不解释,你就看着这个名字,想着这个场景,你觉得你会想到什么?
异步,是不是想到了 MQ?
那么请问你系统里面为什么要引入 MQ 呢?
来,面试八股文背起来:异步处理、系统解耦、削峰填谷。
你说我们当前的这个场景下属于哪一种情况?
肯定是为了做削峰填谷呀。
假设账务系统的 TPS 是 200 笔每秒,当请求低于 200 笔每秒的时候,账务服务基本上能够及时处理马上返回。
从用户的角度来说就是:啪的一下,很快啊。我就收到了记账成功的通知了,也看到账户余额发生了变化。
但是在业务高峰期的时候,流量直接翻倍,每秒过来了 400 笔请求,这个时候对于账务系统来说就是流量洪峰,需要进行削峰了,队列里面开始堆积着请求,开始排队处理了。
在流量低谷的时候,就可以把这部分数据消费完成。
相当于数据扔到队列里面之后,就可以告诉用户记账成功了,钱马上就到。
但是这个方案带来的问题也是很明显的,如果流量真的爆了,一天都没有谷让你填,队列里面堆积着大量的请求还没来得及处理,你怎么办?
这对于用户而言就是:你明明告诉我记账成功了,为什么我的账户余额迟迟没有变化呢?是不是想阴我钱,我反手就是一波投诉。
另外一个风险点就是对于支出类的请求,如果被削峰,很明显,我们提前就告诉了用户操作成功,但是真正动账户余额的时候已经延迟了,所以可能会出现账户透支的情况。
另外一个设立影子账户的方案,其实和我们本次的请求合并的主题是另外一个不同的方向。
它的思想是拆分。
热点账户说到底还是一个单点问题,那么对于单点问题,我们用微服务的思想去解决的话是什么方案?
就是拆分。
假设这个热点账户上有 100w,我设立 10 个影子账户,每个账户 10w ,那么是不是我们的流量就分散了?从一个账户变成了 10 个账户。
压力也就进行了分摊。
这个方案就有点类似于秒杀场景中的库存了,库存我们也可以拆多份。
但是带来的问题也很明显。
一是获取账户余额的时候需要进行汇总操作。
二是假设用户要扣 11w 呢?我们总余额是够的,但是每个影子账户上的钱是不够的。
三是你的影子账户选择的算法是很重要的,是用随机?轮训?加权?这些对于账务成功率都是有比较大的影响的。
另外这个思想,我在之前的文章中也提到过,有兴趣的可以看看其在 JDK 源码中的应用:我从LongAdder中窥探到了高并发的秘籍,上面只写了两个字...
好了,回到本次的主题:多笔合一笔记账。
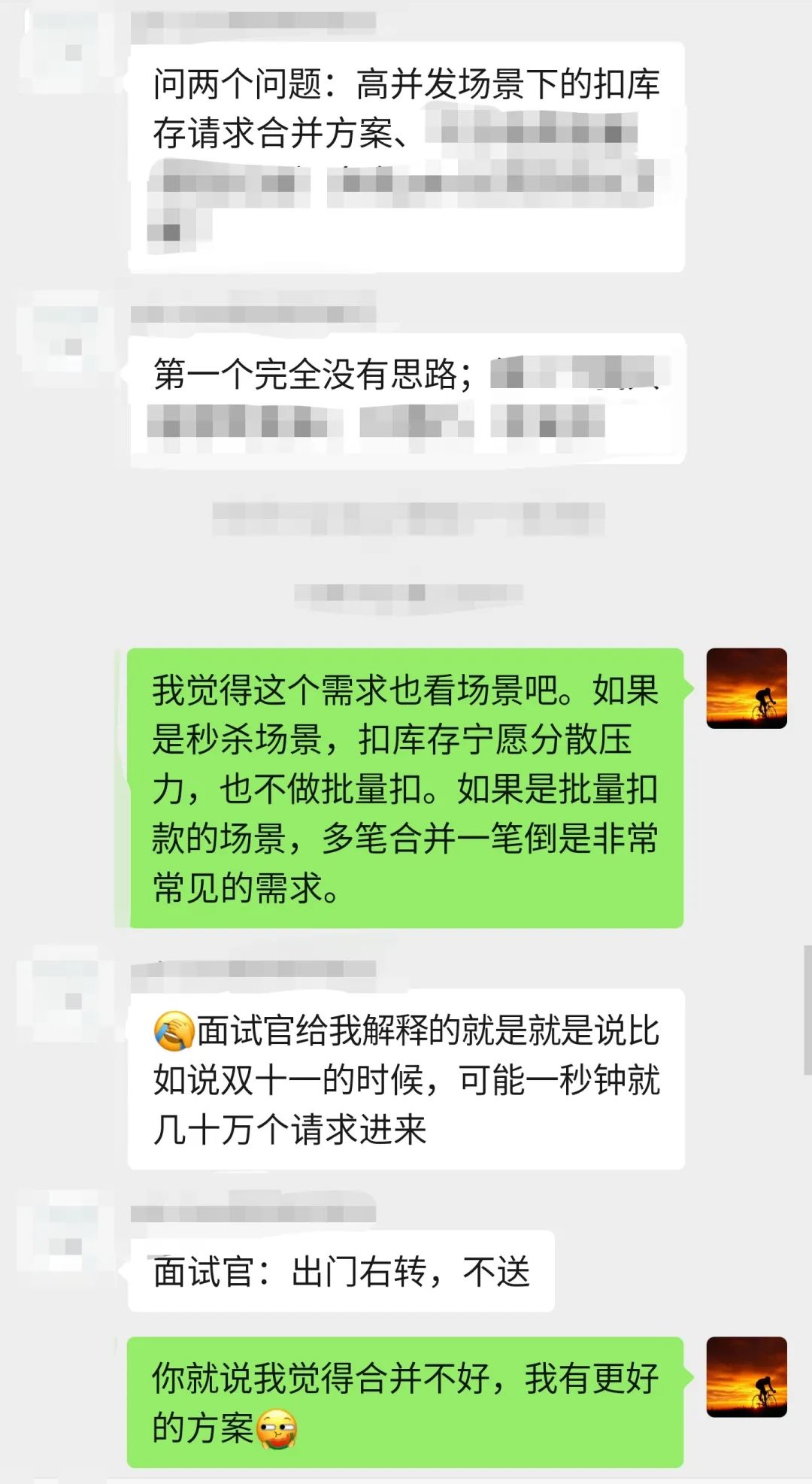
有个网红店,生意非常的好,每天很多人在店里面消费。
当用户扫码支付后,请求会发送到这个店对接的第三方支付公司。
当支付公司收到请求,并完成记账操作后才会告知商户用户支付成功。可以给用户商品了。
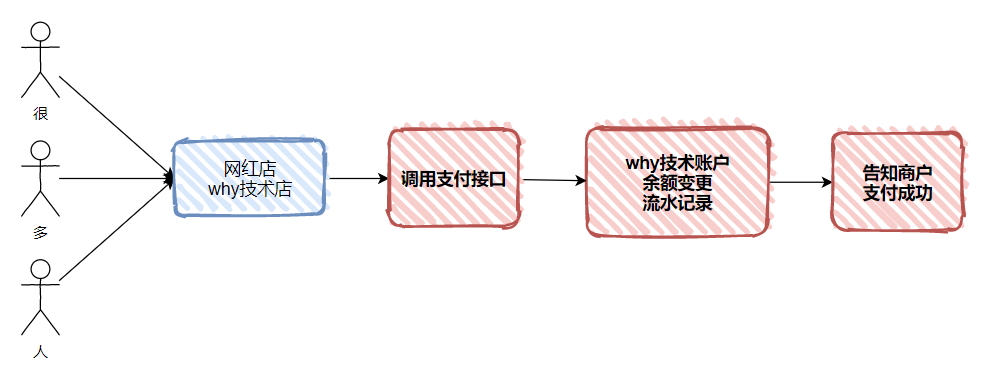
随着店里生意越来越好,带来的问题是第三方支付公司的系统压力增加,扛不住这么大的并发了。导致用户支付成功率的下降或者用户支付成功后很长时间才通知到商户。
那么针对这个商户的账户,我们就可以做多笔合一笔处理。
当记录进入缓冲流水记录表之后,我们就可以通知商户用户支付成功了,至于钱,你放心,我有定时任务,一会就到账:
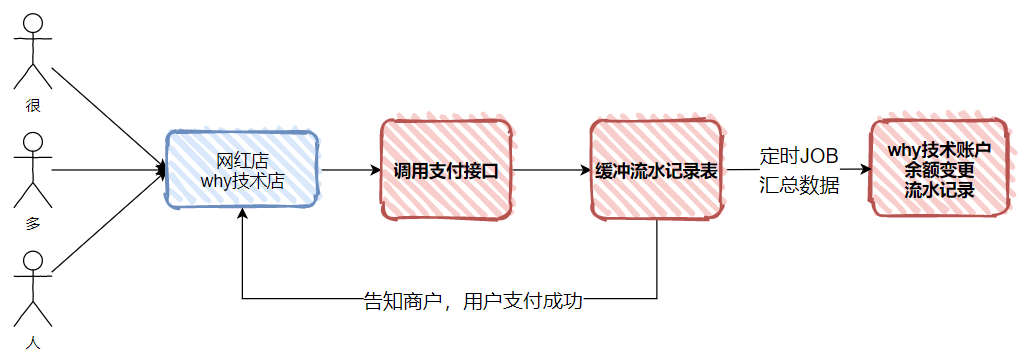
所以当用户下单之后,我们只是先记录数据,并不去实际动账户。等着定时任务去触发记账,进行多笔合并一笔的操作。
比如下面的这个示意图:
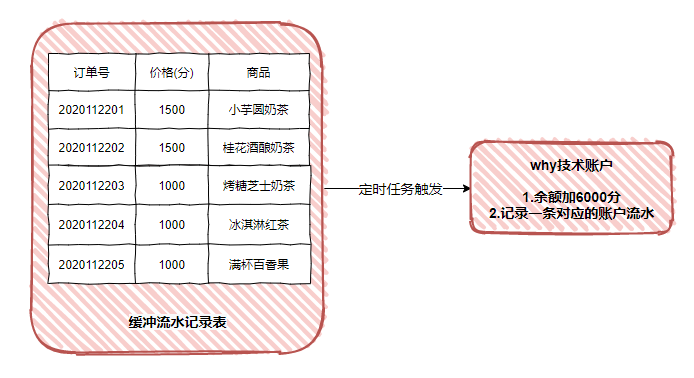
商户实际有 5 个用户支付记录,但是这 5 笔记录对应着一条账户流水。我们拿着账户流水,也是可以追溯到这 5 笔交易记录的。
这样的好处是吞吐量上来了,通知及时,用户体验也好了。但是带来的弊端是余额并不是一个准确的值。
假设我们的定时任务是一小时汇总一次,那么商户在后端看到的交易金额可能是一小时之前的数据。
而且这种方案对于账户收钱的场景非常的适合,但是减钱的场景,也是有可能会出现金额为负的情况。
不知道你有没有看出多笔合一笔处理方案的秘密。
如果我们把缓冲流水记录表看作是一个队列。那么这个方案抽象出来就是队列加上定时任务。
所以,请求合并的关键点也是队列加上定时任务。
文章看到现在,请求合并我们应该是大概的了解到了,也确实是有真实的应用场景。
除了我上面的例子外,比如还有 redis里面的 mget,数据库里面的批量插入,这玩意不就是一个请求合并的真实场景吗?
比如 redis 把多个 get 合并起来,然后调用 mget。多次请求合并成一次请求,节约的是网络传输时间。
还有真实的案例是转账的场景,有的转账渠道是按次收费的,那么作为第三方公司,我们就可以把用户的请求先放到表里记录着,等一小时之后,一起汇总发起,假设这一小时内发生了 10 次转账,那么 10 次收费就变成了 1 次收费,虽然让客户等的稍微久了点,但还是在可以接受的范围内,这操作节约的就是真金白银了。
高并发的请求合并
理解了请求合并,那我们再来说说当他前面加上高并发这三个字之后,会发生什么变化。
首先不论是在请求合并的前面加上多么狂拽炫酷吊炸天的形容词,说的多么的天花乱坠,它也还是一个请求合并。
那么队列和定时任务的这个基础结构肯定是不会变的。
高并发的情况下,就是请求量非常的大嘛,那我们把定时任务的频率调高一点不就行了?
以前 100ms 内就会过来 50 笔请求,我每收到一笔就是立即处理了。
现在我们把请求先放到队列里面缓存着,然后每 100ms 就执行一次定时任务。
100ms 到了之后,就会有定时任务把这 100ms 内的所有请求取走,统一处理。
同时,我们还可以控制队列的长度,比如只要 50ms 队列的长度就达到了 50,这个时候我也进行合并处理。不需要等待到 100ms 之后。
其实写到这里,高并发的请求合并的答案已经出来了。关键点就三个:
一是需要借助队列加定时任务实现。
二是控制定时任务的执行时间.
三是控制缓冲队列的任务长度。
方案都想到了,把代码写出来岂不是很容易的事情。而且对于这种面试的场景图,一般都是讨论技术方案,而不太会去讨论具体的代码。
当讨论到具体的代码的时候,要么是对你的方案存疑,想具体的探讨一下落地的可行性。要么就是你答对了,他要准备从代码的交易开始衍生另外的面试题了。
总之,大部分情况下,不会在你给了一个面试官觉得错误的方案之后,他还和你讨论代码细节。你们都不在一个频道了,赶紧换题吧,还聊啥啊。
实在要往代码实现上聊,那么大概率他是在等着你说出一个框架:Hystrix。
Hystrix框架
其实这题,你要是知道 Hystrix,很容易就能给出一个比较完美的回答。
因为 Hystrix 就有请求合并的功能。给大家演示一下。
假设我们有一个学生信息查询接口,调用频率非常的高。对于这个接口我们需要做请求合并处理。
做请求合并,我们至少对应着两个接口,一个是接收单个请求的接口,一个处理把单个请求汇总之后的请求接口。
所以我们需要先提供两个 service:
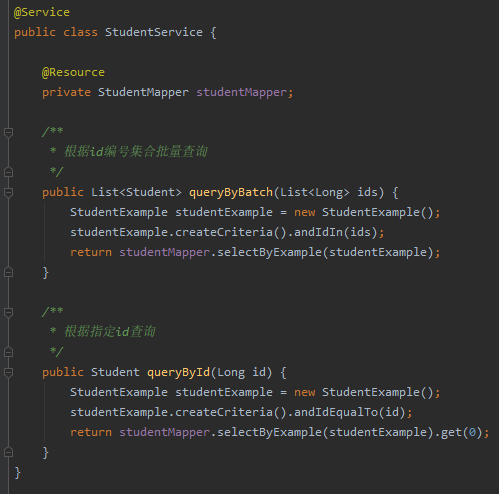
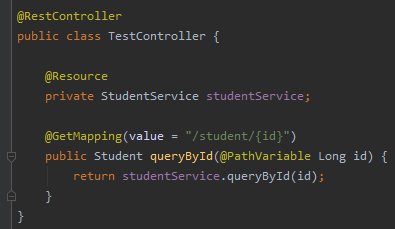
其中根据指定 id 查询的接口,对应的 Controller 是这样的:
服务启动起来后,我们用线程池结合 CountDownLatch 模拟 20 个并发请求:
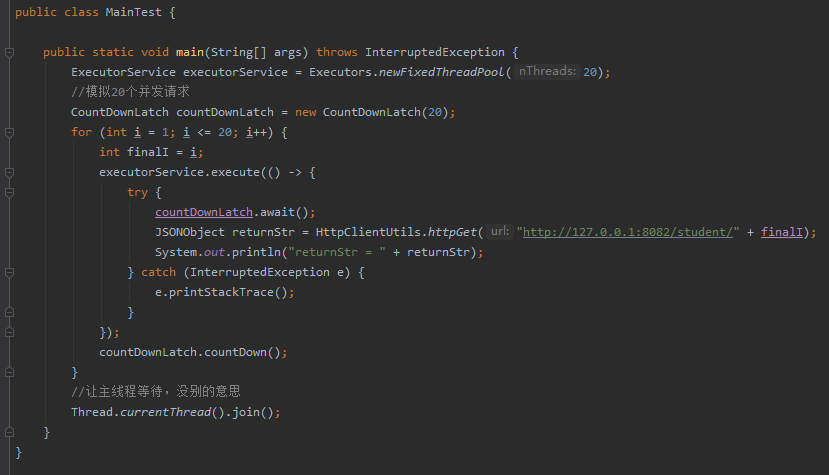
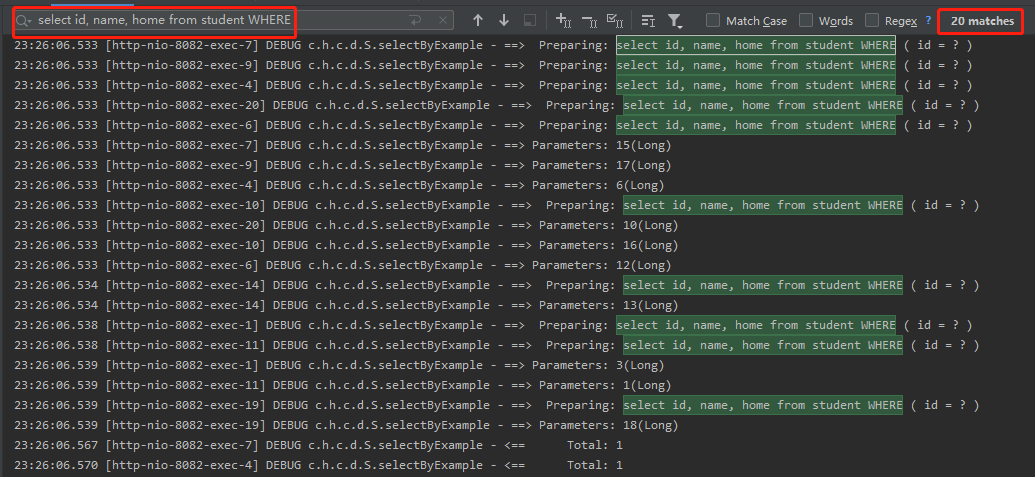
从控制台可以看到,瞬间接受到了 20 个请求,执行了 20 次查询 sql:
很明显,这个时候我们就可以做请求合并。每收到 10 次请求,合并为一次处理,结合 Hystrix 代码就是这样的,为了代码的简洁性,我采用的是注解方式:
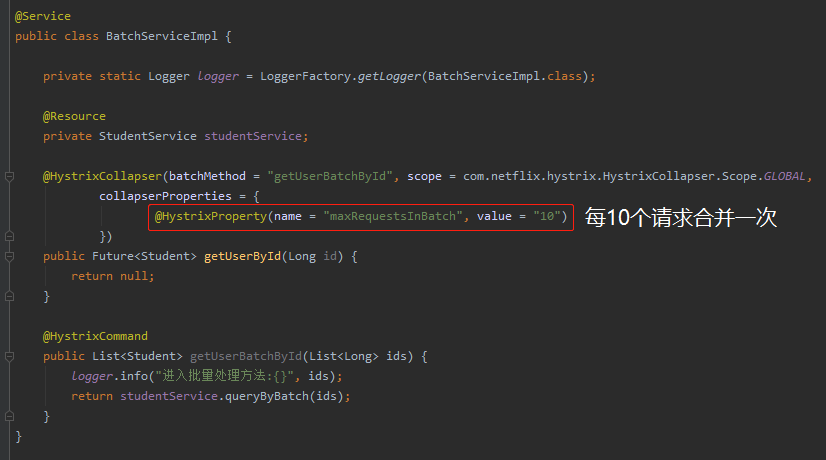
在上面的图片中,有两个方法,一个是 getUserId,直接返回的是null,因为这个方法体不重要,根本就不会执行。
在 @HystrixCollapser 里面可以看到有一个 batchMethod 的属性,其值是 getUserBatchById。
也就是说这个方法对应的批量处理方法就是 getUserBatchById。当我们请求 getUserById 方法的时候,Hystrix 会通过一定的逻辑,帮我们转发到 getUserBatchById 上。
所以我们调用的还是 getUserById 方法:
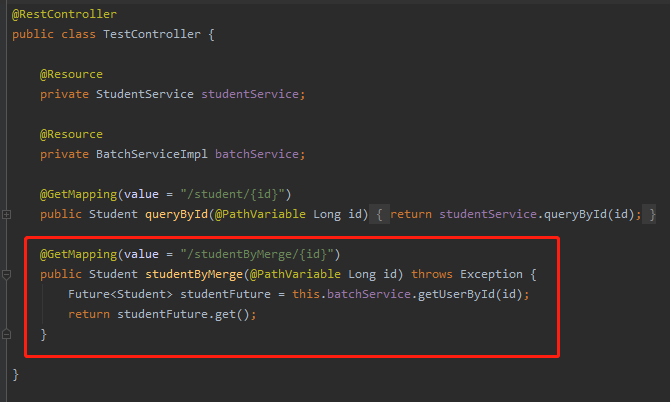
同样,我们用线程池结合 CountDownLatch 模拟 20 个并发请求,只是变换了请求地址:
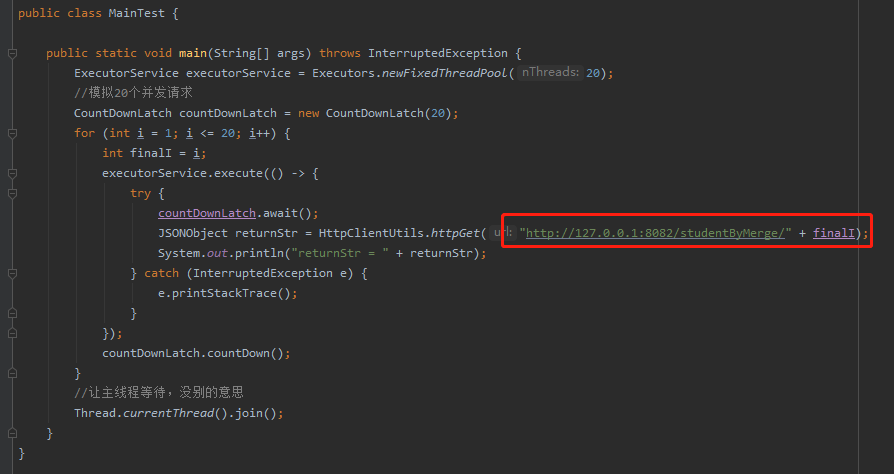
调用之后,神奇的事情就出现了,我们看看日志:

同样是接受到了 20 个请求,但是每 10 个一批,只执行了两个sql语句。
从 20 个 sql 到 2 个 sql,这就是请求合并的威力。请求合并的处理速度甚至比单个处理还快,这也是性能的提升。
那假设我们只有 5 个请求过来,不满足 10 个这个条件呢?
别忘了,我们还有定时任务呢。
在 Hystrix 中,定时任务默认是每 10ms 执行一次:

同时我们可以看到,如果不设置 maxRequestsInBatch,那么默认是 Integer.MAX_VALUE。
也就是说,在 Hystrix 中做请求合并,它更加侧重的是时间方面。
功能演示,其实就这么简单,代码量也不多,有兴趣的朋友可以直接搭个 Demo 跑跑看。看看 Hystrix 的源码。
我这里只是给大家指几个关键点吧。
第一个肯定是我们需要找到方法入口。
你想,我们的 getUserById 方法的方法体里面直接是 return null,也就是说这个方法体是什么根本就不重要,因为不会去执行方法体中的代码。它只需要拦截到方法入参,并缓存起来,然后转发到批量方法中去即可。
然后方法体上面有一个 @HystrixCollapser 注解。
那么其对应的实现方式你能想到什么?
肯定是 AOP 了嘛。
所以,我们拿着这个注解的全路径,进行搜索,啪的一下,很快啊,就能找到方法的入口:
com.netflix.hystrix.contrib.javanica.aop.aspectj.HystrixCommandAspect#methodsAnnotatedWithHystrixCommand
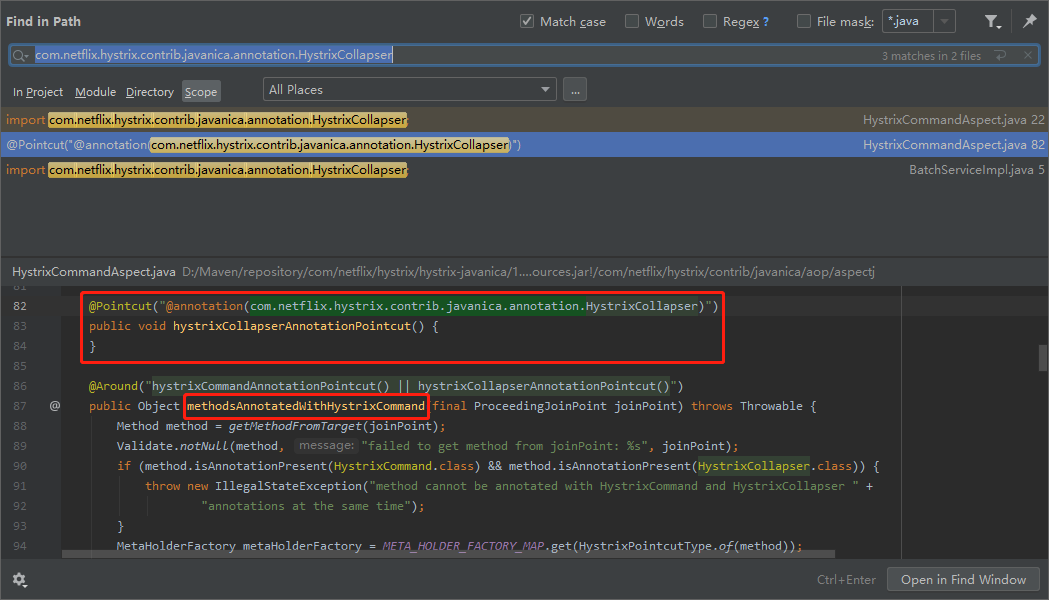
在入口处打上断点,就可以开始调试了:
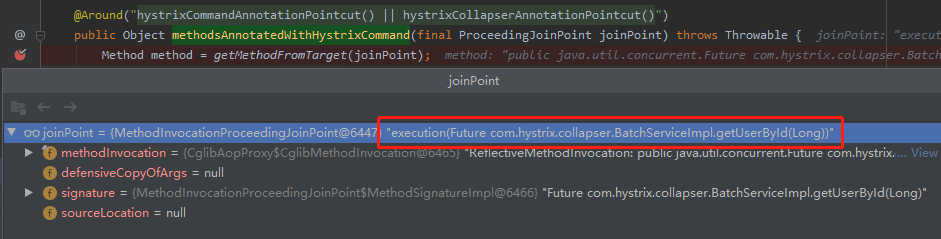
第二个我们看看定时任务是在哪儿进行注册的。
这个就很好找了。我们已经知道默认参数是 10ms 了,只需要顺着链路看一下,哪里的代码调用了其对应的 get 方法即可:
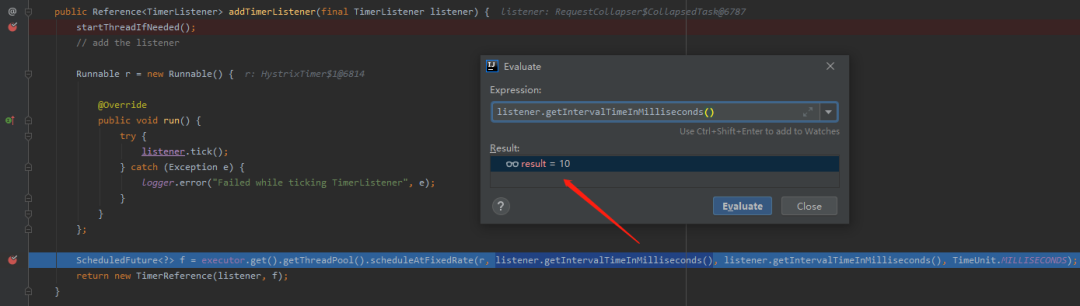
同时,我们可以看到,其定时功能是基于java.util.concurrent.ScheduledThreadPoolExecutor#scheduleAtFixedRate实现的。
第三个我们看看是怎么控制超过指定数量后,就不等待定时任务执行,而是直接发起汇总操作的:
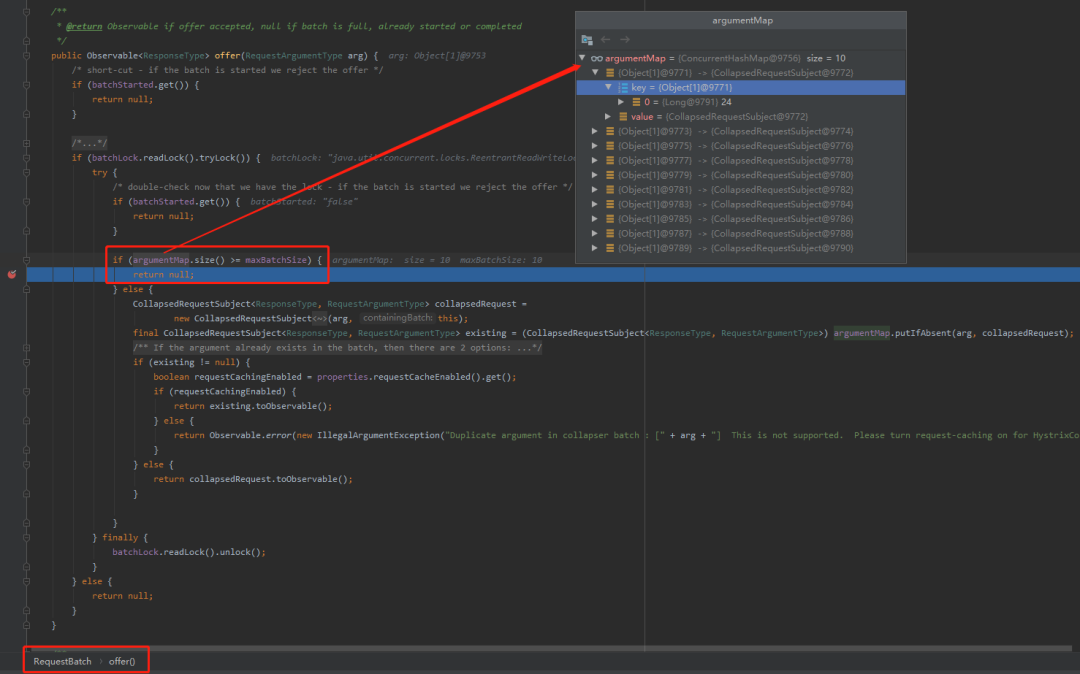
可以看到,在com.netflix.hystrix.collapser.RequestBatch#offer方法中,当 argumentMap 的 size 大于我们指定的 maxBatchSize 的时候返回了 null。
如果,返回为 null ,那么说明已经不能接受请求了,需要立即处理,代码里面的注释也说的很清楚了:
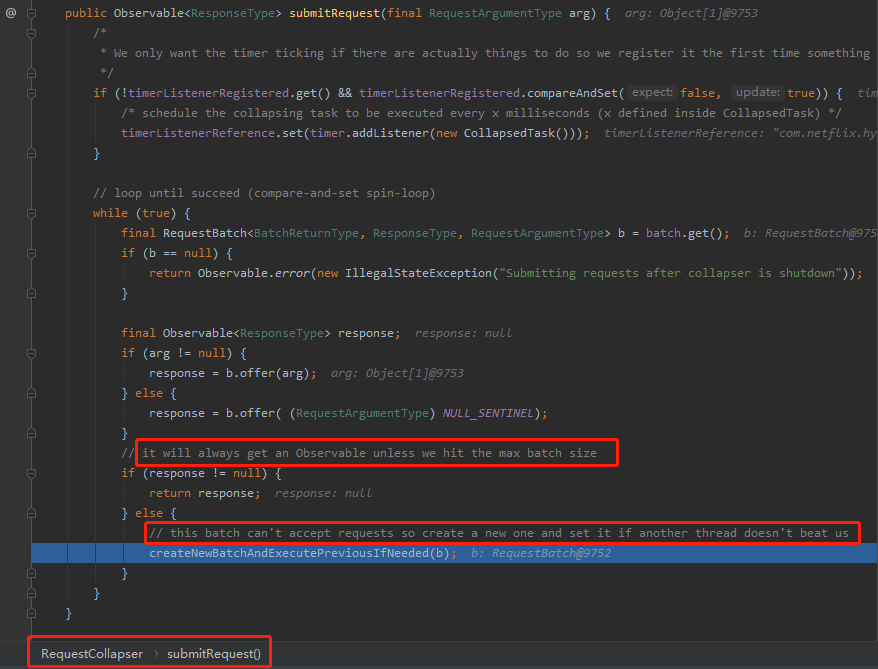
以上就是三个关键的地方,Hystrix 的源码读起来,需要下点功夫,大家自己研究的时候需要做好心理准备。
最后再贴一个官方的请求合并工作流程图:
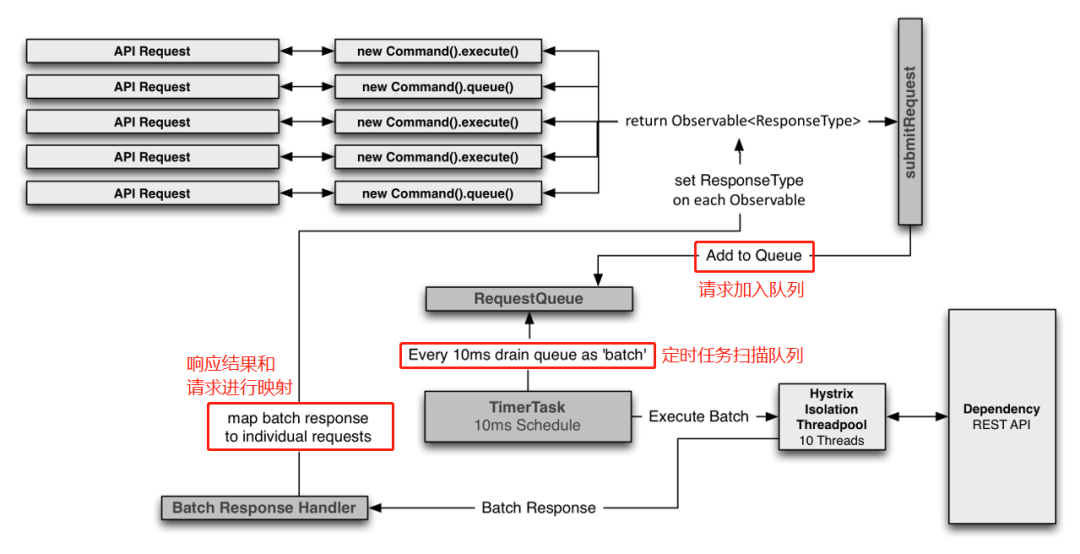
打完收工。
面试题分享
前面说的深圳的,两年经验的小伙伴把面试题汇总了一份给我,我也分享给大家吧。
Java基础
volatile关键字底层原理 线程池各个参数含义 lock、Synn区别 ReentrantLock锁公平与非公平实现、重入原理 HashMap扩容时机(容量初始化为1000和10000是否触发扩容)、机制、1.7与1.8的差异 ConcurrentHashMap1.7、1.8的优化与差异,size方法实现差异 ThreadLocal原理与风险、为什么会内存泄露 阻塞队列的用途、区别 LinkedBlockingQueue对列的add、put区别,实际过程中如何使用 悲观锁、乐观锁、自旋锁的使用场景、实现方式、优缺点 Class.forName、loanClass区别; 线程生命周期、死锁条件与死锁避免、状态转换关系(源码级别); String intern方法; cas的优缺点与解决方案、ABA问题;
JVM相关
CMS垃圾回收的碎片解决方式 常用的垃圾回收器 JVM垃圾回收器CMS的优缺点、与G1的区别、进入老年代的时机 JVM内存模型 JVM调优思路 GC Root、ModUnionTable 偏向锁、轻量级锁、重量级锁底层原理、升级过程 jmap、jstat、top、MAT CMS与G1对别 GC Root、ModUnionTable;
Redis相关
Redis高性能原因 Redis的部署模式 RedisCluster底层原理 Redis持久化机制 缓存淘汰机制 缓存穿透、缓存雪崩、缓存击穿发生场景与解决方案
SQL相关
MyBatis拦截器的用途 MyBatis动态SQL原理 分库分表方案设计 MySQL怎么解决幻读、原理(源码级别) Gap锁的作用域原理 RR、RC区别 MySQL默认的事务隔离级别、Oracle默认的事务隔离级别 MySQL为啥使用B+树索引 redo log、binlog、undo log写入顺序、分别保证了ACID的什么特性 数据库乐观锁 MySQL优化 MySQL底层原理
Spring相关
@Bean注解、@Component注解区别 Spring Aop原理 @Aspect和普通AOP区别 自定义拦截器和Aop那个先执行 web 拦截器 DispatchServlet原理
Dubbo相关
Dubbo负载均衡、集群容错 Dubbo SPI机制、Route重写使用场景 Dubbo RPC底层原理 全链路监控实现原理
分布式相关
分布式锁的实现方式 漏斗算法、令牌桶算法 事务最终一致性解决方案 SLA 分布式事务实现方式与区别 Tcc Confirm失败怎么办? 分布式锁的各种实现方式、对比 分布式ID的各种实现方式、对比 雪花算法时钟回拨问题与应对方案 红锁算法
设计模式
常用的设计模式 状态模式 责任链模式解决了什么问题 饿汉式、懒汉式优缺点、使用场景 模板方法模式、策略模式、单例模式、责任链模式
Zookeeper
Zookeeper底层架构设计 zk一致性
MQ
Kafka顺序消息 MQ消息幂等 Kafka高性能秘诀 Kafka高吞吐原理 Rocket事务消息、延时队列
计算机网络
浏览器输入一个url发生了什么 Http 1.0、1.1、2.0差异 IO多路复用 TCP四次挥手过程、状态切换 XSS、CRSF攻击与预防 301、302区别
Tomcat
Tomcat大概原理
代码
手写发布订阅模式 大数(两个String)相加
场景问题
打赏排行榜实现 高并发下的请求合并 CPU 100%处理经验 短链系统设计 附近的人项目实现 10w个红包秒级发送方案 延时任务的实现方案与优缺点对比
说来惭愧,有些题我也答不上来,所以和大家一起查漏补缺吧。
哦,对了,那个小伙子最终收割了好几个大厂 offer,跑来问我哪个 offer 好。
你说这问题对我来说那不是超纲了吗?我也没在大厂体验过啊。所以我怀疑他不讲武德,来骗,来偷袭我这个老实巴交的小号主,我希望他能耗子尾汁,在鹅厂好好发展:

荒腔走板

周六早上起来,看到新闻说北京下雪了。成都最近也降温了。上面的图片还是我在北京的时候拍的。
刚刚怀念完北京个性鲜明的秋天,又迎来了我最喜欢的冬天。
我怀念北方的冬天,那种一进屋,眼镜上蒙起一层薄薄的雾,然后里面就被暖气包裹起来的感觉。
在北京,冬天进屋是先脱下厚厚的棉衣,而在成都,冬天进屋是先下意识的裹紧了身上的衣服。
当然,我作为一个南方人,最喜欢的还是下雪的时候。在成都的市区里面,是极少极少能遇到下雪天的,偶尔碰见飘着几粒雪花,落在地上也决然是不会有积雪形成的。
而在北京的时候,看天气预报说是晚上会下雪,那第二天早上起来都是满怀期待的拉开窗帘,急迫的想看看白雪覆盖的北京。
我喜欢那种穿着大头靴子,踩在积雪上软软的,发出格叽格叽的声音,那是一种属于北方的声音。
说来也是可惜,每次北京下雪的时候,都不合时宜,导致我都没有时间能去故宫。下雪的时候去故宫,可能也是无数人可遇而不可求的事情吧。
写到这里的时候我本来想多描述一下我多怀念北京的雪景的,但是给家里安装投影幕布的师傅打电话过来说他已经在等电梯了。
那我必须的快速的收尾了。
这个周末一直在忙着装家具,弄软装方面的事情,有点疲倦。又想着今年马上就要结束了。我计划的每年都要写的《我这一年》还没开始动笔,一想着坚持写了 7 年,不会在今年真的给断了吧?
一股焦虑就随之而来。那能怎么办呢?要么休息休息,要么继续肝呗。没所谓的,焦虑大多是因为看的太远了。
没关系,那就先走好脚下的路吧。
哦,对了,新家还没安装网络,我周末在那边待了两个下午,所以这篇文章是我开手机热点,用流量写的。不断更,是我最后的倔强。
好了,师傅在敲门了。
就这样吧。
最后说一句(求关注)
好了,看到了这里安排个“一键三连”(转发、在看、点赞)吧,周更很累的,不要白嫖我,需要一点正反馈。

才疏学浅,难免会有纰漏,如果你发现了错误的地方,可以在后台提出来,我对其加以修改。
感谢您的阅读,十分欢迎并感谢您的关注。

